



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
À medida que as equipes movem aplicativos LLM e agentes de IA para produção, o custo rapidamente se torna um dos problemas mais difíceis de analisar. Ao contrário das cargas de trabalho tradicionais na nuvem, os custos de IA são impulsionados por padrões de uso que são dinâmicos, não determinísticos e frequentemente ocultos por trás de múltiplas camadas de abstração.
Uma única solicitação de usuário pode acionar múltiplas chamadas de modelo, novas tentativas, invocações de ferramentas e loops de agente. Pequenas alterações em prompts, lógica de roteamento ou comportamento do agente podem aumentar significativamente o uso de tokens e o custo, muitas vezes sem sinais óbvios até que os relatórios de faturamento cheguem.
É por isso que a observabilidade de custos de IA é crítica em sistemas de produção. Ela vai além do rastreamento de contagens de tokens ou faturas de provedores. A observabilidade de custos de IA foca em atribuir custos às unidades reais dos sistemas de IA, como solicitações, prompts, agentes, ferramentas e usuários, ao mesmo tempo que permite às equipes detectar e controlar problemas de custo precocemente.
Neste blog, explicaremos o que a observabilidade de custos de IA significa na prática, por que os custos de IA são difíceis de rastrear e como as equipes usam arquiteturas baseadas em gateway para monitorar e controlar os gastos com LLM em produção.
A observabilidade de custos de IA é a capacidade de medir, atribuir e analisar o custo das cargas de trabalho de IA em modelos, agentes e fluxos de trabalho em tempo real.
Em sistemas de produção, isso geralmente inclui:
Na prática, isso vai além de simples painéis de faturamento para uma solução estruturada de rastreamento de custos de LLM, onde o uso de tokens, novas tentativas, decisões de roteamento e comportamento do agente estão diretamente ligados aos fluxos de trabalho de aplicativos reais.
Ao contrário do monitoramento tradicional de custos de infraestrutura, a observabilidade de custos de IA deve operar na camada de aplicação e inferência. As ferramentas de faturamento em nuvem podem informar às equipes quanto gastaram no total, mas não explicam por que os custos aumentaram ou qual parte do sistema o causou.
Uma observabilidade de custos de IA eficaz fornece às equipes o contexto necessário para responder a perguntas como:
Ao tornar os custos visíveis neste nível, as equipes podem tratar os gastos com IA como uma métrica operacional, em vez de uma despesa inesperada.
Os custos de IA são difíceis de rastrear não porque o preço seja opaco, mas porque o custo é uma propriedade emergente do comportamento do sistema. Em ambientes de produção, o uso de LLMs é moldado por lógicas de roteamento, novas tentativas, agentes e chamadas de ferramentas, todos os quais interagem de maneiras não óbvias.
Vários fatores tornam a observabilidade de custos de IA um desafio para as equipes.
A maioria dos provedores de LLM cobra com base em tokens, mas o uso de tokens é altamente sensível ao comportamento em tempo de execução. Pequenas alterações em prompts, tamanho do contexto ou restrições de saída podem aumentar significativamente a contagem de tokens. Como essas alterações geralmente ocorrem na camada de aplicação ou de prompt, elas são difíceis de detectar usando apenas o faturamento no nível do provedor.
Sistemas de produção raramente dependem de um único modelo. As equipes roteiam solicitações por múltiplos modelos e provedores para equilibrar custo, latência e qualidade. Sem uma visão centralizada, os dados de custo ficam fragmentados entre os provedores, tornando difícil comparar ou otimizar os gastos de forma holística.
Falhas são caras em sistemas de IA. Novas tentativas e lógicas de fallback podem multiplicar os custos silenciosamente, especialmente quando as solicitações se propagam por vários modelos. Sem observabilidade no nível da solicitação, as equipes frequentemente perdem esses multiplicadores de custo ocultos até que apareçam nas faturas agregadas.
Sistemas baseados em agentes amplificam a complexidade dos custos. Uma única execução de agente pode envolver múltiplas chamadas de modelo, etapas de planejamento e invocações de ferramenta. Se um agente entra em um loop ou usa ferramentas em excesso, os custos podem aumentar rapidamente. Acompanhar esse comportamento requer visibilidade de como os agentes executam passo a passo.
Ferramentas de custo de nuvem e painéis de provedores relatam o uso em nível de conta ou projeto. Eles não atribuem custos a prompts, agentes, usuários ou fluxos de trabalho. Isso dificulta que as equipes de plataforma imponham orçamentos ou que as equipes de aplicação otimizem seu próprio uso.
Na prática, esses desafios significam que os problemas de custo de IA são frequentemente detectados tardiamente e abordados de forma reativa. É por isso que as equipes que executam cargas de trabalho de IA em produção precisam de observabilidade de custos integrada ao Gateway de IA e caminho de execução, por onde todas as solicitações passam.
