

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Amazon Bedrock ist ein praktikabler Ausgangspunkt für Teams, die strikt an das AWS-Ökosystem gebunden sind. Es bietet eine verwaltete API-Ebene für Foundation Models (FMs) ohne sofortiges Infrastrukturmanagement. Da KI-Workloads im Jahr 2026 jedoch in die Produktion übergehen, sehen sich Entwicklungsteams unweigerlich mit der „Plattformwand“ konfrontiert. Diese Barriere äußert sich in drei primären Reibungspunkten:
Für Architekten, die langfristig planen, verlagert sich das Ziel vom einfachen API-Zugriff hin zur Entwicklung einer „Migrations- und Multi-Cloud-Strategie“. In diesem Leitfaden werden die technischen Kompromisse, die Wirtschaftlichkeit der Einheiten und die betrieblichen Realitäten der wichtigsten Alternativen zu Bedrock bewertet. Managed Services bieten zwar Komfort, aber Plattformen wie TrueFoundry entwickeln sich zur bevorzugten Steuerungsebene für Unternehmen, die die Benutzerfreundlichkeit von Bedrock in Kombination mit der wirtschaftlichen und betrieblichen Kontrolle der Bereitstellung auf ihrer eigenen Cloud-Infrastruktur benötigen.
In diesem Abschnitt analysieren wir die technischen Vorzüge und die architektonische Eignung der folgenden Wettbewerber:
TrueFoundry arbeitet eher als plattformunabhängige Steuerungsebene als als proprietäres Ökosystem. Im Gegensatz zu Bedrock, das ein verwaltete API, bei der Inferenz auf gemeinsam genutzter Infrastruktur erfolgt, TrueFoundry orchestriert die Rechen- und Inferenzschichten direkt in Ihren eigenen VPC- oder Kubernetes-Clustern (EKS, GKE, AKS oder Bare Metal).
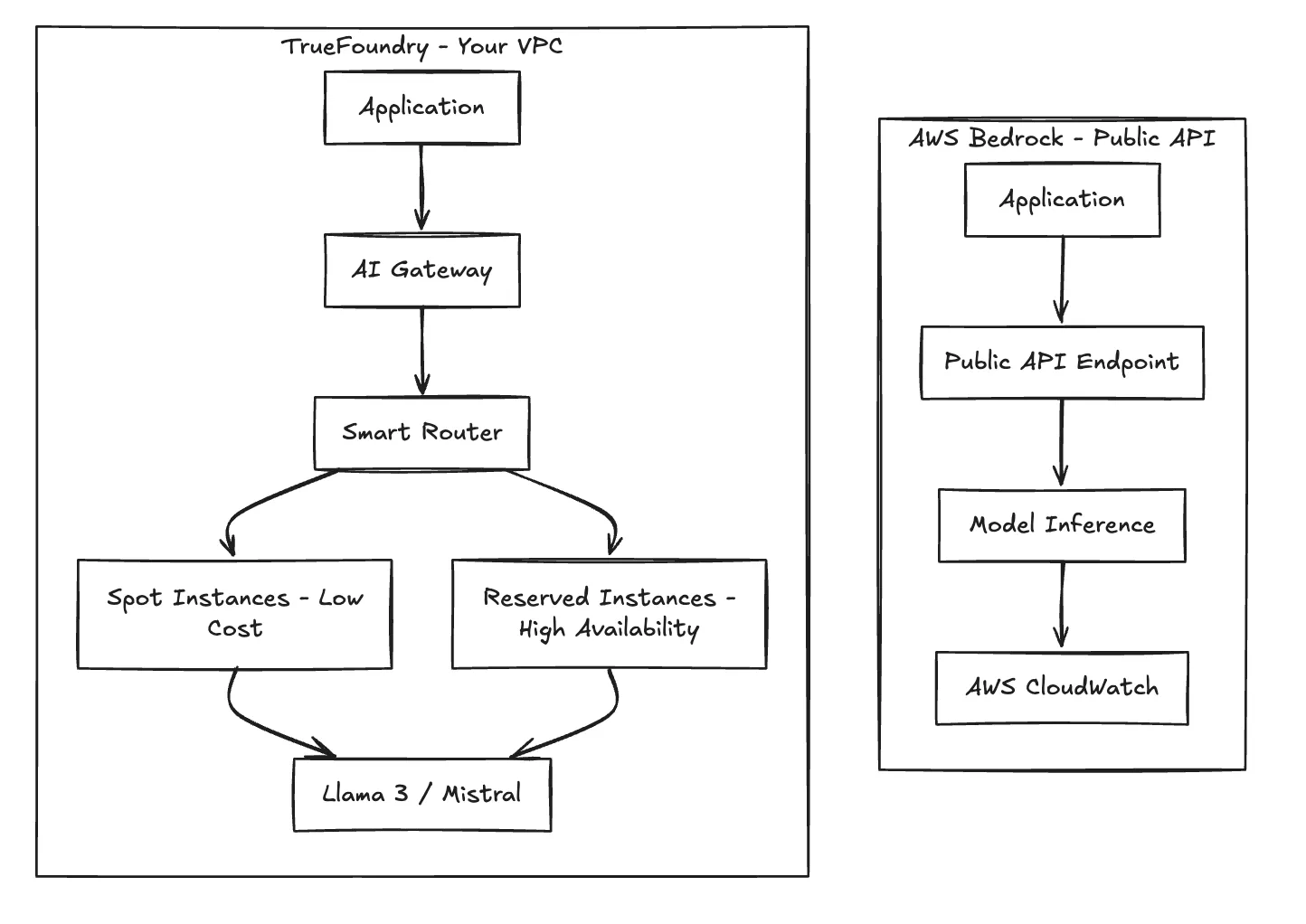
