














November 5, 2025
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Elasti は、アイドル時にサービスをゼロにスケールダウンし、オンデマンドでスケールアップできるようにすることで、Kubernetesのリソース使用量を最適化するよう設計された革新的なオープンソースソリューションです。Kubernetesコントローラーとリクエストリゾルバーという2つのコンポーネントアーキテクチャで構築されており、Elastiはコストを最小限に抑えながら、サービスの可用性をシームレスに管理します。この記事では、そのアーキテクチャ、インストール、運用フローについて技術的な解説を行い、Kubernetes環境でElastiを効果的に統合し、拡張できるようになることを目指します。
💡この機能はTruefoundryのオートスケーリングスイートに含まれています。詳細については、 ドキュメント。
KubernetesはHPAやKEDAのようなソリューションを通じて堅牢なスケーリング機能を提供していますが、レプリカをゼロにスケールすることは依然として困難です。既存のアプローチは通常、2つのカテゴリに分類されます。
Elastiはこれらの制限に対処するために、3つの主要な設計目標を掲げて作成されました。
Elastiは、サービスのスケーリングを管理するために連携して動作する2つの主要コンポーネントで構成されています。
コントローラー(オペレーター):
リゾルバー:
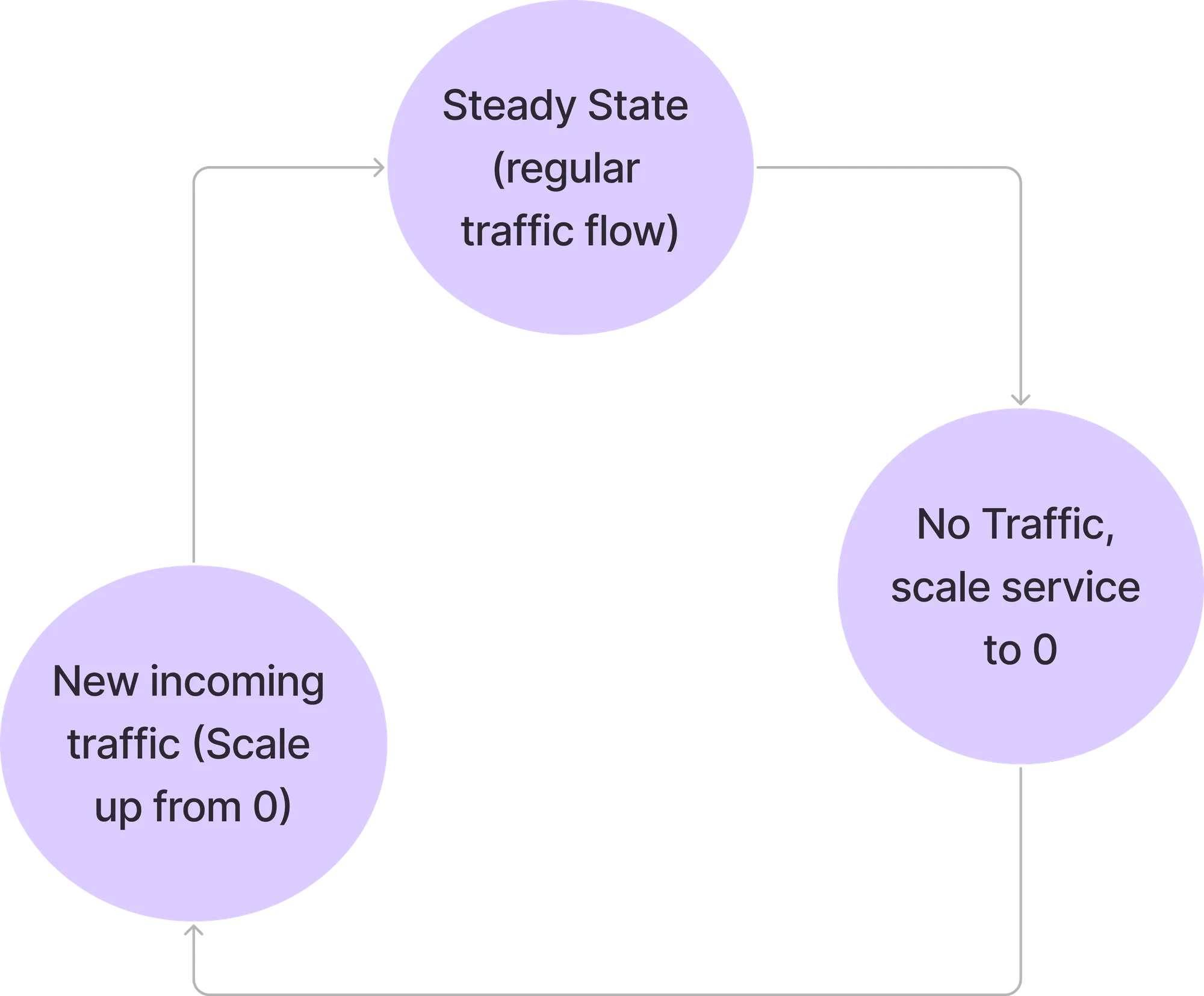
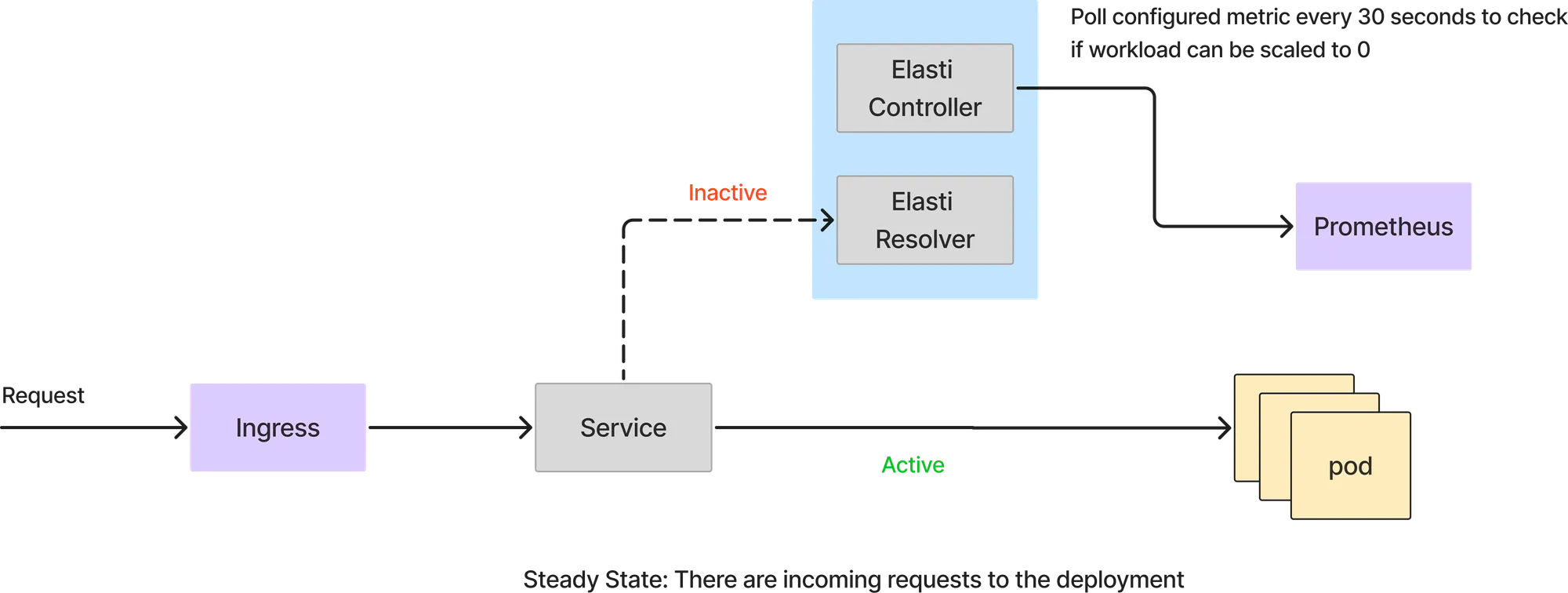
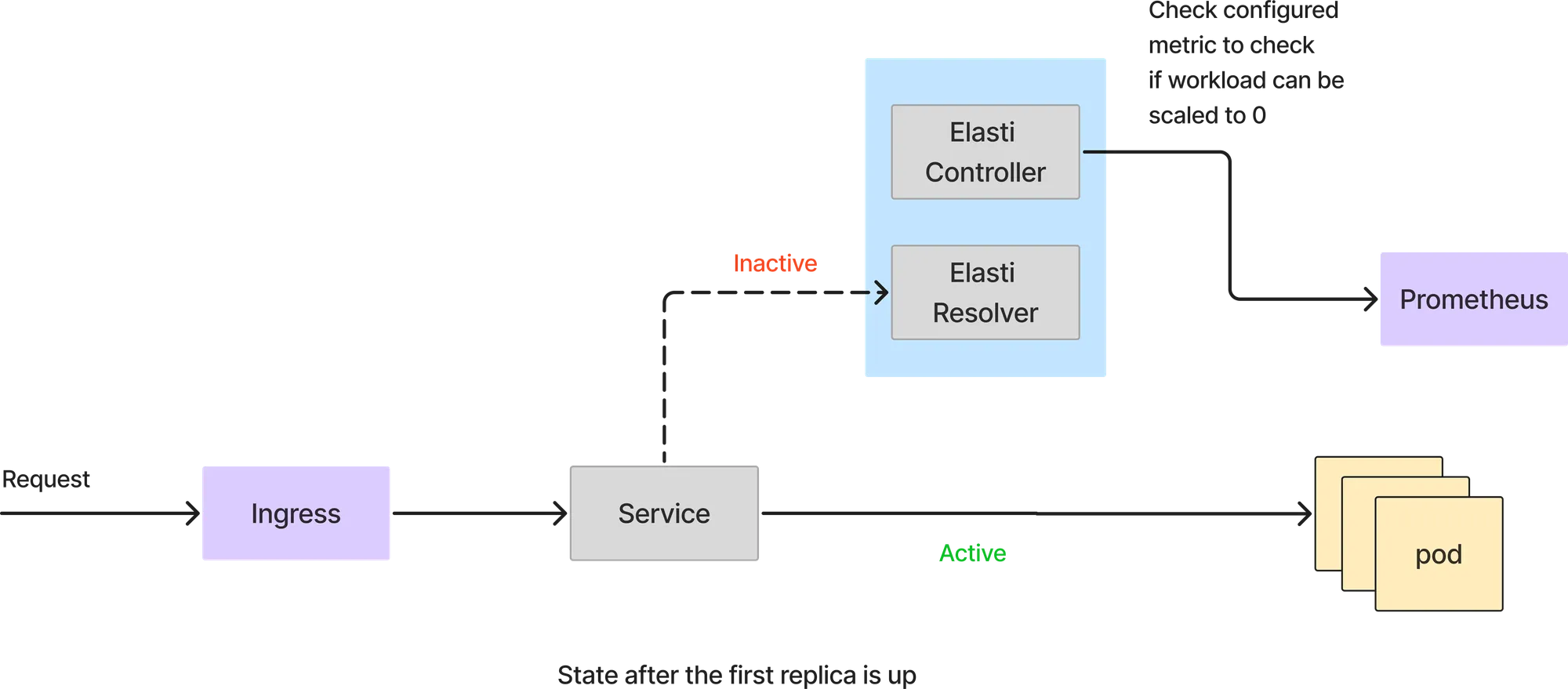
このモードでは、すべてのリクエストはサービスポッドによって直接処理されます。Elastiリゾルバーはリクエストパスに関与しません。Elastiコントローラーは、設定されたクエリでPrometheusをポーリングし続け、その結果を閾値と比較して、サービスをスケールダウンできるかどうかを確認します。
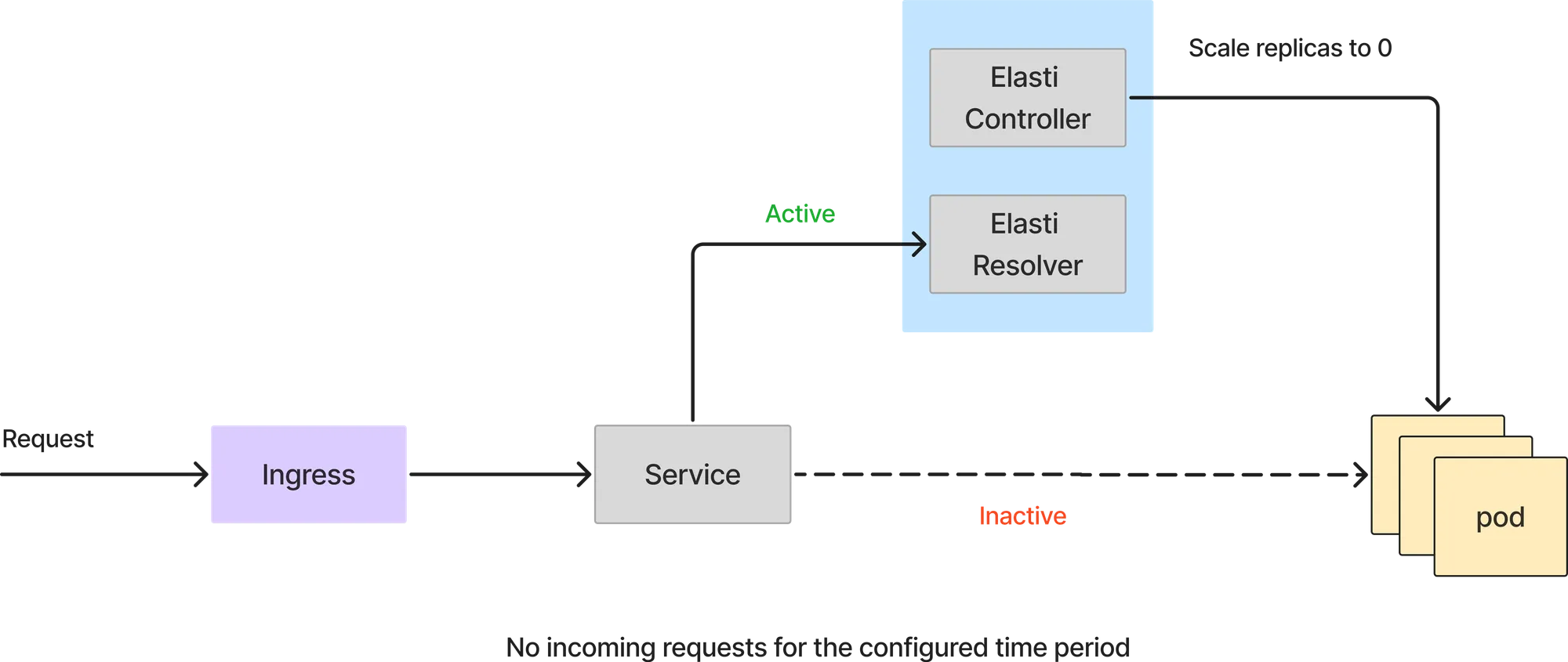
