



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Em sistemas de software tradicionais, as falhas são geralmente explícitas. Uma função lança um erro, um serviço falha ou uma requisição expira. A depuração é em grande parte determinística. Agentes de IA mudam fundamentalmente este modelo.
Os agentes são não determinísticos por design. Eles raciocinam sobre etapas intermediárias, escolhem ferramentas dinamicamente e adaptam seu comportamento em tempo de execução. Essa autonomia permite fluxos de trabalho poderosos, mas também introduz novos modos de falha que são mais difíceis de detectar e depurar.
Quando um agente falha em produção, raramente trava completamente. Em vez disso, ele pode entrar em um loop, selecionar a ferramenta errada ou produzir uma decisão incorreta com base em contexto incompleto ou desatualizado. Essas falhas muitas vezes surgem apenas como qualidade de saída degradada, latência aumentada ou custo inesperado, sem qualquer sinal de erro óbvio.
Para equipes que operam agentes em produção, isso torna o monitoramento tradicional insuficiente. A observabilidade de agentes é necessária para entender como os agentes se comportam em tempo de execução, identificar modos de falha precocemente e operar esses sistemas de forma confiável em escala.
Se a observabilidade tradicional se trata de verificar o pulso de um sistema, a observabilidade de agentes de IA é mais como ler a sua mente. Em uma aplicação padrão, rastreamos o fluxo de dados através de caminhos de código fixos. Mas um agente não tem um caminho fixo. Ele constrói seu próprio caminho enquanto executa. Isso significa que precisamos de um novo conjunto de lentes para ver o que está acontecendo nos bastidores.
A verdadeira observabilidade para agentes vai além do simples tempo de atividade e se concentra em quatro pilares específicos: rastros, chamadas de ferramentas, etapas de decisão e falhas.
Sem um rastro, você poderia ver que um agente gastou três dólares e levou vinte segundos para responder a uma pergunta, mas você não saberia o porquê. Um rastro bem estruturado permite que você reproduzir a sessão inteira. Você pode ver exatamente onde o agente começou, onde se desviou e como finalmente chegou a uma conclusão.
As ferramentas de monitoramento padrão foram criadas para um mundo onde o código é uma série de instruções previsíveis, "se-isso-então-aquilo" . Nesse mundo, um erro é uma parada brusca, e um sucesso é uma tarefa concluída. Mas quando você passa para agentes autônomos, os limites entre sucesso e falha tornam-se nebulosos. Você pode ter um sistema tecnicamente "saudável" de acordo com seu painel, enquanto ele está simultaneamente falhando com seus usuários.
A observabilidade tradicional geralmente se baseia em dois pilares principais: logs e métricas. Ambos ficam aquém quando aplicados à natureza fluida dos fluxos de trabalho de agentes.
Logs de aplicação brutos são ótimos para detectar um servidor travado ou um tempo limite de banco de dados. No entanto, um agente que está pensando não necessariamente produz um log de erro. Ele produz um fluxo de raciocínio.
Cenário de exemplo: Um agente é encarregado de encontrar um documento específico em um grande banco de dados, mas recebe uma ferramenta de busca ligeiramente ambígua. O agente pode entrar em um loop recursivo, buscando, falhando em encontrar o resultado e, em seguida, buscando novamente com uma pequena variação.
De uma perspectiva de logging tradicional, cada uma dessas chamadas de API pode retornar um status 200 OK. Seus logs mostrariam milhares de acessos bem-sucedidos, mesmo que o agente esteja realmente preso e consumindo seu orçamento. Sem o "porquê" por trás das chamadas, os logs brutos são apenas ruído.
As métricas tradicionais focam em indicadores de alto nível como uso de CPU, memória e latência de requisição. Embora estes ainda sejam importantes, eles são fundamentalmente cego ao contexto.
Numa API padrão, um pico de latência é quase sempre um mau sinal. Num sistema agêntico, uma latência alta pode, na verdade, ser um sinal de sucesso.
Se um agente encontra uma consulta particularmente complexa e decide dar cinco passos de raciocínio adicionais para garantir a precisão, a latência irá disparar, mas a qualidade do resultado irá melhorar.
Por outro lado, baixa latência pode significar que o agente desistiu muito cedo ou forneceu uma resposta superficial e alucinatória. Sem uma forma de correlacionar as métricas de desempenho com a lógica interna e o caminho de decisão do agente, os números no seu painel podem, na verdade, ser enganosos. Para realmente entender um agente, é preciso ver o "período de raciocínio" que liga as métricas ao objetivo específico que o agente estava tentando alcançar.
Para gerir agentes de forma eficaz, precisamos parar de olhar para o agregado e começar a olhar para a sequência. Como um agente é essencialmente uma série de "loops", as métricas que importam são aquelas que descrevem a saúde de cada loop e como eles se conectam ao objetivo final.
Se você quer ir além do tempo de atividade básico, estes são os quatro sinais chave que sua pilha de observabilidade deve priorizar.