Diese Architektur entkoppelt das Entwicklererlebnis von der zugrunde liegenden Infrastruktur.
Wahre Gießerei berechnet keine Prämie auf Inferenz-Tokens, wenn Sie Ihre eigenen Open-Source-Modelle hosten. Sie zahlen die zugrunde liegenden Infrastrukturkosten direkt an Ihren Cloud-Anbieter. Bei Workloads mit hohem Volumen sind diese pauschalen Rechenkosten deutlich günstiger als die lineare Skalierung der tokenbasierten Preisgestaltung.
Benutzer auf G2 bewerten TrueFoundry durchweg 4,8/5, was die Fähigkeit der Plattform hervorhebt, die Komplexität von Kubernetes für Backend-Ingenieure zu abstrahieren. Ein Testbericht stellt fest: „Es hat unser Backend-Team über Nacht zu MLOps-Ingenieuren gemacht, ohne die Lernkurve von Kubeflow.“
Aktion: Melden Sie sich für das kostenlose TrueFoundry-Kontingent an um das AI Gateway zu testen.
Vertex AI ist tief in das Google Cloud-Ökosystem integriert. Es bietet nativen Zugriff auf die Gemini-Familie und unterstützt AutoML. Es zeichnet sich durch die Operationalisierung von Modellen mit integrierten Feature-Stores und einer Vektorsuche aus, die direkt in BigQuery integriert ist.
Die Preisgestaltung ist nach Geschäftsbereichen segmentiert. Zum Beispiel wird der Preis für Gemini 1.5 Pro pro 1.000 Zeichen/Bildern berechnet. Entscheidend ist, dass bei Prognosen auf speziell trainierten Modellen Gebühren pro Knotenstunde anfallen. Die spezifische Aufschlüsselung der Maschinentypen (z. B. n1-standard-4 im Vergleich zu TPU v5e) finden Sie unter Vertex AI Pricing.
Vertex ist aufgrund des Datenzugriffs mit niedriger Latenz innerhalb des GCP-Backbones optimal für Unternehmen, die BigQuery for RAG-Pipelines (Retrieval-Augmented Generation) verwenden.