Prometheusからのクエリが閾値未満の値を返した場合、Elastiはサービスを0にスケールダウンします。0にスケールする前に、リクエストをElastiリゾルバーに転送するようにリダイレクトし、その後、Rollout/Deploymentを0レプリカに修正します。また、Kedaが使用されている場合はKedaを一時停止し、KedaはminReplicasが1に設定されているため、サービスがスケールアップされるのを防ぎます。
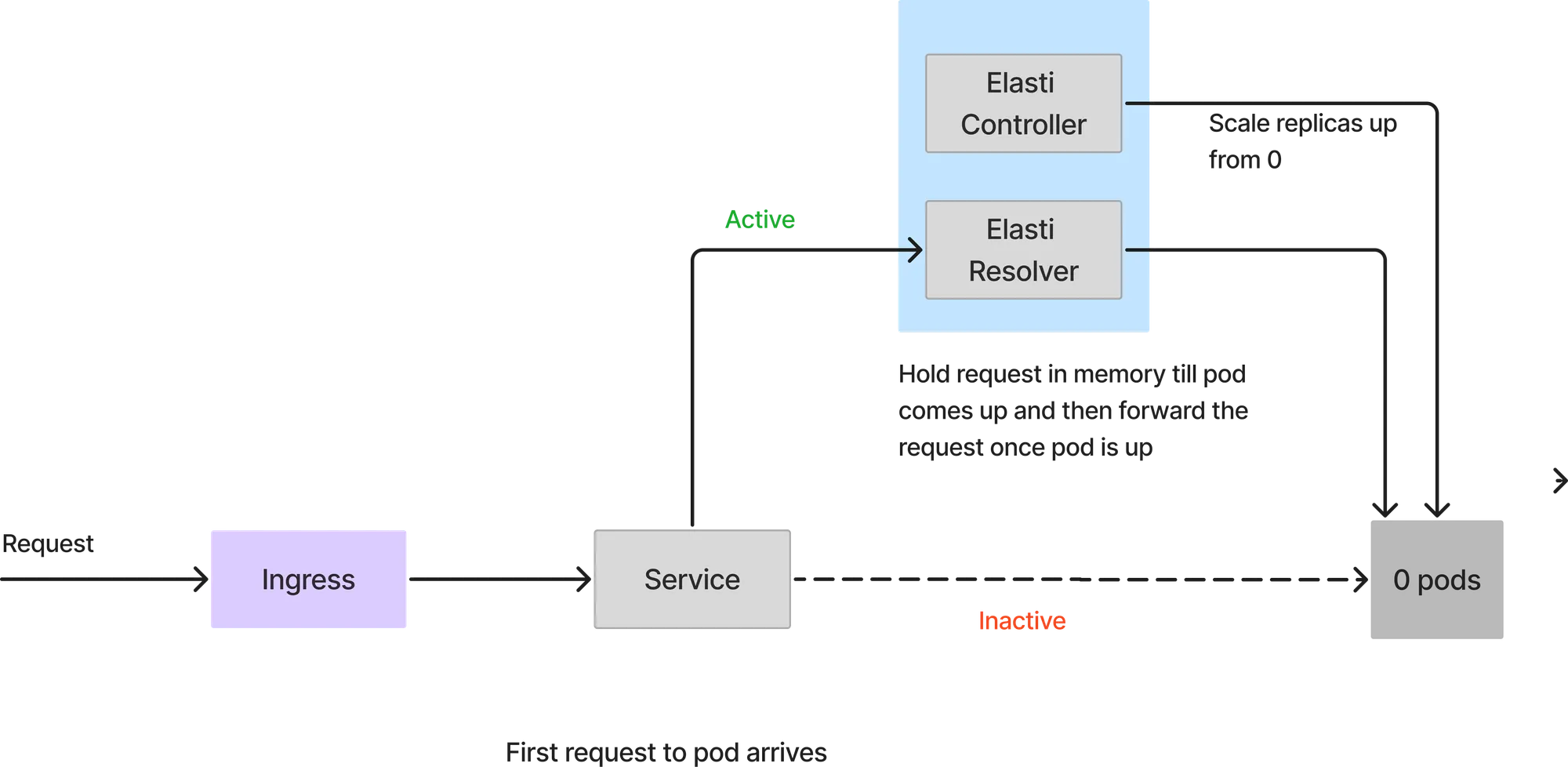
サービスが0にスケールダウンされているため、すべてのリクエストはElastiリゾルバーに到達します。最初のリクエストが到着すると、Elastiはサービスを設定されたminTargetReplicasまでスケールアップします。その後、急なリクエストの急増に備えて、Kedaを再開しオートスケーリングを継続します。また、ポッドが起動すると、サービスを実際のサービスポッドを指すように変更します。ElastiResolverに到達したリクエストは6分間リトライされ、クライアントに応答が返されます。ポッドの起動に6分以上かかる場合、リクエストは破棄されます。
minikube start
または
kind create cluster --name elasti-demo
または
Docker Desktopでローカルクラスターを作成する
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set alertmanager.enabled=false \
--set grafana.enabled=false \
--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
Prometheusを monitoring 名前空間にインストールおよび設定します。
Prometheusはnginx ingressからメトリクスを読み取り、そのメトリクスはElastiによってクエリされ、サービスをゼロにスケールしたり、ゼロからスケールしたりするタイミングの決定に利用されます。
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true \
--create-namespace
