Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
Volumes bieten persistenten Speicher für Container in Pods, sodass sie Daten über mehrere Pods hinweg lesen und auf eine zentrale Festplatte schreiben können. Sie sind besonders nützlich beim maschinellen Lernen, wenn Sie Daten, Modelle und andere Artefakte speichern und darauf zugreifen müssen, die für Schulungs-, Bereitstellungs- und Inferenzaufgaben erforderlich sind.
In diesem Blog werden wir besprechen, wie Volumes genutzt werden können und welche Optionen in den einzelnen Clouds verfügbar sind.
Wann sollten Kubernetes-Volumes verwendet werden?
Einige Anwendungsfälle, in denen sich Volumes als sehr nützlich herausstellen:
Trainingsdaten teilen: Es ist möglich, dass mehrere Datenwissenschaftler an denselben Daten trainieren oder wir mehrere Experimente parallel mit demselben Datensatz durchführen. Der naive Weg wird darin bestehen, die Daten für mehrere Datenwissenschaftler zu duplizieren — aber das wird uns am Ende viel mehr kosten. Eine effizientere Methode wäre es, die Trainingsdaten auf einem Volume zu speichern und das Volume dann auf die Notebooks verschiedener Datenwissenschaftler zu montieren.
Modellspeicher: Wenn wir Modelle als Echtzeit-APIs hosten, wird es mehrere Replikate des API-Servers geben, um den Datenverkehr abzuwickeln. Hier muss jedes Replikat das Modell aus der Modellregistrierung (z. B. S3) auf die lokale Festplatte herunterladen. Wenn jedes Replikat dies wiederholt tut, dauert der Start länger und es fallen auch mehr S3-Zugriffskosten an. Mithilfe von Volumes können Sie Ihre trainierten Modelle extern speichern und auf dem Inferenzserver mounten. Das Modell muss nicht heruntergeladen werden; der API-Server kann das Modell einfach auf der Festplatte im bereitgestellten Pfad finden.
Teilen von Artefakten: Wir könnten einen Anwendungsfall haben, bei dem die Leistung einer Pipeline-Stufe von der nächsten Phase verbraucht werden muss. Nach der Feinabstimmung eines Modells müssen wir es beispielsweise möglicherweise nur zum Experimentieren als API hosten. Wir können das Modell zwar auf S3 schreiben und es dann wieder von S3 herunterladen, aber allein für den Upload-/Download-Prozess des Modells wird es viel Zeit in Anspruch nehmen. Stattdessen kann die Feinabstimmung für schnellere Experimente das Modell einfach auf ein Volume schreiben, und der Inferenzdienst kann dann das Volume mit dem Modell mounten.
Checkpoints: Während des Trainings von Modellen für maschinelles Lernen ist es üblich, Checkpoints in regelmäßigen Abständen zu speichern, um das Training im Falle eines Fehlers fortzusetzen oder um Modelle zu verfeinern. Volumes können zum Speichern dieser Checkpoint-Dateien verwendet werden, um sicherzustellen, dass der Trainingsfortschritt nicht verloren geht, wenn ein Job aufgrund eines Fehlers neu gestartet wird. Auf diese Weise können Sie auch Schulungen vor Ort durchführen und so eine Menge Kosten sparen.
Jetzt sprechen wir über ML-Anwendungsfälle. In den meisten Fällen erhalten die ML-Techniker die Daten in S3 Bucket GCS Buckets oder Azure Blob Storage. Wenn sie nun Modelle anhand dieser Daten trainieren möchten, müssen sie die Daten in ihren Trainings-Workload (bereitgestellter Job oder Notizbuch) herunterladen oder den Inhalt ihres Buckets direkt auf der Arbeitslast bereitstellen.
Wann sollte Volume- oder Blob-Speicher wie S3/GCS/Azure Container verwendet werden?
Aus Leistungs-, Zuverlässigkeits- und Kostensicht ist es wichtig, zu entscheiden, wann Blob-Speicher wie S3 oder Volume gewählt werden sollten.
