













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Braintrustは、AI評価と本番環境のトレースにおいて、本格的な可観測性プラットフォームとして確立されています。その強みは明らかで、チームは本番環境の動作をトレースし、評価を実行し、プロンプトとモデルを比較し、データセットを管理し、実際の障害を回帰テストに変換できます。厳格な評価ワークフローを求めるエンジニアリングチームにとって、Braintrustは依然として強力な選択肢です。
しかし、評価だけではニーズを満たせなくなった場合、チームはBraintrustの代替ツールを検討します。トレース量が多い場合に、より安価な価格設定を求めるチームもあれば、オープンソースのセルフホスティングを望むチームもあります。また、本番環境のトラフィックがプロバイダーに到達する前に、モデルアクセス、コスト管理、エージェントポリシー、MCP権限、監査証拠を強制するランタイムガバナンスを必要とするチームもあります。
このガイドでは、2026年におけるBraintrustの競合7社を比較し、各ツールの得意な点と限界を説明します。すべてのチームがBraintrustを置き換えるべきだと主張するものではありません。より明確な目標は、LLMチームが解決しようとしている問題に対して、適切なレイヤーを選択できるよう支援することです。
ツールを比較する前に、選定基準を明確にしましょう。Braintrustの代替ツールは、それぞれLLMライフサイクルの異なるレイヤーを解決するため、互換性があるわけではありません。強力なBraintrust代替ツールは、現在の運用モデルに不足している機能と合致するはずです。
言語と統合の対応範囲も重要です。特にアプリケーションコードが複数のサービスにまたがる場合、チームはPython、TypeScript、Ruby、Javaのワークフローへの対応を確認すべきです。計測、SDKの対応範囲、チームのワークフローが摩擦を生むまでは、単一のプラットフォームが魅力的に見えるかもしれません。

2026年の主要なBraintrust代替品は、大きく3つのグループに分けられます。評価とプロンプトの品質に焦点を当てるもの、トレースと可観測性に焦点を当てるもの、そして本番トラフィック、エージェント、ツール、コスト管理のためのランタイムガバナンスを追加するものです。
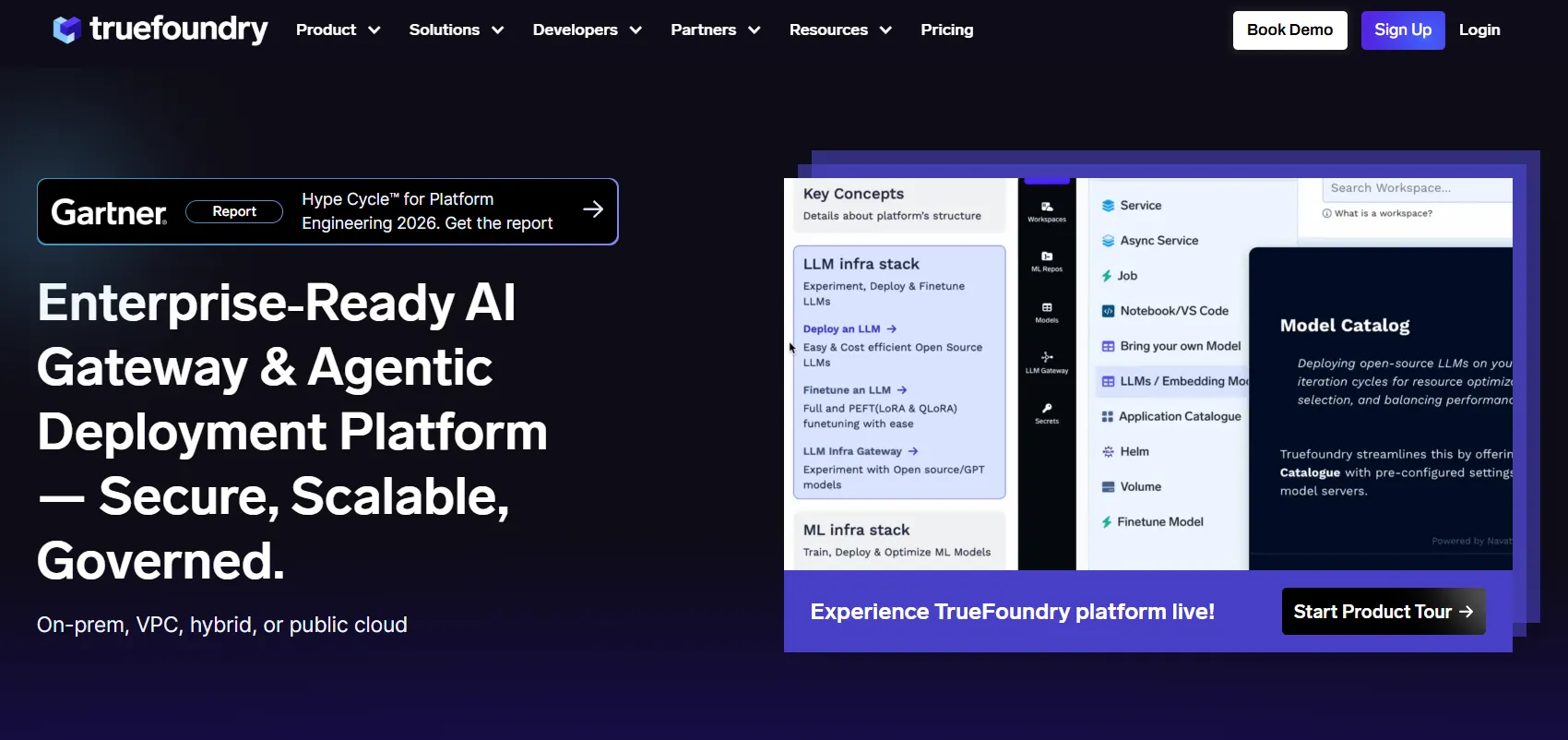
