













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
要点 TrueFoundryとSeldonは一つのプラットフォームとして統合されます。SeldonのリアルタイムMLサービングがTrueFoundryのAI DeployおよびAI Gatewayと統合され、これにより企業は従来のMLとエージェントの両方に対応する単一のコントロールプレーンを手に入れます。本番環境のモデルは、現在お使いのKubernetes上で引き続き稼働し、その上でLLMやAIエージェントへの明確な道筋が得られます。
ほとんどのエンタープライズAIチームは現在、一つの境界線の両側で活動しています。不正スコアリング、顧客離反予測、レコメンデーションなどのために、従来のMLモデルを本番環境で運用しています。同時に、推論し、ツールを呼び出し、自律的に動作するエージェントアプリケーションを構築しています。これら二つの世界は、かつては異なる速度で進化していましたが、もはやそうではありません。両方とも同時にビジネス上不可欠なものとなっており、これらを二つの異なるスタック、二つのベンダー、二つのガバナンスモデルで運用することは、すぐにコストがかさみ、脆弱になります。
それが、TrueFoundryとSeldonが共に埋めようとしているギャップです。Seldonは、世界で最も要求の厳しい企業の一部向けに、リアルタイムMLサービングを10年以上にわたり完璧なものにしてきました。TrueFoundryは、デプロイメント、AI Gateway、LLMおよびエージェントのガバナンスを備えた、最新のAIを中心としたコントロールプレーンを構築しました。私たちはこの二つを一つのプラットフォームに統合することで、チームがすでに信頼しているKubernetes基盤上で、予測モデルとエージェントを運用できる単一の場所を提供します。
この統合がうまくいくのは、どちらの側もその設計を諦める必要がないからです。SeldonとTrueFoundryは、数年前に同じアーキテクチャ上の選択をしていました。両者とも、顧客自身のKubernetes上で、VPC内、オンプレミス、またはエアギャップ環境でコントロールプレーンとして動作します。両者ともクラウドに依存しません。両者とも、トラフィック、オートスケーリング、テレメトリーに同じ標準コンポーネントを使用し、クラスター全体の管理者権限を要求するのではなく、チームに独自のネームスペースを提供します。
Seldonはその共通基盤を基に、一つのレイヤーに深く特化し、従来のMLをリアルタイムで大規模に提供してきました。私たちは同じ基盤を基に、デプロイメントからモデル、エージェント、ツールを管理するゲートウェイまで、幅広く展開しました。そのため、二つのプラットフォームが衝突することは決してありませんでした。両者は同じ問題の隣接する部分を、同じ方法で解決していたのです。これらを統合することは、すでに同じ言語を話す二つのレイヤーを結びつけることに他なりません。
Seldonは10年以上にわたり、銀行、通信会社、保険会社、小売業者、ヘルスケア企業におけるリアルタイムML推論のバックボーンとなってきました。その評判は、本番環境でのMLサービングの最も困難な部分に深く取り組んできたことに由来します。
これらを合わせると、規制の厳しい低遅延環境に深く根ざした、成熟したサービングおよびモニタリング層となります。そこでは、誤った予測が数分以内に顧客の問題に発展する可能性があります。
