














May 8, 2024
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
AIを構築するほとんどのチームは、同じ壁にぶつかります。彼らは毎日、さまざまなプロバイダーやアプリケーションで何千ものモデル呼び出しを実行していますが、その内部で実際に何が起こっているのかほとんど把握できていません。どのプロンプトが機能したのか?なぜそのエージェントは奇妙な回答をしたのか?その応答は適切だったのか?これらの質問に答えるには、通常、各アプリケーションに手動でトラッキングコードを追加する必要があり、これは誰も好まず、ほとんどのチームが避けています。 TrueFoundry AI Gateway と HoneyHive の連携は、それらがすべて既に通過する唯一の場所であるゲートウェイを流れるすべての呼び出しを自動的にキャプチャすることで、この問題を解決します。
TrueFoundry AI Gatewayを、チームが使用するすべてのモデルの単一の玄関口と考えてください。各アプリケーションがOpenAI、Anthropic、またはその他のプロバイダーと直接やり取りする代わりに、すべてゲートウェイを経由します。誰が何を呼び出すことを許可されているか、リクエストがどのモデルに送られるべきか、そして物事を安全かつ制限内に保つかといった複雑な部分を、すべて一箇所で処理します。すべてのリクエストがこの単一の玄関口を通過するため、何が起こったかを記録するのに最適な場所でもあります。
最も良い点は、追加の計測が一切不要であることです。ゲートウェイは、各呼び出しの主要な詳細(使用されたモデル、かかった時間、関連するトークン、プロンプトと応答)を自動的に記録します。そして、これはリクエストがすでにユーザーに戻る途中で行われます。そのため、この可視性を追加しても、アプリケーションを使用するユーザーの速度が低下することはありません。
