














November 5, 2025
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
構成管理はソフトウェアエンジニアリングの重要な側面です。本記事では、この問題の「なぜ」と「何を」に焦点を当て、存在する様々な解決策について考察します。

アプリケーションがトラフィックと開発チームの規模の両方でスケールするにつれて、構成変更を管理するアプローチ。その道のりを説明するために、簡単なアプリから始めましょう。
これはMongoDBに接続し、ユーザーリストを返すシンプルなサーバーアプリです。コードは擬似コードであり、特定の言語に準拠するものではありません。

アプリケーションに構成をハードコードする:絶対に避けるべき!

MongoDBのURIをアプリケーションにハードコードすると、他の環境(チームメイトのラップトップや本番環境など)でアプリケーションを実行するのが非常に困難になります。私たちは 12ファクターアプリの原則 ここで、設定をコードから分離します。
「設定をコードから分離する」
さて、問題はアプリの設定が何で構成されているかです。?引用元: https://12factor.net/config
アプリの 設定 は、 デプロイ (ステージング、本番、開発環境など)間で変化する可能性のあるすべてのものです。これには以下が含まれます。
1. データベース、Memcached、その他のリソースハンドル バックエンドサービス
2. Amazon S3やTwitterなどの外部サービスへの認証情報
3. デプロイの正規ホスト名など、デプロイごとの値
設定をコードから分離する最も簡単で一般的な方法は、変数を.envファイルに置くことです。
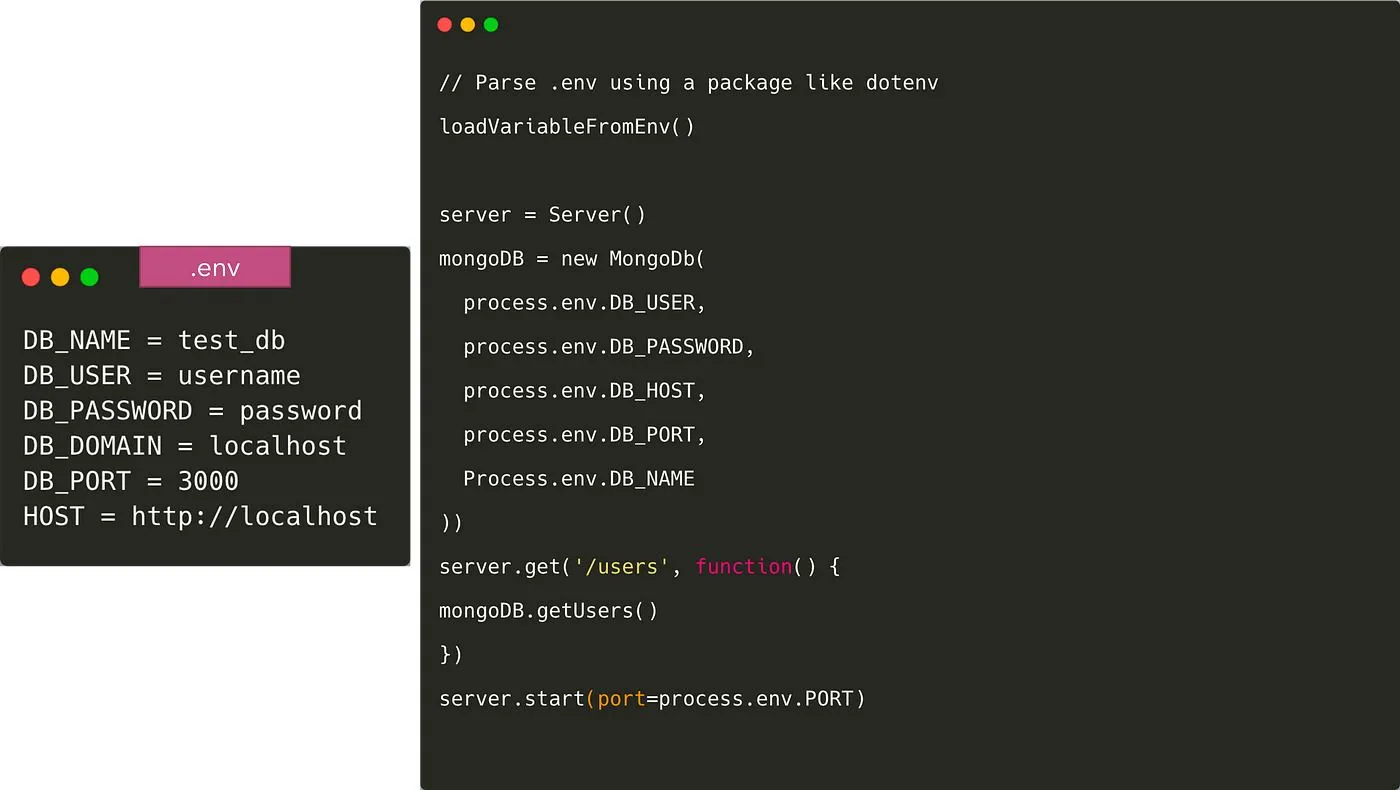
これを行うと、コード内で.envファイルから変数を読み込む必要があります。dotenvやdotenv-expandのようなパッケージがいくつかあります。 この場合、.envファイルはGitにプッシュされません そして、各開発者は自分の環境に合わせて変数を上書きします。すべての開発者に、どのような環境変数を追加する必要があるかを知らせるために、通常、次のようなファイルをコミットします .env.example をGitに。

