
.webp)
July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 25, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
CI/CD hat sich still und leise zu einer der größten Kostenpositionen für LLMs in modernen Ingenieurorganisationen entwickelt. Ein einziger Sicherheitsprüfungsagent, der bei jeder Pull-Anfrage ausgelöst wird, kann die gesamte kundenorientierte KI-Arbeitslast des Ingenieurteams um das Dreifache übersteigen. Die Rechnung des Anbieters weist den Gesamtbetrag aus. Sie sagt Ihnen jedoch nicht, welche Pipeline, welches Repository oder welcher Agentenschritt dies verursacht hat. Ohne diese Zuordnung ist die einzige mögliche Reaktion ein pauschales Verbot, und der Produktivitätsverlust übersteigt die ursprüngliche Überschreitung.
Das AI Gateway von TrueFoundry schließt diese Lücke mit drei Grundelementen – obligatorischem Metadaten-Tagging bei jeder Anfrage, hierarchischen Budgets pro Kostenstelle mit weichen, eingeschränkten und harten Schwellenwerten sowie einer rollierenden P95-Prognose, die Überschreitungen aufzeigt, bevor sie auf der Rechnung erscheinen. Die Konfigurationen in diesem Beitrag sind real, kopierbar und basieren auf den offiziellen TrueFoundry- Budgetbegrenzung und Ratenbegrenzung Schemata.
Produktions-LLM-Anwendungen basieren auf Benutzerverkehr, der durch die Anzahl der Benutzer und die Anforderungshäufigkeit begrenzt ist. CI/CD-Pipelines basieren auf Maschinenverkehr – automatisierten Agenten, geplanten Jobs, periodischen Regressionen, PR-Reviews für jede Anfrage. Die Kostenstruktur ist grundlegend anders. Ein Team von 50 Ingenieuren, das jeweils 15 Pull-Anfragen pro Woche öffnet, generiert 750 PR-gesteuerte LLM-Aufrufe pro Woche, bevor jemand eine benutzerorientierte Funktion anfasst. Jeder Aufruf kann vier oder fünf Agentenschritte verketten. Jeder Schritt kann mehrere Modellaufrufe mit Kontexten von mehreren tausend Tokens tätigen. Der Durchsatzmultiplikator zwischen benutzerorientierter KI und CI/CD-KI beträgt routinemäßig das 10- bis 100-fache.
Das erste Mal, dass die technische Führungsebene aufmerksam wird, ist, wenn die Finanzabteilung eine Rechnung mit einem Betrag weiterleitet, der niemandes Vorstellung entspricht. Die Geschichte wiederholt sich in jeder Organisation, die agentenbasierte CI/CD ohne Beobachtbarkeit einführt: Oktober ist eine kleine Rechnung, November ist mittel, Dezember ist der Monat, der ein Führungstreffen auslöst. Das Muster ist so konsistent, dass Plattformteams es als erwarteten Betriebsstandard betrachten sollten, nicht als Überraschung.
Die Rechnung des Anbieters – Anthropic, OpenAI, Bedrock oder jeder andere – schlüsselt nach Modell und Token-Typ auf. Sie kann nicht nach Repository, Pipeline oder Agentenschritt aufschlüsseln, da der Anbieter nicht weiß, was diese Konzepte innerhalb Ihrer Ingenieurorganisation bedeuten. Diese Informationen befinden sich in Ihren Anforderungsmetadaten, die der Anbieter nie sieht. Aus Sicht des Anbieters sehen alle 847 Millionen Sonnet-Input-Tokens des letzten Monats identisch aus; aus Ihrer Sicht stammten 80 % davon aus einer außer Kontrolle geratenen Pipeline, die Sie in der ersten Woche gedrosselt hätten, wenn Sie es gewusst hätten.
