

July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Das Aufkommen großer Sprachmodelle (LLMs) hat die KI-Fähigkeiten verändert — aber die Feinabstimmung dieser riesigen Modelle bleibt eine kostspielige, ressourcenintensive Herausforderung. Hier kommt LoRa (Low-Rank Adaptation) ins Spiel, eine bahnbrechende Technik, die eine effiziente Feinabstimmung vortrainierter Modelle ermöglicht, indem die Anzahl der trainierbaren Parameter drastisch reduziert wird. Anstatt das gesamte Modell zu aktualisieren, fügt LoRa leichte, trainierbare Module ein, wodurch die Feinabstimmung schneller, billiger und zugänglicher wird. Egal, ob Sie domänenspezifische LLMs erstellen oder Edge-Bereitstellungen optimieren, LoRa ist zu einer bevorzugten Methode in modernen ML-Workflows geworden. In diesem Handbuch werden wir aufschlüsseln, was LoRa ist, wie es funktioniert und warum es die Feinabstimmung verändert.
LoRa, kurz für Low-Rank Adaptation, ist eine parametereffiziente Feinabstimmungstechnik, mit der große, vorab trainierte Modelle angepasst werden können, ohne dass ihre Matrizen mit vollem Gewicht aktualisiert werden müssen. Anstatt die ursprünglichen Modellparameter zu modifizieren — deren Zahl in die Milliarden gehen kann — führt LoRa kleine trainierbare Rangzerlegungsmatrizen in bestehende Ebenen ein. Diese Module erlernen die Feinabstimmung, während das Basismodell eingefroren bleibt.
Die Kernidee hinter LoRa wurzelt in der linearen Algebra. Anstatt direkt eine große Gewichtungsaktualisierungsmatrix ΔW zu lernen, nähert sich LoRa sie als Produkt zweier kleinerer Matrizen an:
ΔW≈ A⋅ B
wo aωrd×R und bωrr×K, mit rωmin (d, k). Diese Faktorisierung mit niedrigem Rang reduziert die Anzahl der Parameter, die trainiert werden müssen, drastisch, oft um mehrere Größenordnungen.
In der Praxis werden LoRa-Module in bestimmte Schichten eines Transformatormodells eingefügt (typischerweise Aufmerksamkeits- und Feedforward-Schichten). Während des Trainings werden nur die LoRa-Parameter aktualisiert, während die ursprünglichen Modellgewichte eingefroren bleiben. Dadurch ist LoRa nicht nur effizient in Bezug auf Rechen- und Speichernutzung, sondern auch modular — Sie können verschiedene LoRa-Adapter für verschiedene Aufgaben trainieren und sie bei Bedarf ein- und austauschen.
Ursprünglich für NLP-Aufgaben eingeführt, wurde LoRa inzwischen in Sichtmodellen, Spracherkennung und multimodalen Architekturen eingesetzt — was seine Vielseitigkeit in allen Bereichen unter Beweis stellt.
