




October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
OpenAI und Langchain haben es wirklich einfach gemacht, eine Demo für die Beantwortung von Fragen zu Ihren Dokumenten zu erstellen. Es gibt viele Artikel im Internet, in dem beschrieben wird, wie das geht. Wir haben auch ein funktionierendes Notebook für den Fall, dass Sie mit einem System von Anfang bis Ende spielen möchten:
In diesem Artikel werden wir darüber sprechen, wie Sie einen Bot zur Beantwortung von Fragen in Ihren Dokumenten produzieren können. Wir werden es auch in Ihrer Cloud-Umgebung bereitstellen und auch die Verwendung von Open-Source-LLMs anstelle von OpenAI ermöglichen, wenn Datenschutz und Sicherheit eine der Kernanforderungen sind.
Der wichtigste Arbeitsablauf für den Aufbau des QA-Systems mit RAG (Generierung durch Abruf) lautet wie folgt:
Ablauf der Indizierung von Dokumenten:
Die Antwort auf eine Benutzeranfrage erhalten:
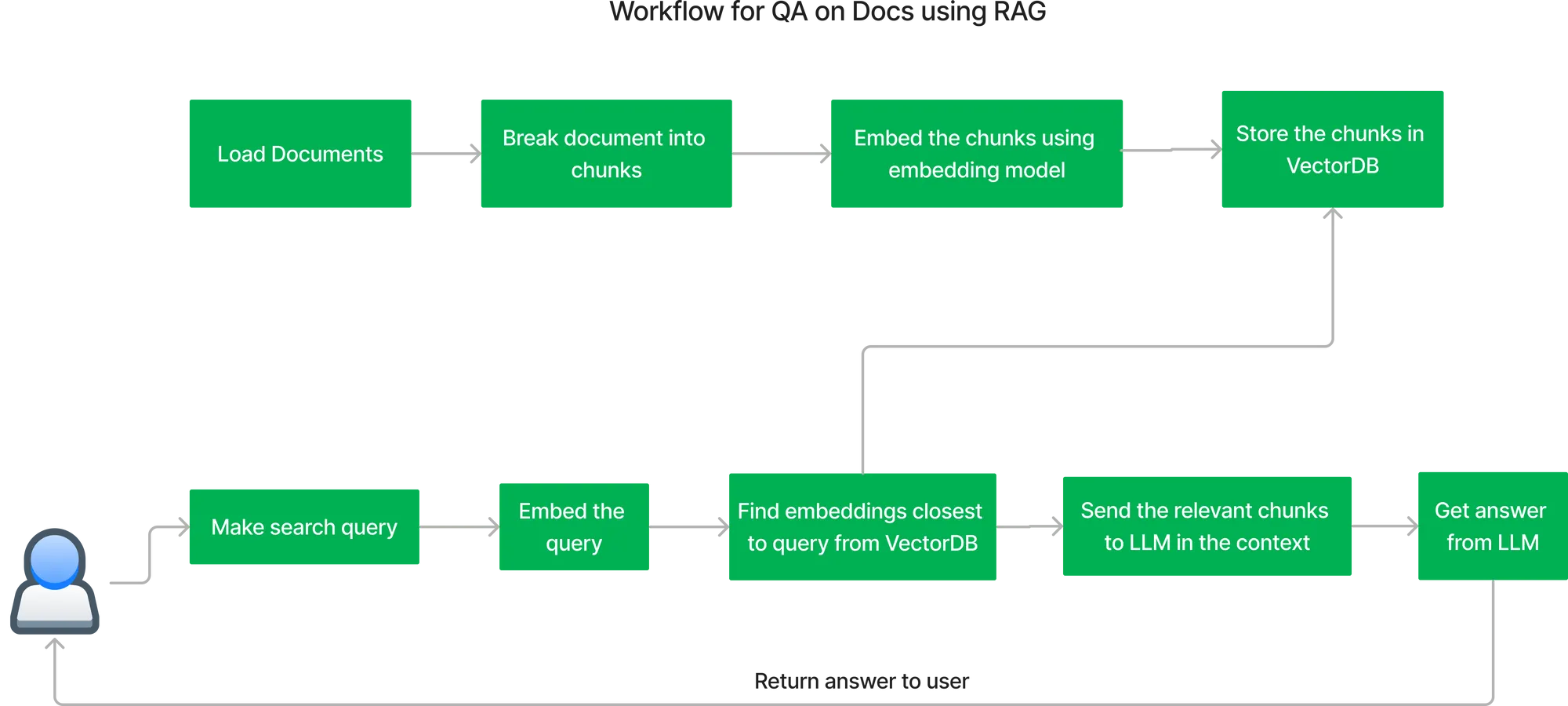
Um den gesamten oben beschriebenen Ablauf bereitzustellen, müssen wir eine Reihe von Komponenten zusammen bereitstellen. Hier ist das Architekturdiagramm für die Bereitstellung von RAG in Ihrer eigenen Cloud.
