

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 29, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Große Sprachmodelle wie ChatGPT und Diffusionsmodelle wie Stable Diffusion haben die Welt in knapp einem Jahr im Sturm erobert. Immer mehr Unternehmen beginnen nun, Generative KI für ihre bestehenden und aufregenden neuen Anwendungsfälle zu nutzen. Während die meisten Unternehmen direkt damit beginnen können, APIs zu verwenden, die von Unternehmen wie OpenAI, Anthropic, Cohere usw. bereitgestellt werden, sind diese APIs auch mit hohen Kosten verbunden. Langfristig möchten viele Unternehmen kleine bis mittelgroße Versionen gleichwertiger Open-Source-LLMs wie Llama, Flan-T5, Flan-UL2, GTP-Neo, OPT, Bloom usw. verfeinern Alpaka und GPT4 Alle Projekte haben es getan.
Die Feinabstimmung kleinerer Modelle mit den Ausgängen größerer Modelle kann auf mehrere Arten nützlich sein:
Um all dies zu ermöglichen, sind GPUs zu einem unverzichtbaren Arbeitstier in jedem Unternehmen geworden, das mit diesen grundlegenden Modellen arbeitet. Da die Modellgrößen wachsen und Billionen von Parametern erreichen, wird das verteilte Training über mehrere GPUs langsam zur neuen Norm. Nvidia ist mit seinen neueren Karten der Serien Ampere und Hopper führend im Hardwarebereich. Die Hochgeschwindigkeits-NVLink- und Infiniband-Verbindung ermöglichen den Anschluss von bis zu 256 Nvidia A100 oder Nvidia H100 (und ~4.000 in Super-Pod-Clustern), um mit immer größeren Modellen in Rekordzeit zu trainieren und Schlussfolgerungen zu ziehen.
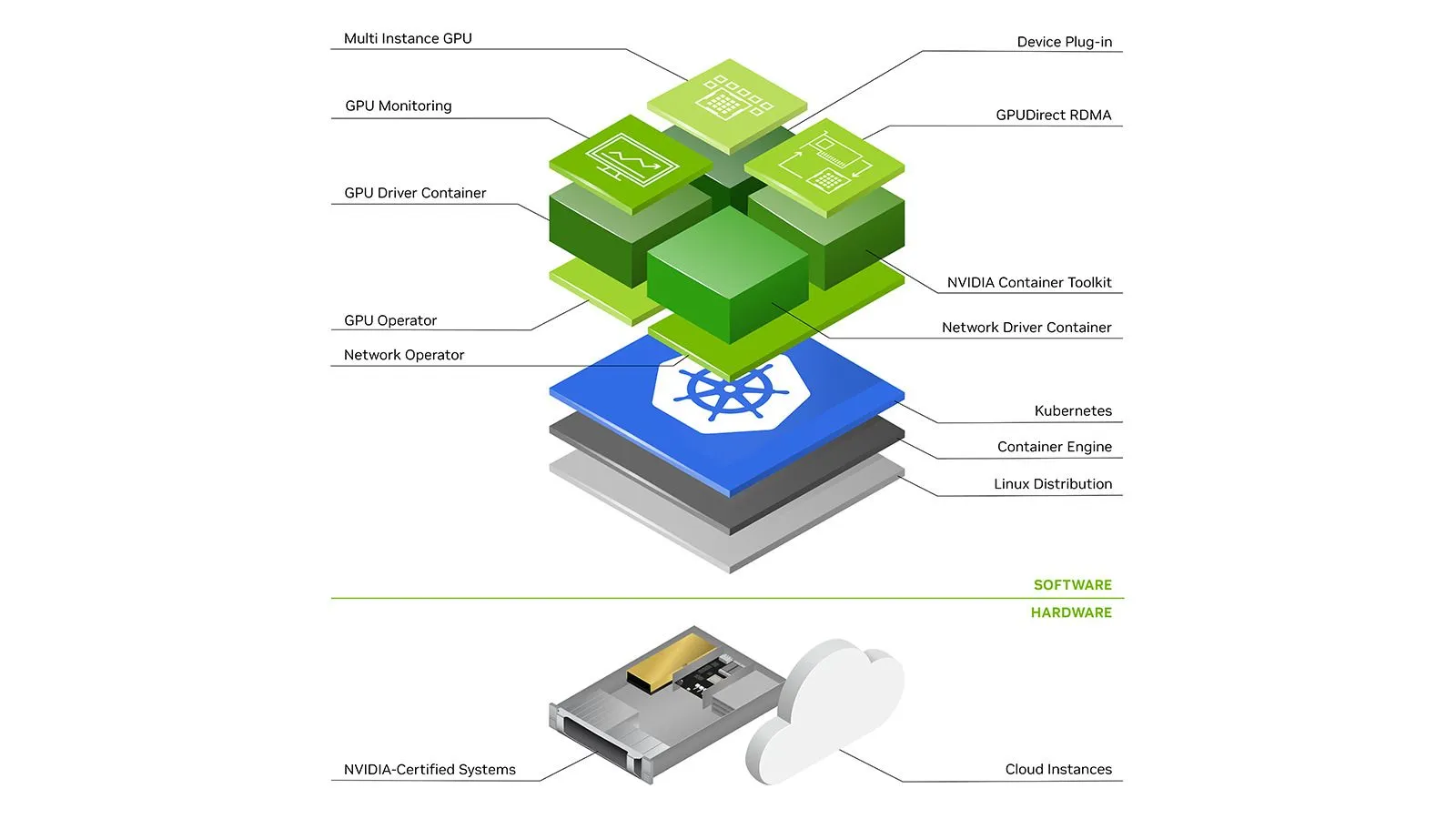
Wir werden nun die Komponenten durchgehen, die für die Verwendung von GPUs mit Kubernetes erforderlich sind — hauptsächlich auf AWS EKS und GCP GKE (Standard oder Autopilot), aber die genannten Komponenten sind auf jedem K8s-Cluster unerlässlich.