nginxコントローラーを ingress-nginx 名前空間にデプロイします。
このコントローラーは、デモのhttpbinサービスへのトラフィックをルーティングするために使用されます。
4. Elastiのセットアップ:
helm repo add elasti https://charts.truefoundry.com/elasti
helm repo update
helm install elasti oci://tfy.jfrog.io/tfy-helm/elasti \
--namespace elasti --create-namespace
elastiネームスペースにhelmでElastiをインストールする
Elastiがインストールされると、その主要な2つのコンポーネントが稼働しているのが確認できます。
より高度な設定については、以下を参照してください。 values.yaml helmのバリューファイルにあるすべての設定オプションを確認してください。
kubectl create namespace elasti-demo
kubectl apply -n elasti-demo -f \
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
httpbinサービスを elasti-demo ネームスペースにデプロイしています。
このhttpbinサービスは、Elasti経由でトラフィックを処理するサービスの設定方法をデモンストレーションするために使用されます。
ElastiService用のYAMLファイルを以下の設定で作成します。
apiVersion: elasti.truefoundry.com/v1alpha1
kind: ElastiService
metadata:
name: httpbin-elasti
namespace: elasti-demo
spec:
minTargetReplicas: 1
service: httpbin
cooldownPeriod: 5
scaleTargetRef:
apiVersion: apps/v1
kind: deployments
name: httpbin
triggers:
- type: prometheus
