













.webp)
July 4, 2026
|
5 min read

Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
In traditional software, an infinite loop is a nuisance. It spikes your CPU usage, maybe slows down a server, and you fix it by restarting the pod. The cost is negligible—electricity is cheap.
In Agentic Software, an infinite loop is a financial disaster.
Imagine two agents getting stuck in a politeness loop: "No, after you!" "I insist, you first!"
If these agents are running on GPT-4 at $30 per million tokens, and they exchange messages once per second, you can burn through thousands of dollars in a single afternoon.
To run agents in production, you cannot just give them API keys and hope for the best. You need an Internal Economy.
The TrueFoundry Agent Gateway acts as the Central Bank for your digital workforce. It mints grants, enforces quotas, issues stop-loss orders, and manages the exchange rates between different departments. For more details: .https://www.truefoundry.com/docs/ai-gateway/budgetlimiting.
The Problem: The Hidden Bill of Autonomy
The fundamental risk of agency is unpredictable consumption.
You need a system that governs Consumption Intent, not just request volume.
Let’s look at a real-world horror story: The recursive market analysis.
The Setup:
A user asks the Research Agent: "Find me all AI startups in California."
The agent is designed to:
The Failure Mode:
The agent finds a "List of 1,000 Startups" directory. It dutifully decides to visit all 1,000 links.
Each visit requires a browser tool call and a summarization call (GPT-4).
The Fix (With A2A Economy):
The best agent gateway implements a Budget Grant.
The system failed gracefully and cheaply, rather than succeeding expensively.
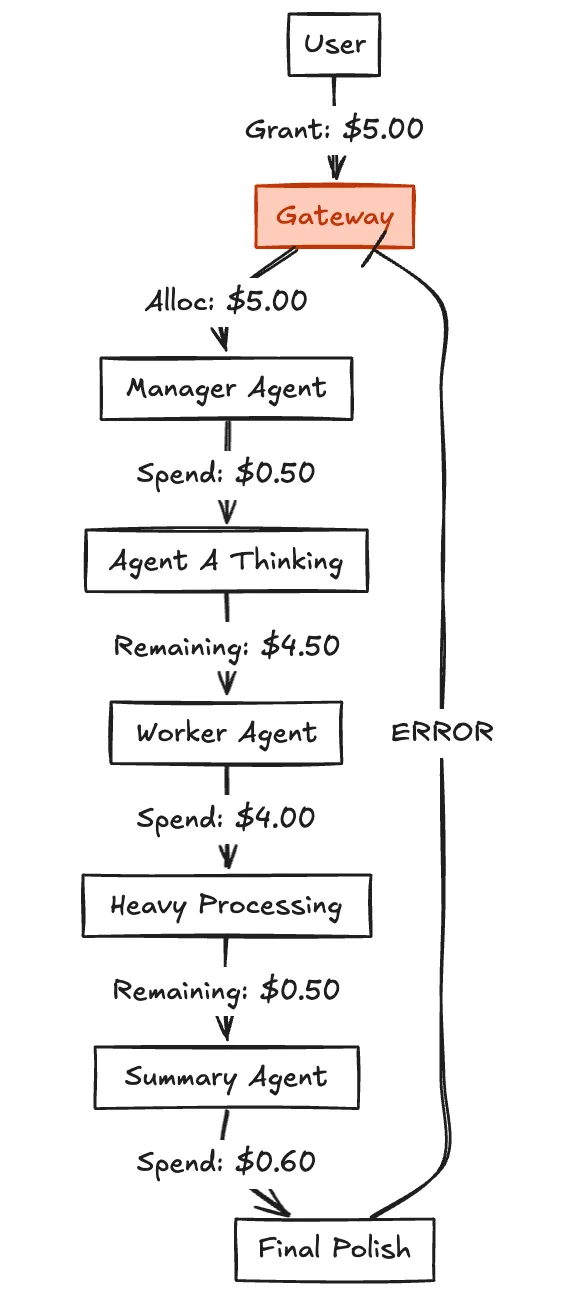
Fig 1: The Flow of the Budget Granting Process