HoneyHiveは、これらすべての活動を実際に可視化し、エージェントを改善するための場所です。AI呼び出しの記録を取り込み、明確なエンドツーエンドの トレース、つまり単一のリクエストまたはセッション全体で何が起こったかを段階的に表示します。途中で使用されたツールやエージェントのステップを含め、入力、出力、タイミングが明確に示されます。何か問題が発生した場合、推測するのではなく、その軌跡をたどることができます。また、コーディングエージェントを使用して、Honeyhive CLIで問題の根本原因を特定することも可能です。
HoneyHiveは監視するだけではありません。記録された同じアクティビティは、 評価 と 実験に取り込むことができるため、AIが時間とともに改善しているか悪化しているかを測定し、変更をリリースする前にテストできます。トレースは単なる出来事のログではなくなり、品質を向上させるために使用できる実際の例となります。
これら2つのツールは、同じ言語を話すため、うまく連携します。TrueFoundryはすでにすべての呼び出しの記録を保持しており、HoneyHiveはその種の記録を読み取る方法を知っています。そのため、これらは単に接続するだけです。ゲートウェイを介してすでにルーティングされているトラフィックの場合、アプリケーション内にコードを追加する必要はなく、各チームが保守するものもありません。ゲートウェイでトレースのエクスポートを一度オンにするだけで、それ以降、TrueFoundryを介して流れるすべてのモデル呼び出しがHoneyHiveに自動的に表示されます。
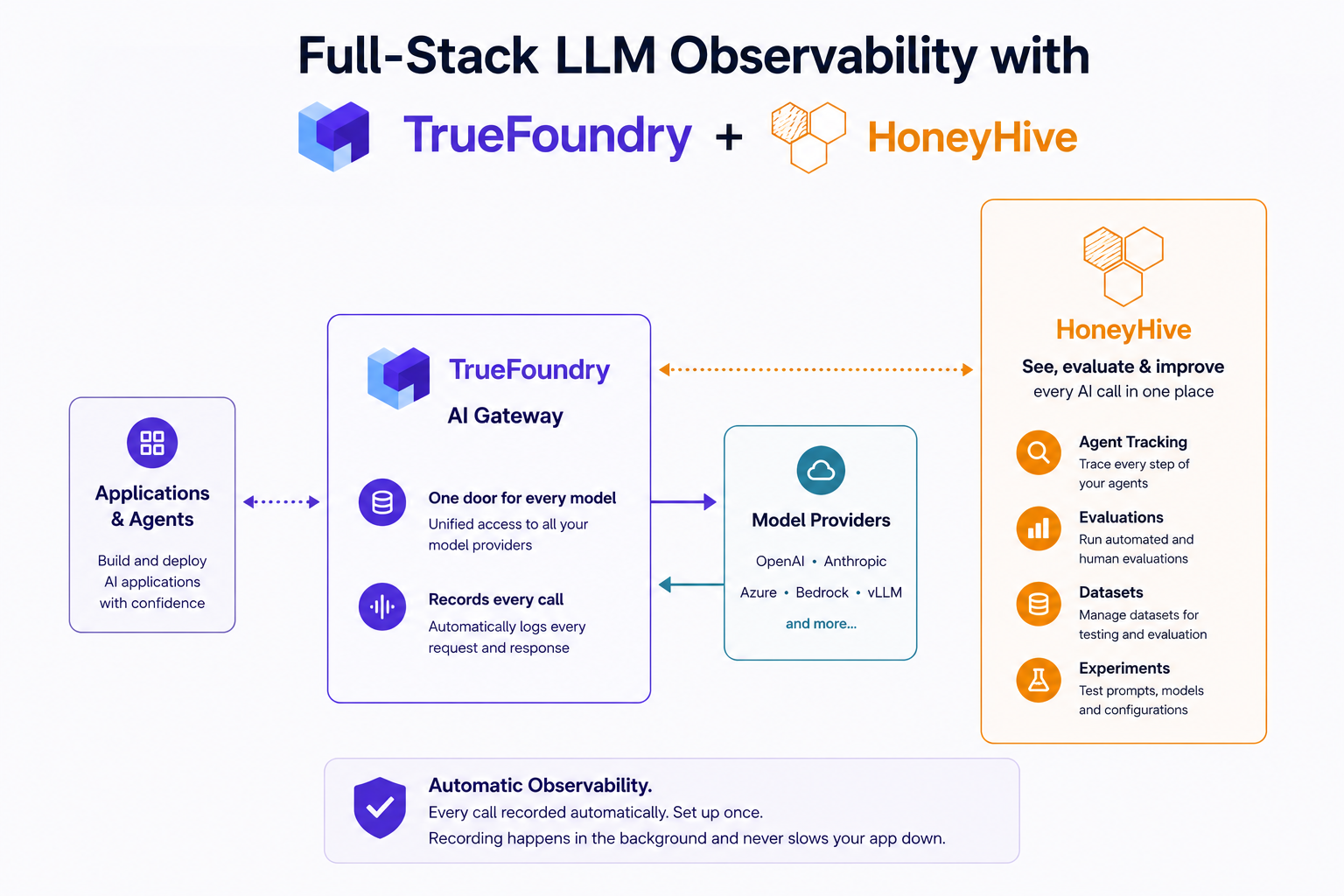
図1:リクエストはTrueFoundry AI Gatewayを介してモデルプロバイダーに流れ、ゲートウェイは各トレースのコピーをHoneyHiveに送信します。
接続は一方向のみで、既存の機能に追加されるだけです。ゲートウェイは、アプリの実行方法を変更したり、HoneyHiveをライブリクエストの途中に置いたりすることなく、完了した各呼び出しのコピーをHoneyHiveに送信します。機密データを扱う場合でも、単一の リクエストデータの除外 トグルをオンにすると、ゲートウェイからデータが送信される前にプロンプトとレスポンスの内容が削除されます。