metadata:
query: sum(rate(nginx_ingress_controller_nginx_process_requests_total[1m])) or vector(0)
serverAddress: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
threshold: "0.5"
demo-elasti-service.yaml
ファイルが作成されたら、ElastiServiceを適用します。
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
CRDスペックの主なフィールドは次のとおりです。
minTargetReplicas: 最初のリクエストが到着したときに起動する最小レプリカ数。cooldownPeriod: スケールアップ後、スケールダウンを検討するまでに待機する最小時間(秒単位)。triggers: スケールダウンのタイミングを決定する条件のリスト(現在はPrometheusメトリクスのみをサポート)。scaleTargetRef: HorizontalPodAutoscalerで使用されるものと同様のスケールターゲットへの参照。詳細およびご自身のユースケースに合わせたElastiServiceの設定については、このドキュメントを参照してください。
これらの手順により、以下のものが利用可能になりました。
この設定により、実際のルーティングシナリオをテストし、Ingressトラフィックのパフォーマンスとメトリクスを監視できます。
この設定をテストするには、nginxロードバランサーにリクエストを送信し、デモサービスのPodを監視します。
kubectl port-forward svc/nginx-ingress-nginx-controller \
-n ingress-nginx 8080:80
nginxコントローラーへのポートフォワード
kubectl get pods -n elasti-demo -w
httpbinサービスでウォッチを開始する
これで、リクエストを送信できます http://localhost:8080/httpbin すると、サービスがElastiによって1レプリカにスケールされていることが確認できます。