Azure OpenAI Service bietet Zugriff auf GPT-4o und DALL-E 3 auf Unternehmensebene. Es fügt Compliance-Ebenen (SOC2, HIPAA) und private Netzwerke über Azure Private Link hinzu, die den Standard-OpenAI-APIs fehlen.
Azure verwendet ein „Pay-as-you-go“ -Modell und „Provisioned Throughput Units“ (PTUs). PTUs bieten garantierte Latenz, erfordern jedoch einen erheblichen Vorabaufwand. Laut Azure OpenAI Pricing können Standard-GPT-4-Modelle pro Token deutlich mehr kosten als Open-Source-Alternativen, die auf selbstverwalteten VMs gehostet werden.
Standardoption für Unternehmen mit bestehenden Microsoft Enterprise Agreements, die eine strikte RBAC über Microsoft Entra ID erfordern.
OCI Generative AI basiert auf einer „Supercluster“ -Architektur mit RDMA-Netzwerken, die für Hochleistungstraining konzipiert ist. Es verfügt über eine Partnerschaft mit Cohere für die eingebettete Vektorsuche.
OCI ist aggressiv bei der Datenverarbeitung. Laut Oracle Cloud Pricing unterbieten ihre GPU-Instances häufig AWS und Azure, was sie für reine Schulungsjobs attraktiv macht.
Ideal für High-Performance Computing (HPC) -Workloads und das Training umfangreicher Basismodelle von Grund auf, bei denen die reine Recheneffizienz pro Dollar der primäre KPI ist.
Mosaic AI ermöglicht es Unternehmen, LLMs mithilfe proprietärer Daten im „Data Lakehouse“ vorab zu schulen und zu optimieren. Die Architektur stellt sicher, dass die Schulungsdaten niemals die Unternehmensgrenzen des Kunden verlassen.
Die Preise werden in Databricks Units (DBUs) zuzüglich der zugrunde liegenden Cloud-Kosten angegeben. Dieses entkoppelte Modell bietet Transparenz, erfordert jedoch eine Überwachung der Instanztypen.
Ideal für Unternehmen, die proprietäre Daten als Wettbewerbsvorteil betrachten und kleinere, domänenspezifische Modelle (SLMs) trainieren müssen.
Botpress ist ein Low-Code-Orchestrierungstool auf Anwendungsebene. Es verfügt über einen visuellen Flow-Builder und Konnektoren für WhatsApp/Slack, wobei der Schwerpunkt eher auf dem Dialogmanagement als auf dem Model-Hosting liegt.
Nutzungsabhängige Modellabrechnung pro eingehender Nachricht.
Ideal für Produktteams, die Kundendienst-Bots erstellen, die keine GPU-Infrastruktur verwalten müssen.
Runpod bietet „Serverless GPU“ -Container (Pods) an. Es ermöglicht Entwicklern, innerhalb von Sekunden Instanzen mit vorkonfigurierten Vorlagen für vLLM oder Stable Diffusion einzurichten.
Runpod konkurriert mit unformatierten Stundensätzen. Zum Beispiel listet Runpod Pricing häufig A100-GPUs zu Preisen auf, die deutlich unter denen von Hyperscalern liegen, manchmal sogar so niedrig wie 1,69 $/h für Community-Cloud-Instanzen.
Zielt auf Startups ab, die kostengünstige On-Demand-GPU-Rechenleistung für die Stapelverarbeitung oder Feinabstimmung ohne langfristige Verträge benötigen.
Konzentriert sich auf industrielle Datenwissenschaft und bietet eine Umgebung ohne Code für die Datenaufbereitung und ML-Bereitstellung, die in Simulationsworkflows integriert ist.
Verwendet ein Lizenzeinheitenmodell (Altair Units), das in ihrem gesamten Softwareportfolio zusammengefasst ist.