Die Diskrepanz zwischen dem, was die Finanzabteilung erhält, und dem, was die Technik zum Debuggen benötigt, ist der strukturelle Grund, warum Kostenmanagementprojekte ins Stocken geraten. Die Finanzabteilung erhält eine Rechnung. Die Technik erhält dieselbe Rechnung ohne Aufschlüsselung. Ohne ein pro Arbeitslast geführtes Hauptbuch reduziert sich die Reaktion auf „Stoppt die Ausgaben für KI für zwei Wochen, während wir das herausfinden“, was den Produktivitätsgewinn zunichtemacht, den die KI erzeugt hat.
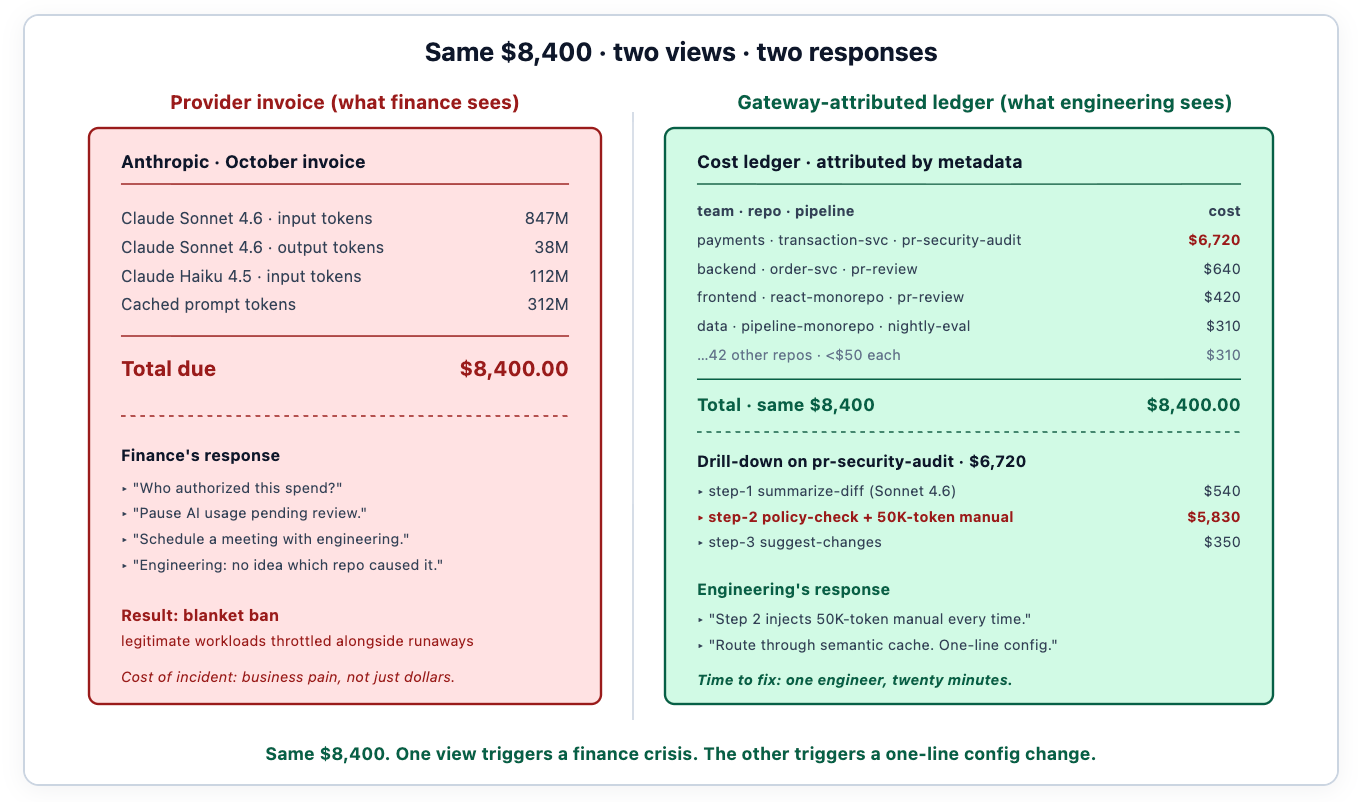
Derselbe Dollarbetrag führt zu gegensätzlichen Reaktionen, je nachdem, ob das Team eine Zuordnung hat. Ohne diese ist die Reaktion strukturell: Ausgaben verbieten, an die Führungsebene eskalieren, ein Meeting ansetzen, das sich für alle schlecht anfühlen wird. Mit ihr ist die Reaktion, dass ein Ingenieur das Kostenbuch liest, feststellt, dass Schritt 2 einer bestimmten Pipeline ein 50.000-Token-Richtlinienhandbuch in jeden Prompt injiziert, und eine einzeilige Konfigurationsänderung schreibt, um Schritt 2 durch den semantischen Cache zu leiten. Dieselbe Rechnung. Anderes Ergebnis.
Die Grundlage der Kostenzuordnung ist das obligatorische Tagging am Gateway. CI/CD-Pipelines müssen bei jeder Anfrage eine Identität injizieren – das Team, das Repository, die Pipeline, den Agentenschritt und die verantwortliche Kostenstelle identifizieren. Gemäß TrueFoundry's Dokumentation der Anfrage-Header, diese Identität wird in einem einzigen Header übertragen — x-tfy-metadata — dessen Wert ein serialisiertes JSON-Objekt mit String-Schlüsseln und String-Werten ist, begrenzt auf 128 Zeichen pro Wert. Die Felder innerhalb des JSON-Objekts sind Konventionen, die vom Plattformteam festgelegt wurden; sie sind keine eigenständigen HTTP-Header.
Eine korrekt formatierte Anfrage aus einer CI/CD-Pipeline sieht im Netzwerkverkehr so aus:
POST /api/llm/api/inference/openai/chat/completions HTTP/1.1
Host: gateway.truefoundry.ai
Authorization: Bearer {TFY_API_KEY}
Content-Type: application/json
x-tfy-metadata: {"team":"payments-platform","repo":"transaction-service","pipeline":"pr-security-audit","agent_step":"step-2-policy-check","cost_center":"eng-backend","run_id":"gh-run-882134"}Die Gateway-Dokumentation listet genau neun akzeptierte benutzerdefinierte Anfrage-Header auf: Authorization, x-tfy-metadata, x-tfy-provider-name, x-tfy-strict-openai, x-tfy-retry-config, x-tfy-request-timeout, x-tfy-ttft-timeout-ms, x-tfy-logging-configund x-tfy-mcp-headers. Benutzerdefinierte Identität – Team, Repo, Pipeline, Kostenstelle, Run-ID, alles andere, was das Plattformteam definiert – befindet sich ausschließlich im JSON-Wert von x-tfy-metadata, nicht als separate Header. Dies ist der einzige Vertrag, den das Gateway erkennt. Teams, die zusätzliche x-tfy-* -Header erfinden, stellen fest, dass sie stillschweigend ignoriert werden – die Metadaten erreichen niemals die Kostenverfolgungs- oder Richtlinienschichten, Dashboards verlieren die Zuordnung, und Audit-Logs enthalten nur das Bearer-Token. Ein Header, JSON als Inhalt, ist die Regel.
Sichtbarkeit ohne Durchsetzung ist ein Dashboard, das niemand nutzt. Das Gateway weist jeder Kostenstelle, die durch die Tagging-Funktion erzeugt wird, hierarchische, mathematisch durchgesetzte Budgets zu. Das Zahlungsplattform-Team erhält beispielsweise 500 US-Dollar pro Woche für agentenbasierte CI/CD-Workflows; dieses Budget wird am Gateway, im Anforderungspfad, mit drei Schwellenwerten durchgesetzt, die unterschiedliche Antworten auslösen.
