














May 8, 2024
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
LLMが重要なアプリケーションを動かす時代において、その内部動作の可視性は不可欠です。LLMオブザーバビリティは、トークン使用量、プロンプトのパフォーマンス、エラー率、レイテンシ、コスト指標などの推論レベルのデータを捕捉・分析し、それをユーザーインタラクションと関連付ける実践です。これは、CPU使用率や応答時間といったインフラストラクチャのメトリクスを主に追跡する従来のモデル監視を超えたものです。TrueFoundryのAI Gatewayは、プロンプトのバージョン管理、構造化ロギング、リアルタイム分析ダッシュボード、異常アラートを備えた包括的なオブザーバビリティレイヤーを組み込み、LLMパイプラインのあらゆる段階で、実用的なインサイトを明らかにし、パフォーマンスを最適化し、コストを管理します。
LLMオブザーバビリティとは、言語モデルパイプラインにおけるすべての推論イベントをエンドツーエンドで計測、収集、分析する実践です。これは2つの主要なレイヤーで構成されています。
インタラクティブ分析
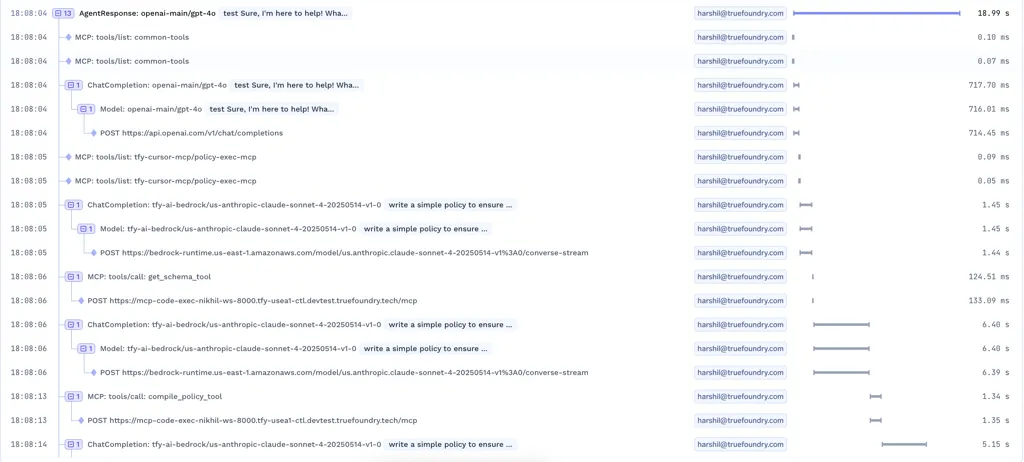
一元化されたダッシュボードには、トークン使用量、リクエスト量、コストに関するリアルタイムのメトリクスが表示されます。各モデルのレイテンシパーセンタイル(P50、P90、P99)と合わせて、累積入力・出力トークン、合計リクエスト数、トークンコストを確認できます。グラフでは、1秒あたりのリクエスト数、エラー率、ユーザーレベルの消費量、モデルごとのコスト内訳が明らかになります。フィルターを使用すると、レート制限、フォールバック、ロードバランシングの影響を受けた呼び出しを特定し、どのルールが適用されたかを確認できます。
[SEG 8]
メタデータ駆動型コンテキスト
各リクエストには、X-TFY-METADATAヘッダーを介して、環境(開発、ステージング、本番)、機能名、ユーザーID、チーム、またはあらゆるビジネスコンテキストなどのカスタムタグを含めることができます。メタデータにより、以下のことが可能になります。
チームや機能全体での使用状況監視
詳細な分析やアーカイブのために、TrueFoundryはリクエストに応じてログとトレースの構造化JSONエクスポートをサポートしており、これにより、パフォーマンス、コスト、使用パターンをオフラインで調査できます。
これらの機能が連携することで、チームはモデルの動作、コスト要因、潜在的な問題について完全な可視性を得られ、信頼性が高く最適化されたLLMデプロイメントが保証されます。
LLMオブザーバビリティ vs. 従来のモデルオブザーバビリティ
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
対照的に、LLMオブザーバビリティは、各推論のセマンティクスと経済性に深く踏み込みます。大規模言語モデルは可変長の入力を処理し、コンテンツをトークンごとに生成するため、その動作を理解するには、コンテンツを意識した計測が必要です。
トークンメトリクス vs. 固定スループット
従来のモデルは1秒あたりのリクエスト数をカウントしますが、LLMは入力および出力トークンを追跡します。オブザーバビリティは、累積トークン量、トークンコスト、モデルごとのトークン使用量を捕捉します。これにより、特定のユーザーや機能に支出を帰属させ、コストがエスカレートする前に暴走プロンプトを検出できます。
プロンプト・応答ロギングとブラックボックス予測
