













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
従来のソフトウェアシステムでは、障害は通常、明確に現れます。関数がエラーをスローしたり、サービスがクラッシュしたり、リクエストがタイムアウトしたりします。デバッグはほとんどの場合、決定論的です。AIエージェントは、このモデルを根本的に変えます。
エージェントは設計上、非決定論的です。中間ステップで推論し、ツールを動的に選択し、実行時に動作を適応させます。この自律性により、強力なワークフローが可能になりますが、検出とデバッグがより困難な新たな障害モードも引き起こします。
エージェントが本番環境で失敗した場合、完全にクラッシュすることは稀です。その代わりに、ループに陥ったり、誤ったツールを選択したり、不完全または古いコンテキストに基づいて不正確な決定を下したりする可能性があります。これらの障害は、明らかなエラー信号なしに、出力品質の低下、レイテンシーの増加、または予期せぬコストとしてのみ現れることがよくあります。
本番環境でエージェントを運用するチームにとって、これは従来の監視では不十分であることを意味します。 エージェントの可観測性 は、エージェントが実行時にどのように動作するかを理解し、障害モードを早期に特定し、これらのシステムを大規模に確実に運用するために必要です。
従来の可観測性がシステムの脈拍をチェックすることだとすれば、 AIエージェント の可観測性は、その心を読み解くようなものです。標準的なアプリケーションでは、固定されたコードパスを通じてデータの流れを追跡します。しかし、エージェントには固定されたパスがありません。実行中に独自の道を構築します。これは、内部で何が起こっているかを見るために、新しい視点が必要であることを意味します。
真の エージェントの可観測性 は、単純な稼働時間を超え、トレース、ツール呼び出し、決定ステップ、および障害という4つの特定の柱に焦点を当てます。
トレースがなければ、エージェントが質問に答えるのに3ドルを費やし、20秒かかったことはわかるかもしれませんが、その理由はわからないでしょう。適切に構造化されたトレースは、 再生を可能にします。 セッション全体を把握できます。エージェントがどこから開始し、どこで脇道にそれ、最終的にどのように結論に至ったかを正確に確認できます。
標準的な監視ツールは、コードが予測可能な一連の 「if-this-then-that」 ステートメントで構成される世界のために作られました。そのような世界では、エラーは明確な停止であり、成功は完了したタスクです。しかし、自律型エージェントに移行すると、成功と失敗の境界線は曖昧になります。ダッシュボード上では技術的に「健全」に見えるシステムでも、同時にユーザーの期待に応えられていない、という状況が発生し得ます。
従来の可観測性は、通常、次の2つの主要な柱に依存しています。 ログとメトリクスです。 どちらも、エージェントワークフローの流動的な性質に適用されると不十分です。
生のアプリケーションログは、サーバーのクラッシュやデータベースのタイムアウトを検出するのに優れています。しかし、 思考している エージェントは、必ずしもエラーログを生成するわけではありません。それは思考のストリームを生成します。
例: エージェントが大規模データベースから特定のドキュメントを見つけるタスクを与えられていますが、やや曖昧な検索ツールが与えられています。エージェントは再帰的なループに陥り、検索し、結果を見つけられず、わずかな変更を加えて再度検索する、という具合です。
従来のロギングの観点から見ると、これらのAPI呼び出しはすべて200 OKステータスを返す可能性があります。エージェントが実際には立ち往生し、予算を浪費しているにもかかわらず、ログには何千もの成功したヒットが表示されるでしょう。 呼び出しの背後にある「なぜ」がなければ、生のログは単なるノイズに過ぎません。