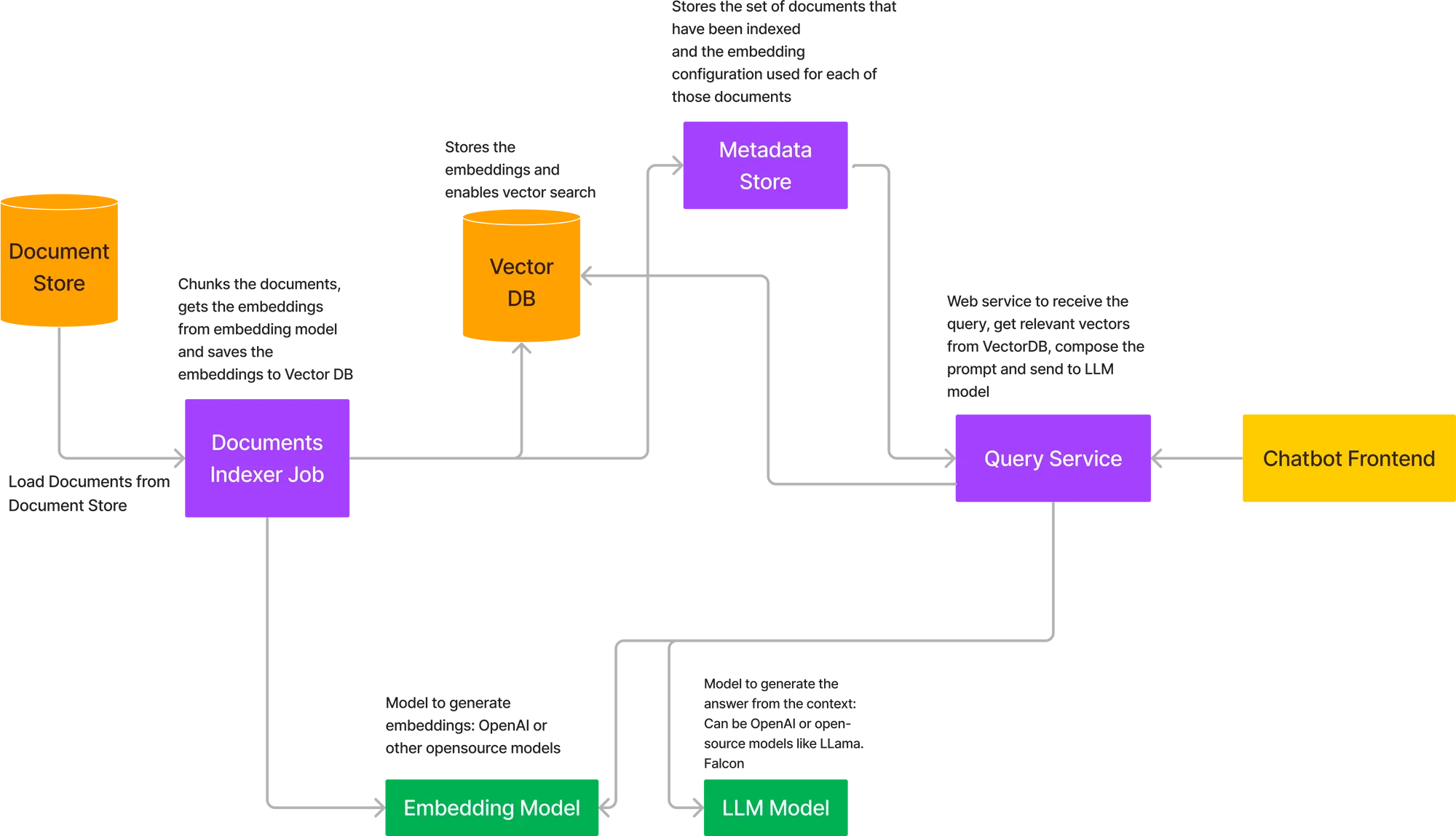
Die Hauptkomponenten der obigen Architektur sind:
Hier werden die Dokumente gespeichert. In vielen Fällen handelt es sich dabei um AWS S3, Google Storage Buckets oder Azure Blob Storage. In einigen Fällen können diese Daten auch von APIs stammen, wenn wir es mit etwas wie Confluence-Dokumenten zu tun haben.
Dies wird ähnlich einem Trainingsjob in ML modelliert, der die Dokumente als Eingabe erhält, sie in Chunks aufteilt, das Einbettungsmodell aufruft, um die Chunks einzubetten, und die Vektoren in der Datenbank speichert. Das Einbettungsmodell kann in den Job selbst geladen oder als API aufgerufen werden. Die API-Route wird bevorzugt, da das Einbettungsmodell dann unabhängig skaliert werden kann, falls eine große Anzahl von Dokumenten vorhanden ist. Die Jobs können ad hoc oder nach einem Zeitplan ausgelöst werden, wenn ein Dokumentenstrom eingeht. Sobald der Job abgeschlossen ist, sollte der Job zusammen mit den Einbettungseinstellungen auch den Status Erfolgreich in einem Metadatenspeicher speichern.
Wenn wir OpenAI oder ein extern gehostetes Modell verwenden, müssen wir in diesem Fall kein Modell hosten. Wenn wir jedoch ein Open-Source-Modell verwenden, müssen wir es in unserer Cloud-Umgebung hosten und dann die Einbettungen mithilfe der API abrufen.
Wenn wir OpenAI oder gehostete Modell-APIs wie Cohere und Anthropic verwenden, müssen wir nichts bereitstellen, sonst müssen wir Open-Source-LLMs bereitstellen.
Dies kann ein FastAPI-Dienst sein, der die API zum Auflisten aller indizierten Dokumentsammlungen bereitstellt und es dem Benutzer ermöglicht, die Dokumentsammlungen abzufragen. Es wird auch eine API geben, um einen neuen Indexierungsauftrag für eine neue Dokumentensammlung auszulösen.
Wir können hier eine gehostete Lösung wie PineCone verwenden oder eine der Open-Source-VectorDB wie Qdrant oder Milvus hosten.
Dies wird benötigt, um die Links zu den Dokumenten zu speichern, die indexiert wurden, und um die Konfiguration zu speichern, die verwendet wurde, um die Chunks in diese Dokumente einzubetten. Dies hilft dem Benutzer bei der Auswahl der Dokumente, die abgefragt werden sollen, und kann mehrere Dokumentsätze in einer Organisation unterstützen.
Echte Gießerei ist eine Plattform auf Kubernetes, die es wirklich einfach macht, ML-Schulungsjobs und -dienste zu den optimalsten Kosten bereitzustellen. Mit Truefoundry können wir alle Komponenten der oben genannten Architektur bereitstellen — auf Ihrem eigenen Cloud-Konto. Die endgültige Bereitstellung in Ihrer Cloud sieht ungefähr so aus:
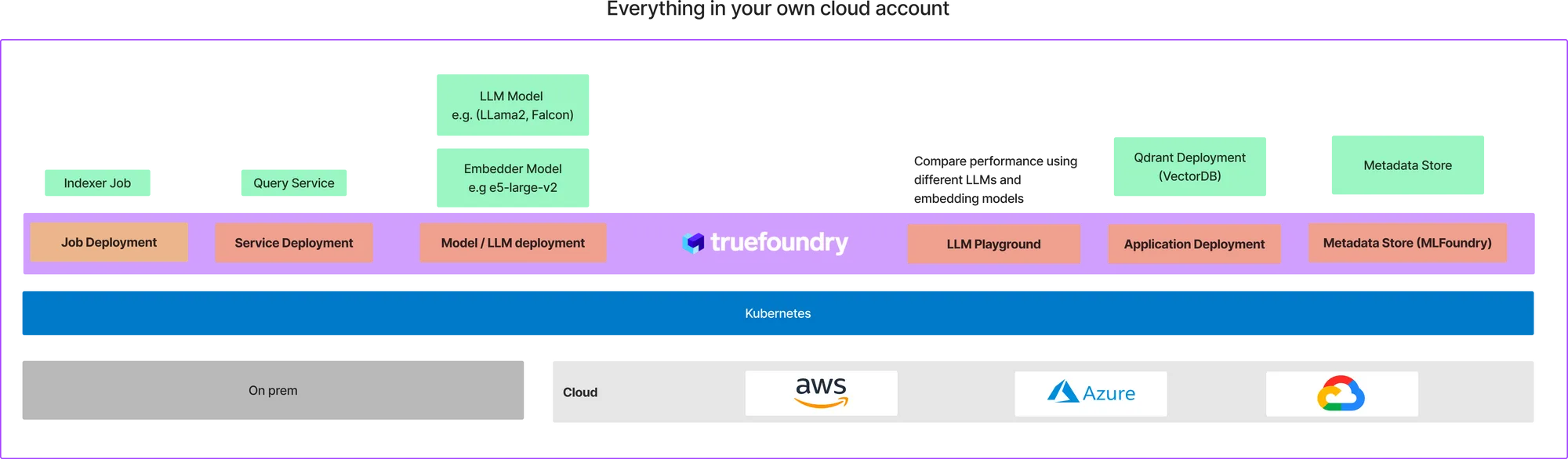
Das mag nach einer Menge Einrichtung erscheinen, wir haben bereits eine Vorlage erstellt, mit der Sie in weniger als 10 Minuten damit beginnen können. Wir gehen davon aus, dass Sie bereits bei TrueFoundry angemeldet sind. Wenn Sie noch nicht Mitglied sind, gehen Sie wie folgt vor Leitfaden um an Bord zu kommen. TrueFoundry funktioniert auf allen drei großen Cloud-Anbietern: AWS, Azure und GCP. Sie sollten es also bei jedem dieser Cloud-Anbieter einrichten können.
