













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
シングルエージェントシステムはモデルやツールを呼び出します。マルチエージェントシステムは、エージェントがエージェントを呼び出すという新たな要素を追加します。オーケストレーターがサブエージェントに委任したり、まだ新しいAgent2Agentプロトコルを介してエージェント同士が作業を受け渡したりする、このイースト・ウエストトラフィックこそが、コストが膨れ上がり、影響範囲が広がり、「どのエージェントが何をしたか」が不明になる原因です。これらのプロトコルは、エージェントが互いをどのように発見し、作業を交換するかを標準化し、セキュリティフックを提供しますが、企業のIDモデル、ポリシグラフ、予算モデル、可観測性、制御プレーンを規定するものではありません。本稿では、このガバナンス層について、そしてそれがなぜゲートウェイに属するべきなのかを説明します。
プラットフォームエンジニアのトマスは、 コストアラートと謎に直面しました。一夜にして、会社の新しいマルチエージェント研究ワークフローは、前月全体の費用を上回る額を消費していました。オーケストレーターエージェントがサブタスクを複数のサブエージェントに委任し、そのうちの1つのサブエージェントが一時的なエラーに遭遇した際、オーケストレーターを再呼び出しすることでリトライし、オーケストレーターは再び委任するというループが何時間も続きました。朝までに、エージェント同士は何万回も呼び出し合っていました。トマスは、どのエージェントがそれを開始し、どこでサイクルが形成されたのかを知りたかったのですが、それができませんでした。すべてのエージェントが同じ共有サービスキーで認証されており、エージェント間の呼び出しはグラフとして記録されておらず、トリガーとなるエージェントごとのレート制限もなかったからです。システムにはモデルプロバイダーへの呼び出しに対するガバナンスはありましたが、自社エージェント間の呼び出しに対するものはほとんどありませんでした。
これがマルチエージェントシステムが抱える課題です。エージェントが互いに委任し始めた瞬間、デフォルトではIDもポリシーもトレースもない新しい内部ネットワークが生まれます。エージェントフレームワークはワークフローの構築を助けますが、それを統制するものではありません。本稿では、マイクロサービスメッシュなしでは運用しないような、その内部ネットワークに同じID、制限、可観測性を与える方法を説明します。
これまでのゲートウェイの文脈では、トラフィックのほとんどはノース・サウス(アプリケーションがモデルを呼び出す、あるいはツールを介して呼び出す)でした。マルチエージェントシステムは、エージェントが他のエージェントを呼び出すというイースト・ウエストトラフィックを追加します。オーケストレーターが専門エージェントに委任し、専門エージェントが別のエージェントに相談し、結果が上位に戻されます。まだ新しいAgent2Agent (A2A) プロトコルは、エージェントが他のエージェントが発見できる能力記述(エージェントカード)を公開し、共通のインターフェースを介してタスクやメッセージを交換することで、これを標準的な形にしています。これは、MCPがエージェントがツールにアクセスする方法を標準化したのと同様です。