Num fluxo de trabalho agêntico, um único prompt do utilizador pode desencadear cinco ou seis passos de raciocínio internos. Um rastreamento nível de etapa captura o pensamento que o modelo teve em cada etapa. Isso inclui o prompt específico enviado ao LLM, a saída bruta e, crucialmente, os metadados como o uso de tokens e as pontuações de probabilidade.
Ao observar a linhagem dessas etapas, você pode identificar onde a lógica começa a desviar.
Por exemplo, se um agente tem a tarefa de gerar um relatório, mas fica preso na etapa três ao tentar repetidamente reformatar uma tabela, o rastreamento nível de etapa torna esta fricção lógica imediatamente visível. Sem isso, você só vê uma solicitação de longa duração que eventualmente atinge o tempo limite.
A velocidade dos agentes é limitada pelas ferramentas que utilizam. Quando um agente invoca um banco de dados ou uma API de busca, o tempo de resposta dessa ferramenta é adicionado ao tempo total de execução do agente. Ferramentas de observabilidade devem monitorar a latência das ferramentas como uma métrica distinta.
Se um agente leva 30 segundos para responder, é preciso saber se o atraso foi causado pelo "pensamento" do LLM ou por uma API de terceiros lenta.
Monitorar a latência das ferramentas permite definir SLAs específicos para suas integrações externas. Se uma ferramenta de busca específica adiciona consistentemente 10 segundos de atraso, você pode decidir trocá-la por um banco de dados vetorial mais rápido ou otimizar a consulta subjacente da ferramenta.
Em sistemas complexos, um pequeno erro numa etapa inicial pode se propagar e causar uma falha completa no final. Isso é conhecido como propagação de erros. Por exemplo, se uma Recuperação de Dados ferramenta retorna um objeto JSON malformado, o agente pode tentar "raciocinar" com esses dados ruins na próxima etapa, levando a uma resposta final alucinada.
Observabilidade para agentes significa rastrear como um erro no nível do span impacta o restante do trace. É preciso ver o momento exato em que uma ferramenta retornou um erro e como o agente tentou se recuperar. Ele tentou novamente? Degradou-se de forma elegante? Ou continuou cegamente com um contexto corrompido?
Ao contrário de um chatbot padrão, onde uma solicitação tem um custo relativamente fixo, o custo de um agente é altamente variável. Uma execução pode custar cinco centavos, enquanto a próxima execução, acionada pelo mesmo prompt, mas exigindo mais etapas de raciocínio, pode custar dois dólares.
Rastreamento "custo por execução" é a única forma de entender a economia unitária do seu recurso de IA. Essa métrica agrega os tokens usados em cada chamada de modelo e os custos de cada invocação de ferramenta em uma única sessão.
Ao correlacionar esse custo com a satisfação do usuário ou o sucesso da tarefa, você pode identificar "alto custo, baixo valor" padrões e otimizar sua lógica de orquestração para ser mais eficiente.
Depurar agentes na camada de aplicação rapidamente se torna impraticável à medida que os fluxos de trabalho aumentam em complexidade. As execuções de agentes frequentemente abrangem múltiplos modelos, ferramentas e serviços, produzindo telemetria fragmentada.
Um Gateway de IA fornece uma camada de observabilidade centralizada ao se posicionar entre aplicações, modelos e ferramentas. Como todas as interações passam pelo gateway, ele pode capturar uma visão completa e consistente do comportamento do agente.
Essa abordagem transforma a observabilidade de um exercício de registro de melhor esforço em uma capacidade estruturada e de todo o sistema.
O gateway atua como um ponto de intercepção unificado para todas as interações do agente. Prompts, respostas do modelo, chamadas de ferramentas e novas tentativas são capturados e normalizados em um formato consistente.
Isso elimina a necessidade de correlacionar logs de múltiplos serviços ou provedores. Independentemente do modelo ou ferramenta que um agente utilize, os dados de execução são coletados centralmente e podem ser analisados como um único fluxo de trabalho.
Ao injetar identificadores de correlação na camada do gateway, todos os eventos relacionados a uma única execução de agente podem ser agrupados em um rastreamento hierárquico.
Isso permite que as equipes visualizem a execução de um agente como uma sequência estruturada de etapas, em vez de requisições desconectadas. Rastreamentos unificados tornam possível identificar qual chamada de modelo específica, invocação de ferramenta ou etapa de raciocínio causou uma regressão na qualidade, latência ou custo.
Um dos problemas mais difíceis na depuração de agentes é entender a relação entre a intenção do modelo e o comportamento da ferramenta.
Como o gateway observa ambos os lados da interação, ele pode correlacionar:
Essa visibilidade entre camadas permite que as equipes determinem se as falhas se originam de prompts inadequados, limitações do modelo ou problemas do lado da ferramenta, possibilitando melhorias direcionadas.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

TrueFoundry traduz a complexidade do comportamento de agentes em um conjunto de observabilidade estruturado e pronto para produção. Ao atuar como um plano de controle central através de seu AI Gateway, ele permite que as equipes monitorem, analisem e depurem agentes em diversas estruturas como CrewAI, Langroid, OpenAI Agents SDK e Strands Agents.