In diesem Github-Repo haben wir für Sie einen Beispiel-QA-Bot mit dem Code für Indexer-Job, Abfragedienst und Chat-Frontend mit Streamlit erstellt:
Sie können dies innerhalb von 15 Minuten auf TrueFoundry in Ihrer eigenen Cloud bereitstellen. Dies ermöglicht eine Einrichtung auf Produktionsebene und bietet Ihnen außerdem die vollständige Flexibilität, den Code gemäß Ihren eigenen Anwendungsfällen zu ändern.
Wir werden die gesamte Architektur auf einem Kubernetes-Cluster bereitstellen. Den gesamten Code und die Anweisungen zur Bereitstellung finden Sie unter dieses Github-Repo.
TrueFoundry bietet eine einfach zu bedienende Abstraktion über Kubernetes, um verschiedene Arten von Anwendungen auf Kubernetes bereitzustellen. Wir werden die verschiedenen Schritte zur Bereitstellung von RAG in Ihrer Cloud durchgehen.
Truefoundry enthält einen Metadatenspeicher in Form von ML-Repos. Sie können Artefakte, Metadaten speichern und mlfoundry-Pip-Bibliothek bietet Methoden zum Hoch- und Herunterladen der Artefakte. Jedes ML-Repo wird durch den Cloud-Blob-Speicher (AWS S3, GCS oder Azure Blob