標準的なMLオブザーバビリティのログは、エンドポイントへのアクセスやステータスコードなどのメタデータのみを記録します。LLMオブザーバビリティは、環境、機能、ユーザーIDなどのコンテキストメタデータとともに、プロンプトと応答の完全なペアを記録します。これにより、ハルシネーションや品質低下の原因を特定のプロンプトテンプレートやユーザーコホートにまで遡って特定できます。
レイテンシーのパーセンタイルと平均
従来のシステムでは、平均レイテンシーが報告されることがよくあります。LLMダッシュボードでは、トークンごとの生成が平均指標では隠れてしまうようなロングテール遅延を引き起こす可能性があるため、モデルごとにP50、P90、P99のレイテンシーパーセンタイルが表示されます。
設定駆動型の影響
LLMでは、レート制限、ロードバランシング、フォールバックルールなどの制御が動作に影響を与えます。オブザーバビリティは、これらのルールによって影響を受けたリクエスト(例:レート制限された呼び出し、再ルーティングされた呼び出し、別のプロバイダーにフォールバックされた呼び出し)にフラグを立て、チームがポリシーを微調整できるようにします。
リアルタイム分析と事後ログ
従来のオブザーバビリティが定期的なログ分析に依存する一方で、TrueFoundryのAI GatewayのようなLLMオブザーバビリティプラットフォームは、リアルタイムのフィルタリングとトレンド探索のためのインタラクティブなダッシュボードを提供し、メタデータタグでメトリクスをその場で細分化できます。
要するに、従来のオブザーバビリティは「サービスインフラは健全か?」という問いに答えます。LLMオブザーバビリティは、「各トークンはどのように、いつ、なぜ生成されるのか、そしてそれがコスト、パフォーマンス、出力品質にどのような意味を持つのか?」を説明します。
LLMに堅牢なオブザーバビリティを実装することは、パフォーマンスを維持し、コストを管理し、高品質な出力を確保するために不可欠です。これらの主要な柱は連携して、チームにあらゆる推論イベントに対する完全な可視性を提供します。これらを理解し適用することで、LLMのデプロイメントを効果的に監視、診断、最適化できます。
1. インタラクティブ分析
統合ダッシュボードは、LLMワークロードのあらゆる側面に関するリアルタイムの洞察を提供します。累積およびモデルごとの入出力トークン量、総リクエスト数、トークンベースのコストを追跡できます。P50、P90、P99といった詳細なレイテンシーパーセンタイルは、パフォーマンス特性を明らかにします。1秒あたりのリクエスト数とエラー率のグラフは、異常を特定するのに役立ちます。フィルターを使用すると、レート制限、ロードバランシングルール、またはフォールバックによって影響を受けた呼び出しをドリルダウンして、的を絞ったトラブルシューティングを行うことができます。
2. メタデータ駆動型コンテキスト
環境(開発、ステージング、本番)、機能名、ユーザーID、チームなどのカスタムメタデータを各リクエストに付加することで、メトリクスを細かく分析する能力が得られます。メタデータは、コホート全体の詳細な使用状況監視を可能にし、レート制限やモデル選択のための条件付き制御を推進し、監査やコンプライアンスのための正確なログフィルタリングを可能にします。メタデータは、OpenAIまたはLangChain SDK、RESTリクエスト、またはcURL呼び出しで単一のX-TFY-METADATAヘッダーを介して渡します。
3. 包括的なロギング
すべての推論は、完全なプロンプトと応答のペア、トークン数、レイテンシーの詳細、エラーコード、および添付されたメタデータを含む構造化された形式でログに記録されます。この詳細レベルにより、ハルシネーション、品質低下、またはパフォーマンスの異常に対する根本原因分析を行うことができます。プロンプトのバージョンを比較したり、テンプレートの変更が出力品質にどのように影響するかを監視したり、特定ユーザーのコホートや機能に問題を遡って特定したりできます。
4. ログのエクスポートと監査