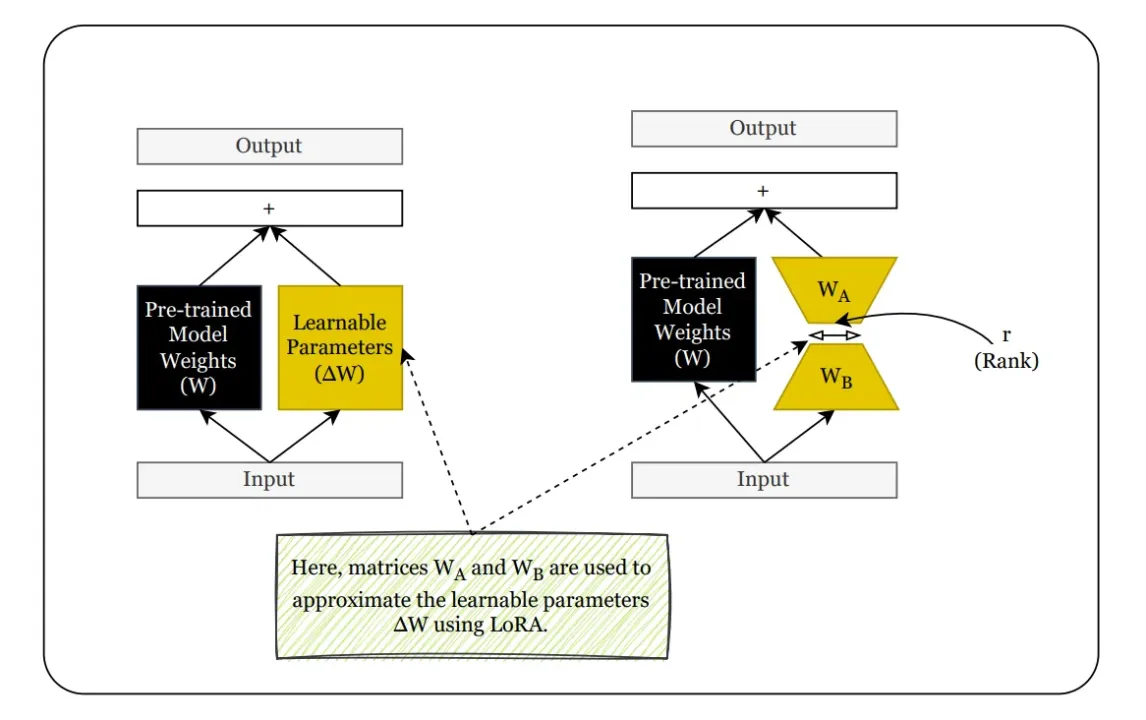
Die LoRa-Feinabstimmung ist eine Methode zur Anpassung großer vortrainierter Modelle — wie BERT, GPT oder LLAMA —, indem nur eine kleine Anzahl zusätzlicher Parameter trainiert wird, anstatt das gesamte Modell zu aktualisieren. Es nutzt das Kernprinzip von LoRa (Low-Rank Adaptation), um die Feinabstimmung recheneffizienter, speicherfreundlicher und einsatzbereiter zu machen, insbesondere in Umgebungen, in denen eine vollständige Neuschulung des Modells nicht praktikabel ist. Unter den modernen Tools zur Feinabstimmung, LoRa zeichnet sich durch seine Fähigkeit aus, große Modelle effizient anzupassen, ohne alle Parameter zu aktualisieren.
Bei der herkömmlichen Feinabstimmung werden alle Modellgewichte aktualisiert, was viel GPU-Speicher, Rechenzeit und Speicherplatz erfordert. Dies wird bei der Arbeit mit Modellen mit mehreren Milliarden Parametern zu einer Herausforderung. LoRa löst dieses Problem, indem es die vorab trainierten Modellgewichte einfriert und leichte trainierbare Adapter in bestimmte Ebenen einfügt — in der Regel die Abfrage- und Werteprojektionsebenen in transformatorbasierten Architekturen.
Während der LoRa-Feinabstimmung:
Aufgrund dieser Struktur ist die LoRa-Feinabstimmung besonders attraktiv für:
Nach dem Training können diese LoRa-Adapter separat gespeichert und zur Ableitung wieder in das Basismodell zusammengeführt werden — oder modular gehalten und je nach Anwendungsfall dynamisch ausgetauscht werden.
Die LoRa-Feinabstimmung beeinträchtigt auch nicht die Leistung. In vielen Benchmarks erzielen Modelle, die mit LoRa optimiert wurden, Ergebnisse, die der vollständigen Feinabstimmung entsprechen oder sogar besser sind als diese — und sind gleichzeitig deutlich ressourceneffizienter.
Die LoRa-Feinabstimmung ermöglicht die Personalisierung und Anpassung großer Modelle mit minimalem Rechenaufwand, maximaler Flexibilität und ohne Kompromisse bei der Genauigkeit.