Storage) unterstützt. Wir beginnen zunächst mit der Erstellung eines ML-Repos und laden dann unsere Dokumente als Artefakt in den Index hoch. Um ein ML-Repo zu erstellen, folgen Sie der Anleitung hier: https://docs.truefoundry.com/docs/creating-ml-repo-via-ui
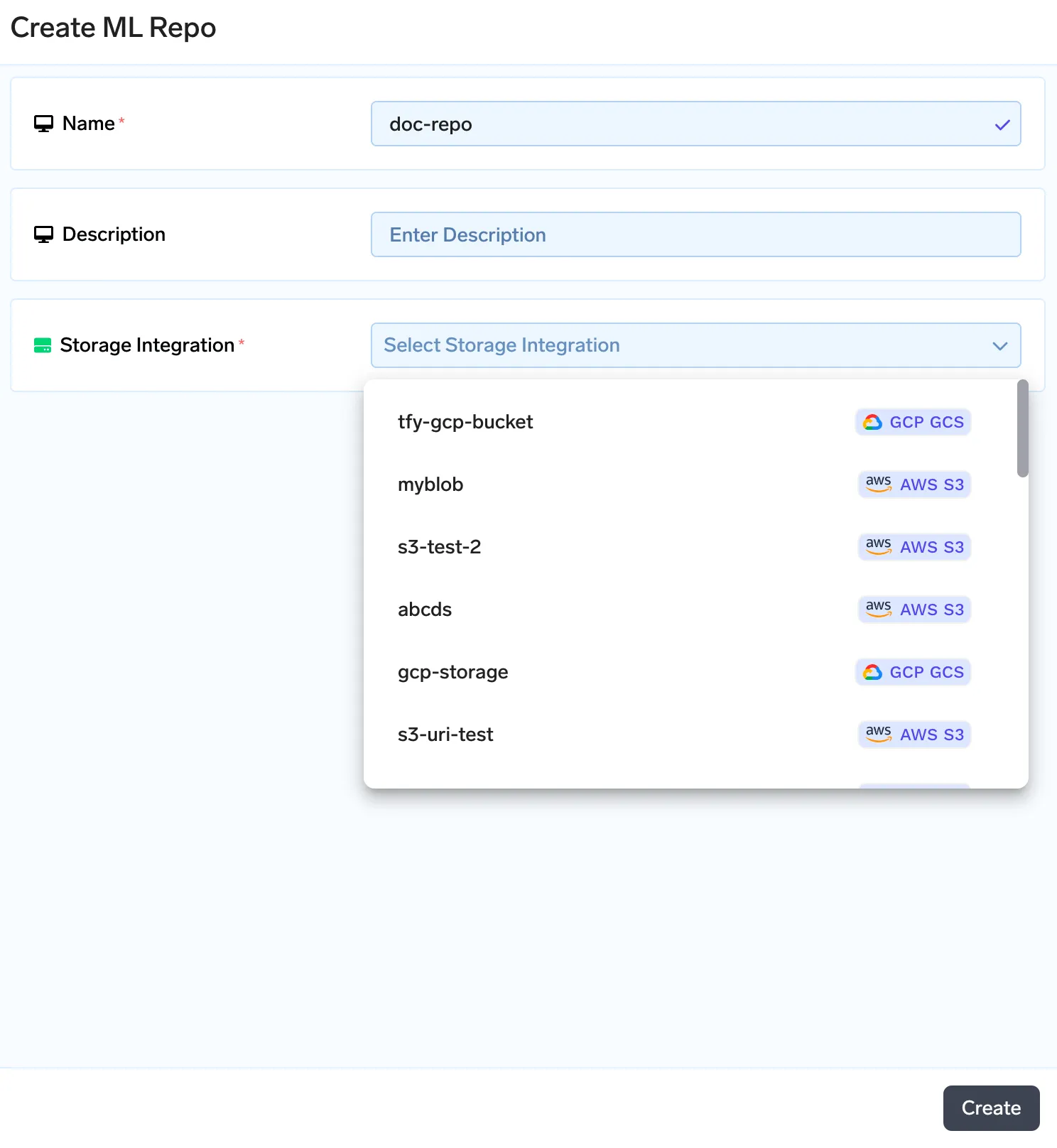
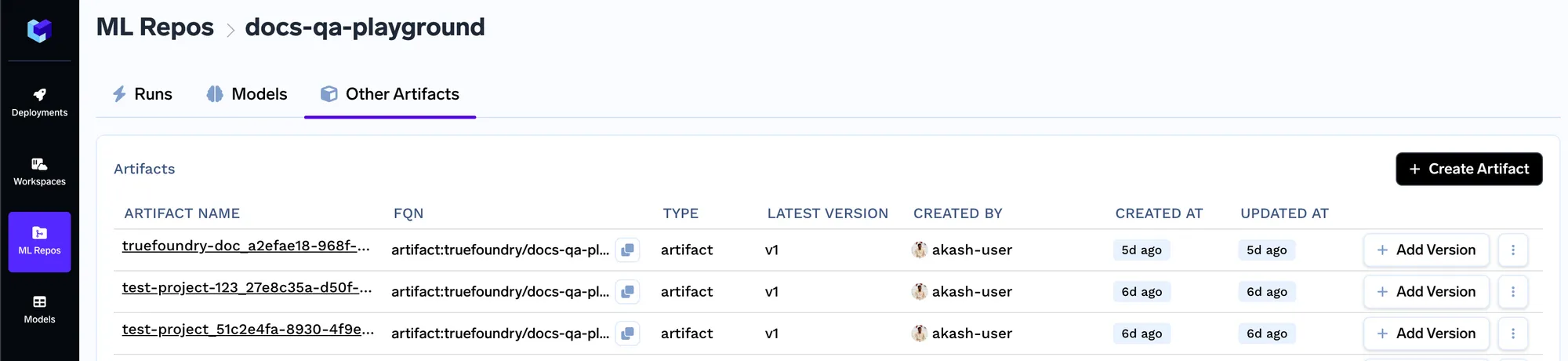
Sobald wir ein Artefakt erstellt haben, erstellen wir eine neue Artefaktversion. Auf diese Weise können Sie jedes Mal, wenn sich der Dokumentensatz ändert, den neuen Dokumentensatz als neue Version hochladen. Sie können Ihre Dokumente auf dem Bildschirm unten hochladen.
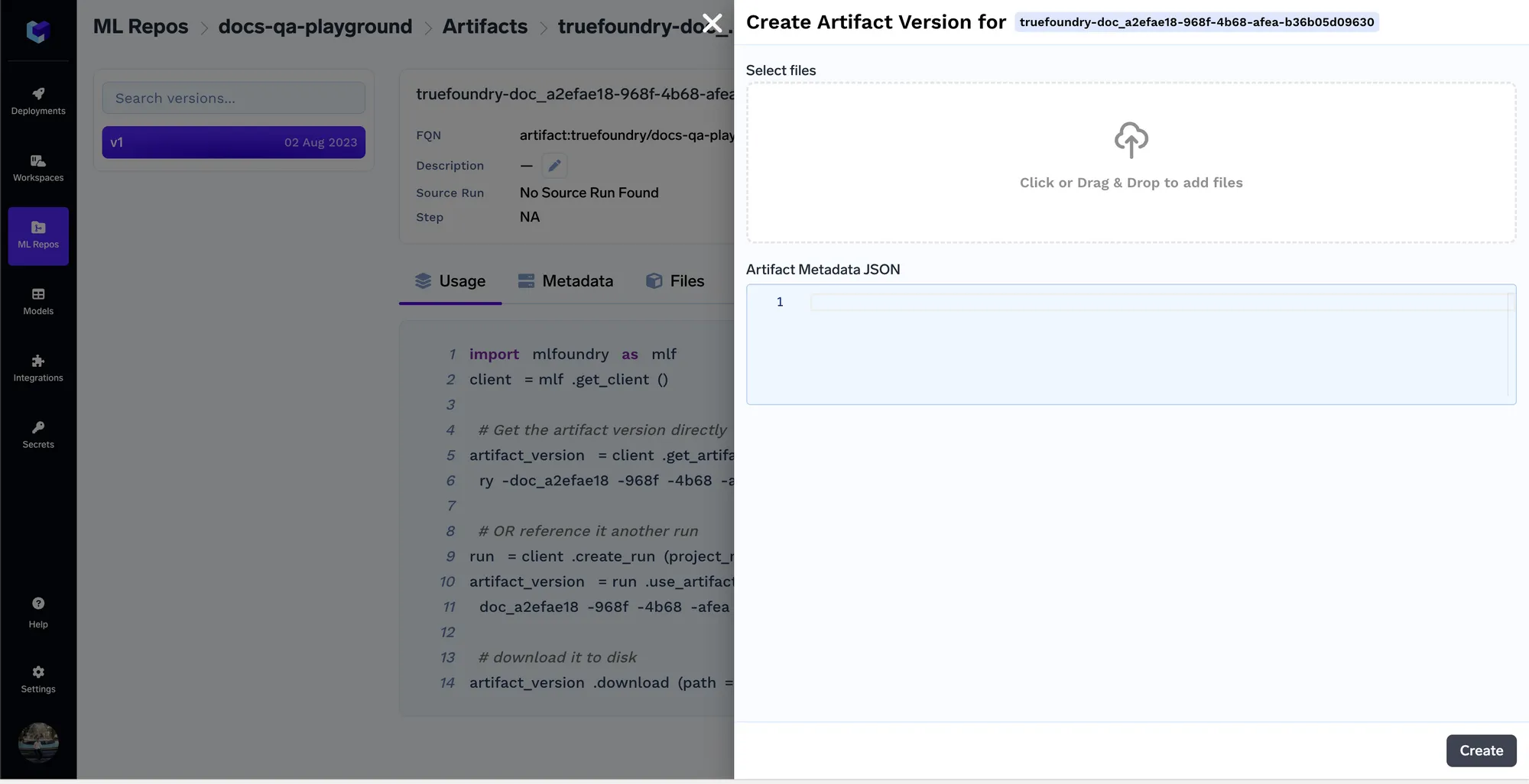
Sobald die Dokumente hochgeladen sind, erhalten wir die Artefaktversion fqn, mit der wir das Artefakt dann überall im Code referenzieren/herunterladen können.
Wir benötigen das Einbettungsmodell, um die Chunks einzubetten. Sie können diesen Schritt überspringen, wenn Sie OpenAI Embeddings verwenden. Sie können jedes der Einbettungsmodelle aus dem Modellkatalog bereitstellen. Im Allgemeinen haben wir festgestellt, dass e5-large-v2 recht gut funktioniert.
