

August 27, 2025
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Verschiedene Workloads erfordern unterschiedliche Hardwarespezifikationen wie Maschinentyp, Größe und Geolokalisierung. Mit dem Aufkommen von ML/LLMs ist die Auswahl der richtigen Hardware entscheidend geworden. Wir müssen Entscheidungen auf der Grundlage von Hardwarespezifikationen wie Betriebssystemtyp, Architektur, Prozessor, GPU-Typ und Speicher treffen. Kubernetes hilft bei der Orchestrierung und Verteilung von Ressourcen auf ähnliche Workloads, aber die dynamische Bereitstellung dieser Ressourcen bei Bedarf bleibt eine Herausforderung.
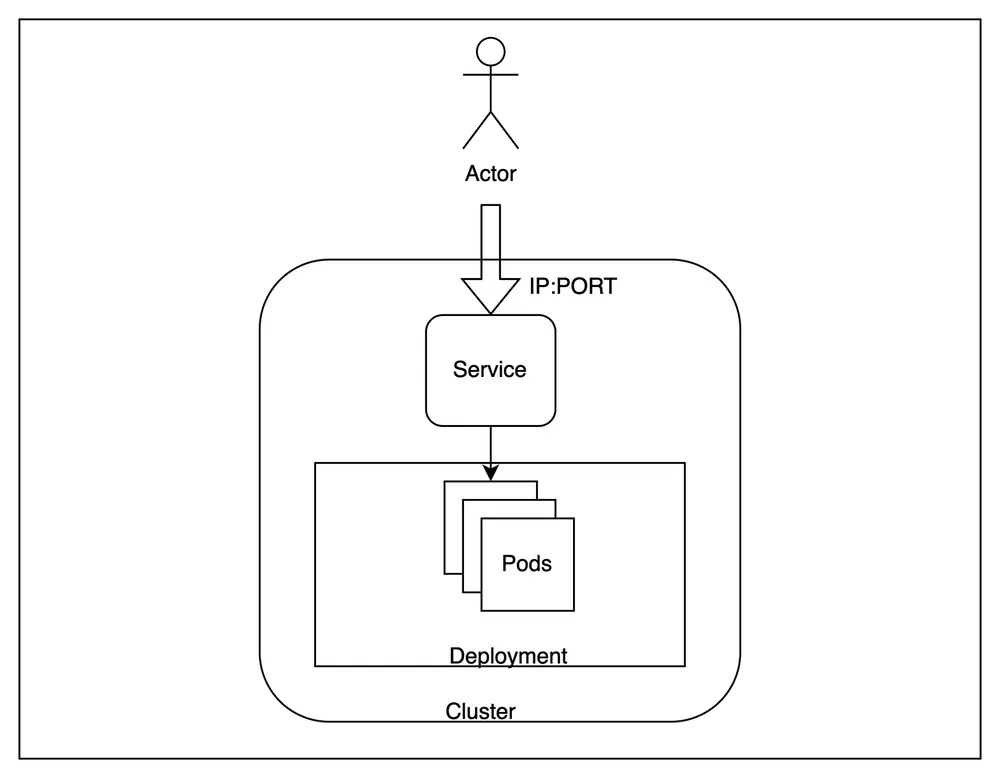
EIN Kubernetes Ein (K8s) -Cluster ist eine Gruppe von Knoten, die containerisierte Apps auf effiziente, automatisierte, verteilte und skalierbare Weise ausführen. Jeder Knoten innerhalb eines Kubernetes-Clusters hat bestimmte Attribute wie Maschinentyp, Größe und Standort.
In diesem Blog wird die Notwendigkeit von Cloud-Node-Autoprovisionern untersucht, um verschiedene Workload-Anforderungen innerhalb von Kubernetes-Clustern automatisch zu verwalten. Wir bieten auch Einblicke in Lösungen, die von großen Cloud-Anbietern wie AWS, GCP und Azure angeboten werden. Schließlich untersuchen wir, wie TrueFoundry diese Herausforderungen als Plattform bewältigt.
Die automatische Knotenbereitstellung automatisiert die Bereitstellung der entsprechenden Knotengruppe auf der Grundlage ungeplanter Pod-Einschränkungen, um die Infrastrukturkosten zu optimieren. Automatische Node-Provisionisten in einem Kubernetes-Cluster sind für die folgenden Aktionen verantwortlich:
Kubernetes hat Knoten als Arbeitscomputer mit spezifischen Hardwarekonfigurationen wie Maschinentyp, Größe und Kapazitätstyp, und Node-Pools beziehen sich auf Pools solcher gängigen Worker-Maschinen. Da es keinen automatischen Node-Provisioner gab, war die einzige Möglichkeit, Ihrem Workload eine bestimmte Hardwarekonfiguration zuzuweisen, die Auswahl eines Knotenpools. Dazu muss der Benutzer einen Knotenpool mit der erforderlichen Konfiguration in seiner Cloud erstellen und dann den Knoten hinzufügen Affinität für den spezifischen Knotenpool in der Pod-Spezifikation.