より詳細なオフライン分析やアーカイブのために、TrueFoundryはログとトレースの構造化されたJSONエクスポートをサポートしています。管理者は、指定された期間でサポートを介してエクスポートをリクエストするだけです。エクスポートされたデータは、カスタム分析、コンプライアンスレポート、または長期保存を可能にします。
これらの柱が連携することで、コスト要因、パフォーマンスプロファイル、出力品質に関する完全な透明性を提供し、LLMのデプロイメントが信頼性、効率性、費用対効果を維持することを保証します。
以下に4つの 優れたLLM可観測性ツール、それぞれの概要を簡単に説明します。
TrueFoundryのAI Gatewayは、LLM向けの統合されたエンタープライズグレードの可観測性およびガバナンスソリューションを以下の機能とともに提供します。
リアルタイムメトリクス
.webp)
インタラクティブなダッシュボードには、累積およびモデルごとの入出力トークン数、総リクエスト量、モデルおよびユーザーごとのコスト内訳、詳細なレイテンシーパーセンタイル(P50、P90、P99)が表示されます。また、1秒あたりのリクエストヒートマップ、エラー率の傾向、障害やレイテンシーの急増を検出するための設定可能な異常アラートも提供されます。
メタデータ駆動型インサイト
{
"tfy_log_request": "true", //Whether to add a log/trace for this request or now
"environment": "staging", // THe environment - dev, staging or prod?
"feature": "countdown-bot" //Which feature initiated the request?
}
単一のX-TFY-METADATAヘッダーを介して、ビジネスコンテキスト(環境、機能、ユーザー、チーム)でリクエストをタグ付けします。メタデータでダッシュボードとログをスライスし、環境を比較したり、機能の使用状況を分離したり、ユーザーやチームのアクティビティを監査したりできます。
コードとしてのポリシー制御
YAML駆動のレート制限ルール(例:「開発環境向けにGPT-4呼び出しを1日1000回」)、プロバイダー間のロードバランシングウェイト、およびエラー発生時のフォールバックチェーンを定義します。
GitOpsワークフローを介して管理されるバージョン管理されたポリシー定義により、プルリクエストレビュー、CI検証、およびロールバックが可能になります。
包括的なロギングとトレース

完全なプロンプトと応答のペア、トークンレベルの内訳、レイテンシー、エラーコード、適用されたポリシーIDを含む構造化されたJSONログを保存します。分散トレース全体で相関付けを行い、多段階ワークフローやRAGパイプラインをデバッグします。
エクスポートとコンプライアンス:
ログとトレースをJSON形式でオンデマンドエクスポートし、オフライン分析、長期保存、または規制監査に利用できます。組み込みのRBACと監査証跡により、許可されたユーザーのみが機密データを閲覧またはエクスポートできることが保証されます。
これらの機能により、TrueFoundryは、LLMデプロイメントにおいてエンドツーエンドの可視性、きめ細かなコスト管理、ポリシーアズコードによるガバナンス、および堅牢な監査可能性を必要とするチームにとって、際立った選択肢となります。