TrueFoundry は、主な課題がオフライン評価ではなく本番環境のガバナンスである場合、Braintrustの最良の代替品です。LLMスタックにインフラ層からアプローチし、本番トラフィックがプロバイダーに到達する前に、モデルアクセス、ルーティング、可観測性、エージェントポリシー、MCPツール制御、コスト強制が行われます。
純粋な評価ツールとは異なり、TrueFoundryはチームが本番環境で実行されるものを管理するのに役立ちます。その AI Gateway は、アクセス、ポリシーチェック、監視、ルーティング、フェイルオーバー、レート制限、監査証跡を一元化します。これにより、評価は存在するものの、ランタイムガバナンスが断片化されている場合に特に役立ちます。
TrueFoundryの料金には、初期開発者向けの0ドルのDeveloperプラン、月額499ドルのProプラン、月額2,999ドルのPro Plusプラン、およびカスタムのEnterpriseプランが含まれます。Enterpriseプランは、より厳格なガバナンス、セキュリティ、デプロイの柔軟性、およびミッションクリティカルな信頼性のために設計されています。
TrueFoundryは、エンタープライズAIプラットフォームチームや、複数のチームでLLMプログラムを運用する規制対象組織に最適です。評価は存在するものの、本番環境へのアクセス、ID、コスト、監査制御が断片化されている場合に特に役立ちます。
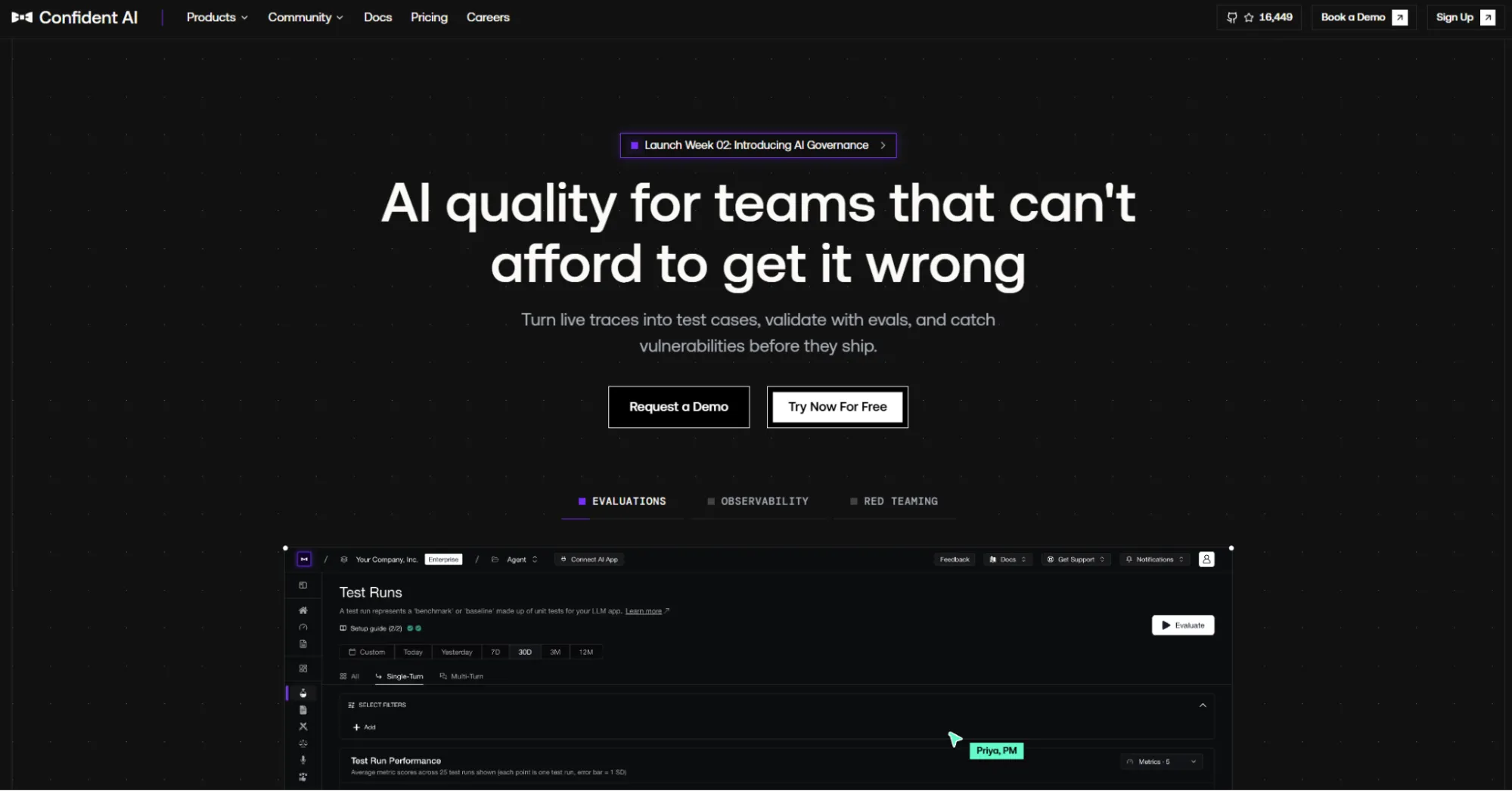
Confident AIは、実際のLLMアプリケーションにおける製品品質の評価ワークフローを求めるチームにとって、Braintrustの強力な代替手段となります。オープンソースのLLM評価フレームワークであるDeepEvalを基盤としており、コラボレーション、トレーシング、モニタリング、ダッシュボード、チームワークフローを追加します。
Confident AIは、評価の深さとQAまたはプロダクトチームからの幅広い参加を必要とするチームに最適です。リリース前のテストと本番環境の品質モニタリングを結びつけるグループに適しています。
Confident AIは主に評価および品質プラットフォームです。チームは、デプロイメント、アクセス制御、ポリシーのニーズを直接検証することなく、これを完全なランタイムガバナンスまたはAIインフラストラクチャのコントロールプレーンとして扱うべきではありません。
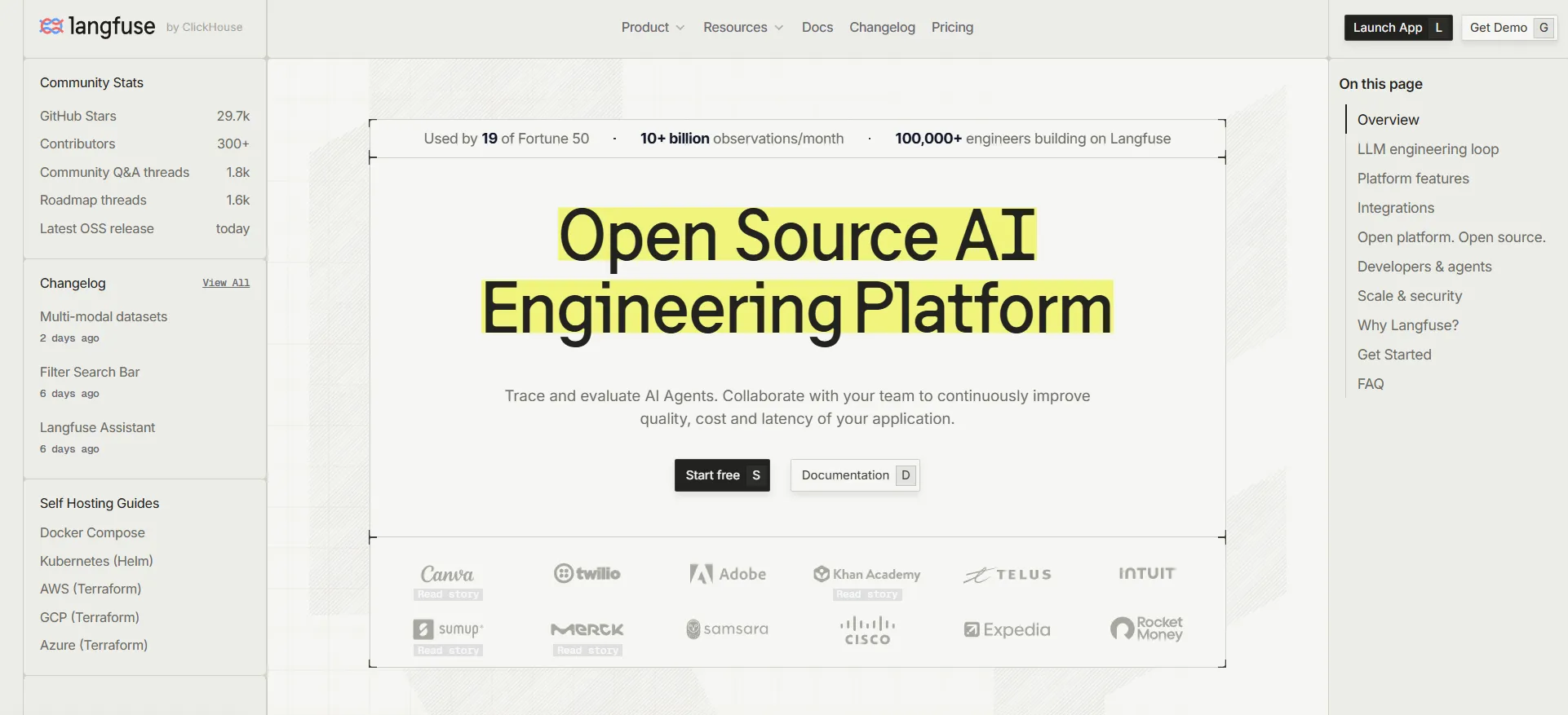
