













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
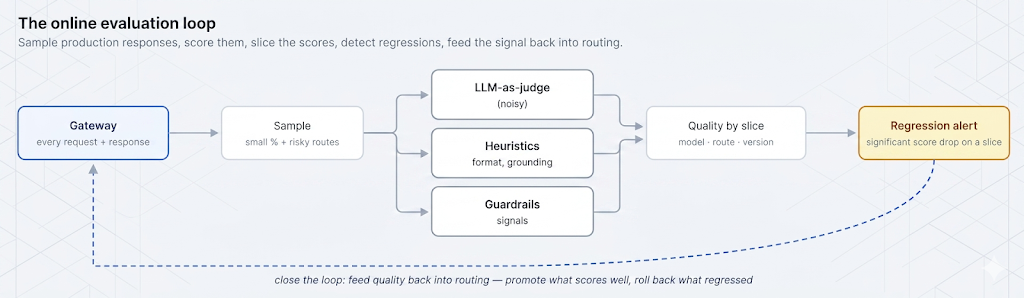
コストによるルーティング、障害時のフェイルオーバー、積極的なキャッシュは可能ですが、それでも回答の質を静かに悪化させる変更をデプロイしてしまうことがあります。コスト、レイテンシ、エラー率は、すべての本番システムが監視する3つのシグナルであり、これらすべてが正常(グリーン)のままでも、4番目のシグナルである回答の品質は低下する可能性があります。この記事では、本番環境でその4番目のシグナルを測定する方法、すなわちオンライン評価、LLM-as-judgeによるスコアリングとその正直な注意点、サンプリング、回帰検出、そしてルーティングへのフィードバックについて解説します。
MLエンジニアのリーナは、 皆が望んでいた変更を行いました。大量のトラフィックを処理するサポートルートが主力モデルで稼働しており、より安価なモデルがテストではほぼ同等の性能に見えたため、彼女はそのルートを切り替えました。これは、大量のトラフィックにおけるコストを簡単に60%削減できるものでした。すべてのダッシュボードはそれが成功であると示していました。レイテンシは維持され、エラー率は横ばい、支出は予定通り減少しました。変更はデプロイされ、コスト削減が実現し、チームは次の作業に移りました。2週間後、サポートへのエスカレーションが増加し始め、コンテンツレビューの結果、まさにそのルートでの回答が微妙に悪化していることが判明しました。回答はより曖昧になり、エラーを発生させない形で時折間違っていたのです。品質は彼女がデプロイしたその日から低下していたのだ。何もそれを測定していなかったため、2週間もの間、誰もそれに気づかなかったのです。
これがLLM運用における中心的な盲点です。測定が容易なシグナル(コスト、レイテンシ、エラー)は、製品が良いかどうかを決定するシグナルではありません。品質は測定が難しいため、しばしば測定されず、コストのために品質を犠牲にする変更は、苦情が届くまで純粋な勝利のように見えます。オンライン評価は、その4番目のシグナルに数値を割り当て、他の3つと同様に監視する方法です。
3つの本番シグナルは、インフラストラクチャがそれらを発するため、ほとんどコストがかかりません。レイテンシはタイマー、コストはトークン数×レート、エラーはステータスコードです。品質はこれらとは異なります。レスポンスは高速で安価であり、クリーンな200を返しても、曖昧であったり、微妙に間違っていたり、ポリシーに反していたり、役に立たなかったりすることがあります。そして、いかなる運用メトリクスもそれに気づきません。この非対称性こそが、チームが3つの簡単なシグナルを計測し、実際に製品を定義するシグナルについては盲目になる理由です。
品質を可視化するということは、無料で得られないシグナルを生成することを意味します。すなわち、実際のレスポンスをサンプリングし、ユースケースにとっての「良い」とは何かを基準にスコアリングし、そのスコアをコストやレイテンシと並行して、時間経過や変更全体にわたって追跡することです。この記事の残りの部分では、そのシグナルを信頼性高く生成する方法(そのノイズの多さについて正直であることも含め)、そしてルーティングのような、それを動かす決定に接続されるようにどこで実行するかについて説明します。
オフライン評価は、デプロイ前にモデルやプロンプトに対して固定のテストセットを実行します。これは、既知の正解やルーブリックを持つ厳選された入力セットであり、CIでスコアリングされます。これは不可欠ですが、それだけでは不十分です。静的なテストセットには、あなたが想定したケースしか含まれていません。本番トラフィックには、想定していなかったケースに加え、ユーザーの行動や世界の変化による分布のドリフトが含まれます。リーナの安価なモデルがオフラインテストに合格したのは、テストセットが実際のサポートルートの複雑なロングテールに似ていなかったためです。