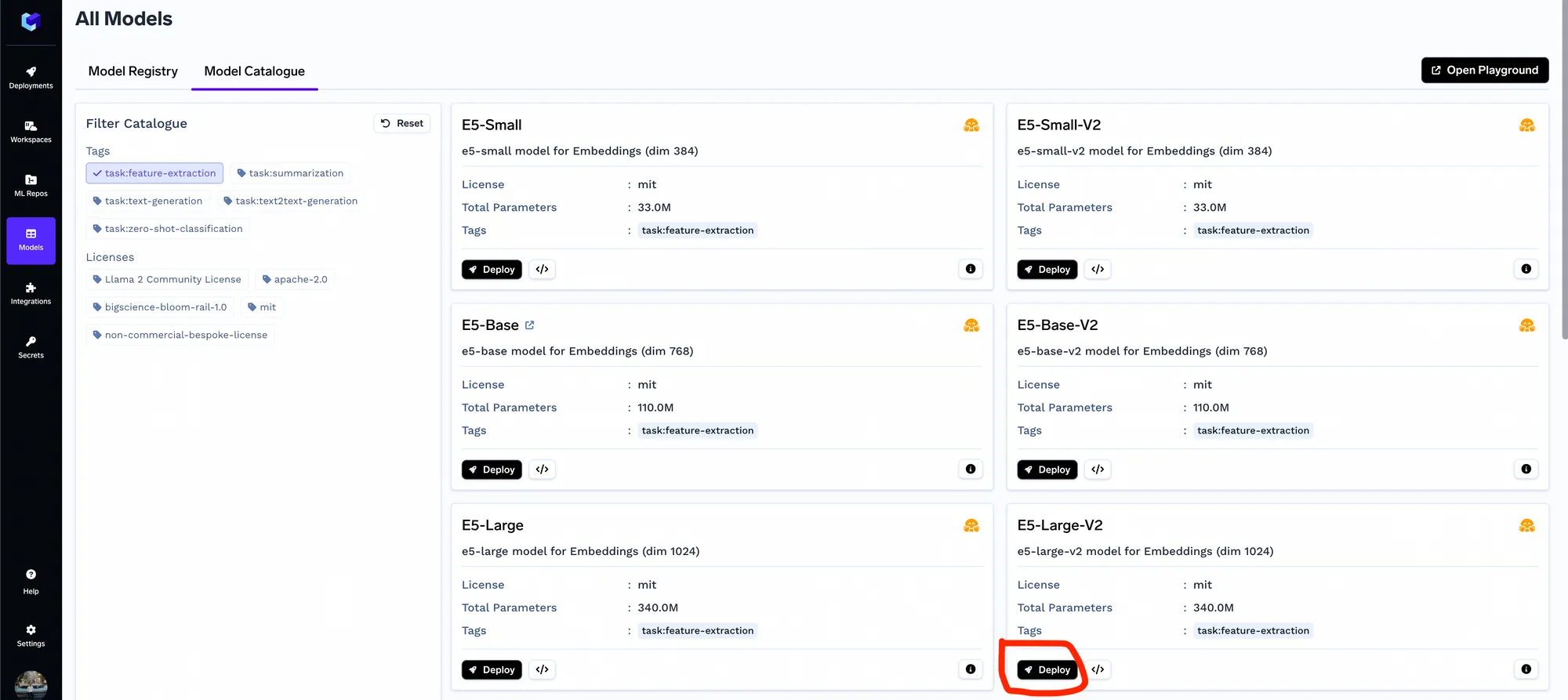
Sobald das Einbettungsmodell bereitgestellt ist, können Sie die APIs mithilfe des OpenAPI-Playgrounds im Truefoundry-Dashboard überprüfen.
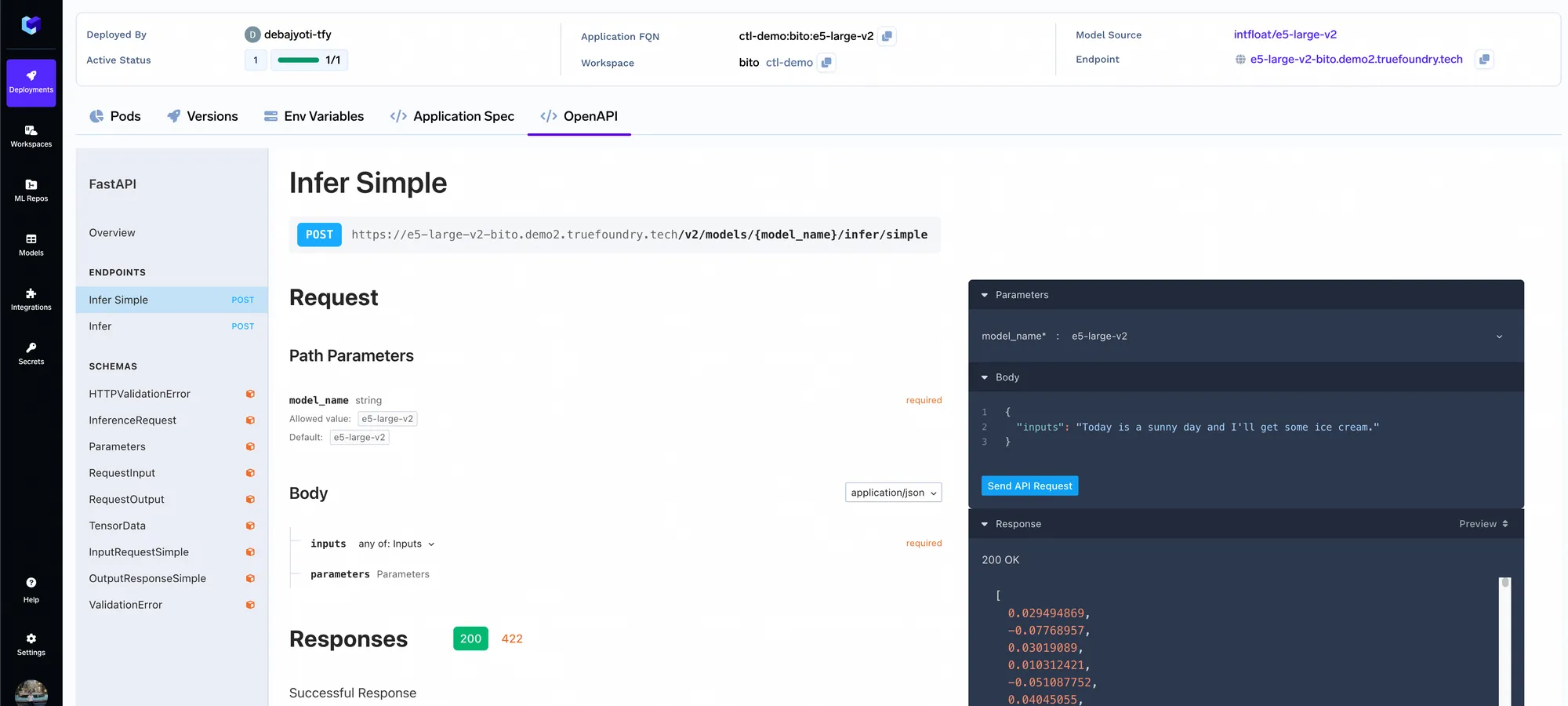
Wir werden die Qdrant VectorDB bereitstellen.