覚えておくべきアナロジーは、モノリスからマイクロサービスへの移行です。エージェントが互いに通信し始めた瞬間、カスケードリトライ、サイクル、ファンアウト増幅、単一の明確なコールスタックの喪失といった分散システムの障害モードを抱えることになります。そしてマイクロサービスと同様に、その解決策は呼び出しをなくすことではなく、すべての呼び出し元にIDを、すべての呼び出しにポリシーを、すべてのフローにトレースを与える層の背後にそれらを配置することです。エージェントにとって、その層こそがエージェントゲートウェイです。
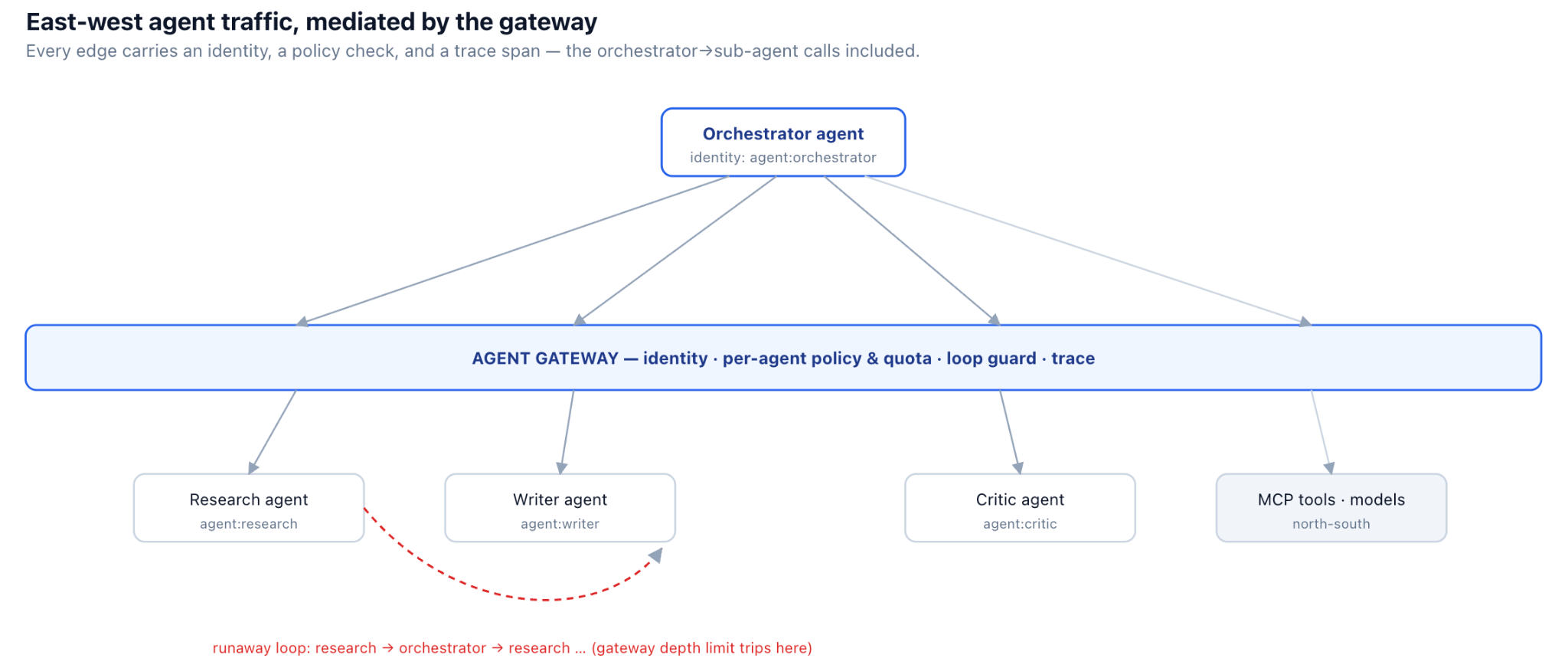
トマスの根本的な問題はIDでした。すべてのエージェントが1つの共有サービスキーで認証されると、システムは文字通りエージェントを区別できません。これは、異なる認可を与えたり、コストを個別に割り当てたり、どのエージェントが行動したかを再構築したりできないことを意味します。
解決策は、各エージェントにゲートウェイで発行・検証された独自のIDを与え、エージェントが行うすべての呼び出し(モデルへ、ツールへ、他のエージェントへ)でそのIDを伝播させることです。そのIDこそが、その後のすべての制御の鍵となります。認可決定、レート制限、コスト配分、トレース配分はすべて「どのエージェントか」に基づいて行われます。
各エージェントはすべてのホップで独自のIDを保持します(図解)
# The gateway issues and verifies a per-agent identity, not a shared key.
ctx = AgentContext(
agent_id="agent:research", # this agent's own identity
on_behalf_of="user:tomas", # the human principal, preserved end-to-end
run_id="run_4f9c", # correlates every hop of one workflow
depth=2, # how deep in the delegation chain we are
)
# Propagated when this agent delegates to another agent or calls a tool:
gateway.invoke(target="agent:writer", context=ctx, payload=task)IDを TrueFoundry's Agent Gateway で一元化すること(ゲートウェイ層でエージェントの認証、ID、サービスアカウント管理を行う)は、各エージェントフレームワークが独自のスキームを考案するのではなく、IDが一度確立され、ダウンストリームのどこでも信頼されることを意味します。エージェントIDとともに人間主体(ワークフローが実行される主体)を保持することで、3段階の委任があってもエンドユーザーの認可と監査が損なわれることはありません。
IDは認可を可能にし、マルチエージェントシステムでは具体的な疑問が生じます。研究エージェントはライターエージェントを呼び出せるのか、それともオーケストレーターだけなのか?サブエージェントは外部ツールを直接呼び出せるのか、それとも親を介してのみなのか?どのエージェントがどの予算を使用できるのか?これらをポリシー・アズ・コード(ガバナンスとルーティングに関する投稿で紹介したCedarやOPAと同じアプローチ)として表現することで、エージェントグラフの許可されたエッジが、コードに暗黙的に含まれるものではなく、明示的でレビュー可能なものになります。
イースト・ウエスト呼び出しに対するエージェントごとの認可(ポリシー例)
