




July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Bereitstellung von Open-Source-Modellen für große Sprachen (LLMs) in großem Maßstab bei gleichzeitiger Gewährleistung von Zuverlässigkeit, niedriger Latenz und Kosteneffektivität kann eine Herausforderung sein. Auf der Grundlage unserer umfassenden Erfahrung beim Aufbau einer LLM-Infrastruktur und deren erfolgreicher Bereitstellung für unsere Kunden habe ich eine Liste der wichtigsten Herausforderungen zusammengestellt, mit denen Einzelpersonen in diesem Prozess häufig konfrontiert sind.
Es gibt mehrere Optionen für Modellserver, um LLM zu hosten, und es gibt verschiedene Konfigurationsparameter, die angepasst werden müssen, um die beste Leistung für Ihren Anwendungsfall zu erzielen. TGI, VLLM, LLM öffnen sind einige der gängigsten Frameworks für das Hosten dieser LLMs. Eine ausführliche Analyse finden Sie hier Blog. Um das richtige Framework für Ihr Hosting auszuwählen, ist es wichtig, die Leistung dieser Frameworks für Ihren Anwendungsfall zu vergleichen und dasjenige auszuwählen, das am besten zu Ihrem Anwendungsfall passt. Außerdem haben diese Frameworks ihre einzigen einstellbaren Parameter, mit denen Sie die besten Benchmarking-Ergebnisse erzielen können.
GPUs sind teuer und schwer zu finden. Es gibt verschiedene GPU-Cloud-Anbieter, die von bekannten Clouds wie AWS, GCP und Azure bis hin zu kleinen Cloud-Anbietern wie Runpod, Fluidstack, Paperspace und Coreweave reichen. Die Preise und Angebote jedes dieser Anbieter sind sehr unterschiedlich. Die Zuverlässigkeit ist auch bei einigen der neueren GPU-Cloud-Anbieter nach wie vor ein Problem.
Das ist in der Praxis schwieriger als es klingt. Aufgrund unserer Erfahrung mit der Ausführung von LLMs in der Produktion sollten Sie auf seltsame, einmalige Fehler in Modellservern vorbereitet sein, die dazu führen können, dass Ihr Prozess hängen bleibt und alle Anfragen zu einem Timeout führen. Es ist sehr wichtig, dass geeignete Prozessmanager und Bereitschafts-/Verfügbarkeitstests eingerichtet sind, damit sich die Modellserver nach Ausfällen erholen können oder der Datenverkehr nahtlos von einer fehlerhaften zu einer intakten Instanz übergehen kann.
Beim Benchmarking ist es sehr wichtig, den Kompromiss zwischen Latenz und Durchsatz herauszufinden. Wenn wir die Anzahl der gleichzeitigen Anfragen an das Modell erhöhen, steigt die Latenz bis zu einem bestimmten Punkt leicht an. Danach verschlechtert sich die Latenz drastisch. Das richtige Gleichgewicht zwischen Latenz, Durchsatz und Kosten zu finden, kann zeitaufwändig und fehleranfällig sein. Wir haben einige Blogs, in denen solche Benchmarks für skizziert werden Lama 7B und Lama 13B.
LLM-Modelle sind riesig groß und reichen von 10s bis 100GB. Es kann viel Zeit in Anspruch nehmen, das Modell herunterzuladen, sobald der Modellserver bereit ist, und es dann von der Festplatte in den Speicher zu laden. Es ist wichtig, dass Sie das Modell auf der Festplatte zwischenspeichern, damit wir das Modell nicht erneut herunterladen, falls der Prozess neu gestartet wird. Um Netzwerkkosten zu sparen, ist es außerdem besser, das Modell einmal herunterzuladen und die Festplatte auf mehrere Replikate aufzuteilen, anstatt dass jedes Replikat das Modell wiederholt über das Internet herunterlädt.