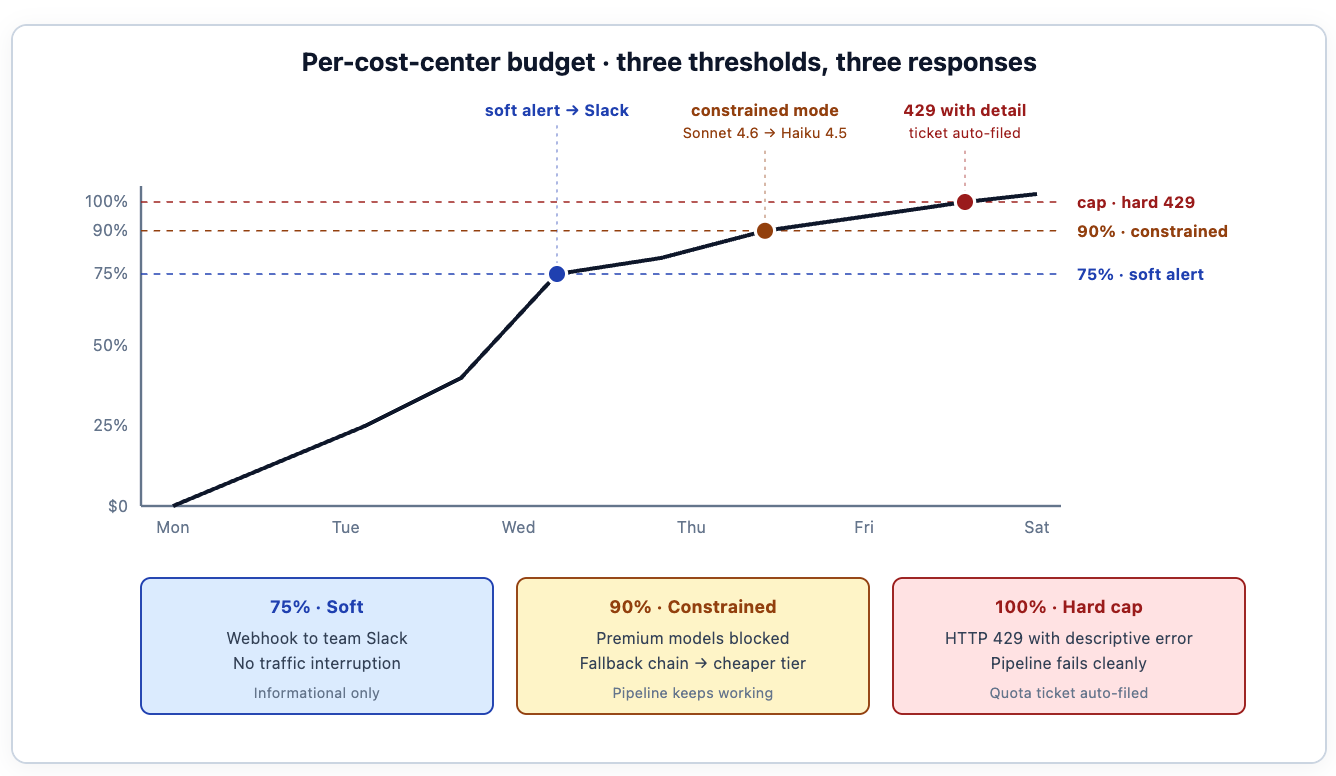
75 % der Obergrenze — Soft-Alert. Ein Webhook postet im Slack-Kanal des Teams: „Ihr habt drei Viertel des KI-Budgets dieser Woche aufgebraucht.“ Keine Traffic-Unterbrechung. Der Workload-Verantwortliche sieht die Warnung während der normalen Arbeitszeiten und kann entscheiden, ob er das Verhalten des Agenten anpasst, eine Quoten-Erhöhung beantragt oder nichts unternimmt, weil die Ausgaben legitim sind.
90 % — eingeschränkter Modus. Premium-Modelle (Sonnet 4.6, Opus 4.7, GPT-4o) werden blockiert; das Gateway leitet Anfragen transparent an günstigere Fallbacks (Haiku 4.5, GPT-4o-mini) über die Konfiguration für virtuelle Modell-Fallbacks weiter, sodass Pipelines weiterarbeiten, während die Kosten stabil bleiben. Die Fallback-Kette ist in einer separaten Routing-Konfiguration definiert – die Budget-Konfiguration löst die Einschränkung aus, die Routing-Konfiguration führt den Austausch durch. Die Anwendung sieht einen Header, der anzeigt, welches Modell die Anfrage tatsächlich bedient hat, und die Qualität kann für bestimmte Workloads variieren.
100 % — harte Obergrenze. Das Gateway lehnt weitere Anfragen mit HTTP 429 ab. Unten ist die Struktur dargestellt, die Plattformteams typischerweise für den Fehlertext entwerfen – die Standardantwort des Gateways ist prägnant, und das Team reichert sie über seine Wrapping-Schicht mit dem Kostenstellenkontext, dem Dashboard-Verweis und dem Quotenanfrage-Workflow an:
{
"error": "Budget Exceeded",
"detail": "Cost center 'eng-backend' has exhausted its weekly $500 AI budget.",
"context": {
"spent_to_date": "$501.23",
"cap": "$500.00",
"resets_at": "2026-05-19T00:00:00Z",
"top_consumer": "pipeline=pr-security-audit · 87% of spend"
},
"mitigation": "Review pipeline logs for runaway loops, or request a quota increase at /governance/quota."
}Der Fehlertext ist Teil des Designs. Eine Pipeline, die ihr Budget erreicht, sollte wissen, was als Nächstes zu tun ist – die Logs lesen, eine Quotenanfrage stellen – ohne dass der Entwickler dem Plattformteam hinterherlaufen muss, um Kontext zu erhalten. CI-Runner interpretieren 429 als ein Standard-Backoff-Signal; der Build schlägt sauber mit einer umsetzbaren Meldung fehl, anstatt auf verwirrende Weise abzustürzen. Dasselbe 429-Muster fügt sich in die Rate-Limit- und Runaway-Detection-Schichten ein, sodass ein Workload, der mehrere Kontrollen überschreitet, einen kohärenten Fehlerpfad erhält, anstatt einer Kaskade von nicht zusammenhängenden Fehlern.
Getaggte Daten, die in Grafana fließen, ermöglichen es dem Plattformteam, Dashboards zu erstellen, die Eigentumsfragen beantworten, anstatt mehr aggregiertes Rauschen zu erzeugen. Anstatt auf einen Ausschlag zu starren und zu fragen „Wer war das?“, zeigt Ihnen das Dashboard bereits, dass um 02:00 UTC das Frontend-Team einen neuen Agenten bereitgestellt hat, um react-monorepo das eine fehlende Abhängigkeit halluzinierte und in eine 400-stufige Auflösungsschleife geriet. Die Metadatenfelder erscheinen als Prometheus-Labels; Standard-PromQL-Abfragen liefern Aufschlüsselungen pro Team, pro Repository, pro Pipeline; Standard-Grafana-Dashboards visualisieren sie.
Diese Art von operativem Kontext verwandelt Kosten von einem Finanzproblem in ein Engineering-Problem. Sobald das Team erkennt, dass der Wechsel des anfänglichen Code-Zusammenfassungsschritts von Sonnet 4.6 zu Haiku 4.5 die Kosten dieses Schritts um 80 % senkt, ohne die Qualität der PR-Überprüfung zu beeinträchtigen, nimmt es die Änderung vor. Die Diskussion über Budgetobergrenzen muss nicht in einem Lenkungsausschuss stattfinden – die Daten sind das Argument, und die Änderung ist die Antwort.
