













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Enterprise adoption of AI has shifted the locus of risk. The critical decisions are no longer confined to model selection or fine-tuning. In production systems, risk is introduced and either controlled or amplified at the AI Gateway layer. This is where inference is routed, models are selected, agents execute workflows, tools are invoked, and observability data is emitted.
As a result, long-standing concepts like data residency and data sovereignty can no longer be treated as static infrastructure concerns. In AI systems, they are runtime properties, enforced (or violated) by the gateway.
Many enterprises believe they have addressed data governance by deploying models in a specific cloud region. That assumption breaks down once AI Gateways introduce:
Understanding data sovereignty vs data residency in the context of AI Gateways is therefore foundational to running compliant, production-grade AI.
Traditional applications had relatively predictable data paths. Requests flowed from users to services to databases, often within a single region. AI Gateways fundamentally change this model.
An AI Gateway may, for a single request:
Each of these actions can introduce implicit cross-region data movement or access, even when the application itself appears local.
This is why AI Gateways become the de facto data control plane.
If residency and sovereignty constraints are not enforced at the gateway:
In other words, data governance failures in AI systems are usually gateway failures, not model failures.
This is also why generic assurances like “we deploy models in-region” are insufficient. Without gateway-level enforcement, enterprises cannot guarantee that:
The rest of this blog examines how data residency and data sovereignty differ, why AI Gateways must enforce both, and how platforms like TrueFoundry design their gateways to make these guarantees enforceable rather than aspirational.
Data residency defines where data is physically processed and stored.
In AI systems, this question is answered not by the model alone, but by the AI Gateway that orchestrates runtime execution.
From an AI Gateway perspective, data residency applies to:
Crucially, residency is enforced or violated at runtime.
In AI systems, data residency is not enforced by a single setting. It is enforced through a set of runtime primitives inside the AI Gateway that collectively constrain where execution can occur.
In platforms like TrueFoundry, these primitives operate before and during request execution, ensuring residency guarantees hold even under retries, failures, and dynamic routing.
Key enforcement primitives include:
Region-scoped model endpoints
Models are registered and exposed to the AI Gateway with explicit region affinity. The gateway can only route requests to model endpoints that belong to the allowed region. This prevents accidental use of globally hosted or cross-region models, even when multiple models are configured for the same workload.
Region-locked retry and failover pools
Retries and fallback are one of the most common sources of silent residency violations. A residency-aware AI Gateway constrains retry logic so that:
This ensures that high-availability behavior never overrides compliance intent.
Residency-aware routing tables
Routing decisions in the gateway are evaluated against region constraints at runtime. Even when routing is policy-driven (for cost, performance, or model selection), the gateway enforces residency as a hard constraint, not a preference.
This is especially important in multi-model setups where different models may be available in different geographies.
Residency-constrained observability exporters
Inference logs, prompts, responses, and traces often contain regulated data. A residency-aware AI Gateway ensures that:
This closes a common compliance gap where inference is local but metadata is not.
While data residency answers where data is handled, data sovereignty answers who ultimately controls the data and under which legal jurisdiction.
For AI Gateways, sovereignty is determined by:
A critical but often overlooked reality is this: Data can be resident in one country while being sovereign to another.
AI Gateways often interact with:
Even if inference happens locally, sovereignty can be compromised if:
For regulated enterprises, sovereignty is therefore a question of architectural control, not geography.
An AI Gateway that enterprises do not fully control cannot guarantee sovereignty regardless of where it runs.
At the AI Gateway layer, the difference between data residency and data sovereignty becomes operationally visible. Both must be enforced at runtime but they solve different risks.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

These are recurring failure patterns seen when AI Gateways are evaluated without a sovereignty-aware lens.
Enterprises deploy models in a local cloud region and assume compliance is handled. In reality, the AI Gateway may still:
Gateways often retry or fail over automatically. Without explicit constraints:
Even if inference is local, agents may invoke tools via the gateway that:
Prompts, responses, and traces often contain regulated data.
If the AI Gateway exports telemetry outside approved boundaries, sovereignty is compromised quietly.
Most AI platforms treat data governance as a deployment concern. TrueFoundry treats it as a runtime enforcement problem.
At enterprise scale, data residency and data sovereignty are not guaranteed by where infrastructure is deployed, but by how execution is controlled. In modern AI systems, where requests are dynamically routed across models, agents invoke tools, and observability pipelines export metadata the only layer with sufficient context to enforce governance correctly is the AI Gateway.
TrueFoundry is designed around this principle.