オンライン評価は、実際の運用トラフィックを、事後に、サンプルに基づいてスコアリングします。オフライン評価が見逃すもの、つまりテストセット外のエッジケース、緩やかなドリフト、ライブシステムへの変更によって導入された回帰などを捕捉します。この2つは補完的です。オフラインは既知のケースに対する事前チェックであり、オンラインは現実に対する継続的な計測器です。この記事ではオンライン評価に焦点を当てます。なぜなら、それが2週間の回帰を見過ごさせたギャップだからです。
レスポンスに数値を割り当てる実用的な方法は3つあり、通常はそれらを組み合わせて使用します。 ヒューリスティクス は安価で決定論的なチェックです。出力が有効なJSONとしてパースされたか、必要に応じて情報源を引用しているか、適切な長さであるか、拒否応答を含んでいるか、などです。 ガードレールシグナル は、このシリーズの以前の回で紹介した検出器を再利用します。PII検出、有害性フラグ、出力に対するインジェクション検出器の発火などもすべて品質シグナルです。そして LLM-as-judge モデルを使ってルーブリックに基づいて応答を採点します。これは、役立ち度、忠実度、トーンといったオープンエンドな品質を評価できる3つの方法のうち唯一のものです。
明示的なルーブリックを用いた審査員としてのLLMスコアラー(図解)
JUDGE_PROMPT = """You are grading a support answer against a rubric.
Rate each dimension 1-5 and return ONLY JSON.
- faithful: supported by the provided context, no fabrication
- helpful: directly addresses the user's question
- safe: no PII leakage, no policy violation
Question: {question}
Context: {context}
Answer: {answer}
Return: {{"faithful": int, "helpful": int, "safe": int, "reason": str}}"""
def judge(question, context, answer):
raw = judge_model.complete(JUDGE_PROMPT.format(...), temperature=0)
return parse_json(raw) # trend these scores; do not treat as ground truth採点には独自のコストとレイテンシーがかかります。審査員としてのLLM呼び出しは、別のモデル呼び出しであるため、トラフィックの100%を採点することはほとんど価値がなく、トラフィック自体のコストに匹敵する可能性があります。解決策は、統計的な誠実さを持ったサンプリングです。すべてのルートからの小さなランダムな割合は、全体的な品質の偏りのない推定値を提供します。ターゲットサンプリングは、高ボリューム、高リスク、または最近変更されたものなど、最も重視するルートの割合を上げます。サンプルから推定しているため、すべての品質数値には不確実性が伴い、低ボリュームのルートでの小さなサンプルは、実際の変更とは関係のない理由で変動する可能性があります。
ホットパスから外して非同期でサンプリングと採点を行う(図解)