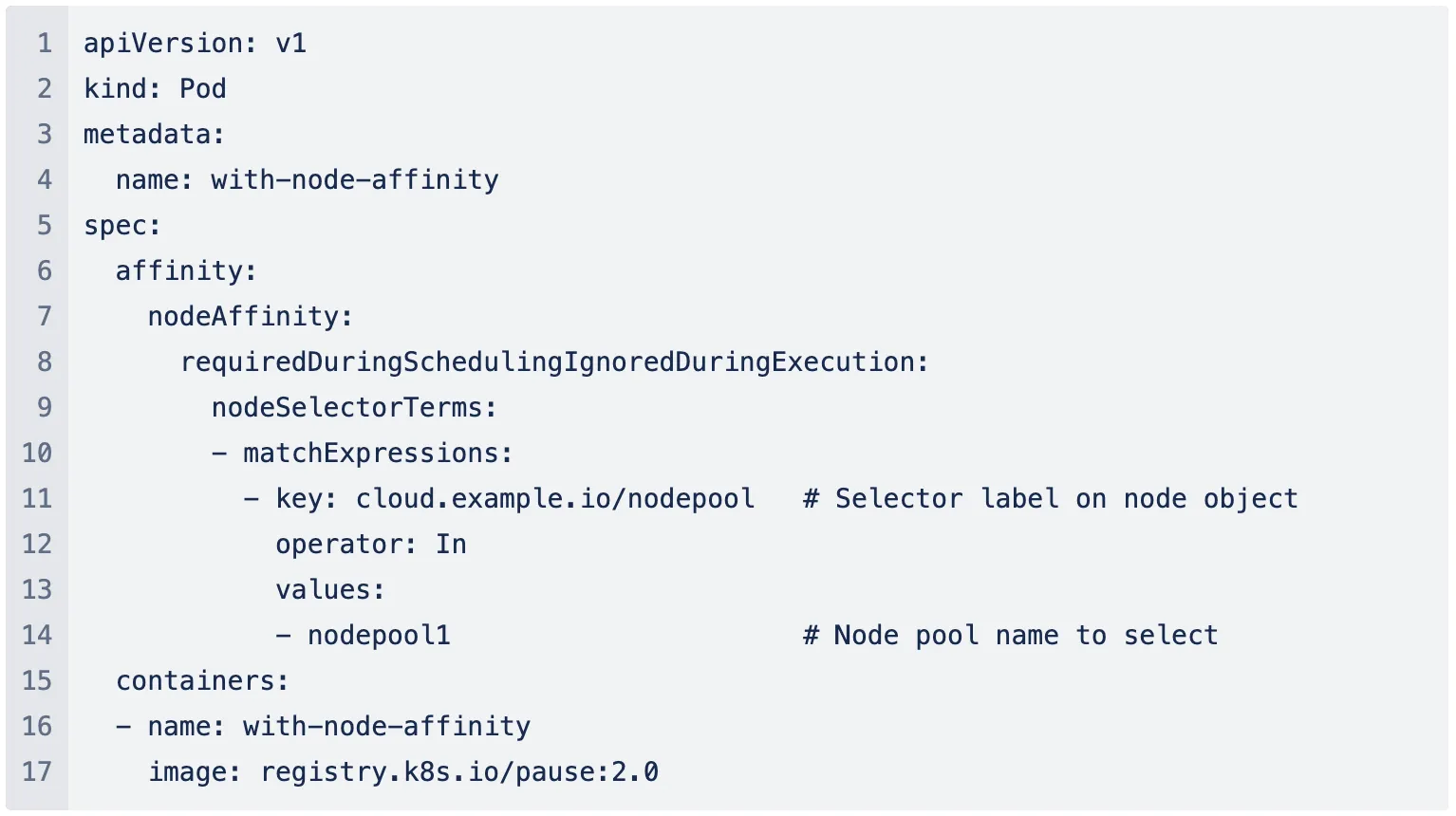
Insgesamt umfasst dieser Mechanismus die folgenden Schritte:
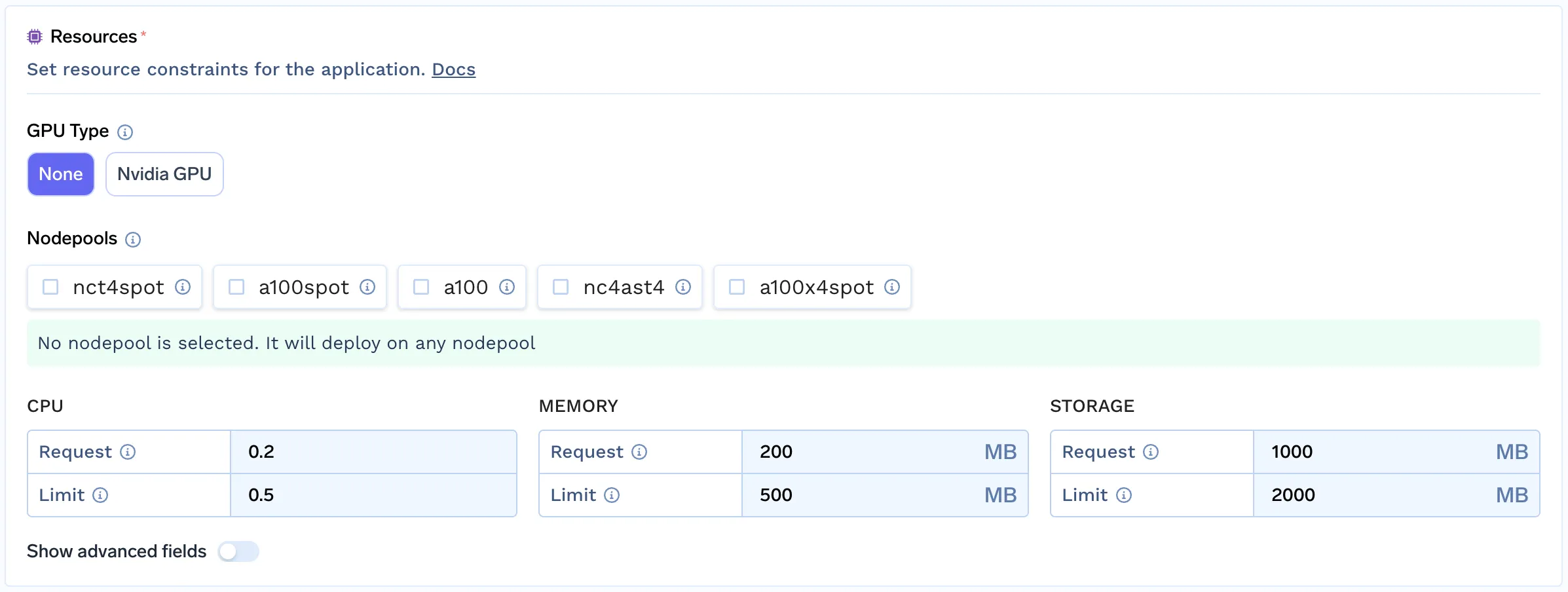
Die Kombinationen der Anforderungen an den Knotenpool können zahlreich sein, insbesondere während der Experimentierphase für ML/LLM-Workloads. Die Koordination zwischen separaten DevOps- und Plattformteams könnte während der Entwicklung viel Zeit in Anspruch nehmen. Daher ist ein Controller, der die Anforderungen dynamisch bewertet und die Infrastruktur automatisch bereitstellt, von entscheidender Bedeutung.
Durch die automatische Bereitstellung von Knoten entfällt der manuelle Schritt der Vorerstellung von Knotenpools, da Benutzer allgemeine Anforderungen als Einschränkungen hinzufügen können. Es bestimmt automatisch den besten Maschinentyp oder den besten verfügbaren Knoten für die jeweilige Arbeitslast.