Para controlar os gastos com IA em produção, as equipes precisam de mais do que uma fatura mensal total. Elas precisam entender de onde vêm os custos e por quê. A observabilidade de custos se baseia em observabilidade de LLM ao vincular o uso de tokens e os gastos a prompts, agentes e fluxos de trabalho. A observabilidade eficaz de custos de IA detalha os gastos em dimensões que correspondem à forma como os sistemas de IA são realmente construídos e operados.
As dimensões de custo mais úteis incluem as seguintes.
Esta é a base. Monitorar o custo por solicitação ajuda as equipes a entender o quão caras são as interações individuais do usuário e como esse custo muda ao longo do tempo. Picos aqui frequentemente indicam crescimento de prompts, novas tentativas ou mudanças de roteamento.
Em sistemas multi-modelo, diferentes modelos têm perfis de custo muito distintos. As equipes precisam de visibilidade sobre quanto está sendo gasto em cada modelo e provedor, e como as decisões de roteamento afetam o custo geral. Isso é essencial para fazer escolhas informadas entre qualidade, latência e gastos.
Prompts influenciam diretamente o uso de tokens. Monitorar o custo por prompt e versão do prompt permite que as equipes vejam quais prompts são caros e se as mudanças recentes aumentaram ou reduziram os gastos. Isso se torna especialmente importante quando os prompts são compartilhados entre várias aplicações ou agentes.
Em sistemas baseados em agentes, a atribuição de custos deve ir além das chamadas de modelo individuais. As equipes precisam entender quanto custa uma execução completa de agente ou fluxo de trabalho de ponta a ponta, incluindo etapas de planejamento, chamadas de ferramentas e novas tentativas. Isso ajuda a identificar comportamentos ineficientes do agente precocemente.
Para plataformas internas e implantações empresariais, atribuir custos a usuários ou equipes permite a responsabilização e o orçamento. Essa dimensão é frequentemente necessária para impor limites de uso ou para apresentar os custos internamente.
Observar essas dimensões em conjunto permite que as equipes passem da análise de custos reativa para o controle proativo de custos.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

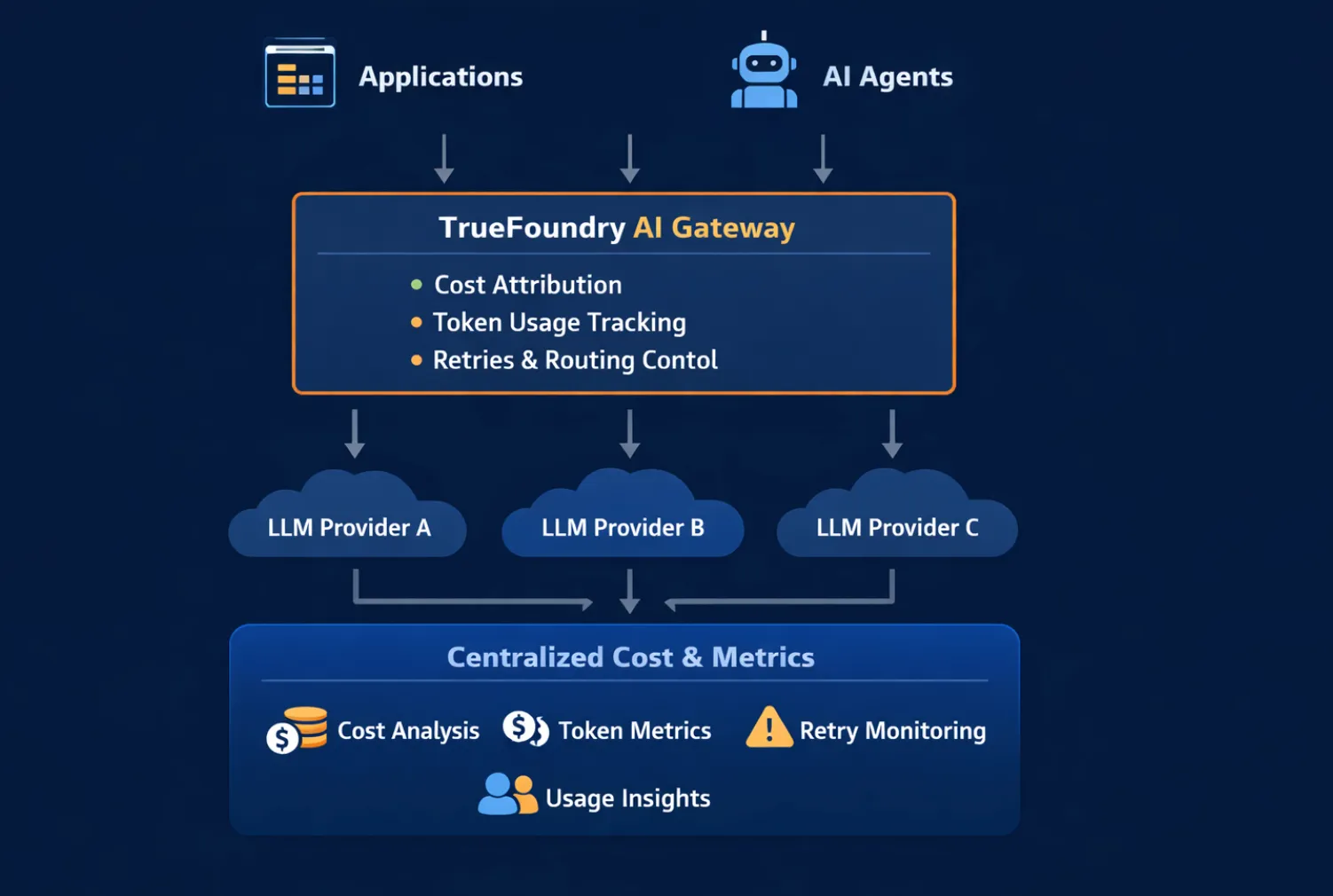
A observabilidade de custos de IA funciona melhor quando implementada em um ponto de intercepção central, onde todas as solicitações, decisões de roteamento e novas tentativas são visíveis. É por isso que os Gateways de IA desempenham um papel crítico.
Um Gateway de IA fica entre aplicativos ou agentes e provedores de modelo. Como cada solicitação passa por ele, o gateway pode:
Sem um gateway, os dados de custo são fragmentados entre SDKs, serviços e painéis de provedores. Com um gateway, o custo se torna um sinal de primeira classe que pode ser analisado e sobre o qual se pode agir antes que os gastos aumentem.
No TrueFoundry, o Gateway de IA fornece este ponto de controle centralizado, tornando possível observar e gerenciar os custos de IA em modelos, agentes e fluxos de trabalho de forma unificada.