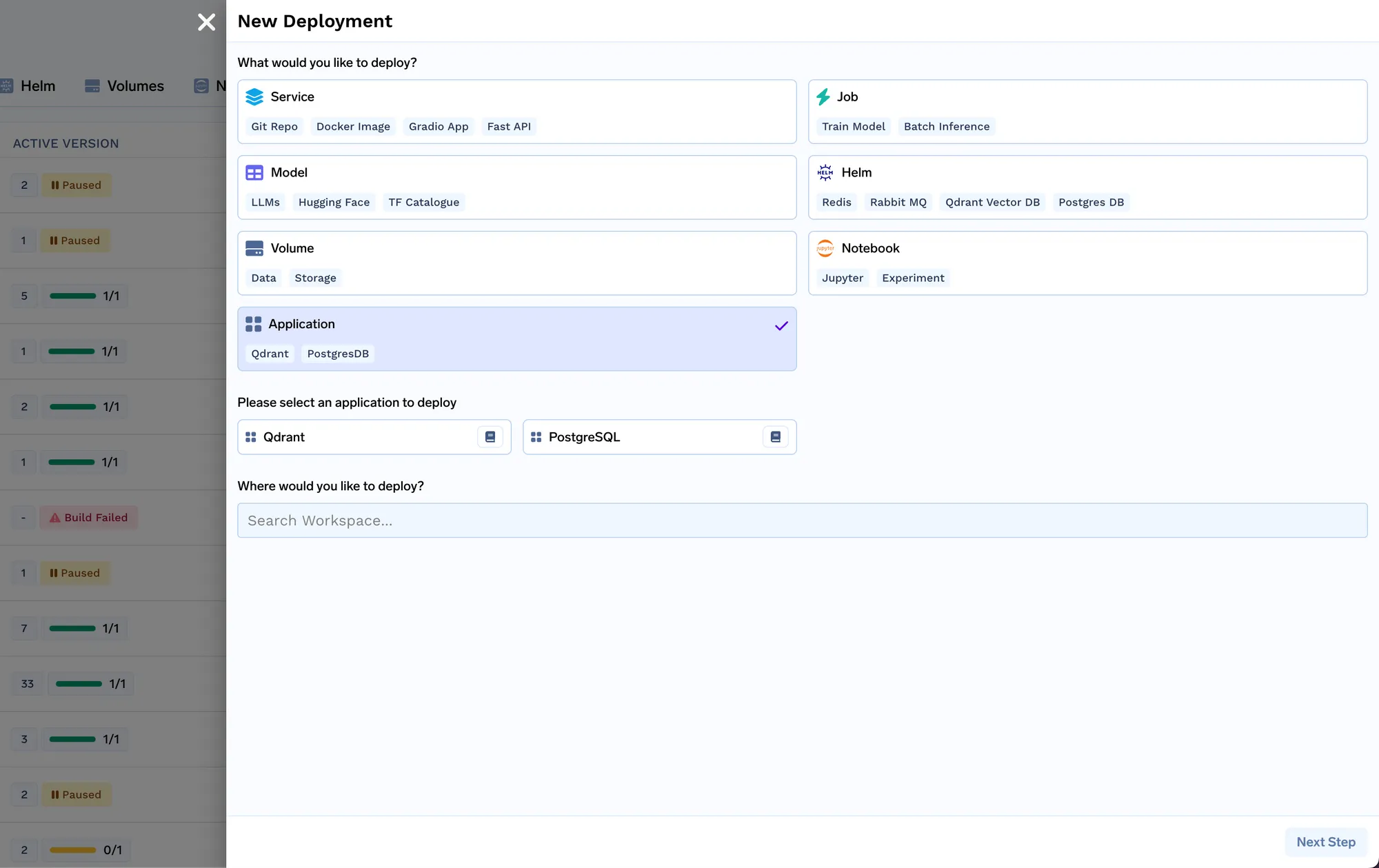
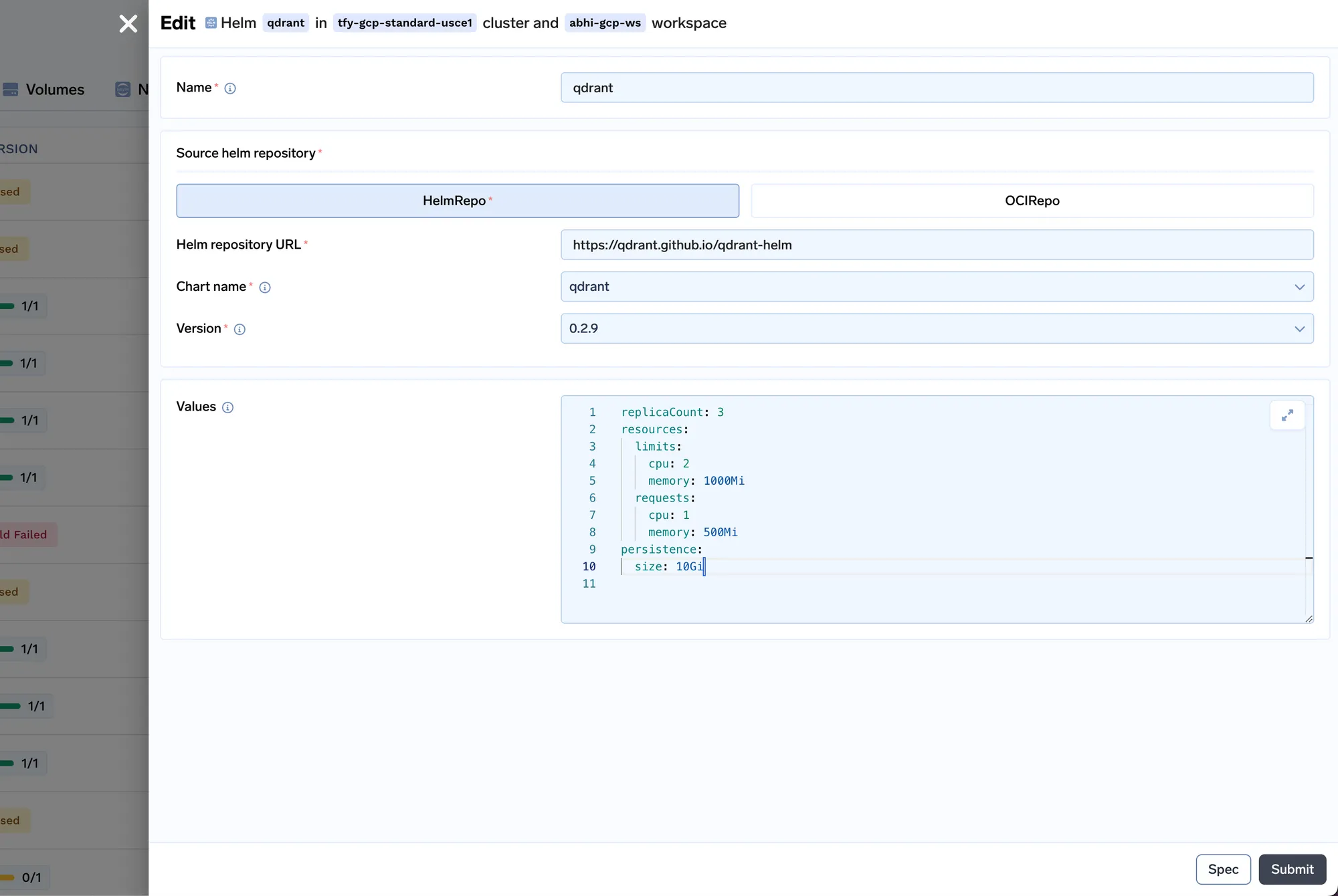
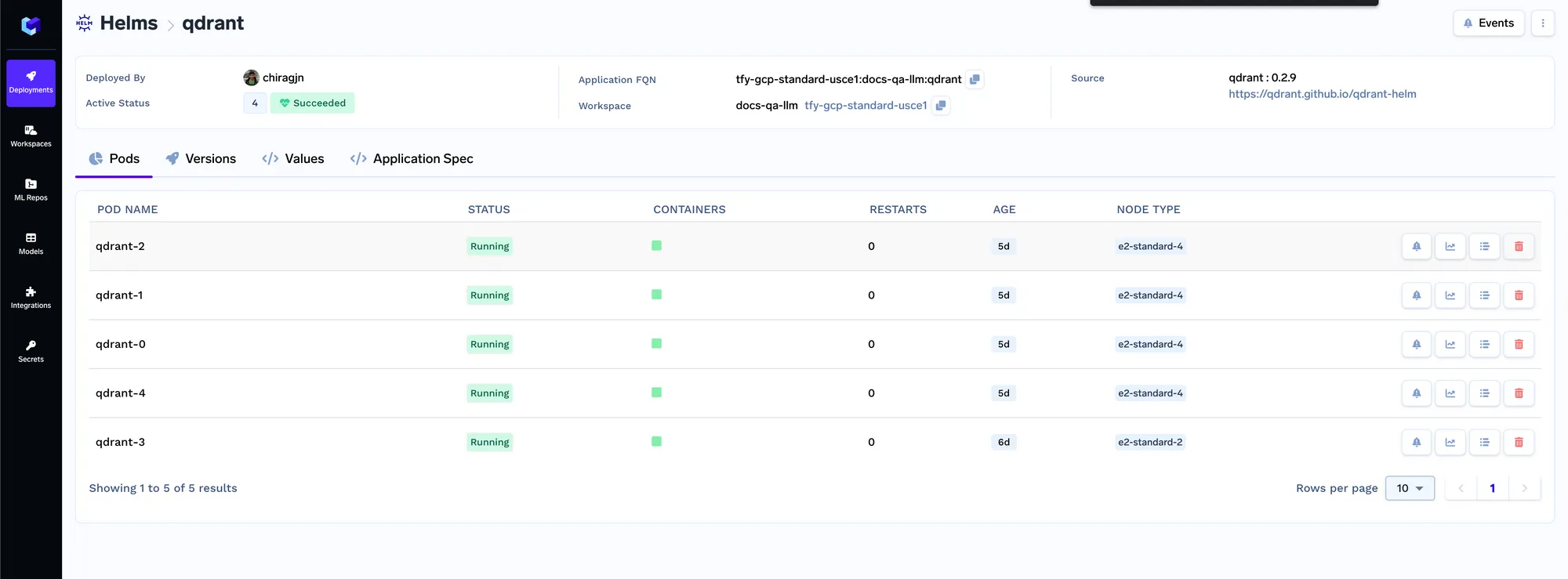
Wir werden jetzt den Indexer-Job bereitstellen. Der Job in Truefoundry ermöglicht es uns, ein Skript einmal oder nach Zeitplan auszuführen, und dann wird der Computer heruntergefahren, nachdem der Job abgeschlossen ist. Den Indexer-Jobcode finden Sie hier: https://github.com/truefoundry/docs-qa-playground/tree/main/backend/train. Der Indexer-Job unterstützt das Laden von Daten aus lokalen Dateien oder aus einem MLFoundry-Artefakt. Außerdem wird automatisch ein Formular gerendert, in dem Sie Argumente angeben können, um den Job auszulösen. <artifact_fqn>Sie können das Artefakt fqn, das wir in Schritt 1 kopiert haben, eingeben und es als mlfoundry://in das Quell-URI-Feld einfügen. Der Repo-Name kann eine beliebige Zeichenfolge sein, die Ihnen hilft, diesen Indizierungsjob zu identifizieren. Sie müssen auch den Namen des ML-Repos eingeben, das wir in Schritt 1 erstellt haben.
