Built for Speed: ~10ms Latency, Even Under Load Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed Production-ready with full enterprise support TrueFoundry LLM Gatewayは、Anthropic、OpenAI、Bedrock、Geminiなど、様々なLLMプロバイダーに対して、統一されたOpenAI互換インターフェースを提供します。 TrueFoundry LLM Gatewayは、1ユニットCPUのシングルレプリカで270MBのメモリを使用しながら、350 RPSまでシームレスにスケールします。同様のセットアップで別のゲートウェイ製品であるLiteLLMと比較したところ、LiteLLMは50 RPSを超えてスケールできませんでした。 TrueFoundry LLM Gatewayが追加するレイテンシはわずか3~5ミリ秒ですが、LiteLLMはリクエストごとに15~30ミリ秒を追加します。 なぜ貴社にLLMゲートウェイが必要なのでしょうか? LLMゲートウェイは、組織のLLM利用を管理するための統一されたインターフェースを提供します。
統合API : 複数のLLMプロバイダーに単一の OpenAI互換 インターフェースでアクセス、コード変更不要APIキーのセキュリティ : 安全で一元化された認証情報管理ガバナンスと制御 : 制限、アクセス制御、コンテンツフィルタリングの設定レート制限 : 不正利用を防止し、公平な利用を確保可観測性 : 利用状況、コスト、レイテンシ、パフォーマンスを追跡ロードバランシング : プロバイダー間でリクエストを自動的にルーティングコスト管理 : 支出を監視し、予算アラートを設定監査証跡 : コンプライアンスのためにすべてのLLMインタラクションをログに記録TrueFoundry LLM Gatewayはどのくらい高速ですか? 