Ihr Cloud-Anbieter hat GPU-VMs. Wie bringen wir sie in den K8s-Cluster? Eine Möglichkeit besteht darin, GPU-Nodepools mit fester Größe oder mit manuell zu konfigurieren Cluster-Autoscaler das kann bei Bedarf GPU-Knoten hinzufügen und loslassen, wenn nicht. Dies erfordert jedoch immer noch die manuelle Konfiguration mehrerer verschiedener Knotenpools. Eine noch bessere Lösung ist die Konfiguration von Auto Provisioning-Systemen wie AWS Karpenter oder Automatische GCP-Knotenbereitsteller. Wir sprechen in unserem vorherigen Artikel darüber: Cluster-Autoscaling für Big 3 Clouds ☁️
API-Version: karpenter.sh/v1alpha5
Art: Provisioner
Metadaten:
Name: GPU-Provisioner
Namensraum: Karpenter
spezifikation:
Gewicht: 10
Kubelet-Konfiguration:
Max. Anzahl der Kapseln: 110
Grenzwerte:
Ressourcen:
Zentralprozessor: „500"
Anforderungen:
- Schlüssel: karpenter.sh/capacity-type
Betreiber: In
Werte:
- Stelle
- auf Abruf
- Schlüssel: topology.kubernetes.io/zone
Betreiber: In
Werte:
- AP-Süd-1
- Schlüssel: karpenter.k8s.aws/instance-family
Betreiber: In
Werte:
- p3
- p4
- p 5
- g4dn
- 5 g
Makel:
- Schlüssel: „nvidia.com/gpu“
Effekt: „NoSchedule“
Anbieterreferenz:
Name: Standard
TTL-Sekunden nach Leerung: 30
Beispiel für eine GCP Node Auto Provisioner-Konfiguration
Ressourcenbegrenzungen:
- ResourceType: 'CPU'
mindestens: 0
maximal: 1000
- ResourceType: 'Speicher'
mindestens: 0
maximal: 10000
- Ressourcentyp: 'nvidia-tesla-v100'
mindestens: 0
maximal: 4
- Ressourcentyp: 'nvidia-tesla-t4'
mindestens: 0
maximal: 4
- Ressourcentyp: 'nvidia-tesla-a100'
mindestens: 0
maximal: 4
Standorte für AutoProvisioning:
- us-central1-c
Verwaltung:
AutoRepair: wahr
AutoUpgrade: wahr
Konfiguration der abgeschirmten Instanz:
enableSecureBoot: wahr
enableIntegrityMonitoring: wahr
Festplattengröße GB: 100
Beachten Sie, dass wir hier auch unsere Provisioner so konfigurieren können, dass sie verwendet werden Stelle Geben Sie Instances ein, um Kosteneinsparungen zwischen 30 und 90% für statusfreie Anwendungen zu erzielen.