Aufführung
In den meisten Fällen ist das Lesen von Daten aus S3 langsamer als das direkte Lesen von Daten von einem Volume. Wenn also die Ladegeschwindigkeit für Sie entscheidend ist, ist die Lautstärke die richtige Wahl. Ein hervorragendes Beispiel hierfür ist das Herunterladen und Laden des Modells zum Zeitpunkt der Inferenz in mehreren Replikaten des Dienstes. Ein Volume ist die bessere Wahl, da Sie das Modell nicht wiederholt herunterladen müssen und das Modell viel schneller vom Volume in den Speicher laden können.
Zuverlässigkeit
Blob-Speicher wie S3/GCS/ACS sind im Allgemeinen zuverlässiger als Volumes. Daher sollten Sie idealerweise immer eine Sicherungskopie der Rohdaten in einem der Blob-Speicher erstellen und Volumes nur für Zwischendaten verwenden. Sie sollten auch dauerhaft eine Kopie der Modelle in S3 speichern.
Kosten
Der Zugriff auf Volumes wie EFS ist etwas günstiger als die Verwendung von S3. Wenn Sie also häufig dieselben Daten lesen, kann es hilfreich sein, sie auf einem Volume zu speichern. Wenn Sie nur sehr selten lesen oder schreiben, sollte S3 in Ordnung sein.
Zugriffsbeschränkungen
Auf Daten in Volumes sollte idealerweise nur von Workloads innerhalb derselben Region und desselben Clusters zugegriffen werden. S3 ist für den globalen Zugriff und in Cloud-Umgebungen vorgesehen. Daher sind Volumes keine gute Wahl, wenn Sie auf die Daten in einer anderen Region oder einem anderen Cloud-Anbieter zugreifen möchten.
Modi für die Volumenbereitstellung
Um alle Arten von Volumes zu unterstützen, bietet TrueFoundry zwei Volume-Bereitstellungsmodi für unterschiedliche Anwendungsfälle:
Dynamisch
Dies sind Volumes, die dynamisch erstellt und bereitgestellt werden, wenn Sie ein Volume auf Truefoundry bereitstellen. Beispielsweise können EBS, EFS in AWS und AzureFiles in Azure dynamisch auf Truefoundry bereitgestellt werden.
Statisch
Dies sind Volumes, für die bereits ein Speichervolume vorhanden ist und wir die Daten auf diesem Speichervolume für unseren Service/Auftrag bereitstellen möchten. Beispiele hierfür sind das Mounten von S3-Buckets und GCS-Buckets auf den Workloads, die auf der Plattform bereitgestellt werden.
Lassen Sie uns also verstehen, wie diese beiden funktionieren und welche Optionen in jeder Cloud verfügbar sind:
Dynamisch bereitgestellte Volumes
Für dynamisch bereitgestellte Volumes müssen Sie eine Speicherklasse angeben. Ein Volume wird entsprechend der vom Benutzer angegebenen Speicherklasse und Größe dynamisch bereitgestellt.
Lassen Sie uns also verstehen, was eine Speicherklasse ist und welche verschiedenen Speicherklassen in jeder Cloud verfügbar sind:
Speicherklassen
Speicherklassen bieten eine Möglichkeit, den Speichertyp anzugeben, der für ein Volume bereitgestellt werden soll. Diese Speicherklassen unterscheiden sich in ihren Merkmalen wie Leistung, Haltbarkeit und Kosten. Sie können die entsprechende Speicherklasse für Ihr Volume aus dem Dropdownmenü Speicherklasse auswählen, während Sie es erstellen.
Die spezifischen verfügbaren Speicherklassen hängen vom Cloud-Anbieter ab, den Sie verwenden, und davon, was vom Infra-Team vorkonfiguriert ist. In den Speicherklassen, die auf dem Cloud-Anbieter basieren, werden in der Regel die folgenden Optionen angezeigt:
AWS-Speicherklassen
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
efs-sc
Elastic File System (EFS)
efs.csi.aws.com
A fully managed, scalable, and highly durable elastic file system that offers high availability, automatic scaling, and cost-effective general file sharing. It's suitable for workloads with varying capacity needs.
