

August 27, 2025
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In der letzten Ausgabe haben wir den Arbeitsablauf eines Datenwissenschaftlers besprochen und erklärt, wo genau sich Kubernetes als nützliche Basis erweisen kann, um eine Plattform dafür aufzubauen.
Lassen Sie uns in dieser Ausgabe ein einfaches Beispiel durchgehen, um praktische Erfahrungen zu sammeln.
Bevor wir beginnen, benötigen wir einen Spielplatz, auf dem wir die Demo durchführen können. Dazu werden wir einen Kubernetes-Cluster auf dem lokalen Computer einrichten. Obwohl ein Cluster aus Gründen der Fehlertoleranz und Hochverfügbarkeit mehrere Knoten enthalten sollte, werden wir dieses Verhalten mit einem großartigen Tool nachahmen nett (Kubernetes im Docker).
Am Ende dieses Abschnitts werden mehrere Container ausgeführt, wobei jeder Container als separater Clusterknoten fungiert.
Folgen Sie den angegebenen Anweisungen hier
Testen Sie die Installation, indem Sie
$ kind --version
Art Version 0.14.0
Jetzt starten wir einen lokalen Cluster mit nett. Wir werden eine Kontrollebene und zwei Worker-Knoten erstellen. Es ist möglich, mehrere von beiden zu haben.
<aside>💡 Kubernetes kann mehrere Steuerungsebenen und Worker-Knoten haben. Alle zentralen Clusterverwaltungskomponenten befinden sich auf den Knoten der Steuerungsebene, während die Arbeitslast der Benutzer auf den Worker-Knoten ausgeführt wird. Lesen Sie mehr hier
