Built for Speed: ~10ms Latency, Even Under Load Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed Production-ready with full enterprise support OCRと文書処理は、すでに解決済みの問題ではないのでしょうか? 多くの人がOCRと文書処理は解決済みの技術だと考えている一方で、手作業によるデータ入力は米国企業に従業員1人あたり年間約15,000ドルから30,000ドルのコストを発生させています。 出典 :手作業による文書処理が原因で発生する運用上および時間的な負担は、依然として深刻です。その理由は:
従来のOCR:柔軟性に欠け、性能が低い 従来のOCR(コンピュータービジョン+ルール+NLP)手法は、さまざまな書式やレイアウトへの適応性が低く、文脈やデータ形式の要件を考慮できないことがよくあります。
低い適応性:最高クラスの従来のOCRシステムでさえ、複雑な文書では85~90%の精度で頭打ちになり、手書きコンテンツではわずか64%の精度にまで低下します。出典 画像品質や照明の悪さ: 300 DPIが、最適なOCR結果を得るための標準的な最低要件です。 ノイズ 傾きと向き テンプレートとレイアウトへの依存:特定のテンプレートに合わせて微調整されており、新しい文書タイプやテンプレートの更新ごとに、カスタムの後続処理パイプラインまたはテンプレートの変更が必要です。例: ベンダーからの新しい請求書フォーマット、レポート内のわずかにずれた列 文脈の認識不足:文字レベルのOCRは類似した文字を区別できず、文書全体の文脈理解を失います。 例:「50mg Metformin」が「5Omg Metformin」と読み取られる可能性があり、これは後続の医療タスクにとって誤りとなります。
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
LLMベースのOCR:予測不能で高コスト LLMベースのOCRは、従来の方法におけるいくつかの課題を解決しますが、新たな複雑さも生み出します。
手書き文字には未対応:GPT-4VやClaude 3.5 Sonnetが達成しているにもかかわらず 82~90%の精度 手書き文字において著しい改善ではあるものの、これはまだ業務上重要な基準には達していません。 例:ヘルスケア分野では、手書きの処方箋における10~18%のエラー率は、文字通り命に関わる可能性があります。 スケーリングが困難: 非常に高価:毎年何百万もの文書を処理する組織にとっては。 応答が遅い: セルフホスト型ではSLAの維持が困難 サードパーティプロバイダーではダウンタイムやレイテンシーの急増が発生 出力の一貫性がない: ハルシネーション - 例:法的文書の条項において、完全に捏造された値が出力されるなど 構造化された出力への準拠が困難 同じプロンプトでも異なる応答 金融サービスやヘルスケアのように、毎年何百万もの重要な文書を処理する業界では、信頼性高くスケーリングでき、低コストで高品質な出力を生成できるシステムが不可欠です。
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
出典
あなたのドキュメント処理パイプラインはどの程度優れていますか?(実用的な指標)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
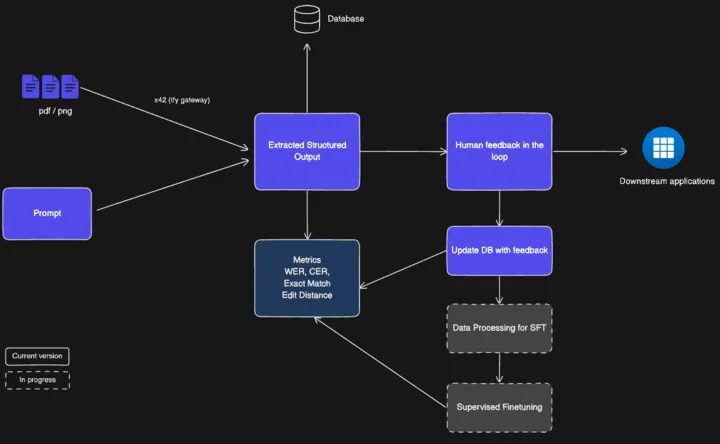
TrueFoundryのインテリジェントドキュメント処理アクセラレーターのご紹介 TrueFoundryのインテリジェントドキュメント処理(IDP)は、実運用可能なプラクティスと、高度にカスタマイズ可能で正確なOCRパイプラインを組み合わせ、エンドツーエンドの文書処理ワークフローを構築・提供する生成AIベースのアクセラレーターです。
仕組み: 数分で構造化データを使ってアプリケーションを強化! このアクセラレーターは、PDF、画像、またはFAXを取り込み、ノイズ除去、傾き補正、アップスケーリングによってクリーンアップします。これにより、モデルは鮮明な画像から処理を開始できます。その後、各文書(請求書、処方箋、手書きメモなど)を分類し、適切なスキーマ、プロンプト、ドメインルールを適用します。抽出モデルは構造化フィールドと信頼度スコアを抽出し、ルールエンジンがチェックとルックアップによってそれらを検証し、補完します。項目はシンプルなUIを通じてレビュー担当者にルーティングされ、すべての修正がシステム改善のためのフィードバックとして継続的に活用されます。
カスタマイズ可能なモジュール型コンポーネント このアクセラレーターは、プラグイン可能なモジュール型コンポーネントで構成されており、これらを組み合わせることで、初日のプロトタイプから本格的な実運用対応アプリケーションまで構築できます。
基本コンポーネント