Langfuseは、セルフホスティング制御でLLMの可観測性、トレーシング、プロンプト管理、データセット、評価ワークフローを求めるチームにとって、Braintrustに対する最も強力なオープンソースの代替手段の1つです。また、コミュニティ採用のシグナルとしてGitHubスターを追跡しているチームにも魅力的です。
Langfuseは、オープンソース制御、セルフホスティング、および広範な可観測性カバレッジを求めるプラットフォームチームに最適です。独自の可観測性スタックを所有することを好むチームに適しています。
セルフホスティングは、運用上の明確なトレードオフを生み出します。チームは、オブザーバビリティスタックのスケーリング、アップグレード、ストレージ、セキュリティ強化、インシデント対応、長期的な信頼性について責任を負う必要があります。
.webp)
.webp)
LangSmithは、LangChainまたはLangGraphを既に利用しているチームにとって、実用的なBraintrustの競合製品です。計測の摩擦を軽減し、LangChainエコシステム内で開発者にトレーシング、デバッグ、データセット、評価、モニタリング機能を提供します。
LangSmithは、LangChainまたはLangGraphを頻繁に利用するチームに最適です。統合の摩擦を最小限に抑え、強力なデバッグワークフローを求める開発者にも適しています。
LangSmithは、ベンダーニュートラルな可観測性、オープンソースのセルフホスティング、またはLangChain以外のシステム全体でのインフラレベルのガバナンスを優先するチームにとっては、あまり魅力的ではありません。
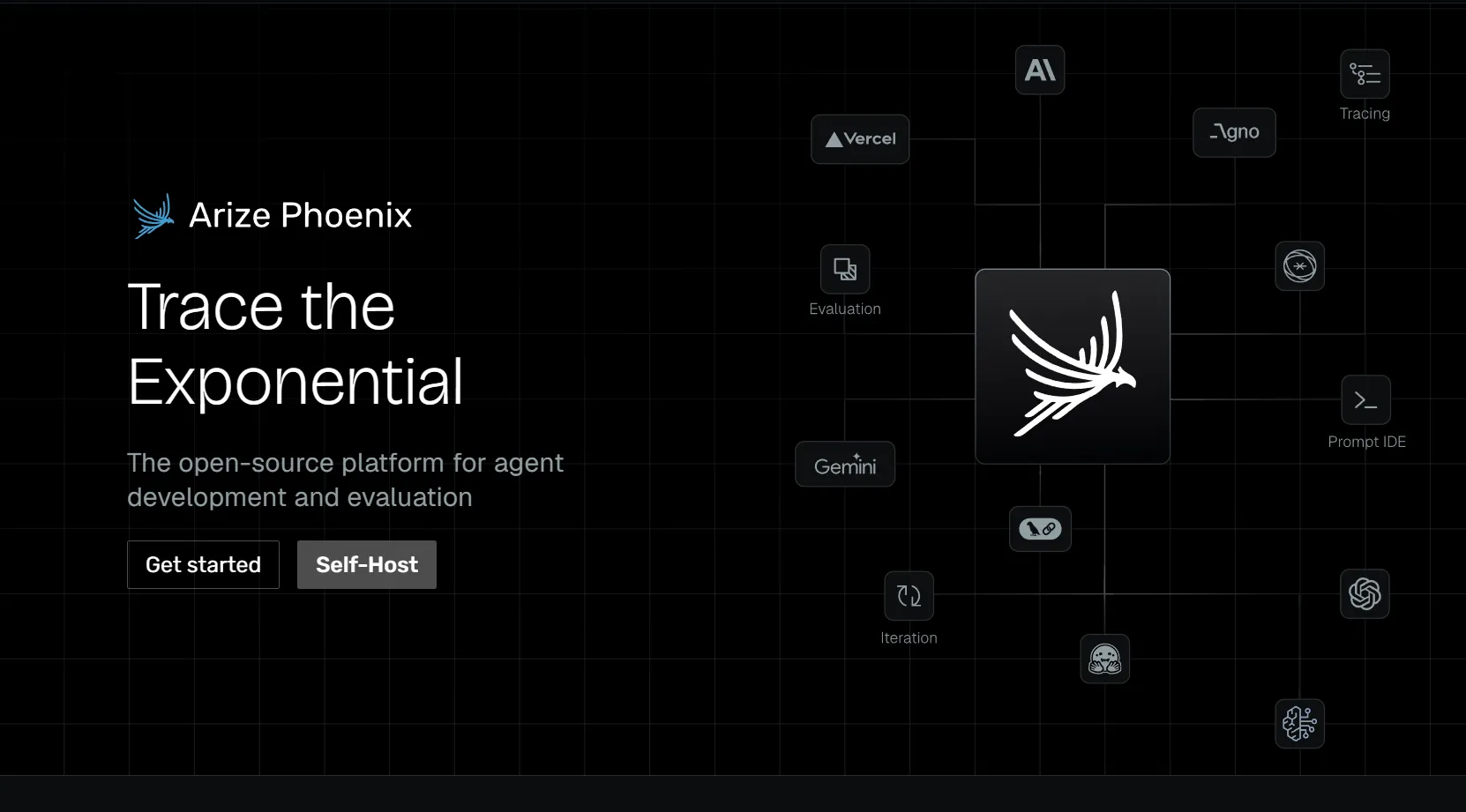
Arize Phoenixは、オープンソースのAI可観測性および評価プラットフォームです。特に、OpenTelemetryベースの計測、RAG評価、検索デバッグ、実験、トラブルシューティングのワークフローを重視するチームに適しています。
プラットフォームエンジニアリングの能力を持つチームで、強力なトレースおよび実験ワークフローを備えたオープンソースのLLM可観測性および評価ツールを求める場合。
Phoenixは強力ですが、規模、セキュリティ、サポートのニーズによっては、本番環境レベルのエンタープライズ運用には追加のプラットフォーム作業や商用版Arizeの導入が必要になる場合があります。
W&B Weaveは、すでにML実験トラッキングにWeights & Biasesを使用しているチームにとって、Braintrustの論理的な代替手段となります。これは、W&Bエコシステムを本番AIシステム全体におけるLLMの可観測性、評価、トレース、エージェントワークフローに拡張します。