重要なのは、常にユーザーが最優先されるということです。リクエストが応答され、その後でゲートウェイが静かにレコードをHoneyHiveに送信します。
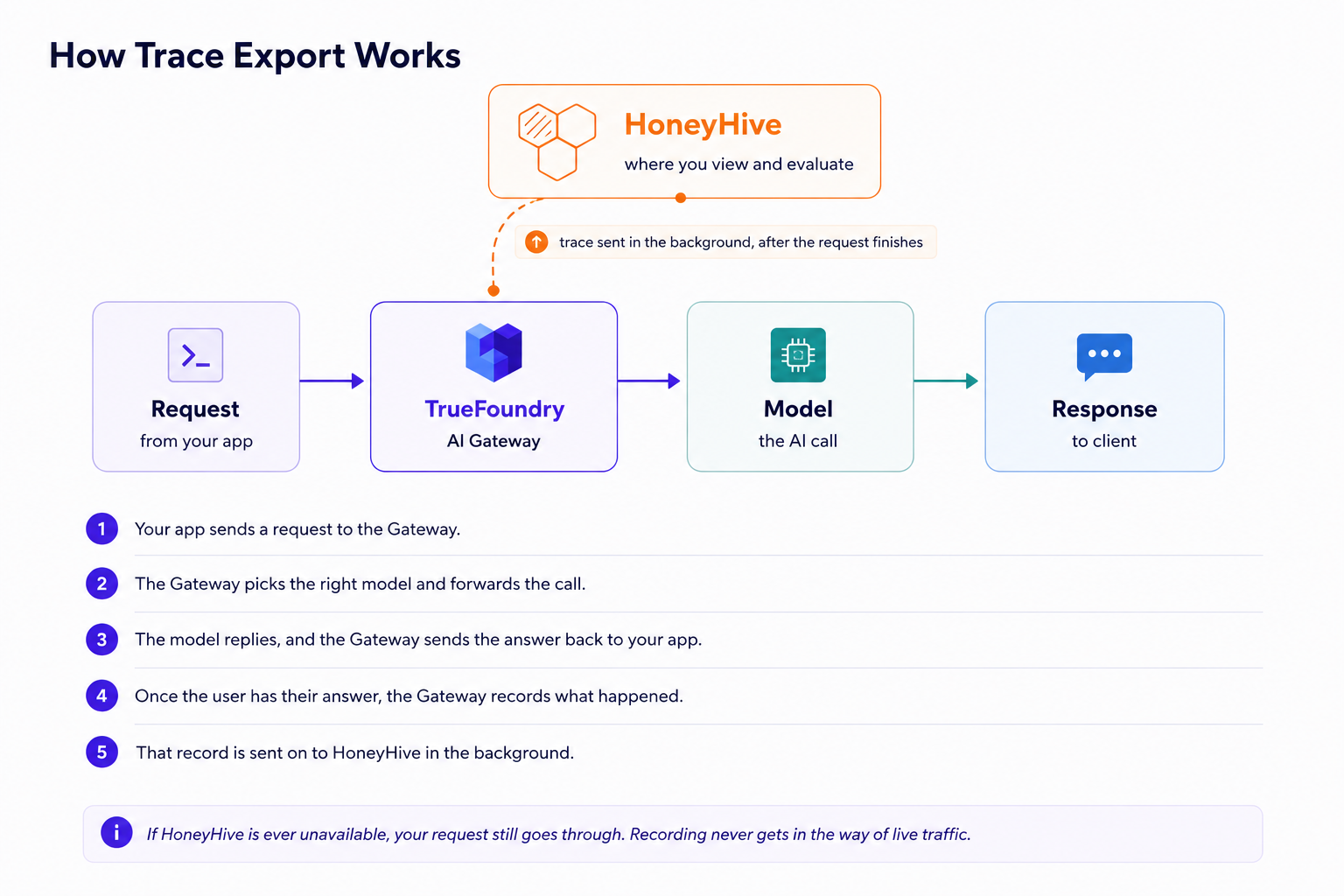
図2:リクエストはエンドツーエンドで応答され、その後、バックグラウンドでトレースがHoneyHiveに送信されます。
セットアップは設定変更であり、エンジニアリングプロジェクトではありません。HoneyHiveでプロジェクトAPIキーを作成し、TrueFoundryダッシュボードで「AI Gateway → Controls → Settings」を開き、OTELトレースエクスポーターを有効にして、HoneyHive OTLPエンドポイントを指定します。正確な値は以下の通りです。
トレースエンドポイント: https://<provider-host>/opentelemetry/v1/traces
プロトコル: OTLP/HTTP
エンコーディング: Json
認証ヘッダー: Authorization: Bearer <HH_API_Key>
接続を確認するには、ゲートウェイを介していくつかのリクエストを送信し、その後、HoneyHiveで「Observe → Traces」を開き、SOURCEがotlpに設定されている新しいイベントを探します。詳細な手順は TrueFoundry HoneyHive連携ドキュメント。
この連携が機能するのは、各ツールがそれぞれの得意分野に特化し、シンプルな接続を共有しているためです。TrueFoundryはAI呼び出しを実行および指示し、HoneyHiveはそれらを可視化し、測定し、改善するのに役立ちます。ゲートウェイがすでにすべての前に配置されているため、可視化は各チームが覚えておくべき面倒な作業ではなくなり、プラットフォームの機能の一部として自然に組み込まれます。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)




.png)








.webp)
.webp)