GCP-Speicherklassen
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
standard-rwx
Google Basic HDD Filestore
filestore.csi.storage.gke.io
A cost-effective and scalable file storage solution ideal for general-purpose file storage and cost-sensitive workloads. It offers lower cost but also lower performance due to its HDD-based nature.
premium-rwx
Google Premium Filestore
filestore.csi.storage.gke.io
Provides higher performance and throughput compared to Basic HDD, making it suitable for I/O-intensive file operations and demanding workloads. It's SSD-based, offering higher performance at a higher cost.
enterprise-rwx
Google Enterprise Filestore
filestore.csi.storage.gke.io
Delivers the highest performance, throughput, advanced features, multi-zone support, and high availability, making it ideal for mission-critical workloads and applications with strict availability requirements. It comes with the highest cost.
Azure Storage-Klassen
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
azurefile
Azure File Storage (Standard)
file.csi.azure.com
Uses Azure Standard storage to create file shares for general file sharing across VMs or containers, including Windows apps. It offers cost-effective performance.
azurefile-premium
Azure File Storage (Premium)
file.csi.azure.com
Uses Azure Premium storage for higher performance, making it suitable for I/O-intensive file operations.
azurefile-csi
Azure File Storage (StandardCSI)
file.csi.azure.com
Leverages Azure Standard storage with CSI for dynamic provisioning, potentially offering better performance and CSI features.
azurefile-csi-premium
Azure File Storage (PremiumCSI)
file.csi.azure.com
Combines Azure Premium storage with CSI for dynamic provisioning and high-performance file operations.
azureblob-nfs-premium
Azure Blob Storage (NFS Premium)
blob.csi.azure.com
Uses Azure Premium storage with NFS v3 protocol for accessing large amounts of unstructured data and object storage, catering to demanding workloads with NFS access.
azureblob-fuse-premium
Azure Blob Storage (Fuse Premium)
blob.csi.azure.com
Uses Azure Premium storage with BlobFuse for accessing large amounts of unstructured data and object storage, suitable for workloads that require BlobFuse access.
Statisch bereitgestellte Volumes
Statisch bereitgestellte Volumes ermöglichen es Ihnen, Folgendes als Volume bereitzustellen:
GCS-Eimer
S3-Eimer
Bestehendes EFS
Jedes allgemeine Volume auf Kubernetes
Um statisch bereitgestellte Volumes zu verwenden, müssen Sie ein „PersistentVolume“ erstellen, das sich auf Ihren Speicher bezieht (S3/GCS usw.). Dazu müssen Sie die erforderlichen CSI-Treiber auf dem Cluster installieren und/oder entsprechende Dienstkonten für Berechtigungen einrichten. Im nächsten Abschnitt besprechen wir, wie Sie statisch bereitgestellte Volumes erstellen können.
Montieren Sie einen GCS-Bucket als Volume
Um einen GCS-Bucket als Volume auf Truefoundry zu mounten, müssen Sie die folgenden Schritte ausführen. Sie können sich darauf beziehen Dokument für weitere Informationen:
Einen GCS-Bucket erstellen
Erstellen Sie einen GCS-Bucket und stellen Sie Folgendes sicher:
Sollte eine einzige Region sein (mehrere Regionen funktionieren, aber die Geschwindigkeit wird langsamer sein und die Kosten werden höher sein)
Die Region sollte mit der Ihres Kubernetes-Clusters übereinstimmen
Dienstkonto erstellen und entsprechende Berechtigungen gewähren
Sie müssen das folgende Skript ausführen. Dies bewirkt Folgendes:
Aktiviert den GCS Fuse Driver auf dem Cluster
Erstellen Sie eine IAM-Richtlinie für den Zugriff auf Ihren Bucket
Erstellen Sie ein K8s-Dienstkonto und fügen Sie diesem Dienstkonto eine Richtlinie hinzu
Aktiviert die Rollenbindung des Dienstkontos an den gewünschten K8s-Namespace.
Erstellen Sie ein Dienstkonto in Workspace über die Truefoundry-Benutzeroberfläche
Wir müssen jetzt ein Dienstkonto auf TrueFoundry im selben Workspace mit dem Namen Target_Namespace erstellen und das Dienstkonto muss den Namen GCP_SA_NAME haben.