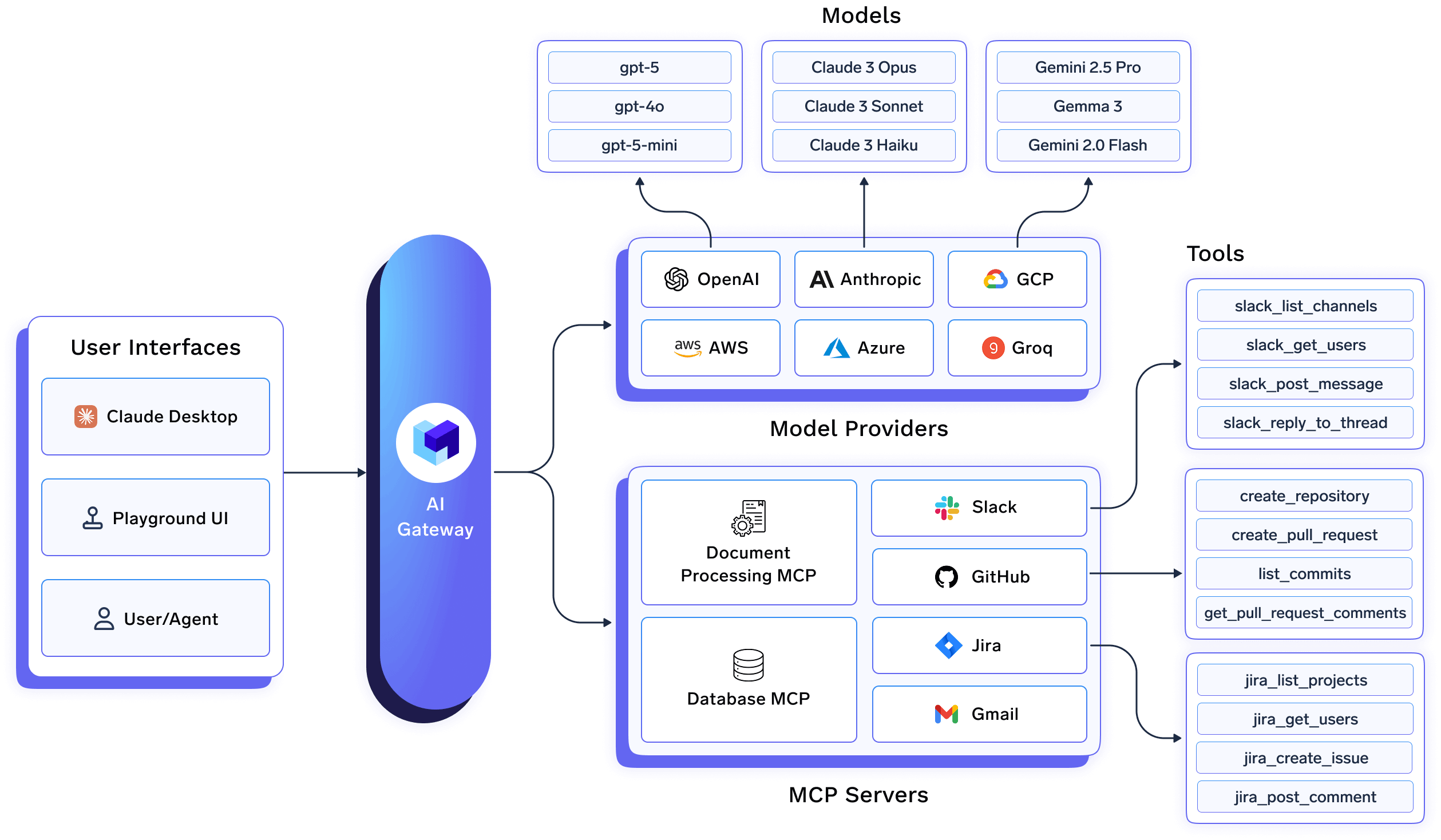
In TrueFoundry, the AI Gateway is not a thin proxy in front of models. It is a control plane that sits at the convergence point of:
Because every request passes through this layer, TrueFoundry can enforce both residency and sovereignty as first-class runtime policies, not best-effort guarantees.
This distinction matters.
TrueFoundry’s AI Gateway enforces residency by constraining execution paths, not by relying on static region selection.
Concretely, this means:
If a request cannot be satisfied within residency constraints, it fails closed rather than silently routing elsewhere.
This eliminates one of the most common compliance failures in AI systems: cross-region execution during exception paths.
Data sovereignty is fundamentally about who controls access、計算が実行される場所ではありません。
TrueFoundryは、企業が以下の点を制御できるようにすることで、主権を確保します。
ゲートウェイが企業の管理下にあるため、主権は以下に依存しません。
これは、推論がローカルで行われる場合でも、ホスト型AIサービスとは決定的に異なります。しかし、 制御はそうではありません。
TrueFoundryのアプローチの重要な利点は 一貫性です。レジデンシーおよび主権ポリシーは、以下全体にわたって一貫して適用されます。
これは、次のような一般的な障害パターンを防ぎます。
AIゲートウェイを共有の強制ポイントとして扱うことで、TrueFoundryはガバナンスが システム全体にわたる、断片的なものではなく、確実に適用されるようにします。
現代のAIシステムでは、データガバナンスはインフラがどこにデプロイされているかによって定義されるものではなく、 ランタイム時に実行がどのように制御されるかによって定義されます。モデル、エージェント、ツールが動的に相互作用するにつれて、 データレジデンシーとデータ主権 の両方が、意味を持つために一元的に強制される必要があります。
レジデンシーは どこで データが処理されるかを決定します。主権は 誰がそれを制御するかを決定します。片方だけを解決してもギャップが生じ、特にルーティング、フェイルオーバー、エージェントワークフロー、可観測性を処理するAIゲートウェイではそれが顕著です。
すべての推論リクエストとツール呼び出しがそれらを通過するため、 AIゲートウェイは、これらの保証を一貫して適用できる唯一の場所です。TrueFoundryはAIゲートウェイをガバナンスのコントロールプレーンと位置づけ、レジデンシーとソブリンティを 適用可能なシステム特性としています、仮定ではなく。
この違いこそが、AIを実験的な機能から、本番環境レベルの準拠したシステムへと変えるのです。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