Einige der häufig verwendeten Einschränkungen:
21000t4, a100auf Abruf oder StelleUS-Ost-1ALinux oder Fensterarm64 oder amd64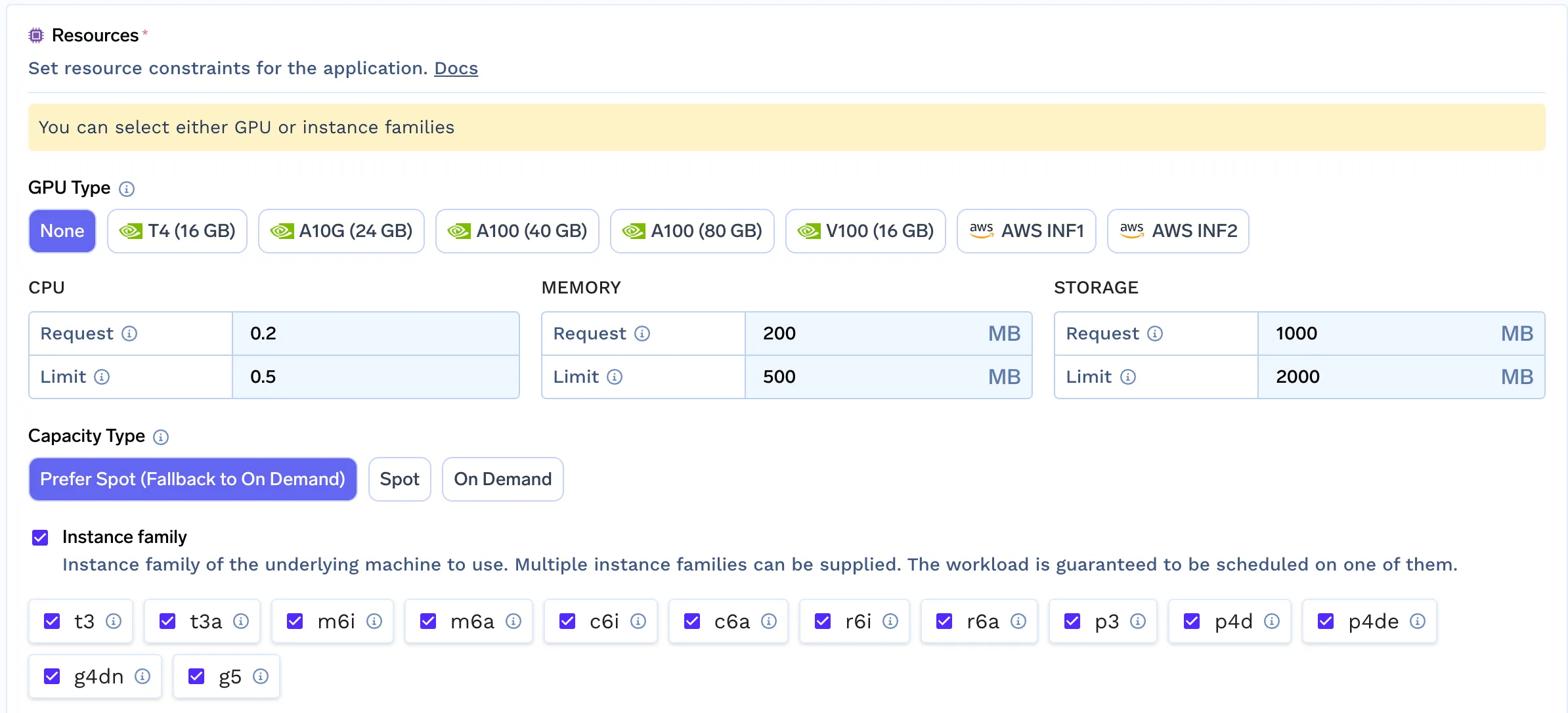
Jeder Cloud-Anbieter bietet seine Auto-Provisioning-Mechanismen an. AWS erfordert die Installation von Tools wie Karpenter, während GCP eine integrierte Lösung bietet. Azure hat kürzlich sein Auto-Provisioner-Projekt vorgestellt, das sich derzeit im Vorschaumodus befindet.
Karpenter, ein Open-Source-Node-Lifecycle-Management-Projekt, das für Kubernetes entwickelt wurde, verbessert die Effizienz und Wirtschaftlichkeit der Ausführung von Workloads auf Clustern erheblich. Karpenter berücksichtigt Planungseinschränkungen wie Ressourcenanforderungen, Knotenselektoren, Affinitäten, Toleranzen und Topologiestreuungsbeschränkungen und verteilt Knoten intelligent nach Bedarf und gibt sie frei.
Automatische Bereitstellung von Knoten, das in den Cluster-Autoscaler integriert ist, skaliert bestehende Node-Pools auf der Grundlage der Spezifikationen von nicht planbaren Pods. Die automatische Bereitstellungsfunktion von GCP gewährleistet eine optimale Nutzung der Ressourcen, indem CPU, Arbeitsspeicher, kurzlebiger Speicher, GPU-Anforderungen, Knotenaffinitäten und Label-Selektoren berücksichtigt werden.
Azurs Projekt zur automatischen Bereitstellung von Knoten (NAP), derzeit im Vorschaumodus, nutzt das Open-Source-Projekt Karpenter, um die optimale VM-Konfiguration für die effiziente und kostengünstige Ausführung von Workloads zu ermitteln. NAP implementiert und verwaltet Karpenter automatisch auf AKS-Clustern und bietet Benutzern so ein nahtloses Erlebnis.