マルチモデル対応(OSSおよびクローズドソース) ヒューマン・イン・ザ・ループ(HITL)とフィードバック 統合されたファインチューニングインフラストラクチャ モニタリングと可観測性 ナレッジベース連携(RAG + ナレッジグラフ) 高度なコンポーネント
自動分類とルーティング 領域認識型OCRとバウンディングボックス スキーマ自動検出(ゼロショット) 検証と後処理 コンプライアンスと監査可能性 当社の設計は、複数のエンタープライズ導入事例で検証済みです。 選択と制御のために構築 このアクセラレーターはモデルに依存せず、OSSまたはクローズドソースに対応し、価格/性能やフェイルオーバーのためにプロバイダー間でルーティングできます。専門家は、ドメインに特化したレビューUIを通じてプロセスに関与し、その編集内容はトレーニングデータとして活用されます。
導入初日から稼働。 リアルタイムな可観測性(遅延、スループット、ドキュメントあたりのコスト)に加え、STP、フィールド精度、編集率といったビジネスKPIも得られます。バリデーションとエンリッチメントにより、データが下流アプリケーションに到達する前に、クロスフィールドルールが適用され、フォーマットが正規化されます。
特に複雑なエンタープライズのユースケースにも柔軟に対応 スキーマ検出、領域認識型OCR、ナレッジベースグラウンディングにより複雑なレイアウトに対応し、監査ログは規制された環境向けにすべての操作、スコア、上書きを保持します。
このシステムのスケーラビリティはどのように保証されますか? 当社のアーキテクチャは、クラウドに依存しないマイクロサービスベースの設計であり、エンタープライズレベルの信頼性、スケーラビリティ、コスト効率のために設計されています。非同期メッセージキューでコアコンポーネントを分離することにより、システムはデータ損失なしに変動するワークロードとコンポーネントの障害を処理し、ベンダーロックインを回避します。
インジェスト層 ステートレスLLMゲートウェイ:すべてのドキュメントをメッセージトピックにキューイングする単一のエントリポイント(認証/レート制限)。 永続的なバッファリング:生のアップロードは、再生、監査、リカバリのためにオブジェクトストレージに書き込まれます。 処理パイプライン サービス分離:分類、抽出、検証のための個別のワーカー。それぞれを個別に更新およびスケールできます。 独立したオートスケーリング:CPU/GPU負荷の高いエクストラクターは、より軽いステージに影響を与えることなく、ピーク時にスケールアップします。 べき等なジョブ:重複排除機能を備えた再実行可能なタスクにより、安全な再試行と正確に1回の出力が保証されます。 データと状態の管理 ポータブルストレージ:S3互換バケットは、バージョン管理付きでドキュメントとアーティファクトを保持します。 リレーショナルバックボーン:PostgreSQL互換DBは、メタデータ、ワークフローの状態、HITLキューを追跡します。 スキーマ契約:サービス間の明確なインターフェースにより、安全で後方互換性のある変更が可能になります。 フィードバックとMLOps層 ヒューマンループ:検証済みの修正は、トレーニングデータのために来歴とともにキャプチャされます。 クローズドループ:自動化された再学習/評価/デプロイパイプラインにより、より良いモデルが本番環境にプッシュされます。 管理されたリリース:モデルレジストリ、A/Bチェック、ロールバックにより、改善は安全かつ監査可能に保たれます。 結論 現代のOCRは「解決済み」ではありません。特に精度、規模、コストが重要となる場合はなおさらです。TrueFoundryのIDPアクセラレーターは、マルチモデル抽出、自動検証、そしてシステムを継続的に強化するヒューマン・イン・ザ・ループを特徴とする、実用的で本番環境に対応したアプローチを提供します。その結果、より迅速なストレートスルー処理、ビジネスを実際に動かすドキュメントにおけるより高いフィールドレベルの精度、そして単に感嘆するだけのデモではなく、チームが運用できるプラットフォームが実現します。
このアクセラレーターは、監査人、専門家、オペレーターのためにデータ整合性を維持しながら、より多くのドキュメントを効率的かつ費用対効果高く処理するのに役立ち、大規模なカスタムエンジニアリングを必要とせず、即座に導入を可能にします。
次のステップ 実際の動作を見る 本番環境でのパイロット運用: このリンクからお問い合わせください。お客様のユースケースに合わせて動作するプロトタイプを作成し、通常の開発時間の10分の1で本番環境に対応したアプリケーションを提供できるよう支援します!TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Built for Speed: ~10ms Latency, Even Under Load






























.webp)




.png)








.webp)
.webp)