Damit eine virtuelle Maschine GPUs verwenden kann, müssen ihre Treiber auf dem Host installiert sein. Zum Glück sind GKE-Knoten sowohl auf AWS EKS als auch auf GCP mit bestimmten Versionen von Nvidia-Treibern vorkonfiguriert.
Weil jeder Eine neuere CUDA-Version erfordert eine höhere Mindesttreiberversion, vielleicht möchten Sie sogar die Treiberversion für alle Knoten kontrollieren. Dies kann geschehen, indem Sie Knoten mit benutzerdefinierten Images ausstatten, die den Treiber nicht haben, und Nvidia GPU-Operator installiere eine angegebene Version. Dies ist jedoch möglicherweise nicht bei allen Cloud-Anbietern zulässig. Achten Sie daher auf die Treiberversionen auf Ihren Knoten, um Kompatibilitätsprobleme zu vermeiden.
Wir sprechen über die GPU-Operator später unten.
Da in Kubernetes alles in Pods (einer Reihe von Containern) läuft, reicht es nicht aus, nur Treiber auf dem Host zu installieren. Nvidia bietet eine eigenständige Komponente namens Nvidia-Container-Toolkit das installiert Hooks für enthalten Führen Sie C aus um die GPU-Treiber und Geräte des Hosts für die Container verfügbar zu machen, die auf dem Knoten laufen. Eine detailliertere Erklärung finden Sie in diesem Artikel.
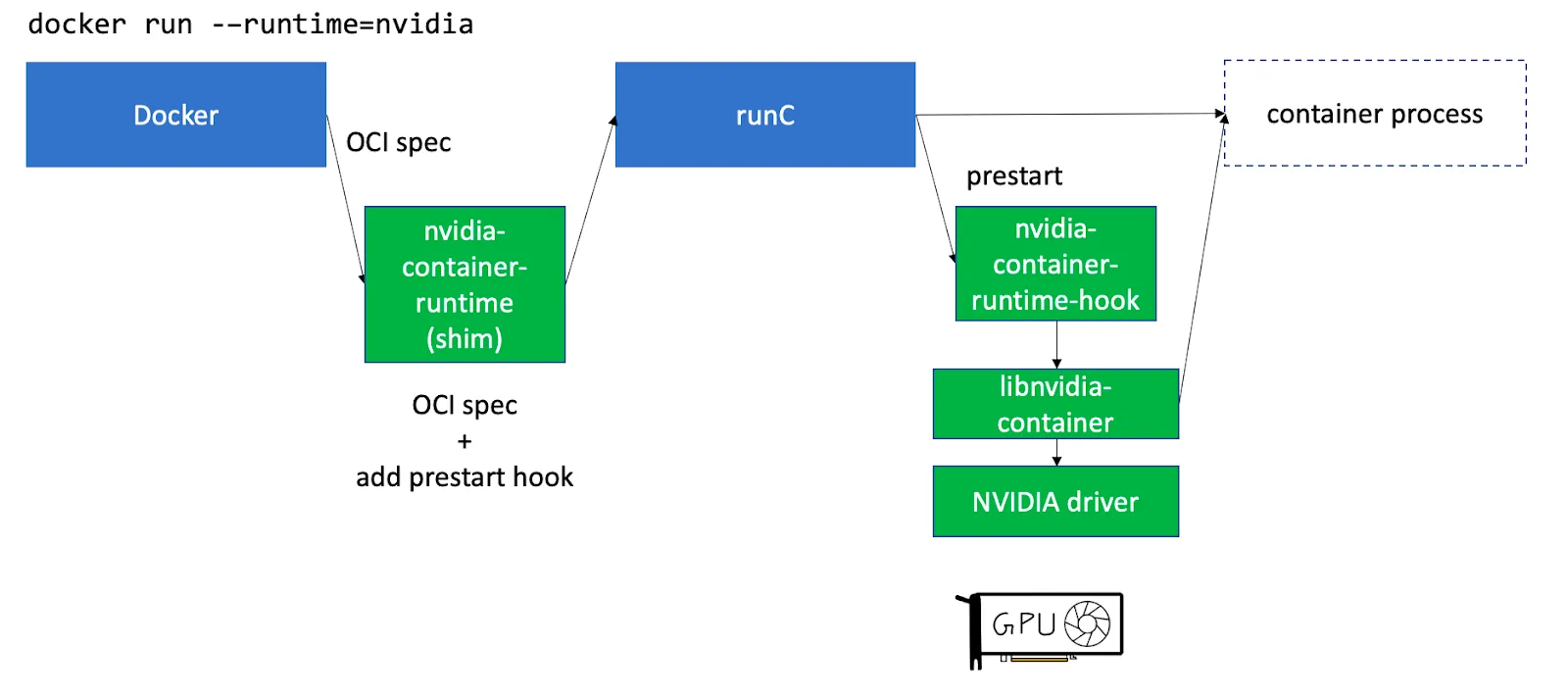
Nvidia-Container-Toolkit kann installiert werden, um als Daemonset auf den GPU-Knoten ausgeführt zu werden.
Es reicht nicht aus, GPUs auf dem Knoten zu haben. Der Kubernetes-Scheduler muss wissen, auf welchem Knoten wie viele GPUs verfügbar sind. Dies kann mit einem erfolgen Geräte-Plugin. Ein Geräte-Plugin ermöglicht die Werbung für benutzerdefinierte Hardwareressourcen auf der Steuerungsebene, z. B. nvidia.com/gpu . Nvidia hat eine veröffentlicht Geräte-Plugin das bewirbt zuweisbare GPUs auf einem Knoten. Dieses Plugin kann wieder als Daemonset ausgeführt werden.