従来のメトリクスは、次のような高レベルの指標に焦点を当てています。 CPU使用率、メモリ、リクエストのレイテンシーなどです。 これらは依然として重要ですが、根本的に 文脈を考慮しない。
標準的なAPIでは、レイテンシーの急増はほとんどの場合、悪い兆候です。しかし、エージェントシステムにおいては、高いレイテンシーが実は成功の兆候であることもあります。
エージェントが特に複雑なクエリに遭遇し、精度を確保するためにさらに5つの推論ステップを踏むことを決定した場合、その レイテンシー は急増しますが、 品質 は向上します。
逆に、低いレイテンシーは、エージェントが早すぎる段階であきらめたか、浅い、幻覚的な回答を提供したことを意味する可能性があります。パフォーマンスメトリクスをエージェントの内部ロジックや意思決定パスと関連付ける方法がなければ、ダッシュボード上の数値は実際には誤解を招く可能性があります。エージェントを真に理解するには、メトリクスをエージェントが達成しようとしていた特定の目標に結びつける「推論スパン」を見る必要があります。
エージェントを効果的に管理するには、集計を見るのをやめ、シーケンスを見る必要があります。エージェントは本質的に一連の「ループ」であるため、重要なメトリクスは、各ループの健全性と、それらが最終目標にどのように接続しているかを記述するものです。
基本的な稼働時間監視を超えて進みたいのであれば、これらがあなたの可観測性スタックが優先すべき4つの主要なシグナルです。
エージェントワークフローでは、1つのユーザープロンプトが5つまたは6つの内部推論ステップをトリガーする可能性があります。ステップレベルのトレースは、 思考 モデルが各段階で持っていたものです。これには、LLMに送信された特定のプロンプト、生の出力、そして決定的に重要なのは、トークン使用量や確率スコアなどのメタデータが含まれます。
これらのステップの系譜を観察することで、ロジックがどこで逸脱し始めるかを特定できます。
例えば、エージェントがレポートの生成を任されているが、ステップ3でテーブルの再フォーマットを繰り返し試みて行き詰まる場合、ステップレベルのトレースは、この 論理的な摩擦 を即座に可視化します。これがなければ、最終的にタイムアウトする長時間実行中のリクエストしか見えません。
エージェントの速度は、使用するツールの速度に左右されます。エージェントがデータベースや検索APIを呼び出す際、そのツールの応答時間がエージェントの総実行時間に追加されます。可観測性ツールは、ツールのレイテンシーを個別のメトリックとして追跡しなければなりません。
エージェントの応答に30秒かかる場合、その遅延がLLMの「思考」によるものなのか、それとも低速なサードパーティAPIによるものなのかを知る必要があります。
ツールのレイテンシーを監視することで、外部連携に対して具体的なSLAを設定できます。特定の検索ツールが常に10秒の遅延を追加する場合、より高速なベクトルデータベースに切り替えるか、そのツールの基盤となるクエリを最適化することを検討するかもしれません。
複雑なシステムでは、初期段階の小さなエラーが最終的に完全な障害へと連鎖することがあります。これはエラー伝播として知られています。例えば、もし データ取得 ツールが不正な形式のJSONオブジェクトを返した場合、エージェントは次のステップでその不正なデータを「推論」しようとし、結果として幻覚的な最終回答を導き出す可能性があります。
エージェントの可観測性とは、 スパン レベルでのエラーがトレースの残りの部分にどのように影響するかを追跡することです。ツールがエラーを返した正確な瞬間と、エージェントがどのように回復を試みたかを確認する必要があります。再試行したのか? 適切に機能低下したのか? それとも、破損したコンテキストで盲目的に続行したのか?