</aside>
Erstellen Sie zunächst eine nett Konfiguration in einer Datei namens kind-config.yaml. Du kannst es finden hier. Dies wird die Struktur unseres Clusters definieren -
Art: Cluster
API-Version: kind.x-k8s.io/v1alpha4
Knoten:
- Rolle: Steuerebene
- Rolle: Arbeiter
- Rolle: Arbeiter
Hier haben wir drei Knoten definiert, von denen einer die Rolle der Kontrollebene hat und die anderen beiden als Worker-Knoten.
Starten Sie einen Cluster mit dieser Konfiguration. Das kann einige Zeit dauern. Stellen Sie sicher, dass der Docker-Daemon auf Ihrem System aktiv ist, bevor Sie dies ausführen -
$ kind create cluster --config kind-config.yaml
...
Danke, dass du nett benutzt! 😊
kubectl um sicherzustellen, dass unser Cluster aktiv ist -$ kubectl cluster-info
Die Kubernetes-Steuerungsebene läuft unter < https://127.0.0.1:63122 >
CoreDNS läuft unter < https://127.0.0.1:63122/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy >
...
Dies sagt uns, dass der Cluster tatsächlich aktiv ist. Wir können auch sehen, wie die einzelnen Container als Knoten agieren, indem wir Folgendes ausführen Docker PS.
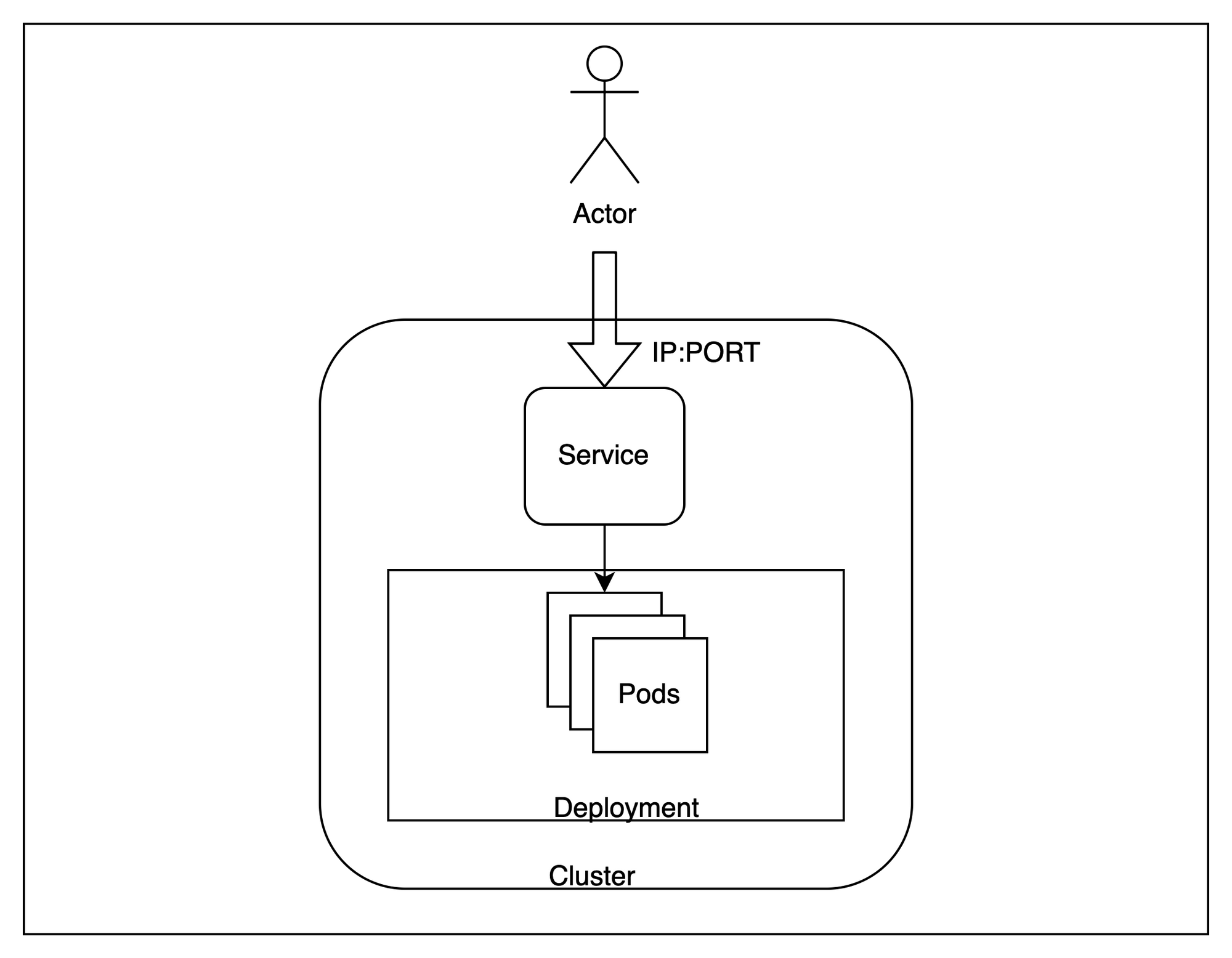
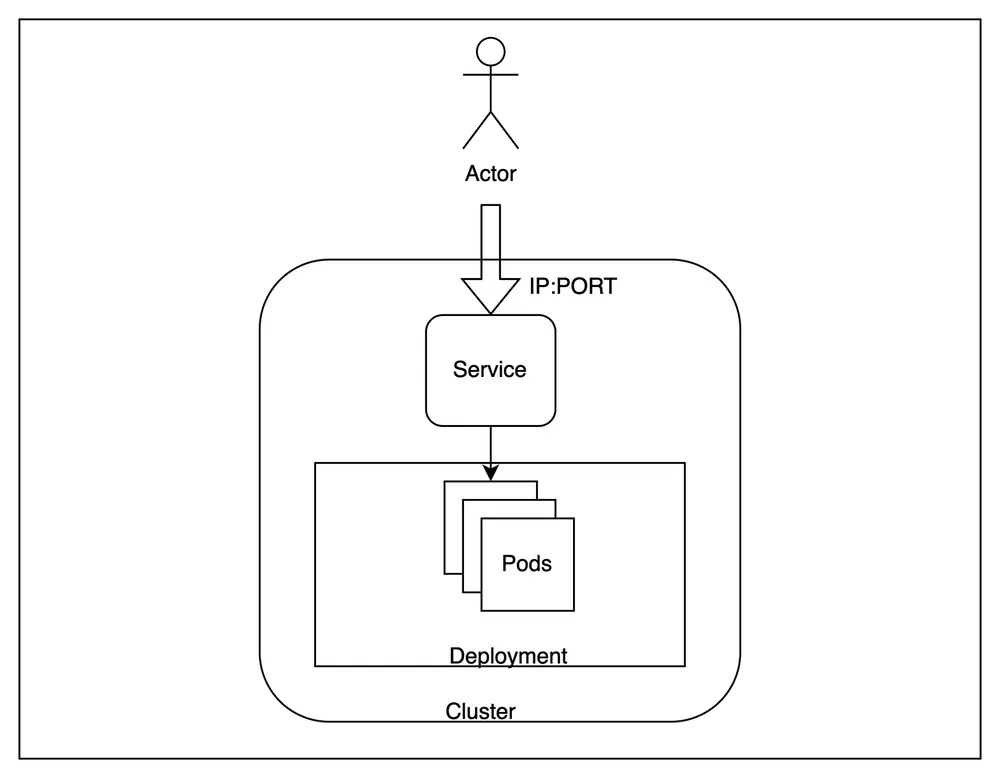
Nachdem unser Cluster eingerichtet ist, schauen wir uns eine breite Architektur dessen an, was wir bereitstellen werden.