We treat computation as a currency. Every request entering the Gateway must carry a Budget Context.
This is not a static monthly quota. It is a Per-Request Micro-Budget.
When a Manager Agent calls a Worker Agent, it must "pay" the Worker from its own wallet. This creates a natural incentive for efficiency. If the Manager wastes money, it fails its own task.
This enables Economic Reasoning within the agent's logic.
Budget caps handle the "Total Cost." But we also need to handle the "Speed of Spend".
A "Runaway Agent" (infinite loop) looks like a spike in financial velocity.
The Gateway monitors the change rate of cost .
If the velocity breaches the threshold, the Circuit Breaker trips. The session is frozen. A human admin is alerted. This protects against code bugs where an agent retries a failed tool call 100 times in a millisecond.
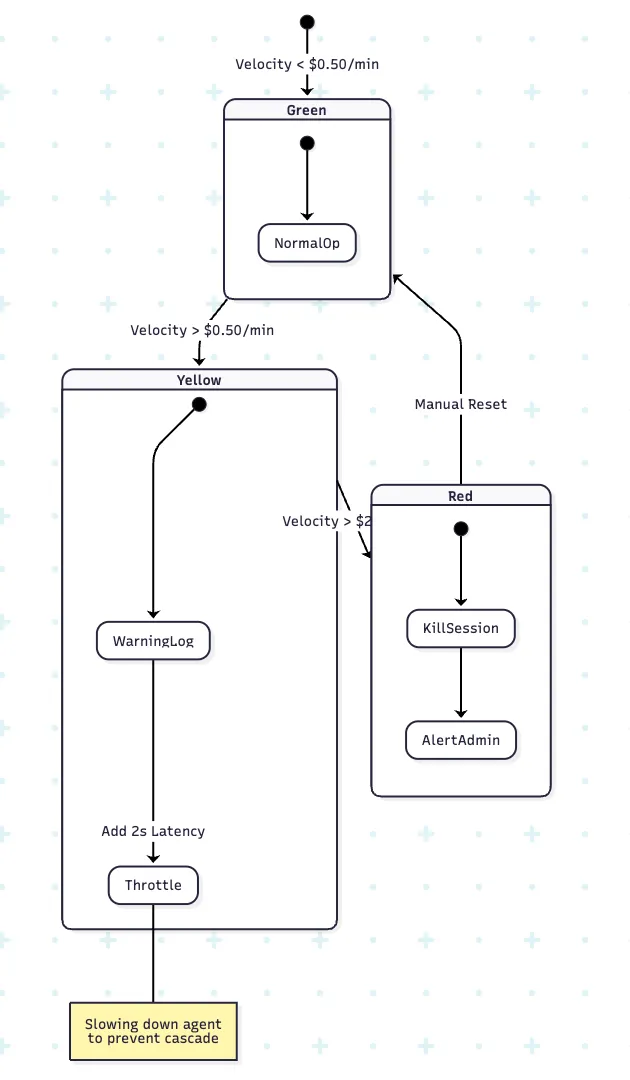
Fig 2: Handling the "Speed of Spend"
In a large enterprise, agents are shared services.
マーケティングのエージェントが技術部門のエージェントにデータを要求した場合、OpenAIの費用は誰が支払うのでしょうか?
技術部門が支払う場合、コスト削減のためにマーケティング部門をブロックするでしょう。これによりサイロ化が進みます。
マーケティング部門が支払う場合、どのように追跡すればよいでしょうか?
エージェントゲートウェイは以下を実装します 東西チャージバック。
月末に、ゲートウェイはCFO向けにレポートを生成します。これにより、エージェントはコストセンターから 内部サービスプロバイダーへと変わります。

エージェントが稼働する前に、費用を予測できるでしょうか?ここで AI向けFinOps は、実行前にコストを予測する上で特に役立ちます。
ゲートウェイにはシャドウFinOpsモデルが組み込まれています。これは、過去のエージェントの実行履歴に基づいて学習された、小さな回帰モデルです。
ユーザーがプロンプトを送信すると、 「第3四半期の財務報告書を要約してください」 シャドウモデルは次のように予測します。
ユーザーの個人制限が$0.20の場合、ゲートウェイはそのリクエストを拒否します 即座に、1回のGPUサイクルも無駄にすることなく。そしてユーザーには次のように伝えます。 「このタスクにはマネージャーの承認が必要です。」
説明責任のない自律性は無秩序です。その A2Aエコノミー 企業が安心してエージェントを導入できるよう、財務的な安全策を提供します。予算を厳守させ、無限ループを防ぎ、公正な費用配分を可能にすることで、AIを「支出のブラックボックス」から、測定可能で管理しやすい資本資産へと変革します。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。










.png)








.webp)
.webp)