リクエストあたりのコストが比較的固定されている標準的なチャットボットとは異なり、エージェントのコストは非常に変動します。ある実行では5セントかかるかもしれませんが、同じプロンプトでトリガーされた次の実行で、より多くの推論ステップが必要な場合は2ドルかかることもあります。
追跡 「実行あたりのコスト」 は、AI機能のユニットエコノミクスを理解する唯一の方法です。このメトリックは、単一セッション内のすべてのモデル呼び出しで使用されたトークンと、すべてのツール呼び出しのコストを集計します。
このコストをユーザー満足度やタスクの成功と関連付けることで、 「高コスト、低価値」 のパターンを特定し、オーケストレーションロジックを最適化して効率を高めることができます。
Here's The Evaluation Framework
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Request Tracing & Correlation | |||
| End-to-end request tracing | Can each request be traced from the application to the gateway to the provider or tool using a correlation ID? | Must have | ✅ Supported: OTEL-compliant traces with correlation IDs. |
| Prompt and response capture | Are full prompts, responses, system messages, and tool calls captured with configurable redaction? | Must have | ✅ Supported: full prompt and response capture with PII redaction. |
| Metadata enrichment | Are user, team, application, environment, model, and provider tags attached to every trace? | Must have | ✅ Supported: metadata enrichment on every request. |
| Trace search and filtering | Can traces be searched and filtered by any combination of metadata, latency band, error code, or model? | Must have | ✅ Supported: full-text and metadata search across traces. |

ワークフローが複雑になるにつれて、アプリケーション層でのエージェントのデバッグはすぐに非現実的になります。エージェントの実行は、多くの場合、複数のモデル、ツール、サービスにまたがり、断片的なテレメトリーを生成します。
AIゲートウェイは、アプリケーション、モデル、ツールの間に位置することで、一元化された可観測性レイヤーを提供します。すべてのインタラクションがゲートウェイを通過するため、エージェントの動作を完全かつ一貫した形で把握できます。
このアプローチにより、可観測性はベストエフォートのロギング作業から、構造化されたシステム全体にわたる機能へと変わります。
ゲートウェイは、すべてのエージェントインタラクションに対する統合されたインターセプトポイントとして機能します。プロンプト、モデルの応答、ツール呼び出し、リトライはキャプチャされ、一貫した形式に正規化されます。
これにより、複数のサービスやプロバイダーからのログを関連付ける必要がなくなります。エージェントがどのモデルやツールを使用しているかに関わらず、実行データは一元的に収集され、単一のワークフローとして分析できます。
ゲートウェイ層で相関識別子を注入することで、単一のエージェント実行に関連するすべてのイベントを階層的なトレースにグループ化できます。