Im Großen und Ganzen werden wir mehrere Replikate unserer Anwendung innerhalb des Clusters hosten und versuchen, von außen darauf zuzugreifen, wobei die Anforderungen auf die verschiedenen Instanzen verteilt werden.
Um dies zu erreichen, gibt es einige kubernetes-spezifische Terminologie, die wir beachten müssen -
Schote - Pods sind die kleinsten einsetzbaren Recheneinheiten, die Sie in Kubernetes erstellen und verwalten können. In unserem Fall wird eine Instanz der Anwendung in einem unabhängigen Pod ausgeführt. Dies sind kurzlebige Ressourcen, und die Steuerungsebene kann sie bei Bedarf über Knoten hinweg verschieben.Einsatz - Eine Bereitstellung ist nützlich, wenn wir mehr als ein Replikat für eine Anwendung haben möchten. Kubernetes versucht, die Anzahl der Replikate immer so zu halten, dass sie der Anzahl entspricht, die in einer Bereitstellung bereitgestellt wird. Wir werden drei identische Replikate für unsere Anwendung erstellen.Bedienung - Ein Dienst ist nützlich, um den Lastenausgleich zwischen einer Reihe von Pods durchzuführen, die auf dem Cluster ausgeführt werden. Da Pods im Wesentlichen kurzlebig sind und jederzeit ausgetauscht werden können, bietet der Service eine stabile Schnittstelle für den Zugriff auf die Pods, die hinter ihm laufen. Wir werden einen Dienst verwenden, um unsere Anwendung zu testen.Diese drei Ressourcen ermöglichen es uns, einen skalierbaren Endpunkt für die Bereitstellung unserer Anwendung zu hosten.
Wenn der Cluster aktiv ist, können wir jetzt eine Anwendung bereitstellen und testen. Wir werden eine Anwendung erstellen, die den beliebten Datensatz des Iris-Klassifikators verwendet.
Das Repo ist verfügbar unter https://github.com/shubham-rai-tf/iris-classifier-kubernetes. Es enthält bereits den Code für die Erstellung und Bereitstellung von Vorhersagen unter /iris/classify_iris Endpunkt unter Verwendung schnelle API.
Wir müssen diesen Code in ein Docker-Image packen, um ihn vorzubereiten Kubernetes. EIN Docker-Datei ist dafür im Repo vorgesehen - hier.
Das Docker-Datei gibt das Bild an, das wir benötigen, um einen Container zu erstellen, der die Prognoseendpunkte hostet, in einem Uvicorn Server auf Port 5000. Weitere Details zur Syntax sind verfügbar hier.
Führen Sie diesen Befehl aus, um ein lokales Image zu erstellen -
$ Docker-Build. -t Iris-Klassifikator: poc
...
$ Docker-Bild ls
GRÖSSE DER ERSTELLTEN BILD-ID DES REPOSITORY-TAGS
iris-classifier poc 549913d5b1f9 vor 12 Sekunden 737MB
Wir können sehen, dass das Bild erfolgreich mit dem Namen erstellt wurde Iris-Klassifikator und tag poc. Wir werden dieses Bild jetzt in den Cluster laden, um es innerhalb des Clusters zu verwenden
<aside>💡 Dieser Schritt ist nur erforderlich, weil wir keine Image-Registrierung haben, aus der wir das neu erstellte Image abrufen können. In der Produktion sollte das Image in einer privaten Registry wie Dockerhub oder AWS ECR gehostet und dann direkt in den Cluster gezogen werden
</aside>
Führen Sie diesen Befehl aus, um das lokal erstellte Image in den Cluster zu laden -
$ nett load docker-image iris-classifier: poc
Bild: „iris-classifier:poc“ mit der ID „sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" noch nicht auf dem Knoten „kind-worker2" vorhanden, wird geladen...