Gehe zu Workspaces -> Wähle deinen Workspace und klicke auf drei Punkte auf der rechten Seite und klicke auf Bearbeiten:
Öffnen Sie die erweiterten Optionen unten links im Formular und füllen Sie das Servicekonto Abschnitt:
Hinweis
Der Name des Dienstkontos und der Workspace sollten genau mit denen im vorherigen Schritt übereinstimmen.
Erstellen Sie ein PersistentVolume-Objekt
Erstellen Sie mit dem folgenden Schritt ein persistentes Volume-Objekt. (indem Sie eine kubectl-Anwendung ausführen)
Um einen S3-Bucket als Volume auf Truefoundry zu mounten, müssen Sie die folgenden Schritte ausführen:
IAM-Richtlinien und relevante Rollen einrichten
Bitte folge dem Dokument von AWS, um den Mountpoint von S3 in einem EKS-Cluster einzurichten.
Dies wird Sie dazu anleiten, die folgenden Dinge zu tun:
Erstellen Sie eine IAM-Richtlinie, um Mount Point Berechtigungen für den Zugriff auf den S3-Bucket zu erteilen
Erstellen Sie eine IAM-Rolle.
Installieren Sie den Mountpoint für den Amazon S3-CSI-Treiber und fügen Sie die oben erstellte Rolle hinzu.
Ein persistentes Volume auf dem Kubernetes-Cluster erstellen
Erstellen Sie eine PV mit der folgenden Spezifikation (indem Sie eine kubectl-Anwendung ausführen):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 100Gi
csi:
driver: s3.csi.aws.com
volumeHandle: s3-csi-driver-volume # must be unique
volumeAttributes:
bucketName:
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: s3-test # put any value here
mountOptions:
- allow-delete
- region
- allow-other
- uid=1000
volumeMode: Filesystem
Mounten Sie ein vorhandenes EFS als Volume
Um einen S3-Bucket als Volume auf TrueFoundry zu mounten, müssen Sie die folgenden Schritte ausführen:
Installieren Sie den EFS-CSI-Treiber auf Ihrem Cluster
Um den EFS-CSI-Treiber auf Ihrem Cluster zu installieren, gehen Sie zu Truefoundry UI -> Cluster-> Installierte Anwendungen-> Verwalten
Aus dem BändeKlicken Sie im Abschnitt auf AWS EFS CSI-Treiber installieren und dann auf Installieren.