Ein nützliches Dashboard bietet drei Ansichten: eine aggregierte Kosten-pro-Kostenstelle-Ansicht über die Zeit, eine Detailansicht nach Pipeline und Schritt und eine Anomalieansicht, die Kosten-Ausreißer automatisch aufzeigt. Die ersten beiden sind die Betriebs-Ansichten; die dritte ist die Frühwarnansicht, die die Ausreißer findet, bevor die Budgetgrenze zuschlägt. Die vom Gateway ausgegebenen OpenTelemetry-Traces umfassen das Modell, die Token-Anzahlen, die Metadatenfelder und den Dollarbetrag pro Aufruf – die vorhandenen Tools von Grafana erledigen den Rest.
Aggregierte Tagging-Daten erleichtern auch die Prognose. Agenten-Workloads sind stoßweise – periodische, ressourcenintensive CI-Jobs dominieren die Rechnung – weshalb einfache gleitende Durchschnitte die Ausgaben systematisch unterschätzen. Ein Team, das drei Wochen lang durchschnittlich 40 US-Dollar pro Tag und an einem einzigen Mittwoch für einen Release-Train-Lauf 400 US-Dollar ausgab, hat einen gleitenden Durchschnitt von 51 US-Dollar pro Tag; ihre tatsächlichen Ausgaben am Monatsende, wenn sie zwei weitere Release-Trains ausliefern, liegen bei über 2.000 US-Dollar.
Das Gateway führt eine 7-Tage-P95-Rollierende Prognose pro Repository und Kostenstelle durch. P95 erfasst das Spitzenrisiko, das ein Durchschnitt glättet, und prognostiziert die Ausgaben am Monatsende mit genügend Vorlaufzeit, um Budgets anzupassen, Quoten zu erhöhen oder eine fehlerhafte Pipeline stillzulegen, bevor die Finanzabteilung die Überraschung bemerkt. „Überraschung“ ist das Schlüsselwort: Dies ist eine Prognose, die darauf ausgelegt ist, keine Überraschungen zu produzieren. Wenn die Prognose besagt, dass ein Team sein monatliches Budget um 30 % überschreiten wird, hat das Team zwei oder drei Wochen Zeit, um zu handeln, bevor die harte Obergrenze greift.
Die Prognose erscheint im selben Grafana-Dashboard wie die Echtzeit-Ausgaben, wobei die Projektion neben der historischen Kurve eingezeichnet ist. Plattformteams, die die Prognose wöchentlich überprüfen, erkennen das Muster, das die Budgetkrise des nächsten Quartals verursacht; Teams, die die Prognose nicht überprüfen, erfahren von dem Problem auf die gleiche Weise wie immer – von der Finanzabteilung.
Im Folgenden wird ein illustratives Beispiel vorgestellt, das auf Mustern basiert, die dieses Team bei realen Kundenimplementierungen beobachtet hat – die Zahlen sind stilisiert, um die Mechanismen zu verdeutlichen, aber der Fehlerfall und die Lösung sind beide häufig.
Eine Organisation mit 50 Ingenieuren entwickelte einen dreistufigen Claude Code-Review-Agenten, der bei jeder Pull-Anfrage ausgeführt wurde: (1) den Diff zusammenfassen, (2) den Diff anhand von Sicherheitsrichtlinien über einen MCP-Dokumentationsserver überprüfen, (3) Codeänderungen vorschlagen. Sinnvolle Architektur, nützlicher Workflow, keine offensichtlichen Warnsignale. Der Agent ging Anfang September in Produktion.
Bei etwa 15 PRs pro Ingenieur pro Woche, unter Berücksichtigung von Wiederholungsversuchen und der Kontextfenster-Kosten für das Einfügen ganzer Dateien in Prompts, verbrauchte der Agent durchschnittlich etwa 400.000 Input-Tokens pro PR. Rechnung für den ersten Monat für CI/CD-Automatisierung: 8.400 US-Dollar. Die Rechnung traf am 5. Oktober ein. Die Slack-Nachricht von der Finanzabteilung traf am 6. Oktober ein. Das Gespräch, das zu diesem Beitrag führte, fand am 7. Oktober statt.
Die Zuordnung deckte die tatsächliche Ursache innerhalb weniger Minuten auf, nachdem das Team sich im Kosten-Dashboard angemeldet hatte. Schritt 2 injizierte ein 50.000-Token-Sicherheitshandbuch in jeden Prompt, bei jeder PR, unabhängig davon, ob der Diff tatsächlich richtlinienrelevanten Code betraf. Das Modell las das gesamte Handbuch, um zu beurteilen, ob es angewendet werden sollte; die Antwort war zu 80 % „nein, das ist eine CSS-Änderung“; die Kosten wurden jedes Mal bezahlt. Das Routing von Schritt 2 über das Gateway-eigene semantic cache — basierend auf der Dateierweiterung und der Inhaltssignatur des Diffs — reduzierte den Token-Overhead um 92 %. Gleiche Abdeckung. Gleiche Vorschläge. Monatliche Rechnung unter 800 US-Dollar.
Ohne Zuordnung wäre die Reaktion ein pauschales Verbot von Sonnet für CI-Workflows gewesen. Das Engineering hätte den Produktivitätsverlust hingenommen; die Finanzabteilung hätte den politischen Sieg verbucht; niemand hätte erfahren, was das eigentliche Problem war. Mit Zuordnung war die Reaktion eine Ein-Zeilen-Konfigurationsänderung. Das ist der Unterschied, den die Daten ausmachen.
Zwei TrueFoundry-Richtlinienkonfigurationen bilden die Grundlage des gesamten Musters: eine Budgetkonfiguration, die Dollar-Obergrenzen mit Audit-Modi und Warnungen durchsetzt, und eine Ratenlimit-Konfiguration, die Token- und Anfragequoten durchsetzt. Beide sind echte Schemata – kopieren Sie diese direkt in das AI Gateway Richtlinien Tab. Die Schema-Referenz befindet sich in der offiziellen Dokumentation für Budgetbegrenzung und Ratenbegrenzung. Zwei semantische Punkte, die Sie vor der Bereitstellung verinnerlichen sollten:
Erstens, zum Thema Regelreihenfolge und geschichtete Nachverfolgung: Gemäß der Budgetdokumentation von TrueFoundry werden, wenn eine Anfrage mehreren Regeln entspricht, die Kosten für jede passende Regel erfasst, aber nur die erste passende Regel steuert die Freigabe-/Blockierungsentscheidung. Die Reihenfolge der Regeln im YAML bestimmt die Priorität – es gibt kein separates Prioritätsfeld. In der folgenden Konfiguration entspricht eine Zahlungsplattform-Anfrage sowohl der spezifischen payments-platform-weekly -Regel (erste Übereinstimmung, steuert die Blockierungsentscheidung) als auch der allgemeinen per-user-daily-default -Regel (verfolgt ebenfalls die Kosten, nützlich für die Sichtbarkeit pro Entwickler). Dies ist beabsichtigt: Das Dashboard zeigt sowohl die Nutzung auf Kostenstellenebene als auch auf Benutzerebene für dieselbe Anfrage an.