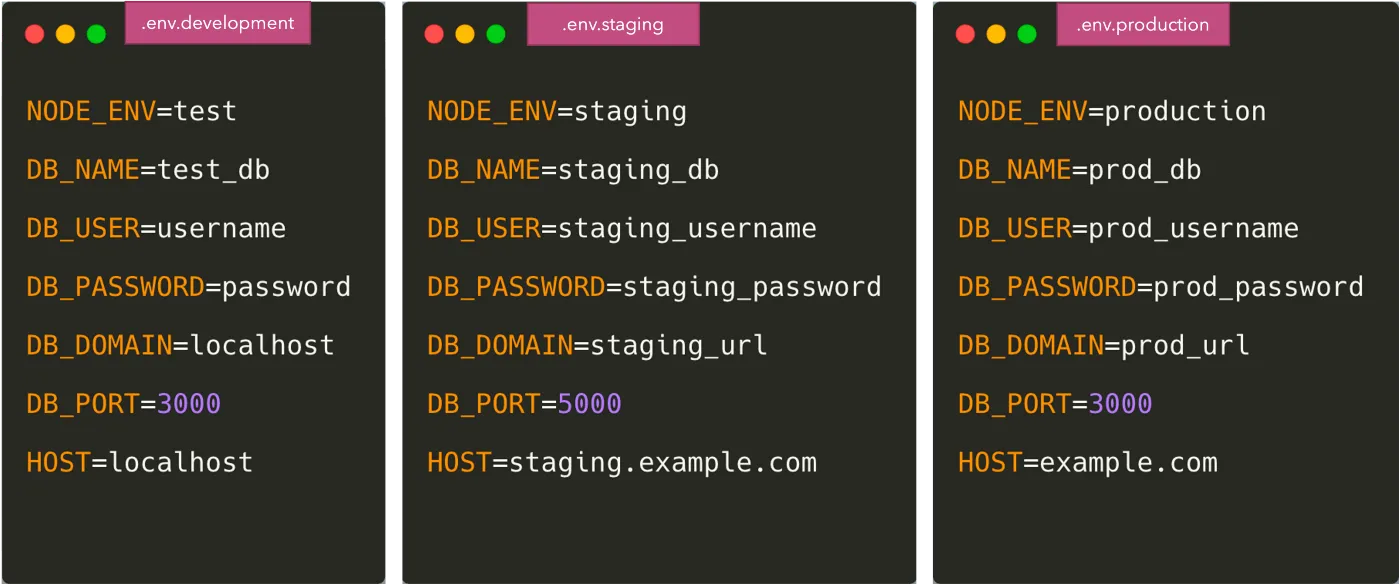
これらの変数の値は、ステージング環境と本番環境でも提供する必要があります。ほとんどすべてのデプロイシステムは、KubernetesのConfigMapやSecrets、またはElastic Container ServiceのS3のように、環境変数を保存および提供する方法を提供しています。
これらの変数をそれらの環境にコピーし、開発者が環境変数を追加/削除するたびに同期を保つ必要があります。一つの可能なアプローチは、ステージング、本番などの環境ごとに個別の.envファイルを持つことです。

これらのファイルをGitに保存することを提案する人もいるかもしれませんが、そこには 大きなセキュリティ上の問題 があります。特に.envファイル内の機密性の高い認証情報については。
ここでは様々なアプローチが取られますが、よく知られている方法には以下のようなものがあります。