Die technische Brillanz von LoRa (Low-Rank Adaptation) liegt in der Verwendung linearer Algebra, um die Anzahl der trainierbaren Parameter zu reduzieren, die bei der Feinabstimmung erforderlich sind — ohne Einbußen bei der Modellkapazität oder der Downstream-Leistung. Um zu verstehen, wie das funktioniert, wollen wir die zugrundeliegende Mechanik aufschlüsseln.
Das Problem mit Full-Rank-Updates
Bei der Standard-Feinabstimmung lernt ein vortrainiertes Modell eine neue Aufgabe, indem es seine Gewichtsmatrizen anpasst WWW. Diese Matrizen, insbesondere bei Modellen mit großen Transformatoren, sind massiv (z. B. Hunderte Millionen Parameter pro Schicht). Ihre direkte Aktualisierung führt zu hohem Speicherverbrauch, langen Trainingszeiten und Schwierigkeiten bei der Anpassung oder Bereitstellung mehrerer Aufgaben.
The LoRa Insight: Zerlegung mit niedrigem Rang
LoRa schlägt vor, dass die Gewichtsänderung, die erforderlich ist, um ein Modell an eine neue Aufgabe anzupassen, nicht hochdimensional sein muss. Stattdessen können diese Aktualisierungen mithilfe von Matrizen mit niedrigem Rang approximiert werden.
Anstatt eine vollständige Aktualisierungsmatrix ΔW zu lernen, führt LoRa zwei kleinere Matrizen ein:
ΔW=A⋅ B
wo, rωmin (d, k)
Diese Matrizen werden mit kleinen Zufallswerten initialisiert und sind die einzigen Parameter, die während des Trainings aktualisiert werden. Die ursprüngliche Matrix WWW bleibt eingefroren.
Integration in Transformatorschichten
LoRa wird typischerweise auf Aufmerksamkeitsprojektionen in Transformatorarchitekturen angewendet — insbesondere auf die Abfrage- (Q) und Wertprojektionsmatrizen (V). Bei der Feinabstimmung wird aus der angepassten Ausgabe:
W (x) +α⋅ A⋅ B (x)
wobei α ein Skalierungsfaktor ist (oft empirisch festgelegt) und A⋅ B (x) die erlernte Anpassung mit niedrigem Rang darstellt, die auf die Eingabe angewendet wird.
Effizienz und Backpropagation
Da nur die Matrizen mit niedrigem Rang trainierbar sind, wird die Anzahl der trainierbaren Parameter um Größenordnungen reduziert. Das reduziert:
Backpropagation erfolgt nur über die LoRa-Module, wodurch die Gradienten gering und die Aktualisierungen konzentriert bleiben.
Durch die Anwendung mathematischer Prinzipien auf die Modellarchitektur bietet LoRa eine hocheffiziente, modulare und elegante Lösung für die Anpassung großer Modelle — ideal für moderne LLM-Feinabstimmungsworkflows.
LoRa hat sich zu einer der wirkungsvollsten Techniken im Bereich der parametereffizienten Feinabstimmung (PEFT) entwickelt, und das aus gutem Grund. Es bietet eine Reihe praktischer Vorteile, die es besonders in Szenarien attraktiv machen, in denen große Sprachmodelle (LLMs), Multitask-Lernen oder Edge-Einsatz zum Einsatz kommen. Lassen Sie uns die wichtigsten Vorteile der Verwendung von LoRa für die Feinabstimmung untersuchen.
Signifikante Reduzierung der trainierbaren Parameter
Einer der herausragenden Vorteile von LoRa ist die Fähigkeit, die Anzahl der trainierbaren Parameter je nach Modellgröße und Rangkonfiguration um das bis zu 10.000-fache zu reduzieren. Durch das Erlernen nur eines kleinen Satzes von Adapterparametern minimiert LoRa den Speicherverbrauch und den Rechenaufwand und ermöglicht in einigen Fällen eine Feinabstimmung auf GPUs oder sogar CPUs für Endverbraucher.