負荷テストのセットアップ 負荷テストの実験のため、当社はこれをデプロイしてセットアップしました 偽のOpenAIエンドポイントサービス TrueFoundryを使用して。このサービスは、実際にトークンを生成することなく、OpenAIのリクエストおよびレスポンス形式をシミュレートするものです。
また、TrueFoundry LLM GatewayとLiteLLMプロキシサーバーもデプロイしました。これらはどちらも、1 CPUユニットと1 GBメモリを搭載した単一のレプリカで稼働しています。
当社は、偽のOpenAIプロバイダーをTrueFoundryとLiteLLMの両方のゲートウェイに追加しました。負荷テスト中、偽のOpenAIサーバーには3つの異なる方法でリクエストを行いました。
設定1:プロキシやゲートウェイを使用せず直接 設定2:1 CPUユニットと1 GBメモリにデプロイされたTrueFoundry LLM Gatewayを介して 設定3:1 CPUユニットと1 GBメモリにデプロイされたLiteLLMプロキシサーバーを介して
RPS
10 RPS
50 RPS
200 RPS
300 RPS
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
Could not scale to 200 RPS
Could not scale to 300 RPS
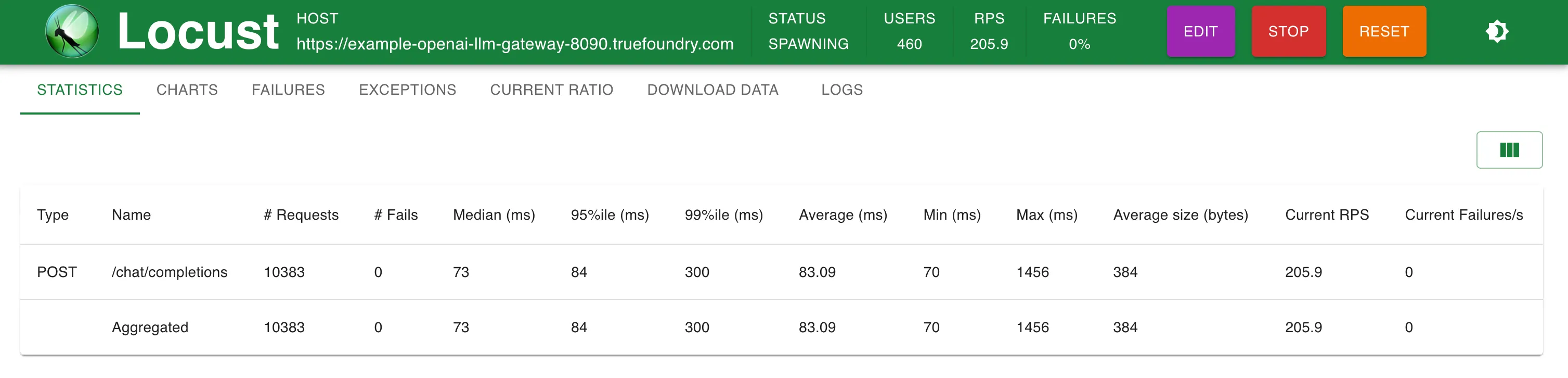
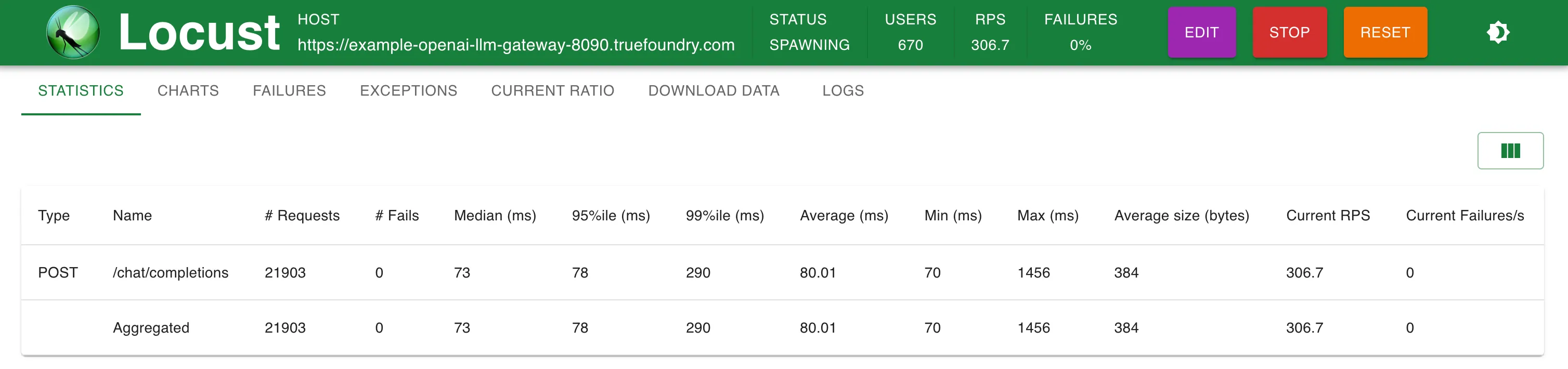
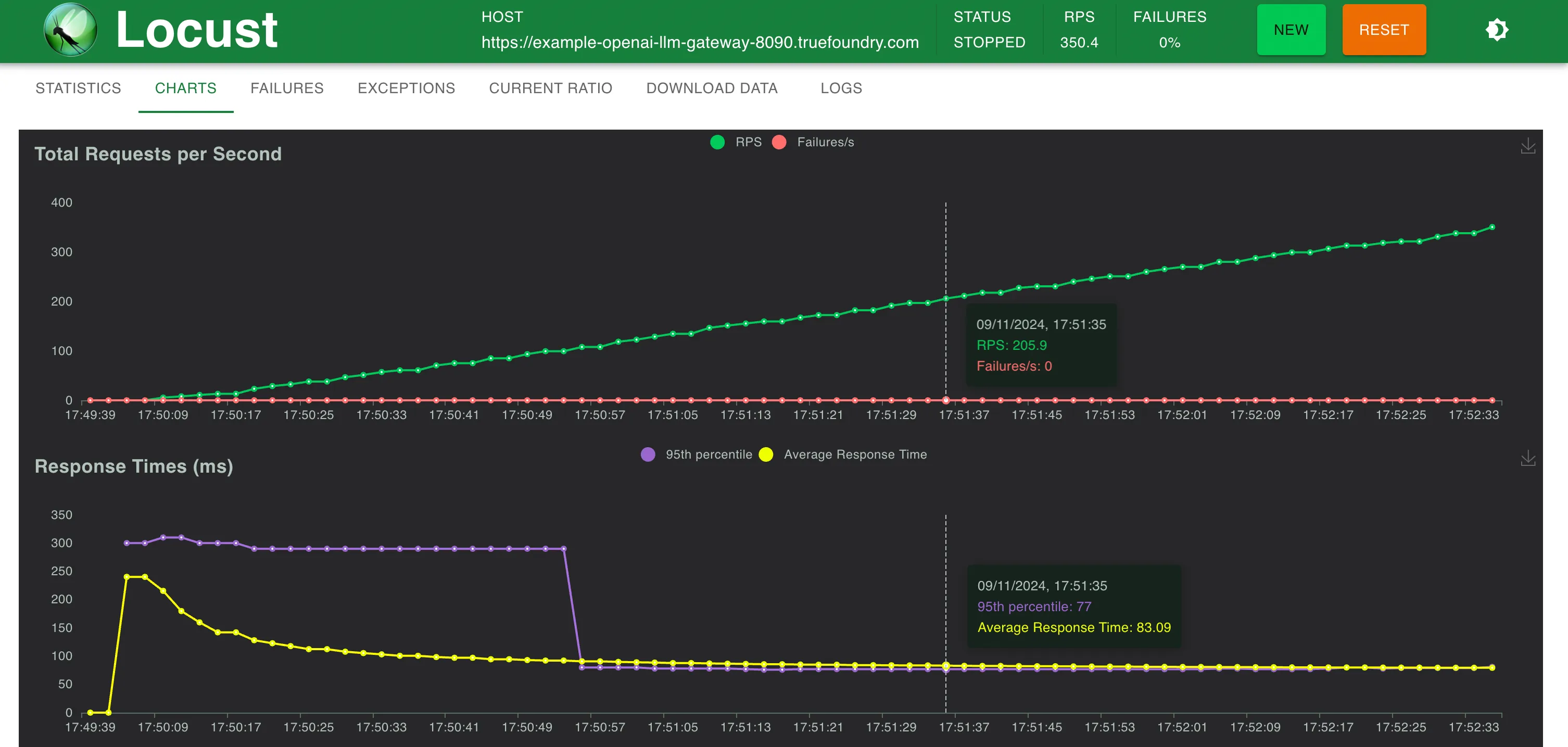
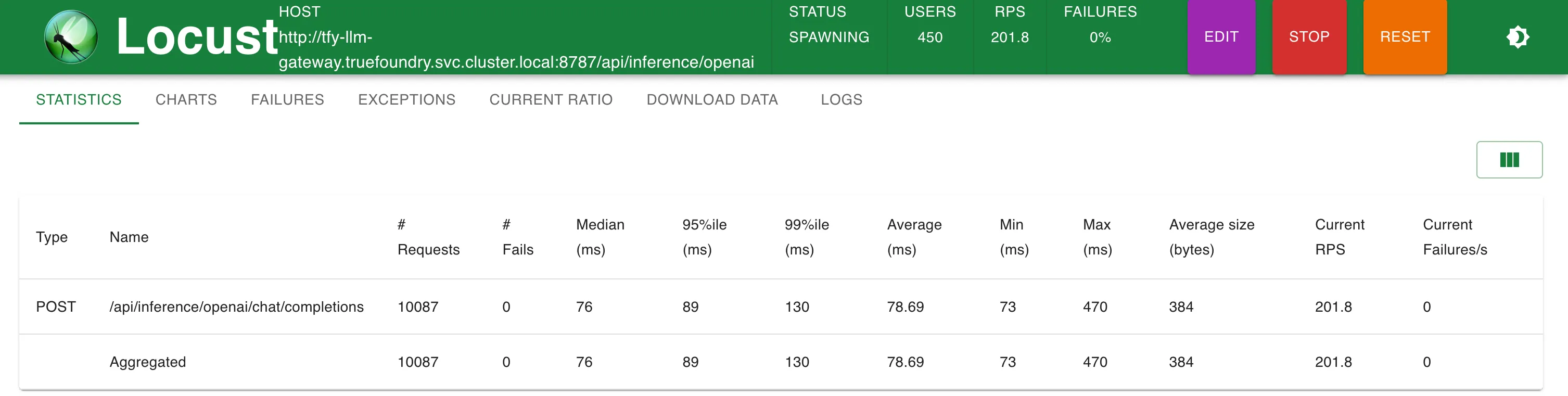
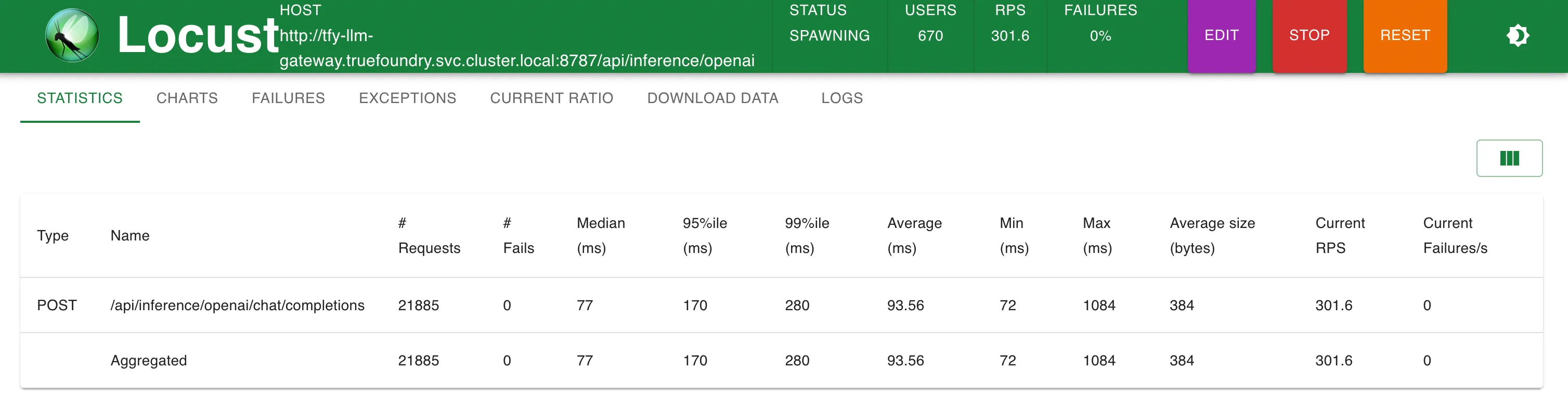
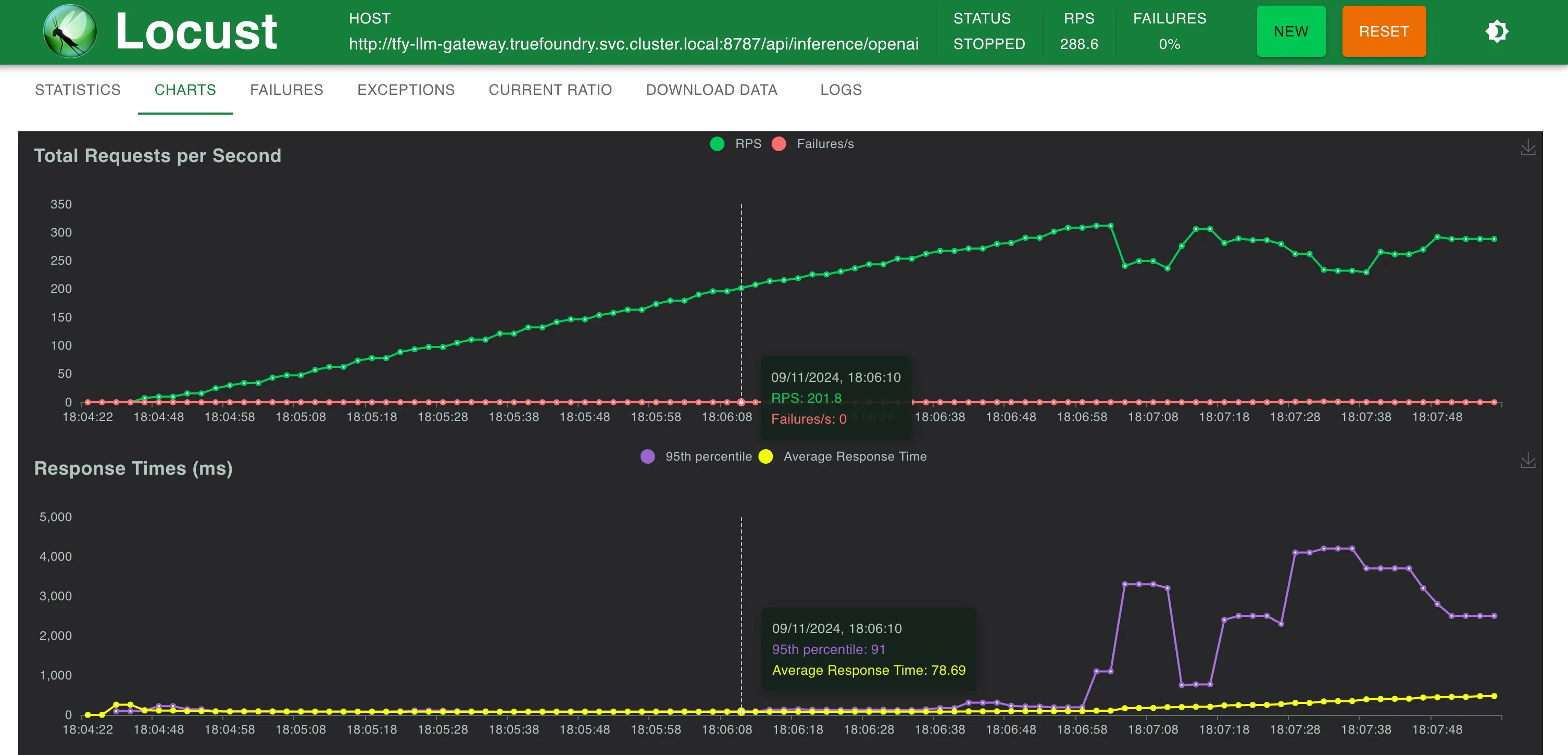
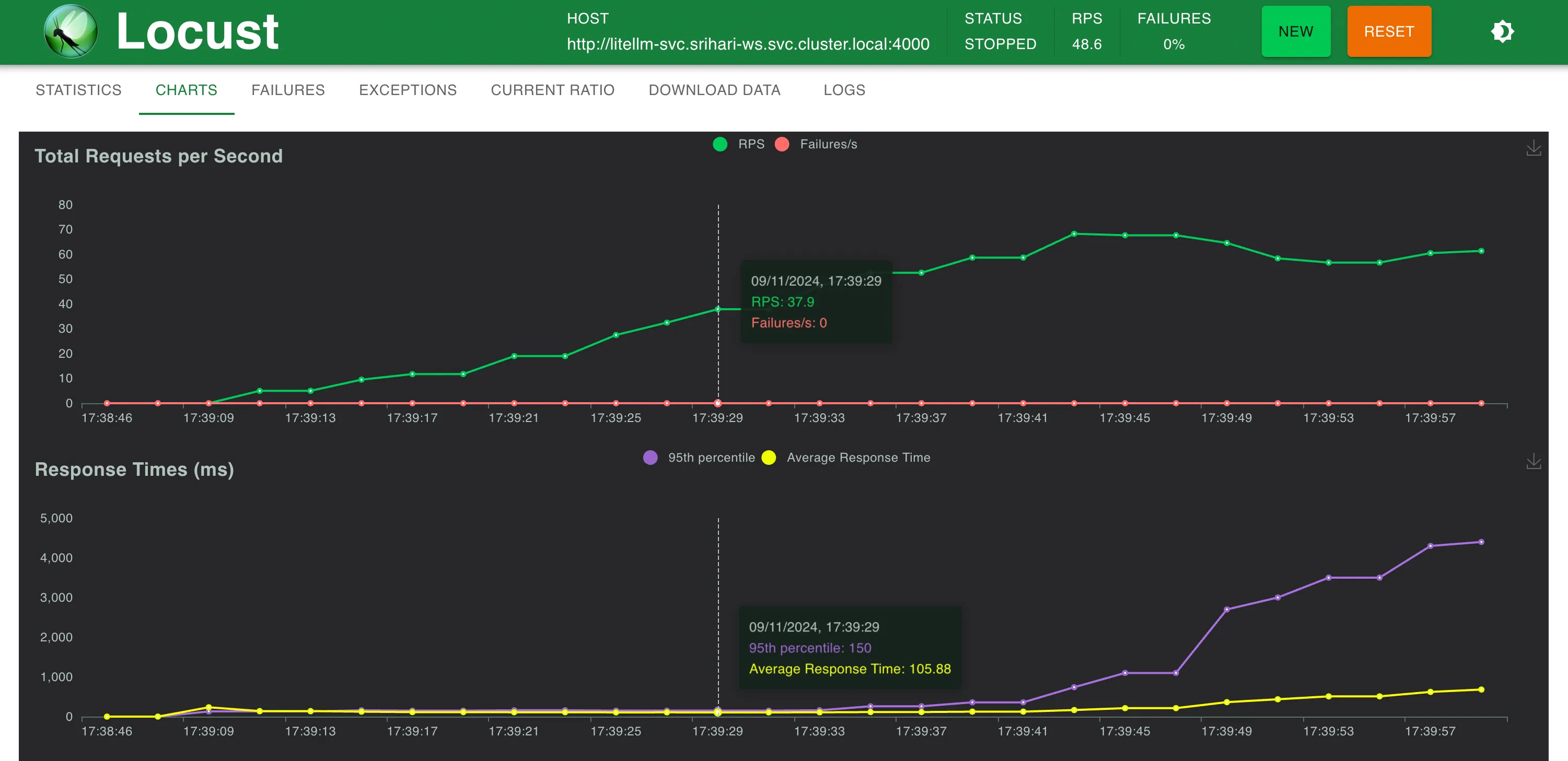