# Scoring runs after the response is returned — never adds latency to the user.
def on_response(req, resp):
rate = 0.20 if req.route in HIGH_RISK_ROUTES else 0.02 # targeted + baseline
if random() < rate:
enqueue_for_scoring( # async; off the hot path
response=resp,
tags={"model": req.model, "route": req.route,
"prompt_version": req.prompt_version}, # slice keys
)この誠実さを保つには2つの規律があります。ユーザーの応答にレイテンシーを追加しないように採点を非同期で実行すること、そしてノイズの多い低ボリュームのスライスがトレンドと誤解されないように、サンプルサイズとともに品質を報告することです。サンプリングは、費用のかかる「すべてを採点する」という行為を、手頃な価格で統計的に有効な手段に変えます。
単一のグローバルな品質数値は、診断にはほとんど役に立ちません。他のすべてが維持されている間に、あるルートが劣化(リグレッション)したことを教えてくれないからです。品質は、当社の コスト帰属に関する投稿でコストが分割されるのと同じ方法で分割される必要があります。モデル別、ルート別、プロンプトバージョン別、そして変更が影響を及ぼしうるその他のあらゆるディメンション別です。これらのスライスキーは、ゲートウェイがすでにすべてのリクエストに付与しているメタデータそのものであり、だからこそ品質は別のシステムではなく、コストとレイテンシーの隣に位置すべきなのです。
品質をコストやレイテンシーと同じ軸に置くことで、トレードオフが隠されることなく可視化されます。リーナの変更は、彼女がデプロイしたその日に、あるルートでの品質低下としてすぐに現れたでしょう。それは、彼女が喜んでいたコスト低下のすぐ隣に表示され、これら2つの数値は常に一緒に読み取るべきものです。 TrueFoundryのAI Gateway は、リクエスト/レスポンスログ、メタデータタグ付け、トレース、コスト、レイテンシー、ルーティングコンテキスト(モデル、チーム、メタデータ別に分割)といった可観測性の基盤を提供し、この採点がそれにアタッチされます。ここで説明する審査と採点のループは、特定の評価統合を通じて組み込まれない限り、そのテレメトリーの上に構築するアーキテクチャパターンです。オンライン評価は、ゲートウェイがすでに収集しているシグナルに品質推定値を追加するものです。
具体的には、オンライン評価が発する単位は、元の応答に結合された採点イベントです。実用的な最小限のスキーマは次のようになります。これらのフィールドは、実行可能なシグナルと誤解を招くシグナルを区別するものです。
品質を分割することで、リグレッション検出が可能になります。ルート上の新しいモデル、プロンプトの編集、ルーティングポリシーの更新といった変更の前後で、スライスにおける品質推定値を比較し、ノイズよりも大きく低下した場合にアラートを発します。スコアはサンプリングされておりノイズがあるため、比較は不確実性を考慮する必要があります。サンプルの誤差範囲内の低下はリグレッションではなく、小さなスライスは、その変動を信頼する前に、より大きなまたはより長いサンプルを必要とします。
変更前後のスライスを比較し、サンプルノイズを考慮する(図解)
before = quality_scores(route="support", prompt_version="v3") # baseline window
after = quality_scores(route="support", prompt_version="v4") # after the change
drop = before.mean() - after.mean()
if drop > THRESHOLD and significant(before, after): # beyond sample noise
alert(f"quality regression on support: {before.mean():.2f} -> {after.mean():.2f}")
# optionally: auto-roll back the route to the prior version/model成功の鍵はタイミングです。適切なスライスに対する回帰チェックにより、リーナの2週間の空白が即日アラートに変わります。サポートルートの品質推定値がノイズ以上にベースラインを下回った瞬間、エスカレーションで問題が表面化するずっと前に、担当者に通知が届きます。自動ロールバックするか、単にアラートを出すかは、そのスライスにおけるシグナルの信頼度によって判断が分かれるところであり、セクション3でのキャリブレーションが重要であるのはそのためです。
品質を個別の分析パイプラインではなくゲートウェイで測定する理由は、ゲートウェイがルーティングの決定も行われる場所だからです。そのため、シグナルを決定に活用できます。私たちの ルーティングに関する投稿 では、品質を意識したルーティングは、実現には品質シグナルが必要な願望であると説明しました。オンライン評価がそのシグナルです。スライスごとの品質スコアがあれば、ルーティングは静的な推測ではなくフィードバックループになります。測定された品質が維持されている間だけ、より安価なモデルをそのルートで促進し、維持できなくなったらアラートを出すかロールバックします。どちらにするかは、そのルートのリスクと、そのスライスにおけるシグナルの信頼度によって異なります。
これにより、冒頭で未解決だったループが閉じられます。リーナのコスト削減変更は、まさにライブの品質シグナルに基づいてゲートされるべき決定です。より安価なモデルをデプロイし、そのルートの品質推定値を監視し、品質が許容範囲内である限りコスト削減を維持します。ゲートウェイは、スコアリング対象の応答を認識し、調整のためのルーティング決定を行う唯一の場所です。そのため、単なる測定場所ではなく、このループにとって適切な拠点となります。
すべての評価が同じ場所にあるわけではなく、その区分を明確にすることが重要です。オフライン評価はCIで行われ、固定されたテストセットに対して、既知のケースでのデプロイをゲートします。アプリケーションレベルの評価は、スコアリングにゲートウェイが持たないコンテキスト(ドメインの真実、ビジネス成果、ユーザーのタスクが実際に成功したかどうかなど)が必要な場合にアプリ内で行われます。ゲートウェイレベルのオンライン評価は、横断的なシグナルのためにゲートウェイで行われます。これは、ライブトラフィックに対するサンプリングされ、スライスされた品質推定値であり、コストとレイテンシーのテレメトリーに付随し、ルーティングにフィードバックされます。
ゲートウェイは他の2つを置き換えるものではなく、それらが残すギャップを埋めます。つまり、すべてのトラフィックにわたる継続的で一貫した品質監視を、応答を監視しルーティングに作用できる唯一の場所で行うのです。これこそが、このシリーズ全体でゲートウェイが果たすと主張してきた役割です。最も測定が困難で最も重要なシグナルに適用される、横断的なコントロールプレーンとしての役割です。
なぜオフライン評価だけでは不十分なのですか?