Bewahrung von vortrainiertem Wissen
Da LoRa das Basismodell einfriert, vermeidet es „katastrophales Vergessen“, bei dem eine vollständige Feinabstimmung nützliches Allzweckwissen überschreiben kann. Dies macht LoRa besonders nützlich, wenn es darum geht, große Modelle an Nischendomänen (z. B. Recht, Medizin, Finanzen) anzupassen und gleichzeitig ihr ursprüngliches Sprachverständnis zu bewahren.
Modularität und Wiederverwendbarkeit
Mit LoRa können verschiedene Adapter für verschiedene Aufgaben trainiert und separat aufbewahrt werden. Dies ermöglicht:
Diese Modularität ist ideal für Plattformen mit mehreren Mandanten oder Anwendungsfälle, in denen häufig der Kontext gewechselt wird.
Verbesserte Skalierbarkeit und Bereitstellung
LoRa-Adapter sind klein und erfordern keine architektonischen Änderungen am Basismodell. Dies erleichtert das Anschließen an bestehende Pipelines für die Modellbereitstellung. Sie eignen sich auch für Edge-Computing-Umgebungen, in denen Modellgröße und Arbeitsspeicher begrenzt sind.
Wettbewerbsfähige Leistung
Trotz seines geringen Gewichts erreicht oder übertrifft LoRa bei Downstream-Aufgaben oft die volle Feinabstimmungsleistung — insbesondere in Kombination mit modernen Basismodellen und guten Daten.
LoRa bietet einen überzeugenden Kompromiss: nahezu vollständige Modellleistung zu einem Bruchteil der Kosten und Komplexität. Es demokratisiert die Feinabstimmung und macht erweiterte LLM-Anpassungen einem breiteren Spektrum von Teams und Entwicklern zugänglich.
In diesem Abschnitt erfahren Sie, wie Sie große Sprachmodelle mithilfe von LoRa mit der PEFT-Bibliothek von Hugging Face feinabstimmen. Dieser Ansatz ermöglicht es Ihnen, trainierbare Adapter mit minimalen Codeänderungen in vortrainierte Modelle einzufügen, wodurch LoRa sowohl zugänglich als auch produktionsbereit ist.
1. Installieren Sie die erforderlichen Bibliotheken
Installieren Sie die Kernbibliotheken, die Sie für das Laden von Modellen, Tokenisierung, Training und LoRa-Injektion benötigen.
pip install transformators links beschleunigte Datensätze
2. Laden Sie das Basismodell und den Tokenizer
Hier laden wir ein kausales Sprachmodell (z. B. LLama 2) und seinen Tokenizer mithilfe der Transformers-Bibliothek von Hugging Face. Dies dient als unser eingefrorenes Basismodell.
aus Transformatoren importieren AutoModelforCausallM, AutoTokenizer
model = autoModelForCausAllM.from_pretrained („meta-llama/LLAMA-2-7B-HF“)
tokenizer = AutoTokenizer.from_preTrained („meta-llama/llama-2-7b-HF“)
3. Injizieren Sie LoRa-Adapter in das Modell
Wir definieren eine LoRa-Konfiguration, die Folgendes spezifiziert:
Dies umhüllt das Basismodell und fügt trainierbare LoRa-Schichten hinzu.
von links importieren get_left_model, LoraConfig, TaskType
lora_config = LoraConfig (
task_type=TaskType.CAUSAL_LM,
r = 8,
lora_alpha=32,
lora_dropout=0,05,
target_modules= ["q_proj“, „v_proj"]
)
modell = get_peft_model (Modell, lora_config)
4. Tokenisieren Sie Ihren Datensatz für das Training
Wir laden einen Beispieldatensatz (z. B. im Alpaka-Format) und verarbeiten ihn vor, indem wir Anweisungen und Eingaben in ein flaches Textformat zusammenfügen und dann mit Auffüllen und Kürzen tokenisieren.
