



August 27, 2025
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Willkommen zu dieser Serie über den Aufbau und die Einrichtung einer skalierbaren Infrastruktur für maschinelles Lernen in einer Kubernetes-Umgebung. In dieser Reihe werden wir verschiedene Themen im Zusammenhang mit der Entwicklung, Bereitstellung und Verwaltung von Modellen für maschinelles Lernen auf einem Kubernetes-Cluster behandeln.
Machine Learning Operations, allgemein bekannt als MLOps, bezieht sich auf die Praktiken und Techniken, die zur Verwaltung des Lebenszyklus von Modellen für maschinelles Lernen verwendet werden. Die skalierbare Betriebsinfrastruktur für maschinelles Lernen ermöglicht es Unternehmen, Modelle in großem Maßstab zu erstellen, bereitzustellen und zu verwalten, wodurch die Investitionsrendite (ROI) ihrer datenwissenschaftlichen Bemühungen erhöht wird.
Zu den Vorteilen einer skalierbaren MLOps-Infrastruktur gehören:
Airbnb investierte von Anfang an viel in die Einrichtung einer skalierbaren MLOps-Praxis. Das Unternehmen verwendete Modelle für maschinelles Lernen, um seine Algorithmen für das Suchranking mithilfe der nutzerdatengesteuerten Suche zu verbessern. Dies führte zu einem besseren Sucherlebnis und einem geschätzten Anstieg der Buchungen um 10%. Airbnb nutzte auch Modelle für maschinelles Lernen, um seinen Nutzern personalisierte Empfehlungen zu geben, was dazu beitrug, das Nutzererlebnis und die Nutzerbindung zu verbessern!
Unternehmen, die sich bei der Einrichtung ihrer ML-Trainings- und Bereitstellungsinfrastruktur auf virtuelle Maschinen (VMs) verlassen, sei es auf AWS, Google Cloud Platform (GCP) oder Microsoft Azure, stehen möglicherweise vor mehreren Herausforderungen:
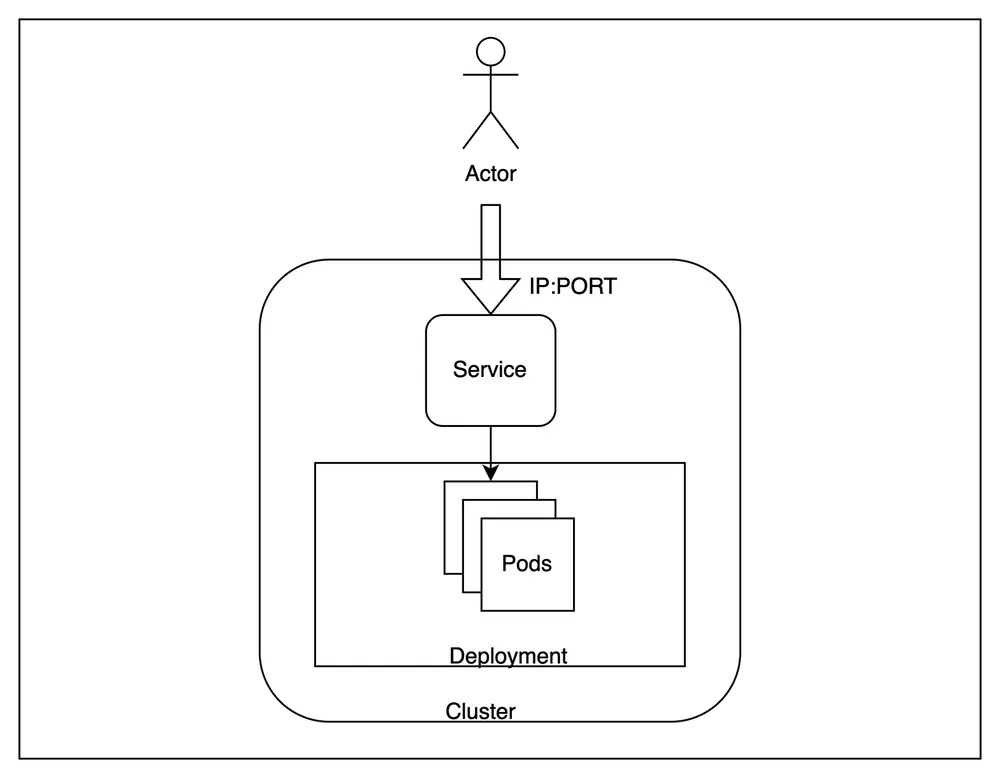
Kubernetes ist eine beliebte Open-Source-Container-Orchestrierungsplattform, die die Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen automatisiert. Sie bietet eine einheitliche API und eine deklarative Konfiguration, die das Management von containerisierten Workloads vereinfacht und es Unternehmen ermöglicht, eine skalierbare, belastbare und portable Infrastruktur für das Training und den Einsatz von ML-Modellen aufzubauen. Kubernetes bietet mehrere Vorteile gegenüber reinen VMs, darunter eine bessere Ressourcennutzung, eine vereinfachte Versionskontrolle und eine effiziente Skalierung. Darüber hinaus bietet Kubernetes integrierte Sicherheitsfunktionen sowie zentralisierte Überwachungs- und Protokollierungsfunktionen, mit denen Unternehmen die Sicherheit und Zuverlässigkeit ihrer ML-Infrastruktur gewährleisten können. Kubernetes ist eine hervorragende Wahl für Unternehmen, die skalierbare Pipelines für maschinelles Lernen auf längere Sicht aufbauen möchten.