Sobald die oben genannten Komponenten konfiguriert sind, müssen wir der Pod-Spezifikation einige Dinge hinzufügen, um sie auf dem GPU-Knoten zu planen - hauptsächlich Ressourcen , Affinität und Toleranzen
ZB auf GCP GKE können wir Folgendes tun:
spezifikation:
# Wir definieren, wie viele GPUs wir für den Pod haben wollen
Ressourcen:
Grenzwerte:
nvidia.com/gpu: 2
# Affinitäten helfen uns, den Pod auf den GPU-Knoten zu platzieren
Affinität:
Knotenaffinität:
Erforderlich während der Planung und während der Ausführung ignoriert:
NodeSelector-Bedingungen:
- Ausdrücke abgleichen:
# Geben Sie an, welche Instanzfamilie wir wollen
- Betreiber: In
Schlüssel: cloud.google.com/machine-family
Werte:
- a2
# Geben Sie an, welchen GPU-Typ wir wollen
- Betreiber: In
Schlüssel: cloud.google.com/gke-accelerator
Werte:
- nvidia-Tesla-a100
# Geben Sie an, dass wir eine Spot-VM wollen
- Betreiber: In
Schlüssel: cloud.google.com/gke-spot
Werte:
- „wahr“
Toleranzen:
# Spot-VMs haben einen Makel, daher erwähnen wir eine Toleranz dafür
- Schlüssel: cloud.google.com/gke-spot
Operator: Gleich
Wert: „wahr“
Effekt: NoSchedule
# Wir verfälschen die GPU-Knoten, daher erwähnen wir eine Toleranz dafür
- Schlüssel: nvidia.com/gpu
Operator: Existiert
Effekt: NoSchedule
Ressourcen. Grenzen AbschnittBeachten Sie, dass sich diese Konfigurationen je nach den von Ihnen verwendeten Bereitstellungsmethoden und Cloud-Anbietern unterscheiden (z. B. Karpenter auf AWS oder NAP auf GKE).