Zweitens, zum Thema Benennung von Anbieterkonten: Modell-Identifikatoren wie anthropic-main/claude-opus-4-7 folgen dem Format <provider-account-name>/<model-id>, wobei der Name des Anbieterkontos derjenige ist, den der Workspace-Administrator dem Anthropic-Konto in AI Gateway → Models. Der Teil "model-id" ist von Anthropic festgelegt. Überprüfen Sie den Namen des Anbieterkontos in Ihrer spezifischen TrueFoundry-Instanz, bevor Sie ihn kopieren und einfügen.
Budgetkonfiguration – Dollar-Durchsetzung pro Kostenstelle, mit Audit-Modus für eine sichere Einführung:
name: cicd-budget-config
type: gateway-budget-config
rules:
# Priority 1 (first in list = first match): payments-platform — higher cap
- id: 'payments-platform-weekly'
when:
metadata:
cost_center: 'eng-backend-payments'
limit_to: 800
unit: cost_per_week
audit_mode: false # enforce: block on exceed
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: slack-bot
notification_channel: 'eng-alerts-channel'
channels: ['#eng-backend-ai']
# Priority 2: data team — lighter cap, longer period
- id: 'data-team-monthly'
when:
metadata:
cost_center: 'eng-data'
limit_to: 2000
unit: cost_per_month
audit_mode: false
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: email
notification_channel: 'data-alerts'
to_emails: ['data-platform-lead@example.com']
# Priority 3: intern sandbox — hard cap, no exceptions
- id: 'intern-sandbox-weekly'
when:
metadata:
cost_center: 'intern-sandbox'
limit_to: 50
unit: cost_per_week
audit_mode: false
alerts:
thresholds: [100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']
# Default per-user safety net — $20/day per individual developer.
# Tracks against every request (layered), controls block only for requests
# that don't match a higher-priority rule above.
- id: 'per-user-daily-default'
when: {}
limit_to: 20
unit: cost_per_day
budget_applies_per: ['user']
audit_mode: true # audit-only during initial rollout
alerts:
thresholds: [90, 100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']Ratenbegrenzungs-Konfiguration – Anforderungs- und Token-Kontingente, die zweite Verteidigungslinie:
name: cicd-ratelimiting-config
type: gateway-rate-limiting-config
rules:
# Per-pipeline token ceiling: prevents runaway agents.
# metadata.pipeline accesses the 'pipeline' field inside x-tfy-metadata JSON.
- id: 'pipeline-hourly-token-cap'
when: {}
limit_to: 500000
unit: tokens_per_hour
rate_limit_applies_per: ['metadata.pipeline']
# Per-user request floor: stops developer mistakes from going viral
- id: 'per-user-daily-requests'
when: {}
limit_to: 5000
unit: requests_per_day
rate_limit_applies_per: ['user']
# Premium-model brake: caps Opus consumption per cost center.
# Replace 'anthropic-main' below with your workspace's Anthropic
# provider-account name (see AI Gateway → Models in the dashboard).
- id: 'opus-per-cost-center-daily'
when:
models: ['anthropic-main/claude-opus-4-7']
limit_to: 200000
unit: tokens_per_day
rate_limit_applies_per: ['metadata.cost_center']Beide Konfigurationen sind versionskontrolliert, werden in Pull-Requests überprüft und über denselben GitOps-Workflow angewendet, den das Plattformteam für den Rest des Gateways verwendet. Die oben genannten Schemata stimmen exakt mit der offiziellen Dokumentation überein – jedes Feld, jeder Wert, jeder rate_limit_applies_per Eintrag ist dokumentiert und wird unterstützt. Workload-Teams schlagen Änderungen an ihren eigenen Kostenstellen-Einträgen über Pull-Requests vor; das Plattformteam genehmigt; das Gateway übernimmt die Änderung bei seinem nächsten Abgleichszyklus.
Die audit_mode: true Einstellung der standardmäßigen Pro-Benutzer-Regel ist das hervorzuhebende Sicherheits-Primitiv. Während der Einführung ermöglicht der Audit-Modus der Regel, tatsächliche Ausgaben zu verfolgen und Warnungen auszulösen, ohne den Datenverkehr zu blockieren. Nach ein oder zwei Wochen Beobachtung ändert das Team audit_mode auf false um es durchzusetzen. Dies ist der risikoärmste Weg zu einem produktionsreifen Budget-Durchsetzungssystem: zuerst beobachten, dann durchsetzen und niemals eine Zahl durchsetzen, die Sie noch nicht durch echten Datenverkehr erzeugt gesehen haben.
Der Fall einer einzelnen Organisation, bei dem jede Kostenstelle zu einem Unternehmen gehört, ist der einfache. Viele KI-Produktionsbereitstellungen sind Multi-Tenant-Systeme: Ein B2B-SaaS-Produkt bietet seinen eigenen Kunden KI-Funktionen an, und die KI-Rechnung muss pro Tenant zugewiesen werden, bevor das Unternehmen weiß, welche Kunden profitabel sind und welche subventioniert werden. Die Kostenattributionsschicht macht diese Frage beantwortbar.