Konzipiert für die Bereiche Fertigung und Luft- und Raumfahrt mit physikbasierten Simulationen.
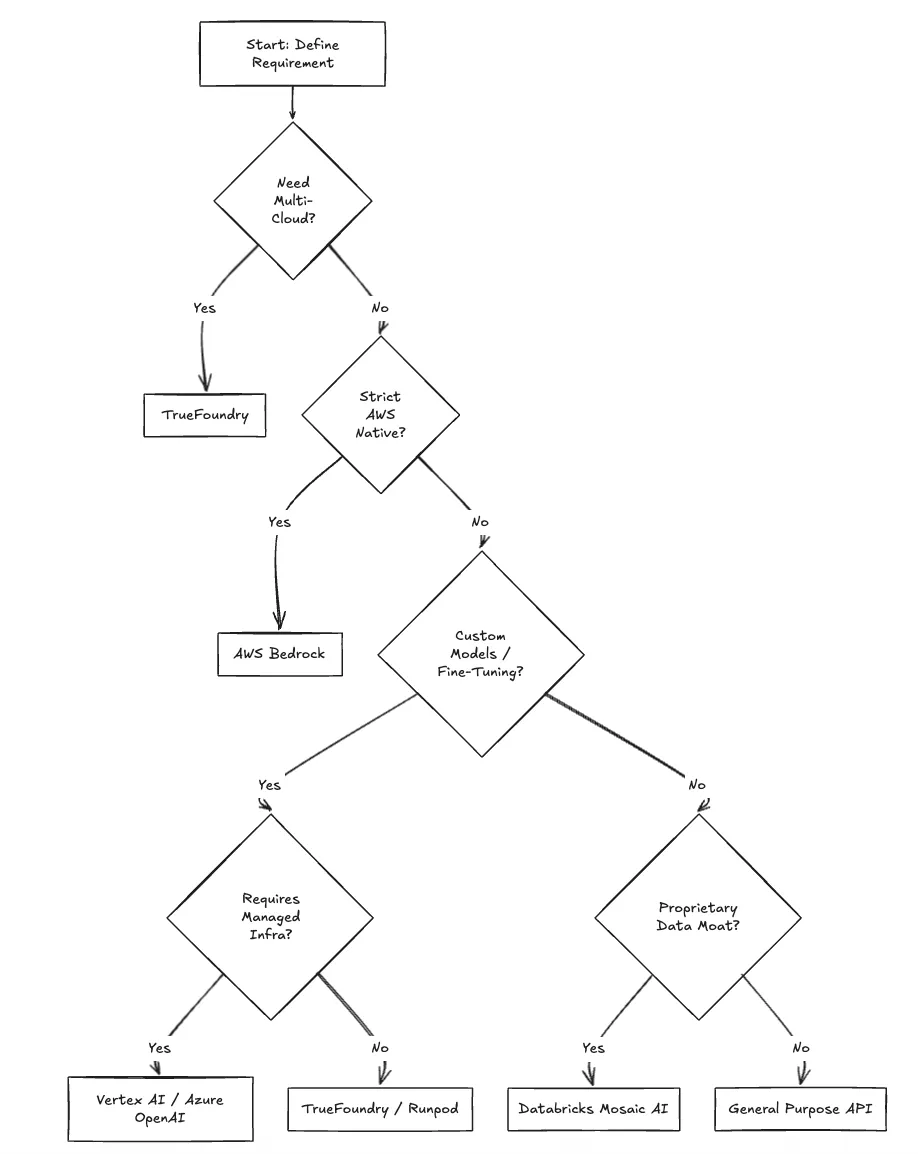
Die Auswahl der richtigen Alternative erfordert einen Entscheidungsrahmen, der auf dem Reifegrad der Infrastruktur und den architektonischen Zielen basiert.
Planen Sie eine Multi-Cloud-Architektur?