TrueFoundryは、デプロイされたモデルを、管理され、コストを意識し、エージェント対応のアプリケーションへと変える層、すなわちモデルを中心としたコントロールプレーンを構築しました。
弊社のお客様はすでに、1日あたり1兆トークンを超える規模で、ゲートウェイを通じてビジネスに不可欠なAIを運用しています。
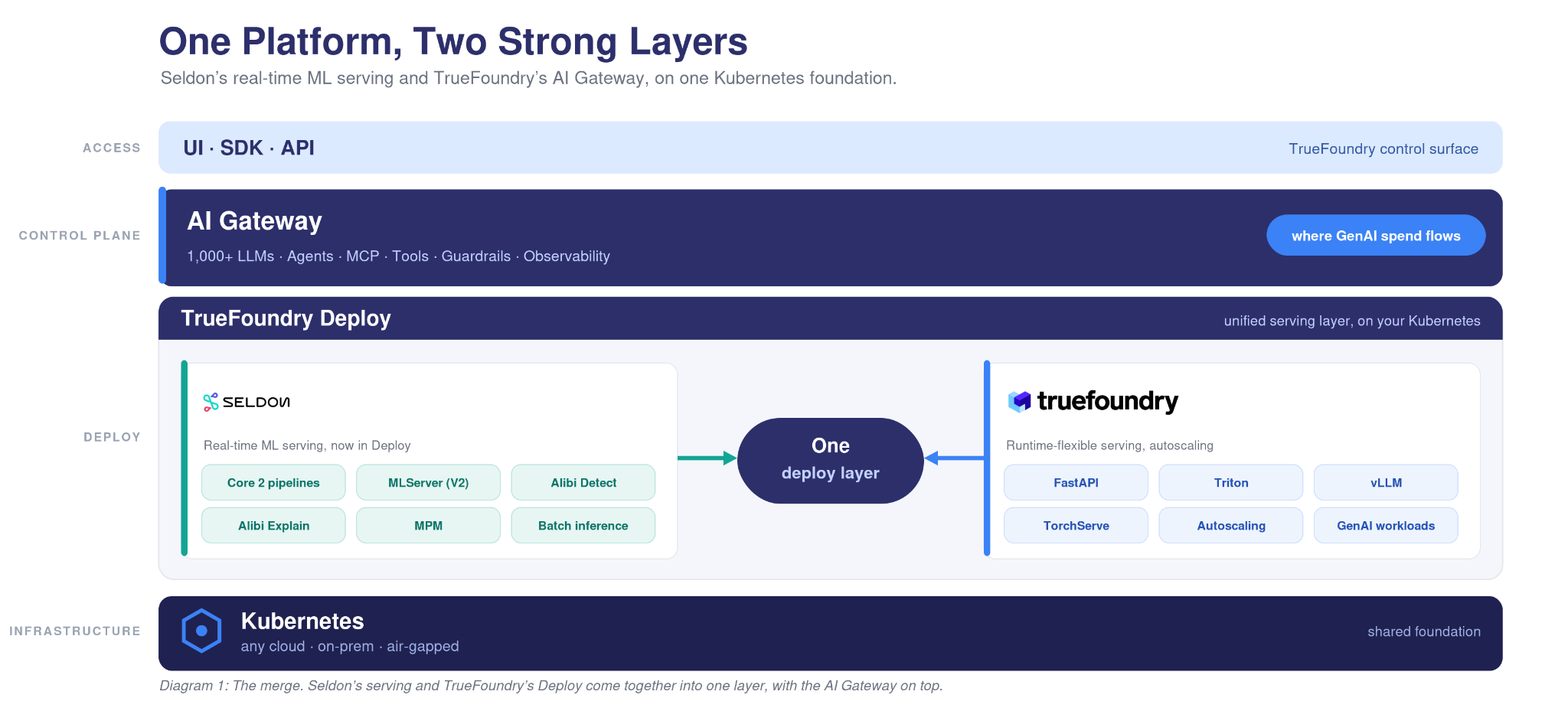
ここが重要な点です。Seldonのサービング層とTrueFoundryのデプロイ層およびゲートウェイ層が統合されることで、企業はAIの両側面をカバーする単一のコントロールプレーンを手に入れることができます。
Deployはワークロードを実行し、Gatewayはそれらを管理・ルーティングします。従来のMLモデルとエージェントは同じKubernetes上に配置され、単一のアクセス制御、単一の可観測性スタック、および単一のコストビューの下で運用されます。単一のリクエストが不正検出モデル、LLM、およびツールを呼び出すエージェントに到達することができ、すべてのホップは同じ方法でログに記録され、管理されます。
資金がどこに流れているかを見ると理解が深まります。予測MLはほとんど構築済みで安定して稼働していますが、企業のAIへの新たな投資はLLMとエージェントに向かっており、その支出はGatewayを通じて行われます。すべてのモデル呼び出し、すべてのエージェントステップ、すべてのツール呼び出しがGatewayを通過するため、弊社のお客様はすでに1日あたり1兆トークン以上をGateway経由で処理しています。
したがって、この統合プラットフォームは2つの有用なことを同時に実現します。既に構築済みのMLを中断なく稼働させ続けるとともに、別のプラットフォームを立ち上げることなく、次のAI投資の波が押し寄せる最前線にあなたを置きます。
現在Seldonをご利用の場合、 お客様のリアルタイムMLは、既存のKubernetes上で引き続き稼働します。V2プロトコルで提供されるモデルはポータビリティを維持し、Core 2パイプラインは、書き換えられることなくDeploy独自のプリミティブにマッピングされます。さらに、AI Gatewayとエージェントレイヤーを新たに構築することなく利用できます。
現在TrueFoundryをご利用の場合、 お客様のスタックに変更はなく、Deployはさらに強化されます。Seldonのサービングおよびモニタリングの系譜(ドリフト検出、外れ値検出、モデルの説明、パフォーマンス監視など)が、お客様が既にお使いのプラットフォームに直接統合されます。
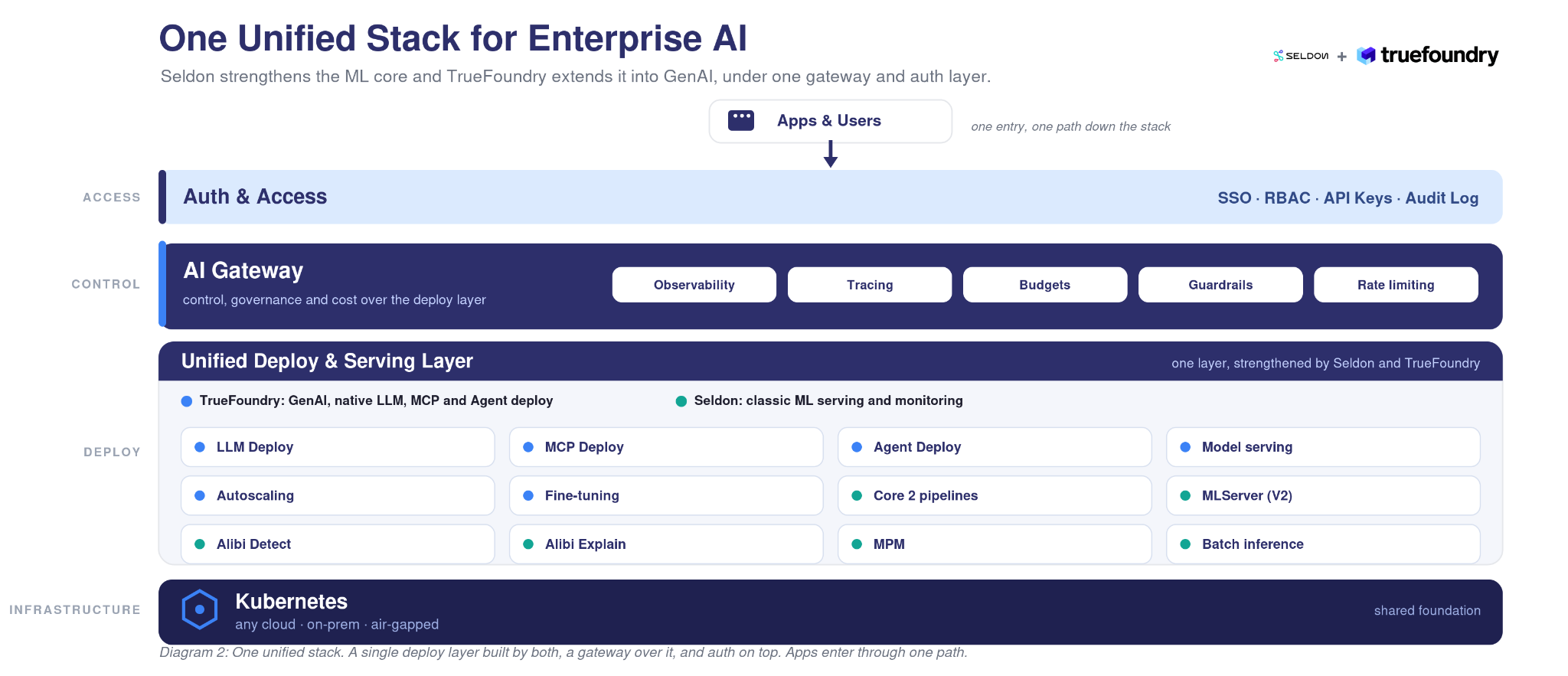
どちらの場合も、2つではなく1つのスタックになります。既存のインフラストラクチャ上で、従来のMLとGenAIの両方において、モデルのデプロイ、呼び出しのルーティング、ドリフトの監視、エージェントの管理、コストの把握をすべて一箇所で行えます。
企業は、モデル用とエージェント用で別々のプラットフォームを運用する必要はありません。TrueFoundryとSeldonが統合されたことで、その必要がなくなりました。SeldonのリアルタイムMLサービングとTrueFoundryのAI Gatewayは、お客様が既にお使いのKubernetes上で、エンタープライズAIのための単一のコントロールプレーンとして機能します。お客様のプロダクションMLは引き続き稼働し、エージェントやLLMへの道筋もその上に開かれています。