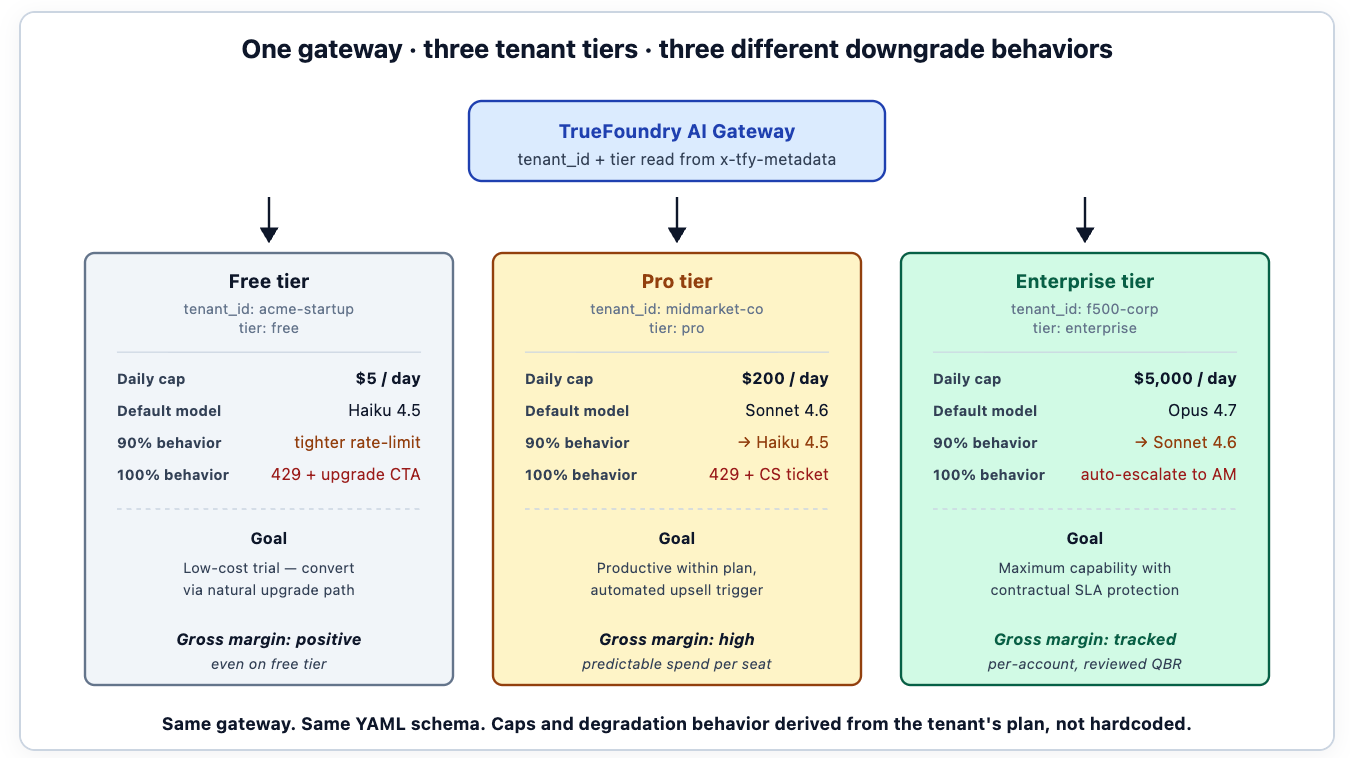
Das funktionierende Muster fügt tenant_id als weiteres Feld im Metadaten-Envelope. Der Bucket-Schlüssel für die Budgetierung wird zur Kombination aus tenant_id und Workload; das Dashboard unterstützt eine Ansicht pro Mandant neben der Ansicht pro Kostenstelle; der FinOps-Bericht verknüpft Gateway-Daten mit dem Abrechnungssystem des Unternehmens, um die Bruttomarge pro Mandant zu ermitteln. Ein Mandant, dessen KI-Verbrauch seine Planstufe überschreitet, erscheint im Dashboard, bevor der Kundenerfolg das Gespräch suchen muss.
Stufenabhängige Budgetobergrenzen sind das zweite Muster. Der Free-Tier-Mandant erhält eine engere Obergrenze als der Enterprise-Tier-Mandant; die Obergrenzen werden vom Plan des Mandanten abgeleitet und sind nicht fest codiert. Wenn ein Mandant ein Upgrade durchführt, aktualisiert sich die Obergrenze ohne Codeänderungen – der Plan ist Metadaten der Mandantenidentität, die Obergrenze ist eine Funktion des Plans. Teams, die Obergrenzen fest codieren, müssen diese bei jeder Preisänderung neu schreiben; Teams, die sie aus Mandantendaten ableiten, übernehmen das richtige Verhalten automatisch.
Das dritte Muster: degradierte, aber funktionierende Modi pro Stufe. Der eingeschränkte Modus des Enterprise-Tier-Mandanten könnte sie auf einem Frontier-Modell mit strengerer Ratenbegrenzung halten; der eingeschränkte Modus des Free-Tier-Mandanten könnte sie zu einem selbst gehosteten kleinen Modell leiten. Dasselbe Gateway, unterschiedliche Downgrade-Ketten, ausgedrückt als Konfiguration. Die Preisstruktur des B2B-SaaS-Unternehmens erscheint direkt in der Gateway-Konfiguration – was der richtige Ort dafür ist.
Vier Konfigurationsfehler treten regelmäßig bei den ersten Versuchen von Teams zur Kostenzuordnung auf. Jeder führt zu einem anderen, wissenswerten Fehlermodus.
Optionales Tagging. Das Team konfiguriert das Gateway so, dass es nicht getaggte Anfragen protokolliert, aber durchlässt, mit der Absicht, dies später durchzusetzen. Das „Später“ kommt nicht, und das Dashboard sammelt einen „unbekannten“ Bucket an, der Monat für Monat wächst. Wenn die Durchsetzung aktiviert wird, befindet sich die Hälfte des Datenverkehrs im unbekannten Bucket, und eine Änderung ist politisch kostspielig. Die Lösung besteht darin, die Ablehnung ab Woche 2 durchzusetzen, wenn der sichtbare Datenverkehr noch gering ist.
Zusätzliche Header erfinden. Teams versuchen manchmal, die Identität über mehrere Header zu verteilen – separate Header für Team, Repo, Kostenstelle und so weiter. Das Gateway erkennt genau neun benutzerdefinierte Header, die weiter oben in diesem Beitrag aufgeführt sind; der Rest wird stillschweigend ignoriert. Alle benutzerdefinierten Identitäten gehören in den JSON-Wert von x-tfy-metadata. Ein Header. JSON darin. Der Vertrag ist dokumentiert und das Gateway setzt ihn durch.
Teamübergreifende Kostenstellen. Eine Kostenstelle wie shared-infra scheint eine saubere Abstraktion zu sein, führt aber bei Überschreitungen zu keiner technischen Verantwortlichkeit – es gibt kein Team, das man anrufen könnte. Kostenstellen sollten der Verantwortungsfläche eines Teams zugeordnet sein; gemeinsame Arbeit gehört in eine „Plattform“-Kostenstelle, die dem Plattformteam gehört, und nicht in einen vagen gemeinsamen Bucket.