Wenn Ihre Strategie darin besteht, die Abhängigkeit von einem einzigen Anbieter zu vermeiden, ist eine einheitliche Kontrollebene unerlässlich. Wahre Gießerei ermöglicht Ihnen die Bereitstellung in jedem Cluster in AWS, GCP und Azure von einem einzigen Dashboard aus.
Ist die Vorhersagbarkeit der Kosten für die Budgetierung von entscheidender Bedeutung?
Token-basierte Preise sind schwer vorherzusagen. Wenn Sie stabile monatliche Ausgaben benötigen, können Sie die Rechenleistung über Wahre Gießerei (auf Reserved Instances oder Spot) ermöglicht eine deterministische Budgetierung. Wie zitiert in AWS-Sparpläne, wenn Sie sich für die Computernutzung entscheiden, können Einsparungen von bis zu 72% im Vergleich zu On-Demand-Preisen — Einsparungen, die Sie mit den API-Preisen von Bedrock nicht erzielen können.
Benötigen Sie Datensouveränität und VPC-Isolierung?
Regulierte Branchen können oft keine Daten an einen öffentlichen Multi-Tenant-API-Endpunkt senden. Wahre Gießerei stellt den Inferenzendpunkt bereit innen Ihre VPC, um sicherzustellen, dass Daten niemals Ihren Perimeter verlassen.
AWS Bedrock ist eine funktionale Lösung für Teams, die innerhalb des AWS-Ökosystems Prototypen entwickeln. Für Entwicklungsteams, die kosteneffiziente Multi-Cloud-KI-Produkte entwickeln, wird das „API-Wrapper“ -Modell jedoch zu einer Einschränkung. TrueFoundry bietet die notwendige Brücke: die Eigenverantwortung für die Infrastruktur und die Flexibilität eines maßgeschneiderten Builds ohne den betrieblichen Aufwand, der mit der Verwaltung roher Kubernetes-Manifeste verbunden ist.
Für das erste Prototyping ist Bedrock effizient. Bei Produktionsanwendungen ist das Markup auf Tokens jedoch oft weniger kostengünstig als das Hosten von Modellen auf Ihrer eigenen Infrastruktur. Mit einer KI-Plattform wie TrueFoundry KI-Gateway das für das schnelle Prototyping von KI-Modellen konzipiert ist, stellt sicher, dass Sie hohe Kosten vermeiden und erhebliche Kosteneinsparungen erzielen.
Zu den Einschränkungen gehören die Abhängigkeit vom Ökosystem, unvorhersehbare Kosten im großen Maßstab (Token-basierte Preisgestaltung) und Einschränkungen bei der Bereitstellung benutzerdefinierter quantisierter Modelle (wie GGUF-Formate), die zu Einsparungen bei der Datenverarbeitung führen könnten. Teams benötigen häufig eine nahtlose Integration mit verschiedenen Datenquellen für komplexe Aufgaben und müssen gleichzeitig verschiedene Versionen ihrer ML-Modelle verwalten.
Nein. ChatGPT ist eine SaaS-Anwendung. Bedrock ist ein PaaS (Platform as a Service), mit dem Anwendungen wie ChatGPT erstellt werden. Es handelt sich um einen vollständig verwalteten Dienst, bei dem Sie über einfache Textaufforderungen auf OpenAI Large Language Models zugreifen können.
Bedrock folgt dem AWS-Modell der gemeinsamen Verantwortung. Es bietet zwar Verschlüsselung, Ihre Daten werden jedoch auf einer von AWS verwalteten Infrastruktur verarbeitet. Das Selbsthosting über TrueFoundry in Ihrer eigenen VPC bietet eine höhere Isolierung. Wir implementieren strenge Sicherheitsmaßnahmen und Zugriffskontrollen, um Ihre KI-Entwicklung architekturübergreifend zu schützen.
Vertex AI ähnelt Amazon Bedrock mit verwalteten APIs, enthält jedoch robustere MLOps-Tools für benutzerdefiniertes Training.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