aus Datensätzen importiere load_dataset
dataset = load_dataset („yashishdua/alpaka-cleaned“)
def tokenize (Beispiel):
Tokenizer zurückgeben (Beispiel ["Anweisung"] + Beispiel ["Eingabe"], truncation=true, padding="max_length“, max_length=512)
tokenized_dataset = dataset.map (tokenisieren)
5. Verfeinern Sie das Modell mit dem Hugging Face's Trainer
Dadurch wird die Trainingsschleife mithilfe von Trainer eingerichtet und die Batchgröße, die Anzahl der Epochen, die Protokollierung und die Speicherstrategie angegeben.
von Transformers Import Trainer, TrainingArguments
Trainer = Trainer (
model=Modell,
args=Trainingsargumente (
Ausgabeverzeichnis=“. /lora-linker Prüfpunkt „,
pro_device_train_batch_size=2,
Anzahl_Zugepochen=3,
logging_steps=10,
save_strategy="Epoche“
),
train_dataset=tokenized_dataset ["Zug"],
tokenizer=tokenizer
)
trainer.train ()
6. Speichern Sie die Gewichte des LoRa-Adapters
Nach dem Training speichern wir nur die LoRa-Adapterschichten (nicht das komplette Basismodell), um die Dinge leicht und modular zu halten.
model.save_pretrained (“. /lora-linker Kontrollpunkt „)
7. Laden Sie die Adaptergewichte zur Inferenz
Um die Inferenz auszuführen, laden Sie das Basismodell neu und hängen Sie den gespeicherten LoRa-Adapter mit PeftModel an. Dadurch wird die fein abgestimmte Version effizient neu erstellt.
von links importieren PeftModel
base_model = autoModelForCausAllm.from_pretrained („meta-llama/llama-2-7b-HF“)
modell = PeftModel.from_preTrained (base_model,“. /lora-linker Prüfpunkt „)
modell.eval ()
Sie können diesen Code als Ausgangspunkt verwenden, um jedes unterstützte Transformatormodell mithilfe von LoRa zu optimieren. Geben Sie einfach Ihren bevorzugten Datensatz ein, optimieren Sie die LoRa-Konfiguration oder die Trainings-Hyperparameter und führen Sie das Skript unverändert aus. Es ist modular konzipiert, sodass Sie es bei Bedarf zur Auswertung, Protokollierung oder Bereitstellung erweitern können. Perfekt für schnelle Experimente oder leichte Feinabstimmungen in der Produktion.
Mit der zunehmenden Akzeptanz von LoRa nehmen seine realen Anwendungen in allen Branchen und Anwendungsfällen rasant zu. Von der Senkung der Infrastrukturkosten bis hin zur Personalisierung in großem Maßstab hat LoRa seinen Wert sowohl in Forschungs- als auch in Produktionsumgebungen bewiesen. Im Folgenden sind einige bemerkenswerte Szenarien aufgeführt, in denen LoRa messbare Auswirkungen erzielt hat.
Domänenspezifische Feinabstimmung in den Bereichen Gesundheitswesen und Rechtswesen
Organisationen, die mit sensiblen oder speziellen Daten arbeiten — wie z. B. Gesundheitsdienstleister oder Legal Tech-Startups — müssen häufig umfangreiche Sprachmodelle an ihre Domäne anpassen. Eine vollständige Feinabstimmung würde umfangreiche Berechnungen erfordern und Bedenken hinsichtlich des Datenschutzes aufwerfen. Mit LoRa können Teams vortrainierte Modelle anhand von domänenspezifischen Korpora (z. B. medizinische Terminologie oder Rechtsverträge) optimieren und gleichzeitig die Basisgewichte einfrieren. Das Ergebnis sind schlanke, aufgabenoptimierte Modelle, die sicher bleiben und intern einfach zu implementieren sind.