Die Überwachung von GPU-Metriken wie Auslastung, Speichernutzung, Stromverbrauch, Temperatur usw. ist wichtig, um sicherzustellen, dass alles reibungslos funktioniert, und um weitere Optimierungen vorzunehmen.
Zum Glück hat Nvidia eine Komponente namens dcgm-Exporteur das als Daemonset auf GPU-Knoten ausgeführt und Metriken an einem Endpunkt veröffentlicht werden kann. Diese Metriken können dann mit Prometheus gelöscht und konsumiert werden. Hier ist ein Beispiel für eine Scrape-Konfiguration:
- Jobname: gpu-metrics
Scrape_Intervall: 15 s
scrape_timeout: 10 Sekunden
metrics_path: /metrics
Schema: http
kubernetes_sd_configs:
- Rolle: Endpunkte
Namespaces:
Namen:
- <dcgm-exporter-namespace-here>
relabel_configs:
- Quellenbezeichnungen: [__meta_kubernetes_pod_node_name]
Aktion: ersetzen
target_label: kubernetes_node
Beachten Sie jedoch, dass dcgm-Exporteur muss laufen mit Host-IPC: wahr und privilegiert Sicherheitskontext. Das ist in Ordnung für EKS und GKE Standard. GKE Autopilot erlaubt einen solchen Zugriff jedoch nicht, stattdessen GKE veröffentlicht Metriken auf dem vorkonfigurierten Nvidia-Geräte-Plugin Daemonsets, die in GCP Cloud Monitoring gescrappt oder angesehen werden können.
AWS EKS/GCP GKE Standard/GCP GKE Autopilot/Provisioning Carpenter//ManualGCP Node Auto Provisioner//Manuell/Auto Provisioning Drivers vorinstalliert/Installation über GPU-OperatorVorinstalliertes vorinstalliertes Container-ToolkitNvidia-Container-Toolkitüber GPU-OperatorVorkonfiguriertes Vorkonfiguriertes Geräte-PluginNvidia-Geräte-Pluginüber GPU-OperatorVorkonfiguriertes DaemonSetVorkonfiguriertes DaemonSetMetricsnvidia-dcgm-exporterüber GPU-OperatorEigenständig nvidia-dcgm-exporter /Benutzerdefiniertes Scraping Benutzerdefiniertes Scraping
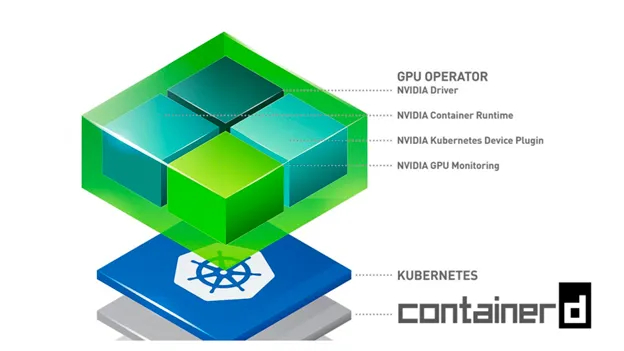
Das GPU-Operator Bei den meisten Teilen von AWS EKS wurde oben eine Reihe eigenständiger Nvidia-Komponenten wie Treiber, Container-Toolkit, Geräte-Plugin und Metrik-Exporter erwähnt, die alle kombiniert und so konfiguriert sind, dass sie zusammen über ein einziges Steuerdiagramm verwendet werden können. Das GPU-Operator führt einen Master-Pod auf der Steuerungsebene aus, der GPU-Knoten im Cluster erkennen kann. Bei der Erkennung eines GPU-Knotens wird ein Worker-Daemonset bereitgestellt, das die Pods weiter plant, um optional Treiber, Container-Toolkit, Geräte-Plugin, CUDA-Toolkit, Metrik-Exporter und Validatoren zu installieren. Sie können mehr darüber lesen hier.