💡
Node Auto Provisioning (NAP) für AKS befindet sich derzeit in der VORSCHAU. Wir freuen uns sehr über dieses neue Projekt und freuen uns darauf, es für unsere Kunden zu nutzen. Erfahre mehr
TrueFoundry bietet erweiterte Filterfunktionen für Knotenpools und simuliert die automatische Bereitstellung von Knoten.
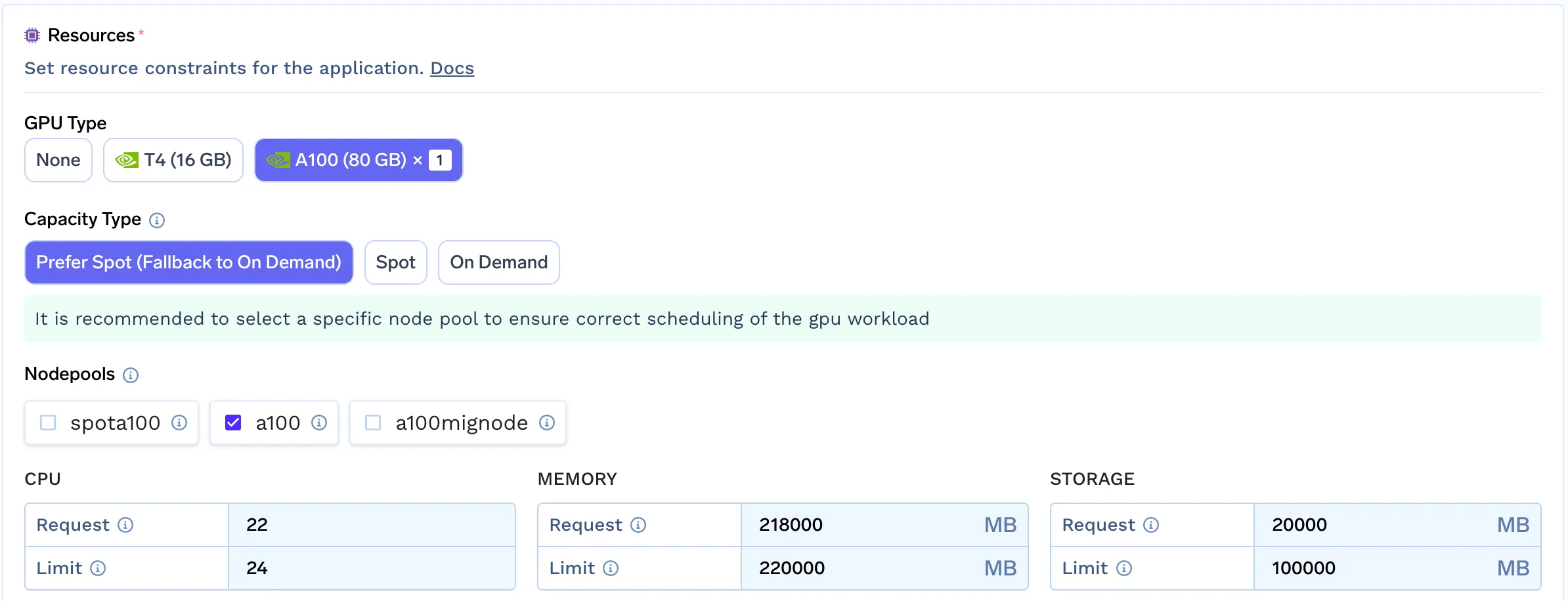
Um dies zu erreichen, haben wir ein paar einfache Schritte befolgt:
Dieser Ansatz ermöglicht es Entwicklern/Datenwissenschaftlern, den besten Knotenpool für ihre Arbeitslast auszuwählen, indem sie ihre Anforderungen analysieren. Dieser einfache Mechanismus ermöglicht es uns, für jede Cloud, die noch keine integrierte Unterstützung für Auto-Provisioner hat, dasselbe Erlebnis zu bieten.
Da sich die Infrastrukturanforderungen ständig weiterentwickeln, sind Cloud-Anbieter bestrebt, den Prozess der Auswahl der optimalen Infrastruktur für unterschiedliche Workloads zu optimieren. Bei Wahre Gießerei, wir teilen dieses Engagement, indem wir uns bemühen, Entwicklern die Tools und das Wissen an die Hand zu geben, die sie für die reibungslose Bereitstellung ihrer Workloads benötigen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)


.webp)
.webp)


.webp)
.webp)
.webp)
.png)