Multi-Task-Feinabstimmung im großen Maßstab
Große KI-Plattformen müssen oft mehrere nachgelagerte Aufgaben unterstützen, z. B. Zusammenfassung, Klassifizierung und Dialoggenerierung. Anstatt für jede Aufgabe separate Kopien des vollständigen Modells zu verwalten, ermöglicht LoRa ihnen, einfache Adapter für jeden Anwendungsfall zu trainieren und zu speichern. Diese Adapter können je nach Benutzeranforderungen dynamisch geladen werden, sodass personalisierte oder multifunktionale Modelle einfach von einer einzigen gemeinsamen Basis aus bereitgestellt werden können.
KI auf dem Gerät und am Edge
Umgebungen mit beschränkten Ressourcen wie Mobilgeräte, IoT-Gateways oder Edge-Inferenzplattformen profitieren erheblich von LoRa. Da nur wenige Millionen Parameter statt Milliarden trainiert werden, ermöglicht LoRa eine schnelle Anpassung, ohne den Speicher oder das Rechenbudget zu beanspruchen. Einige Teams haben LoRa verwendet, um Modelle wie Whisper oder DistilBert für Sprachassistenten oder Dokumentenscanner, die vollständig auf dem Gerät laufen, zu optimieren.
Community und Open-Source-Ökosystem
Open-Source-Projekte wie Alpaca, Dolly und Vicuna haben sich alle auf LoRa verlassen, um offene Basismodelle (z. B. LLama) für Anweisungen oder Dialogaufgaben zu optimieren. Dies zeigt, dass selbst einzelne Entwickler oder kleine Teams leistungsstarke Modelle erstellen können, ohne auf teure Hardware zugreifen zu müssen.
In diesen Anwendungsfällen hält LoRa sein Versprechen stets ein: kostengünstige Feinabstimmung ohne Leistungseinbußen — und mit der Flexibilität, domänen-, aufgaben- und umgebungsübergreifend zu skalieren.

Die wahre Leistung von LoRa geht weit über die Feinabstimmung von Leichtgewichten hinaus. Bei richtiger Skalierung ermöglicht es eine Reihe fortschrittlicher Konfigurationen, die sich ideal für den Einsatz in der Produktion, Systeme mit mehreren Domänen und Forschungsworkflows eignen. Im Folgenden finden Sie einige der wirkungsvollsten und technisch wichtigsten Möglichkeiten zur Erweiterung von LoRa in realen Systemen.
Zusammenführen von LoRa-Adaptern in das Basismodell
Standardmäßig bleiben LoRa-Adapter vom Basismodell getrennt und dienen als Restschichten, die während der Inferenz aufgetragen werden. In latenzempfindlichen Umgebungen oder für den Einsatz auf inferenzoptimierten Laufzeiten (z. B. vLLM, ONNX, TensorRT) ist es jedoch vorteilhaft, die LoRa-Gewichtungen mit niedrigem Rang nach dem Training mit den ursprünglichen Modellgewichten zusammenzuführen. Dadurch entfällt die Notwendigkeit einer Adapterlogik und die Komplexität der Inferenz wird reduziert, was Folgendes ermöglicht:
Der Zusammenführungsprozess erfolgt typischerweise über eine lineare Operation:
wMERGED=W+α⋅ A⋅ B
Selektive Modulanwendung
LoRa muss nicht auf alle Transformatorschichten aufgetragen werden. In vielen Fällen wird durch die Feinabstimmung nur bestimmter Teile der Architektur — wie etwa der Abfrage- (Q) und Werteprojektionsmatrizen (V) in den Aufmerksamkeitsebenen — eine vergleichbare Leistung mit weniger Parametern erzielt.