固定されたテストセットには、想定したケースしか含まれていないからです。本番環境には、想定外のロングテールや時間の経過によるドリフト、ライブ変更による回帰が発生します。リーナのより安価なモデルはオフラインテストを通過しましたが、テストセットが実際のサポートトラフィックと似ていなかったため、本番環境で回帰しました。オフラインは事前チェックであり、オンラインは現実に対する継続的な計測器です。両方が必要です。
LLMが別のLLMを評価することを信頼できますか?
真実ではなく、キャリブレーションされたトレンドシグナルとして使用します。評価モデルにはバイアス(長さ、自己選好、位置など)があり、完全に一貫しているわけではありません。そのため、人間のラベル付けされた例に対して評価モデルをキャリブレーションし、タスクに対する人間の判断をどの程度追跡できるかを学習させます。個々のスコアに基づいて行動するのではなく、時間の経過やスライス全体でのスコアの傾向を追跡し、未キャリブレーションの評価モデルのみに基づいてリリースをゲートしないでください。それは有用ですが、完璧ではないツールです。
冒頭の事態をどうすれば防げたでしょうか?
サポートルートにおける、モデルとプロンプトバージョンでスライスされたサンプリング品質スコアと、変更前のベースラインに対する回帰チェックです。リーナがモデルを切り替えた日、そのルートの品質推定値はコストの低下と並行して低下し、回帰アラートが発動したでしょう。それにより、2週間の盲点を即日のシグナルに変えることができたでしょう。コスト削減自体は間違いではありませんでした。品質シグナルなしでそれをデプロイしたことが間違いだったのです。
どれくらいのトラフィックをスコアリングする必要がありますか?
統計的に意味のあるスライスを得るのに十分な量です。これは、ボリュームと検出する必要がある変更の大きさによって異なります。すべてのルートにわたる小さなランダムベースラインと、重要度の高いルートや最近変更されたルートに対するより高いターゲットレートが、妥当なデフォルトです。品質は常にサンプルサイズとともに報告し、信頼できる十分なサンプルが得られるまでは、低ボリュームのスライスでの動きには懐疑的であるべきです。
オンライン評価にはゲートウェイとアプリケーションのどちらを使用しますか?
異なるシグナルのために、両方です。ゲートウェイは、すべての応答を認識しルーティング決定を行うため、横断的なシグナル(ライブトラフィックにおけるサンプリングされた品質を、コストとレイテンシーに付随させてスライスし、ルーティングにフィードバックするもの)を担当します。アプリケーションは、ユーザーの実際のタスクが成功したかどうかなど、ゲートウェイが持たないコンテキストを必要とする評価を担当します。それらは競合するものではなく、補完し合う関係です。
簡単に取得できる3つのシグナルは、インフラが提供してくれるため、常に最初に計測する対象となります。品質は、レスポンスをサンプリングし、正直にスコアリングし、スコアを細分化し、回帰を監視することで、自分でシグナルを構築する必要があるものです。レスポンスとルーティングの決定が既に行われているゲートウェイでそのシグナルを構築すれば、静かに品質を損なう次のコスト削減の変更は、2週間の謎ではなく、即日アラートとなるでしょう。
NorthwindとLeenaは例示であり、示されている品質数値と閾値も同様です。LLM-as-a-Judgeは既知のバイアスを持つノイズの多い推定器であり、真実ではありません。記述されたスコアは、判決として扱われるのではなく、人間のラベルと照合して傾向を追うべきであり、オンライン評価は品質を保証するものではないものの、盲点を減らします。TrueFoundryの機能は、2026年6月時点の公開製品ドキュメントから要約されており、今後進化する予定です。コードサンプルは、記述されたパターンを例示するものであり、参照実装からコピーされたものではありません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