# Default-deny: an agent may only invoke agents it is explicitly allowed to.
allow if principal.agent_id == "agent:orchestrator"
and action == "invoke"
and resource.agent_id in ["agent:research", "agent:writer", "agent:critic"]
# Sub-agents may NOT invoke the orchestrator — this edge is what created the loop.
deny if principal.agent_id in ["agent:research", "agent:writer"]
and resource.agent_id == "agent:orchestrator"
# Only the research agent may reach external search tools.
allow if principal.agent_id == "agent:research"
and resource.kind == "mcp_tool"
and resource.name == "web_search"2番目のルールに注目してください。サブエージェントがオーケストレーターを再呼び出しすることを禁止するポリシーがあれば、レート制限に関係なく、トマスのループは最初のホップで遮断されたでしょう。ここでの認可は単なるセキュリティ制御ではありません。エージェントグラフの形状を制約することは、暴走する挙動のあらゆる種類を防ぐ方法でもあります。すべての東西間の呼び出しがゲートウェイを経由してルーティングされる唯一の場所であるため、ゲートウェイが強制ポイントとなります。
プロトコルが何を決定し、何をユーザーに委ねるのかについて、正確に理解することが役立ちます。ディスカバリとトランスポートは標準化されていますが、IDモデル、ポリシー、予算、強制ポイントは標準化されていません。
適切な認可があっても、マルチエージェントシステムは単一の呼び出しでは発生しない方法で障害を起こします。なぜなら、被害の単位がカスケードだからです。再委任するリトライはサイクルを形成する可能性があります。多数の子にファンアウトするエージェントは、1つのリクエストを数千に増幅させる可能性があります。遅いサブエージェントは、ワークフロー全体を停止させる可能性があります。これらは、おなじみのサンダリング・ハード問題やサイレント・エスカレーション問題のエージェントスケール版です。 モデル層でのルーティングとフェイルオーバー。
封じ込めは階層化されています。委任深度制限は、チェーンが再帰できる深さを制限し、構造的にサイクルを破壊します。エージェントごとのレート制限は、各エージェントが他のエージェントを呼び出す頻度を制限するため、ループが一晩中実行される代わりに上限に達して停止します。タイムアウトと停止検出は、エージェントが子を永遠に待つことを防ぎます。そして、グローバルな実行ごとの予算は、ワークフローの形状に関係なく、その総費用を制限します。TrueFoundryのAgent Gatewayは、関連するプリミティブ(リトライポリシー、フォールバックパス、タイムアウト、無限ループや停止したエージェントに対するセーフガード、さらにエージェント、ワークフロー、または環境ごとのトークンおよびコストベースのクォータ)を文書化しています。下記の正確な構成形状は例示であり、プリミティブは製品ページで説明されているものです。
マルチエージェント実行のための影響範囲制御(ゲートウェイ構成の例)
run_limits:
max_delegation_depth: 5 # breaks cycles structurally
max_total_tokens: 500000 # whole-run budget, force-stop past this
max_wall_clock_seconds: 600
per_agent:
invoke_rate_limit: 60/min # one agent can't call others without bound
timeout_seconds: 45 # stall detection on a child call
on_breach: halt_and_alert # stop the run, page a human考え方の転換は、マルチエージェントの実行を、際限のない会話ではなく、予算と深さを持つ境界のあるトランザクションとして扱うことです。これらの境界がゲートウェイで強制されることで、トマスの夜通しのループは、午前9時の5桁の請求書ではなく、午前2時に制限に達してアラートが発せられる事態になります。