Cloud-Anbieter (AWS, GCP und Azure) bieten verwaltete Kubernetes-Dienste (EKS, GKE bzw. AKS) an, die es Unternehmen ermöglichen, Kubernetes-Cluster einfach einzurichten, zu konfigurieren und zu verwalten, wodurch der mit der Ausführung und Skalierung von Kubernetes verbundene Betriebsaufwand entfällt. Darüber hinaus bieten Cloud-Anbieter Integrationen mit anderen Cloud-Diensten wie Speicher, Datenbanken und Netzwerken an, was die Bereitstellung und Verwaltung von ML-Workloads auf Kubernetes weiter vereinfachen kann. Durch die direkte Einführung von Kubernetes oder über einen Managed Service können Unternehmen eine flexible und skalierbare MLOps-Pipeline aufbauen, die ihren wachsenden ML-Workloads gewachsen ist und eine schnellere Markteinführung ihrer ML-Modelle ermöglicht.
Lassen Sie uns näher auf die Vorteile der Verwendung von Kubernetes für ML-Trainings- und Bereitstellungspipelines eingehen
Beispiel Anwendungsfall 1: AirBnB
Airbnb, der Online-Marktplatz, auf dem Menschen ihre Häuser oder Wohnungen an Reisende vermieten können. Angesichts von Millionen von Nutzern und einer riesigen Menge an zu analysierenden Daten benötigte Airbnb eine robuste und skalierbare Infrastruktur für maschinelles Lernen, um das Nutzerverhalten zu analysieren, das Suchranking zu verbessern und Nutzern personalisierte Empfehlungen zu geben.
Um dies zu erreichen, investierte Airbnb in den Aufbau einer MLOps-Infrastruktur auf Kubernetes, die es dem Data-Science-Team ermöglichte, Modelle für maschinelles Lernen in großem Maßstab zu entwickeln und einzusetzen. Mit Kubernetes war Airbnb in der Lage, seine Modelle zu containerisieren und als Microservices bereitzustellen, was es einfacher machte, seine Infrastruktur zu verwalten und zu skalieren, je nach Bedarf. Dadurch konnte Airbnb seine Suchrankings verbessern und seinen Nutzern relevantere Empfehlungen geben, was zu höheren Buchungen und höheren Einnahmen führte. Darüber hinaus war das Unternehmen in der Lage, die Effizienz seiner datenwissenschaftlichen Workflows zu verbessern, sodass sich das Team auf die Entwicklung fortschrittlicherer Modelle für maschinelles Lernen konzentrieren konnte.