Feste Obergrenzen ohne aussagekräftige Fehlermeldungen. Ein 429 mit Body {"error": "rate_limited"} sagt dem Entwickler nichts Konkretes. Ein 429-Fehler mit Kostenstelle, Obergrenze, dem größten Verbraucher und einem Link zum Kontingentanforderungs-Workflow sagt ihnen genau, was zu tun ist. Das Fehler-Body-Schema ist einer der am besten abgestimmten Teile der Konfiguration in jeder ausgereiften Bereitstellung.
Die Kostenzuordnung ist eine der sichereren Einführungen im Bereich der KI-Plattformen, da der Fehlerfall eines „falsch kalibrierten Budgets“ begrenzt ist (einige Pipelines geraten unerwartet in den eingeschränkten Modus) und der Fehlerfall „keine Zuordnung“ katastrophal ist (die ausufernde Rechnung). Die richtige Reihenfolge ist: zuerst beobachten, dann durchsetzen.

Woche 1 — Tagging im Audit-Modus. Aktualisieren Sie die CI-Templates, um x-tfy-metadata bei jeder Anfrage einzufügen. Konfigurieren Sie das Gateway so, dass nicht getaggte Anfragen als Warnungen protokolliert, aber durchgelassen werden. Das Dashboard am Ende der Woche zeigt dem Team die natürliche Struktur ihrer Ausgaben: welche Pipelines dominieren, welche Kostenstellen die Hauptnutzer sind, welche Modelle die Workloads tatsächlich bevorzugen. Dies sind die Daten, die als Grundlage für die Budgetkalibrierung dienen.
Woche 2 — Nicht getaggte Anfragen ablehnen. Stellen Sie das Gateway so ein, dass es bei nicht getaggten Anfragen einen 400-Fehler zurückgibt. Die in Woche 1 aktualisierten CI-Templates sind die einzigen legitimen Clients; jede 400-Antwort weist entweder auf eine nicht aktualisierte Vorlage oder einen externen Aufrufer hin, der behoben werden muss. Bis zum Ende von Woche 2 ist jede Anfrage in der Produktion getaggt.
Wochen 3-4 — Budgets im Audit-Modus konfigurieren. Stellen Sie die Budgetkonfiguration mit audit_mode: true für alle Regeln bereit. Legen Sie die weichen Schwellenwerte (75 %) basierend auf dem beobachteten P95 der legitimen Ausgaben plus Marge fest. Warnungen werden an die Team-Slack-Kanäle gesendet; es werden jedoch noch keine Durchsetzungsmaßnahmen ausgelöst. Das Team beobachtet, welche Schwellenwerte angemessen sind und welche angepasst werden müssen. Einige Workloads werden auf einer außer Kontrolle geratenen Bahn erscheinen; ein oder zwei werden es tatsächlich sein, und das Team kann eingreifen, bevor die Durchsetzung einsetzt.
Woche 5 — Durchsetzung aktivieren. Schalten Sie audit_mode auf false zu den Budgetregeln. Aktivieren Sie die 90%-Downgrade-Kette (gepaarte virtuelle Modell-Fallback-Konfiguration) und die 100%-Hard-Cap. Die Downgrade-Kette ist die umstrittenere Änderung bei den Workload-Verantwortlichen – einige Teams bevorzugen für ihre Pipelines stark „Fail Fast“ gegenüber „eingeschränkt, aber funktionsfähig“. Machen Sie die Kette von Anfang an pro Kostenstelle konfigurierbar, damit jedes Team sein bevorzugtes Verhalten wählen kann.
Woche 6+ — Prognose- und Überprüfungszyklus. Aktivieren Sie die 7-Tage-P95-Prognose. Richten Sie eine wöchentliche Überprüfung der Prognose durch das Plattformteam im Vergleich zu den Budgets ein. Neue Kostenstellen erhalten standardmäßig angemessene Anfangslimits basierend auf der beobachteten frühen Nutzung; Quotenänderungen erfolgen über Pull-Requests gegen die Konfiguration. Das System läuft als Infrastruktur, nicht als Projekt.
Die Kostenattributionsschicht benötigt eine klare Verantwortlichkeitsgrenze, da die von ihr erzeugten Daten gleichzeitig in den Bereichen mehrerer Stakeholder landen. Die richtige Aufteilung ist: Das Plattformteam besitzt die Schicht, die Workload-Teams besitzen ihre Budgets, die Finanzabteilung besitzt die strategische Sichtweise, die technische Leitung besitzt die Richtlinie.
Das Plattformteam betreibt das Gateway, die Tagging-Disziplin, die Budget-Engine und die Prognose. Sie überprüfen und genehmigen Quotenanfragen, passen die Downgrade-Ketten basierend auf Qualitätsfeedback von Workload-Verantwortlichen an und priorisieren die Alarme, die außerhalb der Geschäftszeiten ausgelöst werden. Ihre Aufgabe ist es, das System am Laufen zu halten; sie entscheiden nicht, wie viel jede Workload kosten soll.
Die Workload-Teams besitzen ihren eigenen Kostenstelleneintrag in der Konfiguration. Sie schlagen Budgetänderungen über Pull-Requests vor; sie optimieren ihre Pipelines, wenn sie auf Soft-Alerts stoßen; sie wählen zwischen „eingeschränkt, aber funktionsfähig“ und „Fail-Fast“-Verhalten für ihre Hard-Cap-Antwort. Das Plattformteam genehmigt; das Workload-Team führt aus.
Finanz- und technische Führungskräfte nutzen die aggregierten Ansichten. Monatliche Abschlussgespräche nennen spezifische Kostenstellen und spezifische Pipelines anstelle von aggregierten Zahlen. Die Quartalsplanung nutzt die Prognose, um die Ausgaben für KI-Infrastruktur zu projizieren; Budgetzyklen werden vorhersehbar statt reaktiv. Dies ist die Eigenschaft, die KI-Ausgaben zu einem budgetierten Posten macht, anstatt zu einer wiederkehrenden Überraschung.