W&B Weaveは、すでにW&Bを標準化しているMLチームに最適です。また、NVIDIAが支援するモデルワークフローやLLMアプリケーションを単一の運用モデルで追跡するチームにも適しています。
Weaveは、W&BがすでにチームのML運用モデルをサポートしている場合に最も強力です。純粋なLLM評価やセルフホスト型の可観測性については、Langfuse、Phoenix、またはBraintrustの方が評価しやすい場合があります。
.webp)
Heliconeは、軽量なAIゲートウェイおよびLLM可観測性プラットフォームです。迅速なセットアップ、OpenAI互換のルーティング、リクエストロギング、コストトラッキング、キャッシング、レート制限を、ゼロから詳細な計測を構築することなく実現したい開発チームにとって強力な選択肢となります。
Heliconeは、高速なLLMの可観測性とコスト追跡を求めるスタートアップやエンジニアリングチームに最適です。大規模なプラットフォーム実装作業を避けたいチームに適しています。
Heliconeは、主に詳細なオフライン評価ワークベンチやエンタープライズAIガバナンスプラットフォームではありません。規制対象のチームは、唯一のレイヤーとして採用する前に、ID、監査、データ管理、ポリシー適用に関するニーズを検証する必要があります。
このカテゴリにおける最大の落とし穴は、評価、可観測性、ガバナンスが同じものだと仮定することです。これらは関連していますが、同一ではありません。この違いは、チームが本番AIシステム向けにBraintrustの代替品を評価する際に重要になります。
したがって、実用的な問いは「どのツールが最適か?」ではありません。「現在のLLM運用モデルにどのレイヤーが欠けているか?」です。もしそのギャップが統一されたモデルアクセスとリクエストガバナンスであるならば、 LLMゲートウェイ 他の評価ワークベンチよりも重要性が増します。
.webp)
Braintrustは弱いわけではありません。強力なAIオブザーバビリティおよび評価プラットフォームであり、そのゲートウェイは、統一されたモデルアクセス、キャッシング、オブザーバビリティ、マルチプロバイダーサポートを追加します。信頼できる比較を行うには、Braintrustの代替案を議論する前に、その強みを認識すべきです。
適切な代替案は、どのレイヤーが不足しているかによって異なります。不足しているのがセルフホスティングであれば、LangfuseとPhoenixは注目に値します。評価の深さや部門横断的な品質ワークフローが不足しているなら、Confident AIは真剣に検討すべきです。チームがLangChainを主に使用しているなら、LangSmithは摩擦の少ない選択肢です。