Sistemas baseados em agentes amplificam tanto o poder quanto o custo das cargas de trabalho de IA. Ao contrário de aplicações de requisição única, os agentes executam fluxos de trabalho multi-etapas que podem envolver planejamento, raciocínio, novas tentativas e uso de ferramentas. Isso torna o comportamento de custos mais difícil de prever e mais importante de monitorar de perto.
Uma única execução de agente pode incluir:
Sem a observabilidade adequada, essas interações podem multiplicar os custos silenciosamente. Loops de agente, prompts mal restritos ou uso excessivo de ferramentas muitas vezes passam despercebidos até que o gasto total aumente significativamente.
A observabilidade de custos de IA para agentes requer visibilidade no nível de execução do agente, não apenas no nível de chamada de modelo. As equipes precisam entender:
É aqui que uma arquitetura baseada em gateway se torna especialmente valiosa. Ao capturar as requisições do agente no gateway, as equipes podem atribuir custos ao longo de todo o ciclo de vida de uma execução de agente, em vez de tratar cada chamada de modelo isoladamente.
No TrueFoundry, as implantações de agentes se integram com o AI Gateway, permitindo que as equipes observem os custos em todas as etapas e fluxos de trabalho do agente. Isso permite que as equipes de plataforma e aplicação detectem comportamentos ineficientes do agente precocemente e apliquem restrições antes que os custos disparem.
.svg)
No TrueFoundry, AI cost observability is implemented directly at the AI Gateway and agent execution layer, where all model requests, routing decisions, and retries are visible. This provides a unified and consistent view of cost across models, prompts, agents, and workflows.
Because every request flows through the gateway, TrueFoundry can:
This centralized approach turns cost from a passive metric into an operational signal. Teams can set alerts on abnormal spend, enforce budgets at the routing layer, and make cost-aware decisions when choosing models or fallback strategies.
For teams running production AI workloads, this ensures that cost remains predictable, explainable, and controllable, even as systems grow in complexity with more agents, models, and workflows.
AI cost becomes difficult to manage as soon as LLM applications move into production. Costs are no longer driven by a single model call, but by a combination of prompts, routing decisions, retries, agents, and tool usage. Without proper visibility, teams often discover cost issues only after spend has already increased.
AI cost observability addresses this by making cost a first-class signal. By attributing spend across requests, models, prompts, agents, and workflows, teams can understand not just how much they are spending, but why. This level of insight is essential for operating AI systems reliably at scale.
Gateway-based architectures play a central role in enabling this visibility. By capturing requests at a single control point, teams can observe, analyze, and control AI spend consistently across providers and execution paths. In TrueFoundry, this approach allows platform and application teams to detect inefficiencies early, enforce budgets, and balance cost with performance as AI workloads grow.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