これらの外部システムを使用する場合、設定は.envファイルとシークレットマネージャーに分割されます。機密性の低いパラメータは.envファイルから、一部はリモートの認証情報ストレージから取得されます。すべてのパラメータをリモートストレージに保存することも可能ですが、時にはやりすぎになることもあります。その結果、次のようになります。
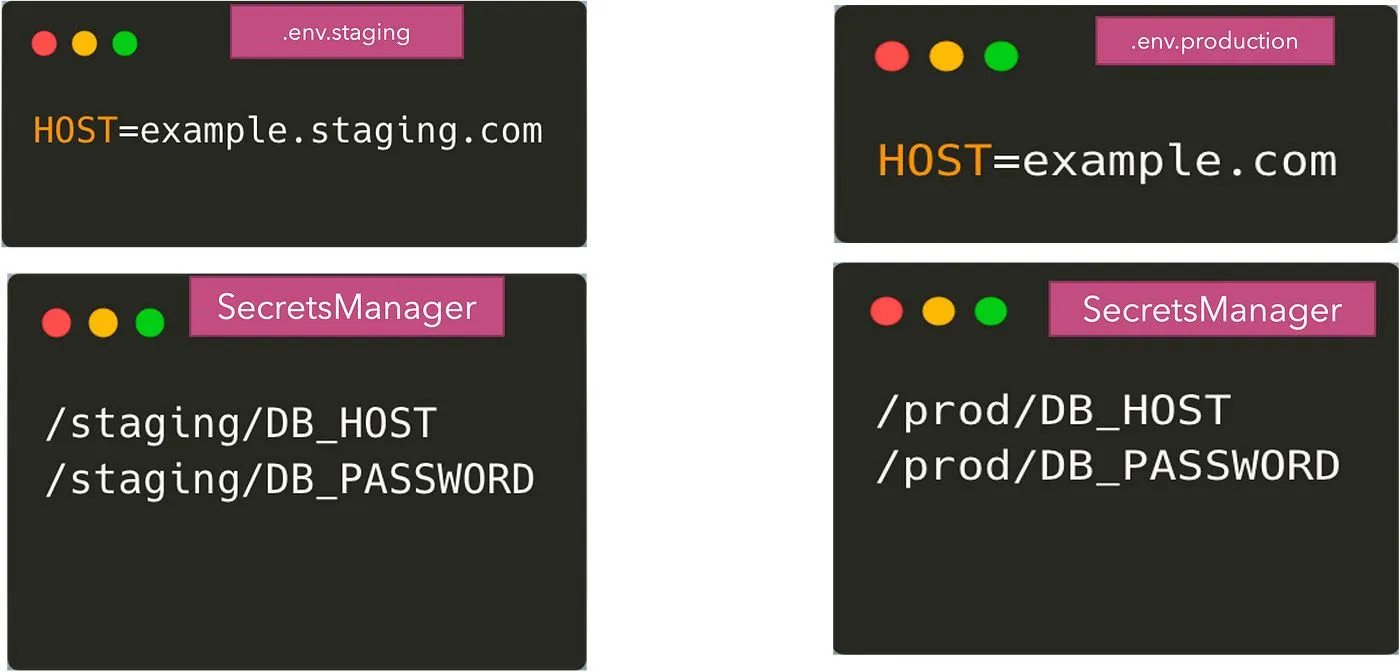
アプリケーションは、これら両方の設定ソースから読み取るためのコードを持つ必要があります。.envファイルからの読み取りはdotenvパッケージを使用して行うことができますが、シークレットマネージャーから環境変数を取得するには、対応するAPIを使用して値を取得する必要があります。

これにより、設定を安全に保つという問題が解決され、12ファクターアプリの原則にも従うことができます。
しかし、シークレットを取得するためのアプリケーションコードを書くことは、反復的な作業になりがちです。その結果、すべてのアプリケーションがAPIから値を取得するためにシークレットマネージャー固有のコードを追加する必要があります。これは、シークレットマネージャーのプロバイダーを変更した場合、すべてのアプリケーションのコードを変更する必要があることも意味します。この問題を解決するには、いくつかの方法があります。
設定管理は複雑であり、セキュリティを犠牲にすることなく開発者の生産性を高く保つためには、最初から適切に行う必要があります。今日最も広く使われているアプリケーションデプロイツールであるKubernetesには、独自の構成管理とシークレット管理機能があります。これについては別の記事で詳しく説明します。また、もし他の方法で設定管理を行っている方がいらっしゃいましたら、コメントで教えてください。ぜひ詳しく知りたいですし、皆さんの経験から学びたいです!
TrueFoundry は、LLM、MCP、エージェントゲートウェイを網羅するエンタープライズグレードのAIゲートウェイです。これにより、企業は単一のコントロールプレーンからモデル、ツール、ガードレール、エージェントへのアクセスを安全に接続、監視、管理できます。このAIゲートウェイは、以下のようなエージェントワークロードを可能にします。
a) 安全な — 鍵管理、認証、認可を解決します
b) 効率的な — コスト、レイテンシ、マルチリージョンフェイルオーバーを最適化します
c) 将来性のある — あらゆるプロバイダーのLLM、MCP、ガードレール間で統一された構成可能な接続を可能にします
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