チームがすでにW&Bを使用しているなら、Weaveは自然に適合します。軽量なゲートウェイオブザーバビリティが必要なら、Heliconeは魅力的です。各オプションは、その運用モデルが実際の問題と一致する場合、Braintrustの有効な競合となります。
本番環境のガバナンスに課題を抱えるエンタープライズチームにとって、TrueFoundryはこのリストの中で最も適しています。インフラストラクチャ制御レイヤーを通じて、モデルアクセス、エージェントアクション、MCPツール、コスト制限、オブザーバビリティ、監査証拠を管理する必要があるチーム向けに位置付けられています。
これは、TrueFoundryがあらゆる評価ワークフローを置き換えるという意味ではありません。本番環境へのアクセス、コスト、ID、監査制御のより強力な実施が必要な場合に、TrueFoundryが既存の評価スタックを補完できることを意味します。それが、AI品質の監視とAIリスクのガバナンスの違いです。
デモを予約する TrueFoundryがAIワークロードを本番環境のリスクに達する前にどのように管理するかをご覧ください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


The strongest Braintrust alternatives are TrueFoundry, Confident AI, Langfuse, LangSmith, Arize Phoenix, W&B Weave, and Helicone. The best choice depends on whether the team needs production governance, evaluation depth, self-hosted observability, LangChain-native tracing, ML workflow continuity, or lightweight gateway logging.
Braintrust is used for AI observability and evaluation. Teams use it to trace production behavior, run evals, compare prompts and models, manage datasets, score outputs, and catch regressions before release. It is strongest when teams need structured evaluation workflows and trace-backed quality improvement.
Confident AI is strongest when teams want structured evaluation workflows across engineering, QA, and product. It builds on DeepEval and provides tracing, dashboards, datasets, regression workflows, and built-in evaluation metrics. Braintrust remains strong for teams that prefer its evaluation, trace, Brainstore, and regression workflow.
Yes. Langfuse is one of the clearest alternatives to Braintrust for teams that want an open-source, self-hostable observability and evaluation platform. The tradeoff is operational ownership. Self-hosting means the team must manage scaling, upgrades, storage, security, reliability, and incident response.
Teams should consider TrueFoundry when the missing layer is production governance: identity-aware model access, MCP tool policies, agent governance, cost enforcement, routing, observability, and audit logs. It can complement an evaluation platform rather than replace one, especially when runtime policy needs stronger control.






最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