TrueFoundryのAI GatewayがMLとエージェントをどのように統合するかを見る → AI Gatewayを詳しく見る
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


It is a single layer that lets a company deploy, run, observe, and govern all of its AI in one place, from classic ML models to LLMs and agents. Instead of a different tool for each workload, you get one control point for deployment, access, guardrails, cost, and monitoring, running on infrastructure you control.
Yes. Your models keep running on the same Kubernetes you use today, on TrueFoundry’s AI Deploy together with Seldon’s serving layer. Models served over the V2 Open Inference Protocol stay portable, and there is nothing to rip out.
Generative AI native path forward. Your real-time ML keeps running as it does now, and you gain the AI Gateway and the agent layer on the same foundation, so you can add LLMs and agents whenever you are ready.
Yes. TrueFoundry runs in your VPC, on-prem, air-gapped, hybrid, or across multiple clouds, and no data leaves your domain. This is the main reason regulated enterprises pick it over SaaS-only gateways.
More than 1,000, through a single OpenAI-compatible API. You switch models by changing the model name in the request, while keeping the URL and credentials the same.
Yes. It includes an MCP Gateway, an Agent Gateway, and an MCP and Agents Registry with tool-level access control, so agents from LangGraph, CrewAI, AutoGen, or a custom framework can be governed centrally.






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