Im Allgemeinen ist es möglich, das CUDA-Toolkit auf dem Host-Computer zu installieren und es dem Pod per Volume Mounting zur Verfügung zu stellen. Wir stellen jedoch fest, dass dies ziemlich spröde sein kann, da man daran herumspielen muss PFAD und LD_LIBRARY_PATH Variablen. Darüber hinaus müssen alle Pods auf demselben Knoten dieselbe CUDA-Toolkit-Version verwenden, was sehr restriktiv sein kann. Daher ist es besser, das CUDA-Toolkit (oder nur Teile davon) in das Container-Image einzufügen.
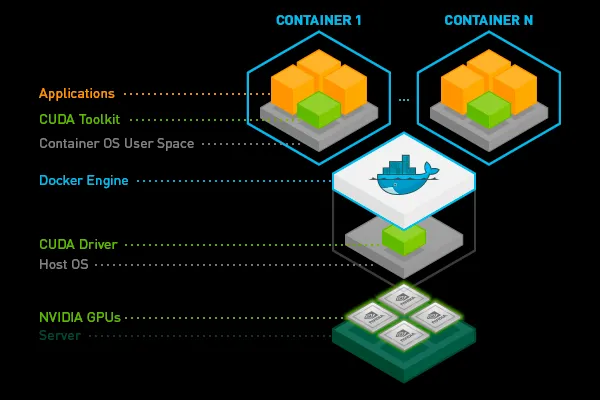
Sie können mit bereits erstellten Bildern beginnen, die von bereitgestellt werden Nvidia oder dein Lieblings-Deep-Learning Rahmen oder füge es mit einer Zeile auf der Truefoundry-Plattform hinzu
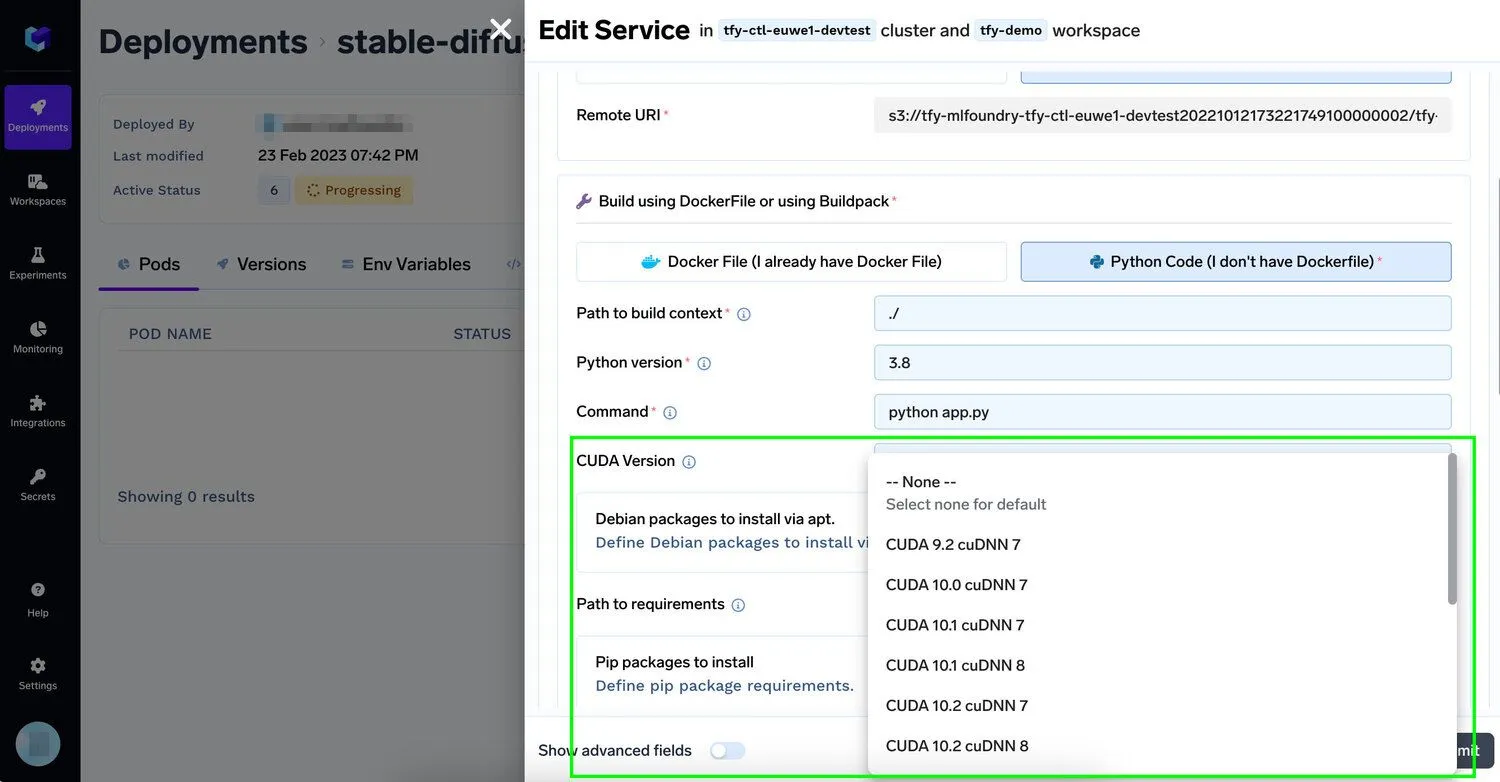
Damit Unternehmen ihre generativen KI-Modelle schneller auf ihrer bestehenden Infrastruktur abstimmen und bereitstellen können, ermöglicht die TrueFoundry-Plattform Entwicklern, ihren Anwendungen mit minimalem Aufwand eine oder mehrere Nvidia-GPUs hinzuzufügen und gleichzeitig Workflows zu unterstützen, die neben dem beste schnelle Engineering-Tools. Entwickler müssen nur angeben, wie viele Instanzen einiger der besten GPUs für maschinelles Lernen wie V100, P100, A100 40 GB, A100 80 GB (optimal für Schulungen) oder T4, A10 (optimal für Inferenz) sie benötigen, und wir erledigen den Rest. Lesen Sie mehr auf unserer Dokumente. Da GPU-gestützte KI-Workloads in die Produktion übergehen, wird diese Art der Infrastruktursteuerung auch für ein breiteres Publikum wichtig KI-Sicherheitsplattformen, wo Rechenisolierung, Zugriffssteuerung und Workload-Beobachtbarkeit zusammenarbeiten müssen.
GPUs sind eine fantastische Technologie und das ist erst der Anfang für uns. Wir arbeiten aktiv an den folgenden Problemen:
Wenn das alles aufregend klingt, Bitte kontaktieren Sie uns, um mit uns zu arbeiten um die beste MLOps-Plattform zu bauen.
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
Diskutieren Sie hier mit uns über Ihre ML-Pipeline-Herausforderungen
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