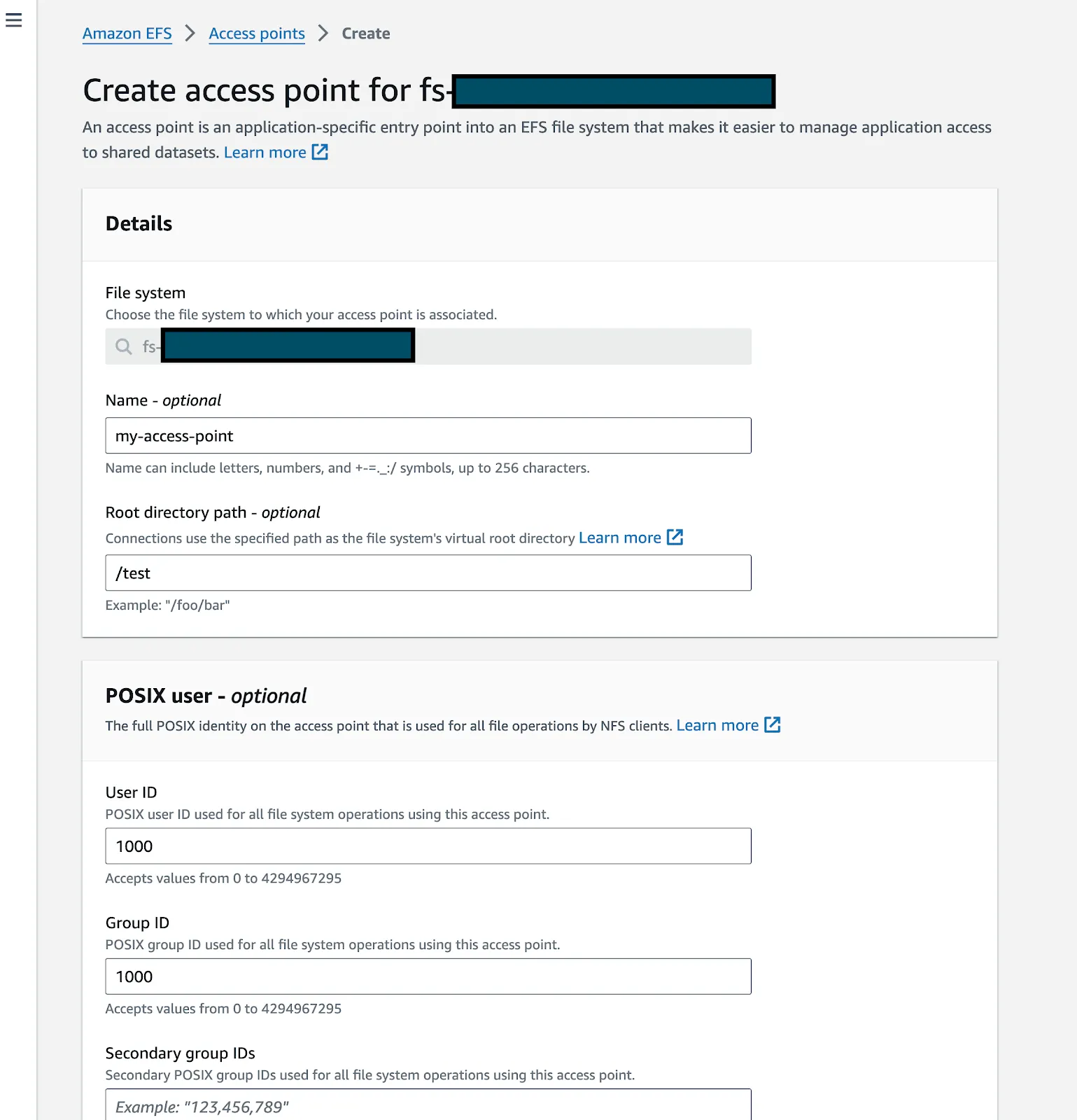
Erstellen Sie einen Access Point für Ihr EFS
Suchen Sie Ihr EFS in der AWS-Konsole und öffnen Sie es. Stellen Sie sicher, dass sich der EFS- und der K8S-Cluster in derselben VPC befinden. Klicken Sie auf „Access Point erstellen“
Geben Sie Details wie den Namen und den Pfad zum Stammverzeichnis ein (bitte stellen Sie sicher, dass Sie den Abschnitt mit den Berechtigungen zum Erstellen des Stammverzeichnisses ausfüllen. Sie können die UID:1000 GID:1000 eingeben, wenn Sie es an das Notizbuch anhängen möchten.)
Klicken Sie auf Erstellen.
Erstellen Sie ein PersistentVolume auf dem Cluster
Erstellen Sie eine PV mit der folgenden Spezifikation (indem Sie eine kubectl-Anwendung ausführen):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 5Gi # this number doesn't matter for EFS, any number will work
csi:
driver: efs.csi.aws.com
volumeHandle: :: # e.g. fs-036e93cbb1fabcdef::fsap-0923ac354cqwerty
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
volumeMode: Filesystem
Erstellen Sie ein Volume auf TrueFoundry
Bitte folge dem Abschnitt um ein Volumen auf TrueFoundry zu erstellen
Volumes auf Truefoundry verwenden
Mit den obigen Anleitungen können Sie problemlos Volumes bereitstellen oder vorhandene Speichercontainer als Volumes verwenden. Jetzt können diese Volumes für jeden Workload auf Kubernetes bereitgestellt werden. Wenn Sie dies verwenden, können Sie Ihr Volume problemlos für jeden Workload auf TrueFoundry bereitstellen. Sie können es einfach auf einem mounten Bedienung oder ähnlich jeder Workload, der auf Truefoundry bereitgestellt wird. Sie können auch einen Dateibrowser aktivieren, um den Inhalt des Volumes mit nur wenigen Klicks zu durchsuchen, indem Sie unseren Volumenbrowser.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last






































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