Fortgeschrittene Benutzer können Folgendes ins Visier nehmen:
Dieser Ansatz gibt Ihnen mehr Kontrolle über das Verhalten des Modells, ermöglicht die Budgetierung von Parametern und ermöglicht die Interpretierbarkeit auf Ebenenebene.
LoRa mit Quantisierung: QLora
QLora ist eine leistungsstarke Erweiterung, die LoRa mit 4-Bit- oder 8-Bit-Quantisierung kombiniert, sodass Modelle mit Milliarden von Parametern auf einer einzigen GPU fein abgestimmt werden können. Es funktioniert durch:
QLora ermöglicht die Feinabstimmung von Modellen wie dem LLama-65B auf handelsüblicher Hardware, ohne Abstriche bei der Genauigkeit machen zu müssen.
Inferenz und Routing mit mehreren Adaptern
In Produktionsszenarien mit Multitask- oder Multi-Tenant-Anforderungen ermöglicht LoRa die Erstellung mehrerer Adapter, die jeweils für einen anderen Anwendungsfall oder Kunden optimiert sind. Diese können sein:
Auf diese Weise kann ein einziges Basismodell viele Domänen bedienen und gleichzeitig die Speicherauslastung niedrig und die Latenz überschaubar halten. Die Adapterauswahllogik kann in externe Orchestrierungsebenen oder Prompt-Parser integriert werden.
Modularer Agent und RAG-Komponenten
In komplexeren Systemen wie Retrieval-Augmented Generation (RAG) oder Multi-Agent-Architekturen können verschiedene Submodule das Abrufen von Dokumenten, die Werkzeugauswahl, die Zusammenfassung oder den Dialog durchführen. LoRa ermöglicht eine Feinabstimmung auf Komponentenebene, bei der jedes Submodell unabhängig mit einem eigenen Adapter trainiert werden kann.
Dies ist besonders wirksam in Szenarien, in denen:
LoRa gewährleistet Isolierung, Wartbarkeit und Anpassungsfähigkeit innerhalb solcher modularer Systeme.
LoRa bietet zwar erhebliche Vorteile in Bezug auf Effizienz und Modularität, ist aber nicht ohne Herausforderungen. Das Verständnis dieser Einschränkungen ist entscheidend, wenn es darum geht, robuste Workflows zur Feinabstimmung zu entwickeln oder LoRa über mehrere Anwendungsfälle hinweg zu skalieren.
Eingeschränkte Kapazität für extreme Anpassung
Da LoRa nur eine kleine Teilmenge von Parametern aktualisiert (über Matrizen mit niedrigem Rang), kann es Probleme geben, wenn die Aufgabe erhebliche Änderungen im Modellverhalten erfordert. Bei Aufgaben, bei denen das Denken in sehr anderen Bereichen als bei der vorab trainierten Verteilung erforderlich ist, sind möglicherweise immer noch eine vollständige Feinabstimmung oder zusätzliche Ebenen erforderlich.
Kompromisse bei der Adapterkonfiguration
Die Auswahl der richtigen LoRa-Konfiguration — wie Rang (r), Alpha-Skalierungsfaktor und Zielmodule — erfordert Experimente. Ein zu niedriger Rang passt möglicherweise nicht, während ein zu hoher Rang zu einer Überanpassung führen oder die Parametereinsparungen verringern kann. Darüber hinaus kann die Ausrichtung auf die falschen Module (z. B. die wahllose Verwendung von LoRa auf allen Ebenen) zu unnötiger Komplexität und Kosten führen, ohne dass die Leistung steigt.
Kompatibilität mit Quantisierung und Serving
Tools wie QLora unterstützen zwar eine quantisierte Feinabstimmung, aber nicht alle Inferenzplattformen verarbeiten LoRa-Adapter oder zusammengeführte Gewichte ordnungsgemäß. Einige Serverframeworks (insbesondere Edge- oder Low-Level-C++-Runtimes) erfordern möglicherweise das Zusammenführen von Adaptern oder den erneuten Export in ein kompatibles Format, wodurch der Bereitstellungspipeline weitere Schritte hinzugefügt werden.