これにより、チームはエージェントの実行を、ばらばらのリクエストではなく、構造化された一連のステップとして見なすことができます。統合されたトレースにより、品質、レイテンシー、またはコストの低下を引き起こした特定のモデル呼び出し、ツール呼び出し、または推論ステップを特定することが可能になります。
エージェントのデバッグにおいて最も困難な問題の一つは、モデルの意図とツールの動作の関係を理解することです。
ゲートウェイはインタラクションの両側を監視するため、以下を相関させることができます。
このクロスレイヤーの可視性により、チームは障害が不適切なプロンプト、モデルの制限、またはツール側の問題のいずれに起因するかを判断し、ターゲットを絞った改善を可能にします。
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
TrueFoundryは、エージェントの複雑な動作を、構造化された本番環境対応の可観測性スイートに変換します。AIゲートウェイを介して中央制御プレーンとして機能することで、CrewAI、Langroid、OpenAI Agents SDK、Strands Agentsなどの多様なフレームワーク全体でエージェントを監視、分析、デバッグすることを可能にします。
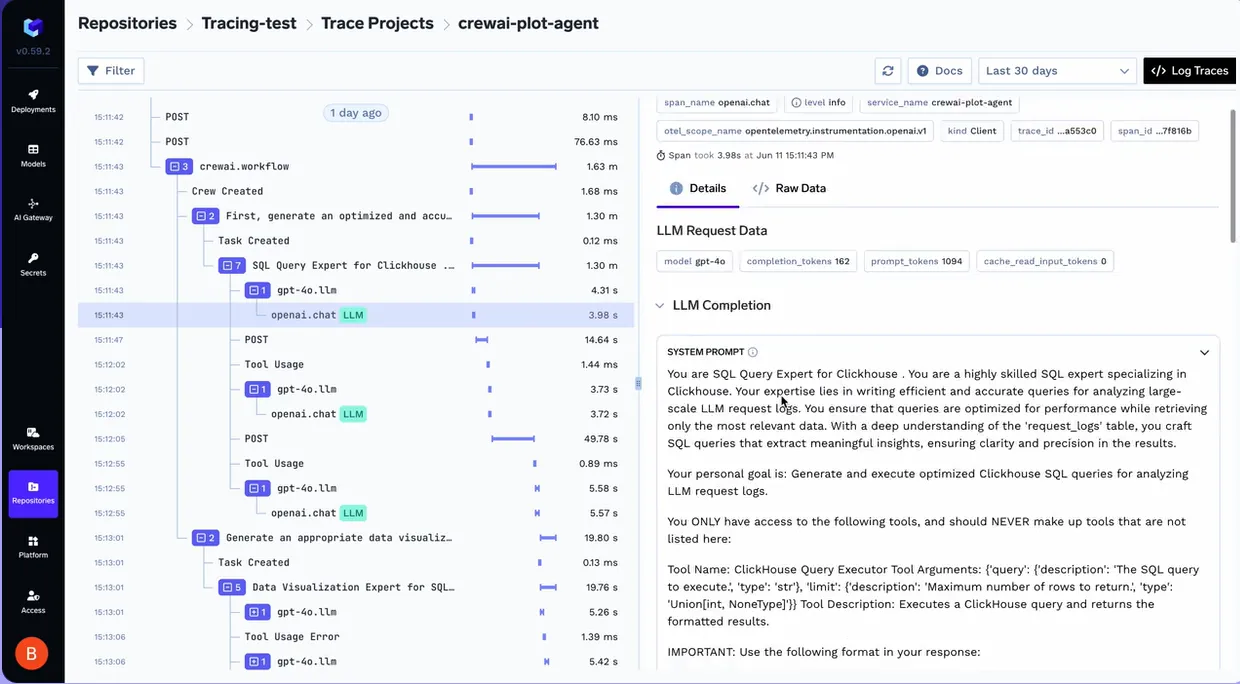
TrueFoundryは、エージェントが行うすべてのステップについて、高精度な可視性を提供します。 Traceloop SDKを利用することで、プラットフォームは複雑なエージェントワークフロー全体で詳細なトレース相関を可能にします。これは単なるロギングを超え、ユーザーの最初のプロンプトと、それに続くモデル呼び出しおよびツール実行の連鎖との間の階層的な関係を確認できます。
トレースを開始するには、アプリケーションコード内でSDKを初期化するだけです。
from traceloop.sdk import Traceloop
Traceloop.init(
api_endpoint="https://your-truefoundry-endpoint/api/tracing",
headers={
"Authorization": f"Bearer {your_pat_token}",
"TFY-Tracing-Project": "your_project"
}
)
TrueFoundryは、きめ細かなパフォーマンスデータを追跡することで、エージェントシステムにおける「レイテンシーの謎」を解決します。ダッシュボードでは、以下の包括的なビューを提供します。
ガバナンスとコスト管理は、オブザーバビリティスタックに直接組み込まれています。TrueFoundryは、 入力トークンと出力トークン の詳細な内訳を提供し、現在のプロバイダー料金に基づいて、モデルごとのコストを自動的に計算します。
チームは 使用パターンを分析できます 最もアクティブなユーザーを特定し、リクエストが異なるモデル間でどのように分散されているかを確認し、チームごとの費用を追跡して社内チャージバックに利用できます。組み込みのサポートにより、 レート制限と予算管理 TrueFoundryは、エージェントが運用上の制約内で動作することを保証し、よくある「予期せぬ高額請求」のシナリオを防ぎながら、エンタープライズの運用に必要な信頼性を維持します。
AIエージェントを本番環境で運用するには、従来の監視から深いオブザーバビリティへの転換が必要です。エージェントは推論し、行動し、動的に適応するため、その障害は技術的なものよりも論理的なものであることがよくあります。
AIゲートウェイでオブザーバビリティを一元化し、推論、ツール、コストに関する実行レベルの可視性を提供することで、チームは不透明なエージェントの動作を測定可能で管理しやすいものに変えることができます。適切なオブザーバビリティがあれば、エージェントは予測不能なブラックボックスではなく、本番システムの信頼できるコンポーネントとなります。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。







.png)








.webp)
.webp)