LangSmithは、LangChainベースのアプリケーション向けに、詳細なトレースとデバッグに特化しています。チェーンの各ステップを自動的にキャプチャし、プロンプト入力、中間出力、最終応答をログに記録します。開発者は、インタラクティブなトレースビジュアライザーを使用して、プロンプトテンプレートを時系列で比較し、パフォーマンスの低下を特定し、関数呼び出しを詳細に調べることができます。また、LangSmithは、トークン使用量やチェーンステップごとのレイテンシなどのランタイムメトリクスを記録し、機能追跡のためにカスタムメタデータを添付することも可能です。組み込みの実験管理機能により、実行にタグを付けたり、モデルバージョン間で出力品質を比較したり、実績のある構成にロールバックしたりできます。開発者の使いやすさとチェーンの透明性に重点を置いているため、迅速なイテレーションとデバッグに最適です。
Heliconeは、生成AIに特化したAPI中心の可観測性プラットフォームを提供します。OpenAI、Anthropic、またはその他のエンドポイントへのすべてのAPI呼び出しを記録し、完全なプロンプトテキスト、応答、トークン使用量、およびタイミングの詳細をキャプチャします。Heliconeのダッシュボードは、呼び出しごとのコスト、最も使用されているプロンプトテンプレート、およびエラー分布を強調表示し、高コストまたは障害が発生しやすいパターンを特定するのに役立ちます。組み込みのトラフィックシェーピングの視覚化により、レート制限とクォータがスループットにどのように影響するかが明らかになり、コストの急増やエラー率の上昇に対してアラートを設定できます。軽量なSDK統合により、Heliconeは支出とパフォーマンスに関する迅速な洞察を提供し、APIコスト管理とプロンプト最適化に注力するチームにとって優れた選択肢となります。
Lunaryは、LLMの可観測性においてシンプルさと開発者エクスペリエンスに重点を置いています。最小限の設定でOpenAIおよびAnthropic SDK呼び出しを自動計測し、プロンプトの履歴、トークンメトリクス、応答時間をログに記録します。そのダッシュボードは、バージョン管理されたプロンプトテンプレートと出力品質の回帰検出を表示し、変更が予期しない結果をもたらした場合にアラートを発します。Lunaryは、実験やA/Bテストにタグを付けるためのアノテーションAPIも提供しており、実行間の明確な比較を可能にします。軽量でありながら、レート制限とフォールバックルーティングのための条件付き制御をサポートしています。Lunaryは、セットアップの容易さとコアな可観測性機能に重点を置いているため、複雑な統合なしにモデルの動作に関する迅速なフィードバックを必要とする小規模チームやプロトタイプに最適です。
可変的なトークン使用量: LLMはトークンごとに結果を生成するため、各リクエストで消費されるトークン数は大きく異なる場合があります。プロンプトやユーザー間でトークン量が大きく変動すると、コストの監視と帰属が複雑になります。きめ細かなトークン追跡がなければ、チームは予期せぬ請求の急増や、気づかれない非効率なプロンプトのリスクを負うことになります。
大量のデータ: すべての推論について、完全なプロンプトと応答のペア、トークンメトリクス、レイテンシの詳細、およびメタデータをキャプチャすることは、毎日数百万のログエントリを生成する可能性があります。この量の構造化データを保存、インデックス作成、クエリするには、可観測性パイプラインにおけるパフォーマンスのボトルネックを回避するために、スケーラブルなストレージソリューションと最適化されたクエリエンジンが必要です。
文脈の複雑さ: LLMの動作は、プロンプトの表現、温度設定、モデルバージョンに大きく依存します。出力品質やレイテンシの変化を特定のプロンプト編集や設定調整と関連付けるには、堅牢なトレースリンクとバージョン管理が必要です。影響要因の複雑な絡み合いを解きほぐすには、チームは一貫したメタデータタグ付けとプロンプトのバージョン管理を実装する必要があります。