Beispiel für einen Anwendungsfall 2: Lyft
Lyft, ein großer Anbieter von Transportation as a SaaS (TaaS), baute seine ML-Infrastruktur zunächst auf AWS auf und verwendete dabei eine Kombination aus EC2-Instances und Docker-Containern. Sie verwendeten EC2-Instances, um virtuelle Maschinen mit unterschiedlichen CPU-, Speicher- und GPU-Ressourcen bereitzustellen, abhängig von den spezifischen ML-Workload-Anforderungen. Sie verwendeten auch Docker-Container, um ihre ML-Workloads zu verpacken und bereitzustellen und die Konsistenz in verschiedenen Umgebungen sicherzustellen.
Als die ML-Workloads von Lyft jedoch an Komplexität und Umfang zunahmen, standen sie vor mehreren Herausforderungen, darunter der Konsistenz in verschiedenen Umgebungen und Teams. Sie beschlossen, ihre ML-Infrastruktur auf eine Kubernetes-basierte Infrastruktur zu migrieren, wobei zunächst KubeFlow und dann eine interne Plattform verwendet wurde. Durch die Migration zu einer Kubernetes-basierten Infrastruktur war Lyft in der Lage, eine effizientere und skalierbarere ML-Infrastruktur aufzubauen, was ihnen half, ihre ML-Entwicklungs- und Bereitstellungspipelines zu beschleunigen. Darüber hinaus konnten sie die Vorteile von Kubernetes wie automatische Skalierung und effiziente Ressourcennutzung nutzen, um ihre ML-Workloads zu optimieren und die Infrastrukturkosten zu senken. Sie nutzten EKS von AWS als ihren verwalteten Kubernetes-Service!
Insgesamt, die Investition in die MLOps-Infrastruktur auf Kubernetes ermöglichte Airbnb und Lyft, erhebliche Produktivitätssteigerungen zu erzielen und ihr Geschäftsergebnis zu verbessern. Dies zeigt den Wert, den skalierbare MLOps auf Kubernetes für Unternehmen bieten können, die maschinelles Lernen in großem Maßstab nutzen möchten.
Trotz der Vorteile bringt die Verwendung von Kubernetes für ML Infrastructure ihre eigenen Herausforderungen und Komplexitäten mit sich:
Zwar gibt es Herausforderungen, aber Unternehmen können diese Herausforderungen bewältigen und eine skalierbare, sichere und zuverlässige MLOps-Infrastruktur aufbauen, indem sie Best Practices befolgen und die Funktionen von Kubernetes nutzen.
Kubernetes für maschinelles Lernen bietet zahlreiche Vorteile für Unternehmen, die ihre Workflows für maschinelles Lernen optimieren möchten. Zwar gibt es Herausforderungen bei der Einrichtung und Verwaltung der MLOps-Infrastruktur auf Kubernetes, wie z. B. Ressourcenmanagement, Sicherheit und Überwachung, aber ein gründliches Verständnis von Kubernetes und Best Practices kann helfen, diese Hindernisse zu überwinden.
In dieser Reihe von ML on Kubernetes werden wir versuchen, verschiedene Themen im Zusammenhang mit dem Aufbau und der Einrichtung einer ML-Infrastruktur in einer Kubernetes-Umgebung zu behandeln, darunter die folgenden:
und mehr..
Durch die Übernahme dieser Best Practices und die Nutzung der Leistungsfähigkeit von Kubernetes können Unternehmen Machine-Learning-Modelle konsistent, zuverlässig und sicher skalieren und bereitstellen. Dies wiederum würde zu einer schnelleren Markteinführung, einer verbesserten Zusammenarbeit zwischen Data-Science- und IT-Betriebsteams und einem besseren ROI ihrer Investitionen in die Datenwissenschaft führen.
Erfahren Sie, wie Gong eine skalierbare Forschungsinfrastruktur für maschinelles Lernen auf Kubernetes aufgebaut hat
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)

.webp)
.webp)


.webp)
.webp)
.webp)
.png)