Debugging und Evaluierung
Das Debuggen von LORA-optimierten Modellen kann komplexer sein als erwartet. Da das Basismodell eingefroren ist, kann es schwierig sein zu interpretieren, ob Fehler auf ein unzureichendes Training der LoRa-Module oder auf inhärente Einschränkungen des eingefrorenen Backbones zurückzuführen sind. Eine korrekte Bewertung mehrerer Aufgaben und Datensätze ist wichtig, um zu verstehen, wann LoRa das richtige Tool für diese Aufgabe ist.
Trotz dieser Herausforderungen bleibt LoRa ein hocheffektiver und flexibler Ansatz, wenn er mit Bedacht eingesetzt wird — insbesondere in Umgebungen, in denen Effizienz, Skalierbarkeit und Modularität oberste Priorität haben.
LoRa hat die Art und Weise, wie wir große Sprachmodelle optimieren, neu definiert. Dadurch ist es möglich, leistungsstarke Modelle effizient anzupassen, ohne dass umfangreiche Berechnungen oder eine vollständige Neuschulung erforderlich sind. Der Low-Rank-Ansatz verleiht modernen ML-Workflows Modularität, Skalierbarkeit und Wirtschaftlichkeit. In diesem Leitfaden haben wir die Grundlagen von LoRa, reale Anwendungsfälle, fortgeschrittene Techniken und die praktische Implementierung mit dem PEFT von Hugging Face untersucht. Da LLMs immer größer und beliebter werden, bietet LoRa einen praktischen Weg zur Personalisierung und Leistung. Für Teams, die intelligent skalieren möchten, ist LoRa mehr als nur effizient — es ist ein strategischer Vorteil beim Aufbau anpassungsfähiger KI-Systeme.
Die LoRa-Feinabstimmung ist eine effiziente Methode zur Anpassung großer vortrainierter Modelle, ohne dass alle Parameter aktualisiert werden müssen. Es friert die Gewichte des Basismodells ein und trainiert nur kleine, leichte Adaptermodule. Diese Technik reduziert die Rechenressourcen und den Arbeitsspeicher erheblich, wodurch die Modellanpassung schneller, kostengünstiger und für bestimmte Aufgaben und Bereitstellungen leichter zugänglich ist.
Die LoRa-Feinabstimmung reduziert die erforderlichen Daten im Vergleich zur vollständigen Modellfeinabstimmung erheblich. Es gibt zwar keine feste Menge, aber LoRa nutzt eine vorab trainierte Datenbasis, sodass Sie mit kleineren, aufgabenspezifischen Datensätzen starke Ergebnisse erzielen können. Dadurch wird die Anpassung großer Modelle effizienter und für spezielle Anwendungsfälle zugänglicher, wodurch die Ressourcennutzung optimiert wird.
Der Hauptvorteil der LoRa-Feinabstimmung ist ihre bemerkenswerte Effizienz. Es reduziert die trainierbaren Parameter drastisch, wodurch der Prozess schneller, kostengünstiger und weniger speicherintensiv wird. Dies ermöglicht die Anpassung großer Sprachmodelle an verschiedene Aufgaben mit minimalen Rechenressourcen und gewährleistet so zugängliche und leistungsstarke KI-Lösungen für US-Unternehmen.
Die LoRa-Feinabstimmung friert die großen Gewichte des Originalmodells ein und fügt kleine, trainierbare Adaptermatrizen in bestimmte Schichten ein. Nur diese leichten Adapterparameter werden während des Trainings aktualisiert, nicht das gesamte Modell. Dieser Prozess macht die LoRa-Feinabstimmung erheblich effizienter, reduziert die Rechenressourcen und beschleunigt die Modellanpassung für US-Teams.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)



.webp)
.webp)


.webp)
.webp)
.webp)
.png)