マルチプロバイダー間の相関: 多くのデプロイメントでは、負荷分散やコスト最適化のために複数のLLMプロバイダーを使用しています。OpenAI、Azure、Anthropic、およびその他のエンドポイントからのメトリクスを統合されたビューに集約するには、異なるAPI、応答形式、およびコスト構造を正規化する必要があります。これらのストリームを統合できないと、断片的な洞察と、プロバイダー間のパフォーマンス比較における盲点が生じます。
リアルタイムアラートとノイズ: 自然な変動が頻繁に発生する環境では、エラー率、レイテンシーの急増、コスト異常などに対して意味のあるアラートしきい値を設定することは困難です。感度が高すぎるアラートはアラート疲れにつながり、しきい値が高すぎると、重大な問題の検出が遅れる可能性があります。チームは、通常の使用パターンを学習し、しきい値を動的に調整する適応型のアラート戦略を必要としています。
コンプライアンスとプライバシー: 会話ログ全体を保存することは、データプライバシー規制や社内セキュリティポリシーと衝突する可能性があります。可観測性データの必要性と、データ最小化、暗号化、アクセス制御の要件とのバランスを取るには、慎重なポリシー定義と、選択的なログの編集または匿名化のためのツールサポートが必要です。
これらの課題に対処するには、使用量に応じて拡張可能で、一貫したメタデータプラクティスを強制し、マルチプロバイダーデータを正規化し、最も重要な問題のみを浮上させるインテリジェントなアラートを提供する堅牢な可観測性フレームワークが必要です。
実際のシステムでは、LLMリクエストが単一のモデル呼び出しであることは稀です。それは一連のステップで構成されています。
ユーザー入力はプロンプトになり、そのプロンプトがコンテキストを取り込みます。モデルが応答し、その応答がツールをトリガーします。ツールの結果はモデルにフィードバックされ、その後初めてユーザーは回答を目にします。各段階には繰り返し発生する LLM推論、そのためトレースは最終出力だけでなく、すべての中間決定を捕捉する必要があります。
適切なトレースはこれを可視化します。
チームは以下を把握する必要があります。
これがなければデバッグは当て推量になります。これがあれば、チームは何が起こり、どこで問題が発生したかを正確に追跡できます。
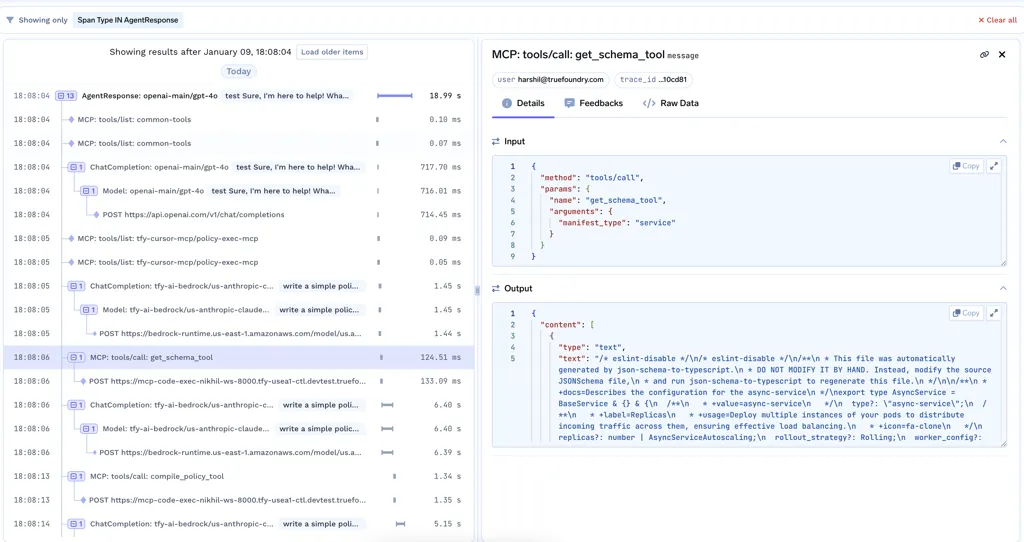
多くのチームにとって、コストは最初の本当の警鐘です。LLMのコストはインフラコストのように増加しません。トークン、冗長性、リトライ、隠れた中間ステップとともに増加します。小さなプロンプトの変更や、誤動作するエージェントが、気づかないうちに二重に費用を発生させる可能性があります。
これが、トークンレベルの可視性が重要である理由です。
チームは以下を理解する必要があります。
トークンデータがトレースと紐付けられると、コストは予期せぬものではなくなり、管理可能なものとなります。
LLMがツールを呼び出し始めると、システムはより強力になる一方で、より脆くなります。エージェントはデータベースを検索したり、APIを呼び出したり、ワークフローをトリガーしたりできます。MCPを使用すると、これらのツールは動的に発見され、呼び出されるため、システムはより柔軟になりますが、その動作を理解するのが難しくなります。
本番環境では、チームは基本的な質問に対して明確な答えを必要とします。
可観測性が LLM可観測性ツールのレベルでなければ、チームはすぐに信頼を失います。それがあれば、動作を監査し、障害をデバッグし、エージェントベースのシステムを安全にスケールできます。
目標はより良いダッシュボードではありません。信頼です。実際には、ここで LLMOps が重要になります。なぜなら、可観測性データはデプロイメントの決定、コスト管理、モデルガバナンスに継続的に供給されなければならないからです。チームがトレース、トークン使用量、ツールの動作を明確に確認できると、問題を早期に発見し、コストを管理し、実際の運用データに基づいて品質を向上させることができます。