リクエストごとのメトリクス(個々の呼び出しにおけるレイテンシ、トークン、エラー)は、マルチエージェントシステムにとって必要ではありますが、十分ではありません。なぜなら、最も必要なもの、つまり実行の形状を見失ってしまうからです。3段階の委任の奥深くで何かがうまくいかない場合、どのエージェントがどのエージェントを呼び出したか、どのような順序で、どのような入力と出力で、どこでコストが発生したか、というツリー全体が必要です。それは、エージェントのステップ、モデルの呼び出し、ツールの呼び出しにまたがるエンドツーエンドのトレースであり、すべてのホップが持つ実行識別子によって結合されます。
これは、私たちの OpenTelemetryに関する投稿と同じスパンモデルであり、エージェントを第一級のディメンションとして、実行をスパンを結合するトレースとして扱います。 TrueFoundry's Agent Gateway は、これらのエンドツーエンドの実行トレースをキャプチャし、ステップごとのログを検査して障害を診断できます。これにより、「エージェントが昨夜使いすぎた」という状況を「このエッジが深さ4でサイクルを形成した」という具体的な問題に変換でき、これは謎と解決策の違いです。
マルチエージェントシステムにおけるコストは、IDがなければ意味がありません。「ワークフローコストX」だけでは、その支出がオーケストレーターの計画呼び出しによるものなのか、あるサブエージェントの高価なモデル選択によるものなのか、あるいはループによるものなのかが分かりません。トークンとコストを特定の「エージェント、ワークフロー、実行」に帰属させること(セクション2のIDをキーとして)が、支出を明確にし、暴走を診断可能にするのです。
これは コスト帰属に関する投稿のチームごとの会計を、エージェントを単位として拡張したものです。エージェントゲートウェイは、トークンの使用量とコストを特定のエージェント、ワークフロー、チーム、環境に帰属させ、二重の役割を果たします。それは、財務上の疑問(どのエージェントが支出を増大させているか)に答え、運用上の異常(単一エージェントのコスト急増は、月額請求書が届くずっと前に、ループの最初の兆候となることが多い)を表面化させます。これをセクション4の実行ごとの予算と組み合わせることで、コストは観測可能かつ制限可能になります。
マルチエージェントシステムは、プロンプトインジェクションに新たな伝播経路を与えます。弊社の プロンプトインジェクションに関する投稿で述べたように、信頼できないコンテンツ(取得されたドキュメント、ツールの結果など)を読み取るエージェントは、その中に隠された指示によって操作される可能性があります。マルチエージェントシステムでは、その侵害されたエージェントが他のエージェントと通信し、その出力が他のエージェントの入力となります。研究エージェントに到達したインジェクションは、下流のライターエージェントや批評家エージェントに伝播する可能性があります。なぜなら、それらのエージェントにとって研究エージェントは信頼できる仲間であり、信頼できない情報源ではないからです。
これが、インジェクション防御が単なる入力境界の問題ではなく、エージェント間の懸念事項である理由であり、ゲートウェイで一元化することが重要である理由です。エージェント間のトラフィックがゲートウェイを経由してルーティングされると、すべての東西メッセージを監視し、各エージェントが仲間をスクリーニングするのを信頼するのではなく、ガードレールを一律に適用できるからです。
ここでのすべての議論は一点に集約されます。マルチエージェントシステムは分散システムであり、他の分散システムと同様に、すべての呼び出し元にIDを、すべての呼び出しにポリシーを、すべてのフローにトレースを、すべての実行に予算を与えるコントロールプレーンが必要です。それを各エージェントフレームワーク(LangChain、CrewAI、あるいは別のカスタムオーケストレーターなど)に組み込むことは、不整合とギャップを保証し、まさにTomásのループがすり抜けた場所となります。
エージェントゲートウェイがそのコントロールプレーンです。 TrueFoundryのエージェントゲートウェイ は、フレームワークに依存しないエージェントを単一の管理された実行レイヤーで実行します。エージェントごとのIDとRBAC、エージェントおよびワークフローごとのトークンとコストのクォータ、リトライ、タイムアウト、ループセーフガード、エンドツーエンドのトレース、MCP管理下のツールアクセスなどです。これにより、 AIゲートウェイのモデルトラフィック、 MCPゲートウェイのツールトラフィック、そしてマルチエージェントシステムのエージェント間トラフィックを一つに統合します。オーケストレーションパターン自体についてさらに詳しく知りたい場合は、TrueFoundryの マルチエージェントオーケストレーションガイド が役立つでしょう。この投稿は、それらが実行された後の管理についてです。
A2Aはまだ初期段階ではないか?なぜ今、統制する必要があるのか?