Autoscaling ist bei LLM-Hosting aufgrund der hohen Startzeit eines anderen Replikats schwierig. Wenn die Auslastung sehr hoch ist, müssen wir die Infrastruktur in der Regel entsprechend der Spitzenreplikate bereitstellen. Wenn der Spitzenwert jedoch zu bestimmten Tageszeiten erwartet wird, funktioniert zeitbasiertes Autoscaling gut.
Wir haben mit dem oben genannten Ansatz begonnen, sind aber bald auf die unten stehende Architektur migriert, die es uns ermöglicht, LLMs mit sehr niedrigen Kosten und hoher Zuverlässigkeit zu hosten.
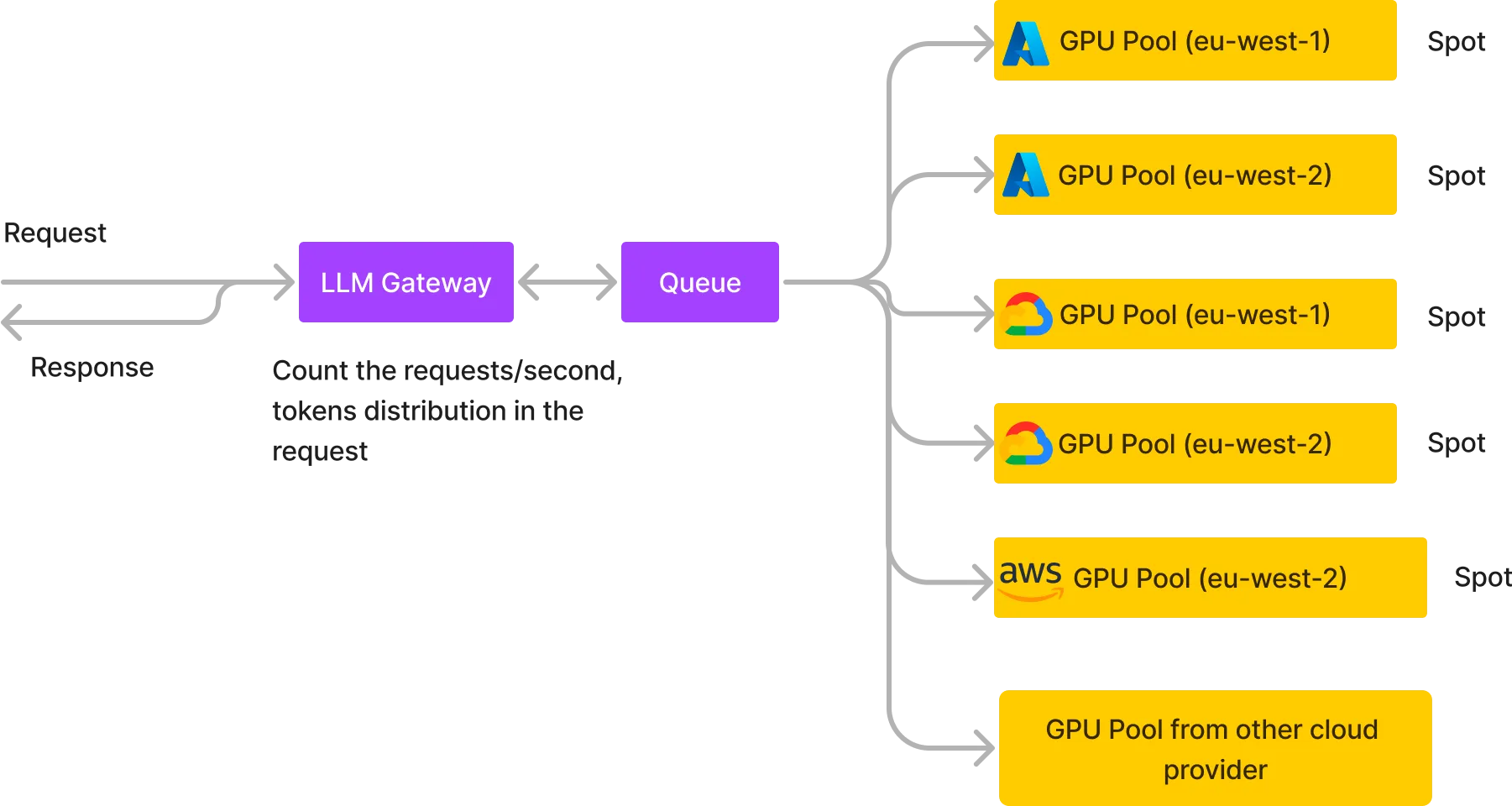
Wir erstellen grundsätzlich mehrere GPU-Pools bei verschiedenen Cloud-Anbietern in verschiedenen Regionen und verwenden in der Regel Spot-Instances, wenn es sich um AWS-, GCP- oder Azure-Instanzen handelt, oder um On-Demand-Knoten kleinerer Cloud-Anbieter. Wir platzieren auch eine Warteschlange in der Mitte, die alle Anfragen aufnimmt und die verschiedenen GPU-Pools aus der Warteschlange verarbeiten, und die Antwort an die Warteschlange zurückgibt, von der aus die HTTP-Antwort an den Benutzer zurückgegeben wird. Ein paar Vorteile dieser Architektur:
Nehmen wir ein Szenario an, in dem ein LLM mit 10 Anfragen pro Sekunde zu Spitzenzeiten und durchschnittlich 7 Anfragen pro Sekunde gehostet wird. Nehmen wir an, wir finden mithilfe von Benchmarking heraus, dass eine A100-GB-GPU-Maschine 0,5 Umdrehungen pro Sekunde erreichen kann. Denken wir auch daran, dass der Traffic 12 Stunden am Tag länger ist (etwa 9-10 RPS) und in den restlichen 12 Stunden am Tag gering ist (7-8 RPS).
Basierend auf den obigen Daten können wir die Anzahl der GPU-Maschinen ermitteln, die im 12-Stunden-Spitzenfenster und außerhalb des 12-Stunden-Zeitfensters benötigt werden:
12-Stunden-Spitzenfenster: 20 GPU
12-Stunden-Fenster außerhalb der Spitzenzeiten: 15 GPU
Wir werden die Kosten für den Betrieb des LLM mit Sagemaker vergleichen, naives Hosten auf On-Demand-Maschinen in AWS, GCP und Azure und die Verwendung unserer eigenen Architektur mit Autoscaling.
Kosten für das Hosting auf Sagemaker (Region US-East-1):
Kosten für 8 A100 80-GB-Maschinen (ml.p4de.24xlarge) -> 47,11$ pro Stunde
Wir benötigen 2 Maschinen außerhalb der Hauptverkehrszeiten und 3 Maschinen in den Hauptverkehrszeiten.
Monatliche Gesamtkosten: 85.000 USD
Kosten für das direkte Hosting auf AWS-Knoten:
Kosten für 8 A100 80-GB-Maschinen (p4de.24xlarge) -> 40.966$ pro Stunde
Wir benötigen 2 Maschinen außerhalb der Spitzenzeiten und 3 Maschinen in den Spitzenzeiten:
Monatliche Gesamtkosten: 73.000 USD
Kosten für das Hosting auf Truefoundry
Mithilfe der Spot-Instances und anderer GPU-Anbieter sind wir in der Lage, den durchschnittlichen GPU-Preis auf 2,5$ pro Stunde zu senken. Gehen wir davon aus, dass 15 GPU außerhalb der Spitzenzeiten und 20 GPU zu Spitzenzeiten verwendet werden, belaufen sich die Gesamtkosten auf:
2,5$ * (15*12 + 20*12) * 30 (Tage pro Monat) = 31.000$
Wie wir sehen können, können wir dasselbe LLM zu fast 30% des Preises des Sagemakers mit hoher Zuverlässigkeit hosten. Es werden jedoch Anstrengungen erforderlich sein, um diese Architektur aufzubauen und zu verwalten. Wahre Gießerei kann Ihnen helfen, es für Sie zu hosten oder es problemlos auf Ihrem eigenen Cloud-Konto zu hosten und gleichzeitig Kosten zu sparen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