Bild: „iris-classifier:poc“ mit der ID „sha 256:549913 d5b1f9456a4beedc73e04c3c0ad70da8691a8745a6b56a4f483c4f0862" noch nicht auf dem Knoten „kind-control-plane“ vorhanden, wird geladen...
...
Sie können überprüfen, ob die Bilder geladen wurden, indem Sie Bilder in einem der drei Container auflisten -
$ docker exec -it gud-worker crictl images
BILD-TAG, BILD-ID-GRÖSSE
docker.io/library/iris-classifier poc 549913d5b1f94 753 MB
Kubernetes ist im Wesentlichen ein deklaratives System. Das heißt, wir beschreiben die Konturen dessen, was wir tun wollen, und Komponenten der Steuerungsebene treiben das System ständig dazu, diesen Zustand zu erreichen.
Um die zuvor besprochene Architektur zu implementieren, beschreiben wir unsere Absicht in Form einer Yaml Datei, die als Aufzeichnung der Absicht dient. Im Sprachgebrauch von Kubernetes heißen diese offenbart.
Alle Kubernetes-Manifeste haben die folgenden Felder -
API-Version - Mehrere Ressourcen sind in denselben API-Versionen zusammengefasst. Dies bietet eine standardisierte Methode, eine Ressource in allen Kubernetes-Versionen als veraltet zu kennzeichnen oder zu bewerben.nett - Identifiziert den genauen Objekttyp, der erstellt werden sollMetadaten - Enthält Felder, die als Metadaten für das erstellte Objekt dienen. - Der API-Version, nett und Metadatenname Felder zusammen identifizieren eine einzigartige Ressource in einem NamensraumSpezifikation - Dieses Feld enthält die Spezifikation für das zu erstellende Objekt. Jede Art definiert ihre eigene Struktur für dieses Feld mit ihrer eigenen Implementierung.Wir werden die im Repo vorhandenen Manifeste in Dateien innerhalb von verwenden offenbart Verzeichnis hier.
Es definiert zwei Kubernetes-Ressourcen, Einsatz und Bedienung in bereitstellung.yaml und service.yaml jeweils. Lassen Sie uns beide Abschnitte durchgehen.
API-Version: Apps/v1
Art: Einsatz
spezifikation:
# Anzahl der Replikate
Repliken: 3
schablone:
spezifikation:
Behälter:
# Name des Bildes
- Bild: iris-classifier:poc
Name: Iris-Klassifikator
Das Einsatzmanifest in bereitstellung.yaml definiert hauptsächlich die Pod-Spezifikation, die wir bereitstellen möchten, in Bezug auf den Image-Namen und die Anzahl der Replikate. Sobald wir dies angewendet haben, wird Kubernetes ständig Maßnahmen ergreifen, um die Anzahl der Replikate auf dem Niveau zu halten, das wir hier angeben.
API-Version: v1
Art: Service
spezifikation:
# Art des Dienstes
Typ: ClusterIP
Anschlüsse:
# Port, auf den der Dienst zugegriffen werden kann
- Anschluss: 8080
# Port auf dem Container, an den der Verkehr weitergeleitet werden soll
Zielport: 5000
Protokoll: TCP
Selektor:
App: Iris-Klassifikator
Das Servicemanifest in service.yaml definiert, wie der Lastenausgleich zwischen den durch die Bereitstellung erstellten Replikaten erfolgt. Hier haben wir definiert, wie der Port on Service dem Port auf den Containern zugeordnet werden soll. Da unsere Anwendung auf Port 5000 läuft, ist Zielport ist auf 5000 gesetzt. Der Dienst ist auf Port 8080 verfügbar. Der an 8080 gesendete TCP-Verkehr wird über Port 5000 auf den Containern mit einem Lastenausgleich durchgeführt.