これによりループが生まれます。本番環境で何が起こっているかを観察し、そこから学び、システムを改善し、繰り返すというものです。のようなプラットフォーム TrueFoundryのAI Gateway チームがこれを実現できるよう、トレーシング、メトリクス、ガバナンスを1か所に集約し、LLMシステムをその重要インフラとして扱えるように支援します。
LLMオブザーバビリティを導入することで、不透明な推論パイプラインは透明で管理しやすいシステムへと変貌します。インタラクティブな分析、メタデータ駆動のコンテキスト、動的なポリシー制御、包括的なロギング、シームレスなログエクスポートを組み合わせることで、チームはパフォーマンスの監視、コストの管理、出力品質の維持に必要なインサイトを得ることができます。可変的なトークン使用量、データ量、複数プロバイダー間の相関といった課題には、スケーラブルなアーキテクチャと厳格なメタデータ管理が求められますが、統合されたオブザーバビリティソリューションがあれば、異常を早期に検出し、効果的にトラブルシューティングを行い、自信を持ってプロンプトを反復改善できます。今日のAI主導の状況において、堅牢なLLMオブザーバビリティはオプションではなく、信頼性が高く、費用対効果の高いアプリケーションを大規模に提供するために不可欠です。
TrueFoundryがLLMオブザーバビリティの改善にどのように役立つか、デモを予約してご確認ください。
AIにおけるオブザーバビリティとは、システムのテレメトリーと出力を調査することで、その内部状態を理解する能力を指します。トレーシング、メトリクス、ログを分析することで、チームはリアルタイムでパフォーマンスの問題を診断できます。これにより、複雑なデプロイメントが透明性、信頼性を保ち、意図されたビジネス目標と密接に連携していることを保証します。
LLMオブザーバビリティの5つの柱には、インタラクティブな分析、メタデータ駆動のコンテキスト、包括的なロギング、評価、ログエクスポートが含まれます。これらの要素は、トークンの消費量、コスト、応答品質に関する可視性を提供します。これらを組み合わせることで、エンジニアリングチームはLLMアプリケーションを効果的に監視、トラブルシューティング、最適化できます。
モデルに関する深いインサイトを得るための人気プラットフォームには、LangSmith、Helicone、Arize Phoenixなどがあります。データ主権を優先する組織にとって、TrueFoundryは自社インフラ内でLLMオブザーバビリティを実装する強力な方法を提供します。これらのツールは、開発者が推論チェーンをデバッグし、コストを追跡し、応答の高い出力品質を維持するのに役立ちます。
従来のモニタリングは、レイテンシーやエラー率などの既知のメトリクスを追跡し、インフラストラクチャの健全性を維持します。LLMオブザーバビリティは、セマンティックトレーシングを使用して、特定の問題が発生する理由を説明します。モニタリングがシステム障害を単に通知するのに対し、オブザーバビリティは根本原因を見つけて修正するために必要な詳細なデータとコンテキストを提供します。
TrueFoundryは、アプリケーションレベルのトレーシングとインフラストラクチャモニタリングを、お客様自身のセキュアなVPC内で統合するという点でユニークです。複数のプロバイダーにわたる高トラフィックを処理しながら、10ミリ秒未満のレイテンシーを維持します。この統合により、LLMオブザーバビリティの取り組みは費用対効果が高く安全であると同時に、すべてのモデルインタラクションに関する詳細なインサイトを提供します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。





.webp)




.png)








.webp)
.webp)