観測結果 TrueFoundry Gatewayは、250 RPSまではレイテンシにわずか3ミリ秒の追加にとどまり、300 RPSを超えると4ミリ秒の追加となります。 TrueFoundry LLM Gatewayは、パフォーマンスの低下なくスケーリング可能でした 約350 RPS (1 vCPU、1 GBマシン) まで、CPU使用率が100%に達するまでは。 そしてレイテンシに影響が出始めました。より多くのCPUまたはより多くのレプリカがあれば、LLM Gatewayは毎秒数万のリクエストにスケーリングできます。 同一マシン上のLiteLLMは、CPU使用率の限界に達する前に40-50 RPSを超えてスケールできませんでした その他のメトリクス セットアップ1:OpenAIエンドポイントへの直接呼び出し
200 RPS時の統計 300 RPS時の統計 応答時間 対 RPS セットアップ2:TrueFoundry LLM Gateway
200 RPS時の統計 300 RPS時の統計 応答時間 対 RPS セットアップ3:LiteLLM
約58 RPS時の統計 応答時間 対 RPS LLM Gatewayの高速化機能 ほぼゼロのオーバーヘッド :追加されるレイテンシはわずか3~5ミリ秒最適化されたバックエンド :高性能なNode.jsフレームワークで構築設定キャッシュ: 設定は高速な参照のためにメモリに保存されますスマートルーティング :最小限の処理オーバーヘッドエッジ対応 :アプリケーションの近くにデプロイ高い処理能力 : t2.2xlargeTrueFoundry LLM Gatewayのエッジデプロイメント 対応プロバイダー TrueFoundry LLM Gatewayがサポートする人気のLLMプロバイダーの包括的なリストは以下の通りです。
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Built for Speed: ~10ms Latency, Even Under Load


































.webp)




.png)








.webp)
.webp)