Führen Sie den folgenden Befehl aus, um die Manifeste auf Kubernetes anzuwenden -
$ kubectl apply -f manifeste/
deployment.apps/iris-classifier wurde erstellt
Service/Iris-Klassifikator erstellt
Beide Ressourcen wurden erfolgreich auf dem Cluster erstellt. Wir können überprüfen, ob die folgenden Befehle ausgeführt werden -
$ kubectl get service iris-Klassifikator
NAME, TYP, CLUSTER-IP, EXTERNE IP-PORT (E), SEITE
<none>Iris-Klassifikator ClusterIP 10.96.107.238 8080/TCP 37m
$ kubectl get Deployment Iris-Classifier
NAME BEREIT AKTUELL VERFÜGBARES ALTER
Iris-Klassifikator 3/3 3 3 38m
$ kubectl get pods
NAME: BEREIT, STATUS, NEUSTARTS, ALTER
iris-classifier-5d97498ff9-77wqw 1/1 Laufen 0 39m
iris-classifier-5d97498ff9-8twjm 1/1 Laufen 0 39m
iris-classifier-5d97498ff9-znrz8 1/1 Laufen 0 39m
Wie wir sehen können, ist der Dienst an Port 8080 verfügbar und drei Pods wurden wie von uns angegeben erstellt.
Modifizieren bereitstellung.yaml um 2 Replikate statt 3 zu haben und sich erneut zu bewerben. Kubernetes löscht eines der Replikate, damit es der Spezifikation entspricht.
Nachdem die Ressourcen im Cluster erstellt wurden, können wir unsere Bereitstellung überprüfen, indem wir das Modell mithilfe des Service-Endpunkts aufrufen. Da wir ein lokales Setup verwenden, müssen wir Port-Forward den Dienst an einen Port auf dem lokalen Computer.
<aside>💡 In einem Cloud-Provider-Setup wird dieser Dienst an einen externen Load Balancer gebunden, auf den bei Bedarf über das Internet zugegriffen werden kann.
</aside>
Führen Sie den folgenden Befehl aus, um die Portweiterleitung für den Dienst durchzuführen -
$ kubectl portforward services/Iris-Classifier 8080
Weiterleitung von 127.0.0. 1:8080 -> 5000
Weiterleitung von [::1] :8080 -> 5000
Wir können dies überprüfen, indem wir die anrufen /gesundheitscheck Endpunkt auf dem Modell -
< http://localhost:8080/healthcheck >$ curl ''
„Der Iris-Klassifikator ist fertig!“
Um eine Testprognose durchzuführen, senden wir eine Beispieleingabe, um eine Vorhersage zu erhalten -
$ curl ''< http://localhost:8080/iris/classify_iris > -X POST\\
-H 'Inhaltstyp: Anwendung/JSON'\\
-d '{"Kelchblattlänge“: 2, „Kelchblattbreite“: 4, „Blütenblattlänge“: 2, „Blütenblattbreite“: 4}'
{"class“ :"setosa“, "Wahrscheinlichkeit“ :0.99}
Wir bekommen eine Klassenprognose Setosa mit einer Wahrscheinlichkeit von 99% Indem wir mehrere dieser Vorhersagen ausführen, können wir überprüfen, ob die Anfragen tatsächlich im Round-Robin-Verfahren an verschiedene Pods weitergeleitet werden.
Lassen Sie uns alle Kubernetes-Ressourcen entfernen, die wir zuerst installiert hatten -
$ kubectl delete -f manifeste/
Dadurch werden alle Kubernetes-Ressourcen bereinigt, die wir in den vorherigen Abschnitten erstellt haben. Jetzt können wir auch den Cluster herunterfahren -
$ irgendwie Cluster löschen
Cluster „kind“ wird gelöscht...
In dieser Ausgabe haben wir erklärt, wie ein Modell als aufrufbaren Dienst in Kubernetes gehostet wird. Obwohl dies ein Spielzeugbeispiel war, bei dem wir ein Docker-Image lokal erstellt und auf einem Cluster ausgeführt haben, der auf demselben Computer läuft, funktioniert ein typisches Produktionssetup nach ähnlichen Prinzipien. Mit nur diesen beiden Ressourcen kann viel erreicht werden.
In den folgenden Ausgaben werden wir uns mit weiteren fortschrittlicheren Funktionen wie Mehrmandantenfähigkeit und Zutrittskontrolle befassen, die im Hinblick auf den Betrieb am zweiten Tag unverzichtbar werden.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)
.webp)

.webp)
.webp)


.webp)
.webp)
.webp)
.png)