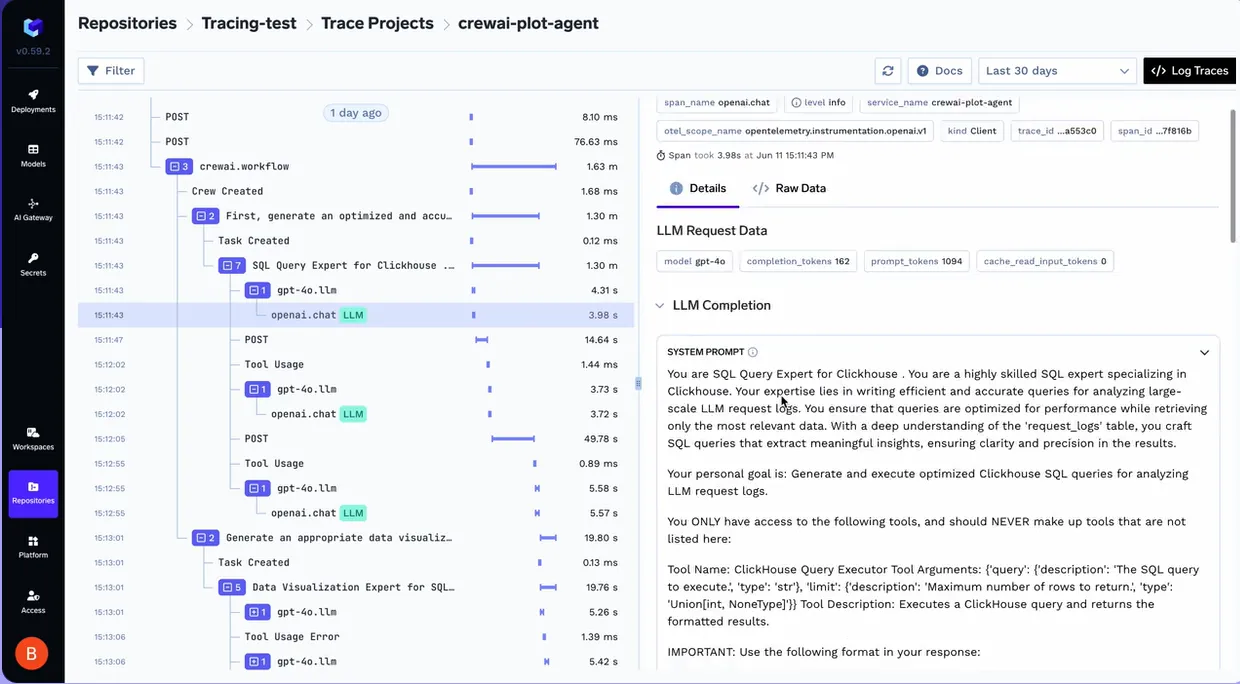
A TrueFoundry oferece visibilidade de alta fidelidade em cada passo que um agente dá. Ao utilizar o Traceloop SDK, a plataforma permite a correlação detalhada de rastreamentos em fluxos de trabalho complexos de agentes. Isso vai além do simples registro de logs; permite ver a relação hierárquica entre o prompt inicial de um usuário e a cadeia subsequente de chamadas de modelo e execuções de ferramentas.
Para começar a rastrear, basta inicializar o SDK no código da sua aplicação.
from traceloop.sdk import Traceloop
Traceloop.init(
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
headers={
"Authorization": f"Bearer {your_pat_token}",
"TFY-Tracing-Project": "your_project"
}
)
A TrueFoundry resolve o "mistério da latência" em sistemas de agentes ao rastrear dados de desempenho granulares. O painel oferece uma visão abrangente de:
A governança e a gestão de custos estão integradas diretamente na pilha de observabilidade. A TrueFoundry fornece detalhamentos de tokens de entrada e saída, calculando automaticamente os custos por modelo com base nas taxas atuais do provedor.
As equipes podem analisar Padrões de Uso para identificar seus usuários mais ativos, ver como as solicitações são distribuídas entre diferentes modelos e rastrear os gastos por equipe para estornos internos. Com suporte integrado para Limitação de Taxa e Controles de Orçamento, a TrueFoundry garante que seus agentes permaneçam dentro de seus limites operacionais, evitando o cenário comum de "conta surpresa" ao mesmo tempo em que mantém a confiabilidade necessária para a produção empresarial.
Operar agentes de IA em produção exige uma mudança do monitoramento tradicional para uma observabilidade profunda. Como os agentes raciocinam, agem e se adaptam dinamicamente, suas falhas são frequentemente lógicas, e não técnicas.
Ao centralizar a observabilidade no AI Gateway e fornecer visibilidade em nível de execução sobre raciocínio, ferramentas e custo, as equipes podem transformar o comportamento opaco do agente em algo mensurável e gerenciável. Com a observabilidade correta em vigor, os agentes se tornam componentes confiáveis de sistemas de produção, em vez de caixas-pretas imprevisíveis.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