curl -v http://localhost:8080/httpbin
httpbinサービスにリクエストを送信する
その後、サービスはアクティビティがない場合、 cooldownPeriod 秒間(この場合は5秒)ElastiServiceで指定された時間が経過すると、再度スケールダウンされます。
Elastiをアンインストールするには、 まず、インストールされているすべてのElastiServiceを削除する必要があります。 その後、インストールファイルを削除するだけです。
kubectl delete elastiservices --all
helm uninstall elasti -n elasti
kubectl delete namespace elasti
Elastiは、次のような場合に最適な選択肢です。
Elastiは、Kubernetesにおける特定の課題、すなわち、リクエストの整合性を損なうことなく、また過度なオーバーヘッドを課すことなく真のスケール・トゥ・ゼロを実装するという必要性から開発されました。このソリューションは、HPAおよびKEDAによるネイティブなオートスケーリングをサポートしており、既存のサービス設定を変更することなく、効率的なリソース利用を実現します。
このツールをオープンソース化することで、真のスケール・トゥ・ゼロ、リクエスト損失ゼロ、そして最小限の運用負荷を必要とする環境に対し、堅牢なソリューションを提供することを目指しています。
コミュニティからの貢献やフィードバックを歓迎します。詳細については、 開発ドキュメント をご覧ください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Kubernetes scale to zero means reducing the number of running pods for a workload all the way down to zero replicas during periods of inactivity. When no traffic or demand is present, the deployment consumes no compute resources and incurs no cloud costs. When a new request arrives, the system automatically scales back up from zero and serves the workload.
The primary tools enabling scale to zero in Kubernetes include KEDA (Kubernetes Event-Driven Autoscaling), which scales based on external event sources like queues and HTTP traffic, and Knative Serving, which provides serverless-style scale-to-zero behavior for containerized workloads. TrueFoundry's deployment infrastructure also builds on these primitives to offer scale-to-zero for ML model serving, reducing GPU and CPU costs during idle periods.
Kubernetes does not support scale to zero natively through its built-in Horizontal Pod Autoscaler (HPA), as HPA has a minimum replica count of one. Achieving true scale-to-zero requires additional tools such as KEDA or Knative, which extend Kubernetes' autoscaling capabilities to include zero-replica deployments triggered by external events or HTTP request-based scaling.






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