Obligatorisches Tagging ist kein Ersatz für Prompt Engineering. Eine Workload, die ein 50.000-Token-Handbuch in jeden Prompt injiziert, wird durch das Tag genau erfahren, welche Workload teuer ist; es wird ihr jedoch nicht sagen, wie sie das Problem beheben kann. Die Lösung – ein kleineres Handbuch, ein Cache, eine gezieltere Abfrage, ein für die Aufgabe besser geeignetes Modell – ist die technische Arbeit, die der Attribution folgt. Das Dashboard ist die Diagnose; die Lösung ist die Behandlung.
Hierarchische Budgets sind keine Garantie für Kostenkontrolle. Ein Team, dessen Budget jedes Mal erhöht wird, wenn es das Limit erreicht, kommt irgendwann zu dem Schluss: „Das Limit existiert nicht.“ Die Disziplin liegt im Budgetüberprüfungszyklus, nicht im technischen Mechanismus. Plattformteams, die jede Quotenanfrage genehmigen, verlieren den Hebel, den das Budget bieten sollte.
Und Kostenattribution am Gateway ist nicht die richtige Antwort für jede Organisation. Teams, deren gesamte KI-Ausgaben so gering sind, dass die technische Investition die Einsparungen übersteigt, sollten zuerst ein anderes Problem lösen; Teams, deren bestehende FinOps-Tools bereits eine pro-Workload-Attribution aus Cloud-Anbieterdaten erzeugen, benötigen kein paralleles System am Gateway. Das Muster passt zu Organisationen, deren KI-Ausgaben schneller gewachsen sind als ihre Transparenz darüber – typischerweise überall über 5.000 US-Dollar/Monat an Anbieterkosten, wo die Kosten eines außer Kontrolle geratenen Vorfalls die Kosten für den Aufbau der Schicht übersteigen. Unterhalb dieser Schwelle rechnet sich die Mathematik selbst eines Standard-Gateways wie dem von TrueFoundry nicht immer; das Team ist besser beraten, die Ausgaben in ein oder zwei gut überwachten Anwendungen zu halten und die Schicht anzuwenden, wenn das Wachstum dies rechtfertigt.
Beides, gleichzeitig. Dollar stimmen mit der Finanz- und Betriebsplanung überein. Tokens sind die technische Metrik, die es dem Team ermöglicht, die Prompt-Effizienz zu debuggen – eine Workload, deren Token-Verbrauch sich verdoppelt, während die Dollarkosten gleich bleiben (weil das Modell billiger wurde), ist aus technischer Sicht eine Untersuchung wert, auch wenn die Finanzabteilung dies nicht bemerkt. Das Gateway verfolgt beides; die Finanzabteilung besitzt die Dollar-Dashboards, die Technikabteilung besitzt die Token-Dashboards, und das Gateway ist die Quelle der Wahrheit für beides.
Die Pipeline erhält einen 429-Fehler mit dem oben gezeigten beschreibenden Fehlertext und einem Link zum Budget-Dashboard. CI-Runner interpretieren 429 als ein Standard-Backoff-Signal; der Build schlägt sauber mit einer umsetzbaren Meldung fehl, anstatt auf verwirrende Weise abzustürzen. Quotenanfragen werden als Standard-Tickets über den Link im Fehlertext an das Plattformteam gerichtet. Der letzte erfolgreiche Schritt der Pipeline bleibt erhalten; die Wiederaufnahme nach der Quotenerhöhung wiederholt keine bereits bezahlte Arbeit.
In der Praxis: Nein. TrueFoundry liefert SDK-Wrapper, die den Metadaten-Umschlag automatisch aus Umgebungsvariablen injizieren, die CI-Runner bereits gesetzt haben, sodass einzelne Entwickler niemals Header bearbeiten müssen. Die einmaligen Kosten bestehen in der Aktualisierung der Pipeline-Vorlagen des Teams; die wiederkehrenden Kosten sind null. Der wiederkehrende Nutzen ist jedes darauf folgende Dashboard.
Verwenden Sie eine stabile workflow_id Feld innerhalb des x-tfy-metadata JSON – denselben Wert für jede Anfrage, die zum selben logischen Workflow gehört. Das Gateway gruppiert Anfragen nach workflow_id zur Durchsetzung des Budgets pro Workflow. Ein Workflow mit einer Obergrenze von 5 $ kann Hunderte von Anfragen umfassen; das Gateway verfolgt die laufende Summe anhand der Workflow-ID und nicht anhand der einzelnen Anfrage.
Sie stimmt mit der Rechnung des Anbieters bei den Kosten für Eingabe- und Ausgabetoken innerhalb von etwa 1 % überein; die geringe Abweichung resultiert aus Rundungen und anbieterseitigen Zuschlägen (Mengenrabatte, regionale Unterschiede), die das Gateway zum Zeitpunkt der Anfrage nicht erkennen kann. Für die meisten Planungszwecke sind die Zahlen des Gateways ausreichend genau; für eine buchhalterisch korrekte Abstimmung bleibt die Rechnung des Anbieters die Quelle der Wahrheit, wobei das Gateway die Aufschlüsselung pro Workload liefert. Die Dokumentation zur Kostenverfolgung von TrueFoundry beschreibt sowohl öffentliche Preismodelle (vom Anbieter veröffentlichte Tarife) als auch private Preismodelle (kundenspezifische Verträge).
Budgets sind pro Kostenstelle festgelegt; ein unkontrollierter Verbrauch eines Teams verbraucht nur dessen eigenes Budget. Die feste Obergrenze stoppt den Verbrauch, bevor er andere Teams beeinträchtigen kann. Die Obergrenzenregel auf Modellebene in der Ratenbegrenzungskonfiguration (das opus-per-cost-center-daily Beispiel) ist eine Absicherung für den Fall, dass mehrere Teams gleichzeitig Fehlverhalten zeigen oder die Zuordnung selbst fehlerhaft ist; sie operiert oberhalb der Pro-Kostenstelle-Ebene.
Teamübergreifende Arbeit ist selten, aber real. Das sauberste Muster ist die Definition einer Kostenstelle für "gemeinsame Initiativen", die dem Plattformteam gehört, mit expliziten Rückverrechnungsregeln, die im Gateway-README dokumentiert sind. Die Kennzeichnung bleibt einwertig – die Anfrage gehört zur Laufzeit genau einer Kostenstelle – aber das Plattformteam kann die Ausgaben am Ende jeder Abrechnungsperiode über die exportierten Kostendaten, die in der Dokumentation zur Kostenverfolgungbeschrieben sind, an die teilnehmenden Teams weiterleiten.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