A2Aは企業での導入パターンとしてはまだ新しい段階にあり、プロトコル自体は正式なv1.0仕様となっているものの、エコシステムの慣習は今後も進化し続けるため、具体的な内容は暫定的なものとして扱うべきです。しかし、統制の必要性は導入が定着するのを待ってはくれません。エージェントがどのようなメカニズムであれ相互に委任し合った瞬間から、IDや制限のない東西トラフィックが発生します。ここに挙げられた制御(エージェントごとのID、認可、影響範囲の制限、トレーシング)は、エージェントがA2A、フレームワークのネイティブな委任、あるいはプレーンなHTTPのいずれを介して通信する場合でも適用されます。
これはマネージドエージェント層に関する以前の投稿とどう違うのですか?
その投稿では、エージェントのロジックとランタイム(エージェントコードがどこで実行され、どのようにデプロイされるか)を分離することを提唱していました。今回のテーマは、エージェントが稼働した後のエージェント間の通信を統制することです。具体的には、各ホップでのID、誰が誰を呼び出せるか、カスケードの抑制、実行のトレーシングなどです。関連する層ではありますが、問題は異なります。ランタイムの分離はデプロイ可能な単位としてのエージェントに関するものであり、今回のテーマはネットワーク参加者としてのエージェントに関するものです。
どのような単一の制御があれば、あのコールドオープンを防げたでしょうか?
2つの制御が連携することで防げたでしょう。サブエージェントがオーケストレーターを再呼び出しすることを禁止する認可ルールがあれば、最初のホップで構造的にループを遮断できたでしょう。また、委任深度の制限とエージェントごとのレート制限があれば、そのポリシーをすり抜けたサイクルも捕捉できたはずです。どちらの制御もワークフローの意図を理解する必要はありません。それらはワークフローの「形」を制限するものであり、そのため各エージェントのロジックではなく、ゲートウェイに配置されるべきなのです。
エージェントは本当にそれぞれ独自のIDが必要なのでしょうか?
エージェントごとに認可、属性付与、または監査する必要があるものについては、その通りです。共有キーでは、すべてのエージェントが単一のプリンシパルに集約されてしまうため、Tomásはどのエージェントがループを開始したのか、あるいはそれぞれにどれくらいのコストがかかったのかを特定できませんでした。人間プリンシパルを併せて保持するエージェントごとのIDは、この投稿で述べられている他のすべての制御が依存する基盤となります。
マルチエージェントの統制にはゲートウェイか、それともフレームワークか?
フレームワークはワークフローを構築し、ゲートウェイはそれを統制します。ID、認可、レートおよび深度の制限、トレーシング、コストの帰属は、実行するすべてのエージェントとフレームワーク全体で一貫している必要がある横断的な関心事です。これこそが単一のコントロールプレーンが提供できるものであり、フレームワークごとの実装では保証できない点です。
Tomásのインシデントは巧妙な失敗ではなく、統制されていない内部ネットワークが、統制されていないネットワークがするべきことをした結果でした。マルチエージェントシステムは、エージェントが自由に委任できるため強力です。そして、その自由さゆえに、すべてのエッジでID、制限、およびトレースが必要となるのです。そのコントロールプレーンをエージェントトラフィックの前に配置すれば、委任は午前2時のインシデントになる代わりに、機能として維持されます。
NorthwindとTomásはあくまで例示です。明確にしておくべき点があります。Agent2Agent (A2A) はオープンな通信プロトコルである一方、TrueFoundry Agent Gateway は、エージェントワークフローを管理するためのTrueFoundryの製品であり、コントロールプレーンの実装です。これらは異なるものであり、本稿ではゲートウェイが管理するトラフィックの標準的な用語としてA2Aを使用しています。TrueFoundry Agent Gatewayの機能は、2026年6月時点の公開製品ドキュメントに基づいて要約されており、今後も進化します。一部の機能はプレビュー段階である可能性があります。A2Aは企業での導入パターンとしてはまだ新しく、そのエコシステムの慣習は今後も進化し続けるため、ここでのプロトコルの詳細は高レベルで記述されており、最新の仕様で確認する必要があります。コードとポリシーのサンプルは、文書化されたパターンを例示するものであり、参照実装からコピーされたものではありません。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