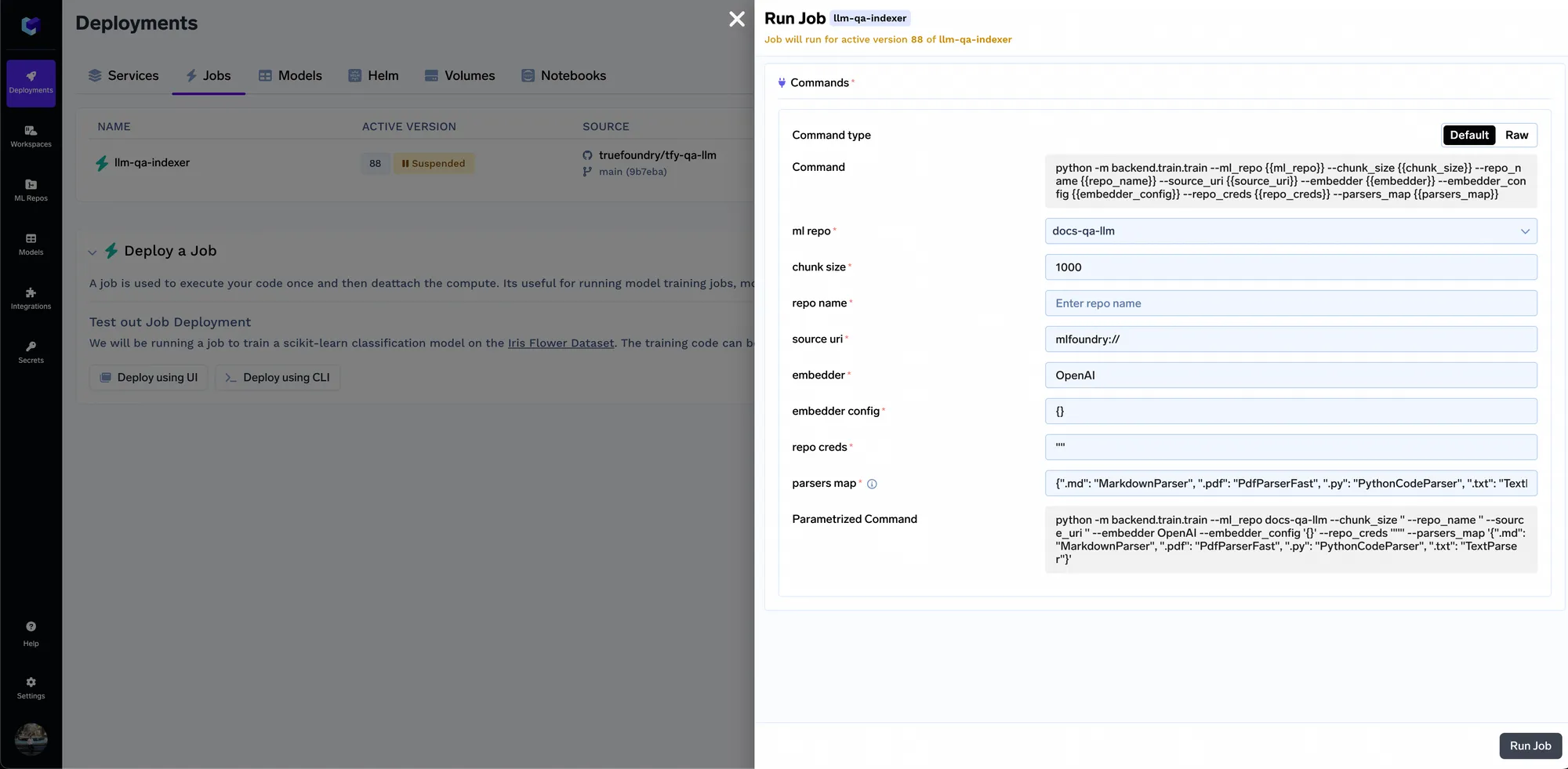
Sobald der Job ausgeführt wird, können Sie alle Jobausführungen und ihre Protokolle verfolgen:
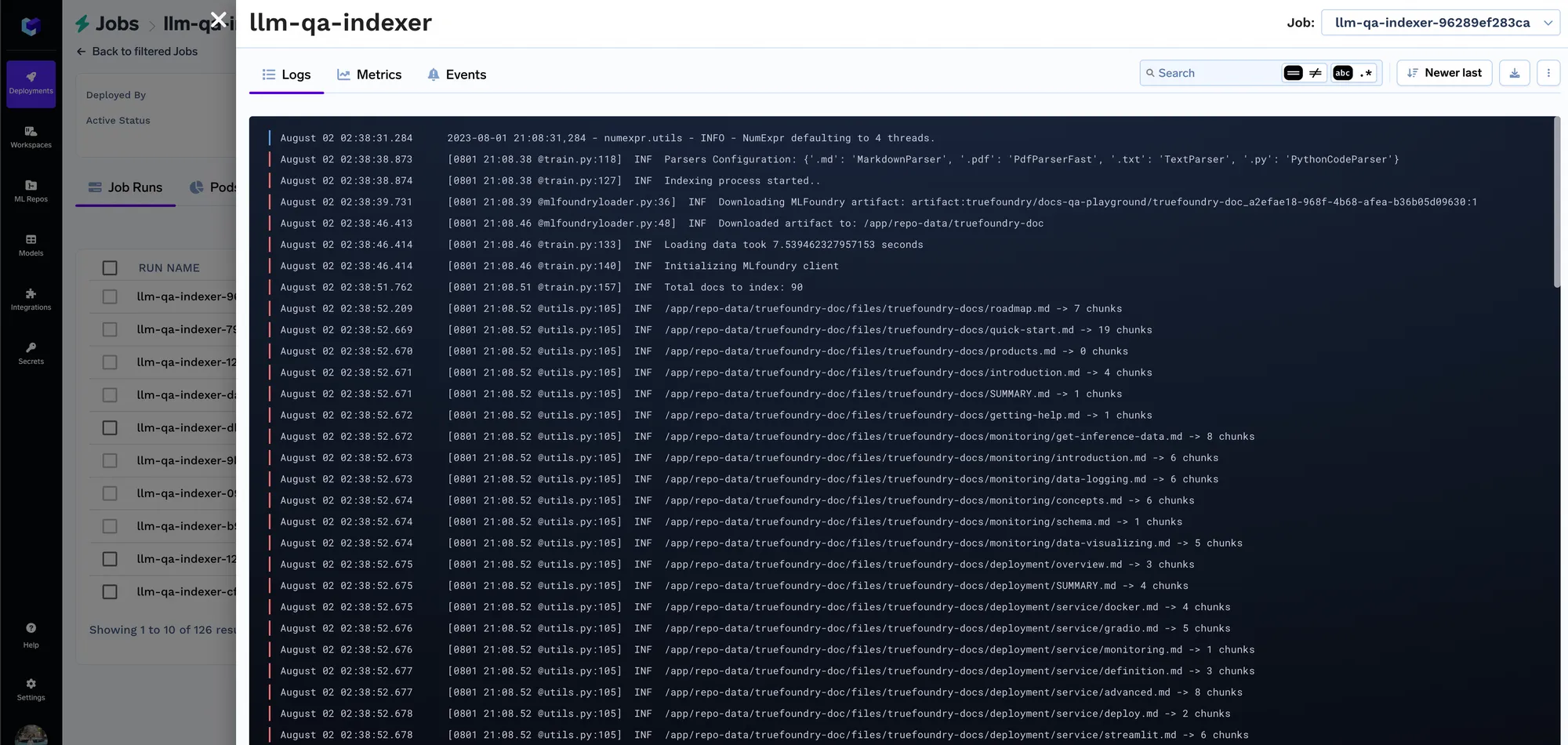
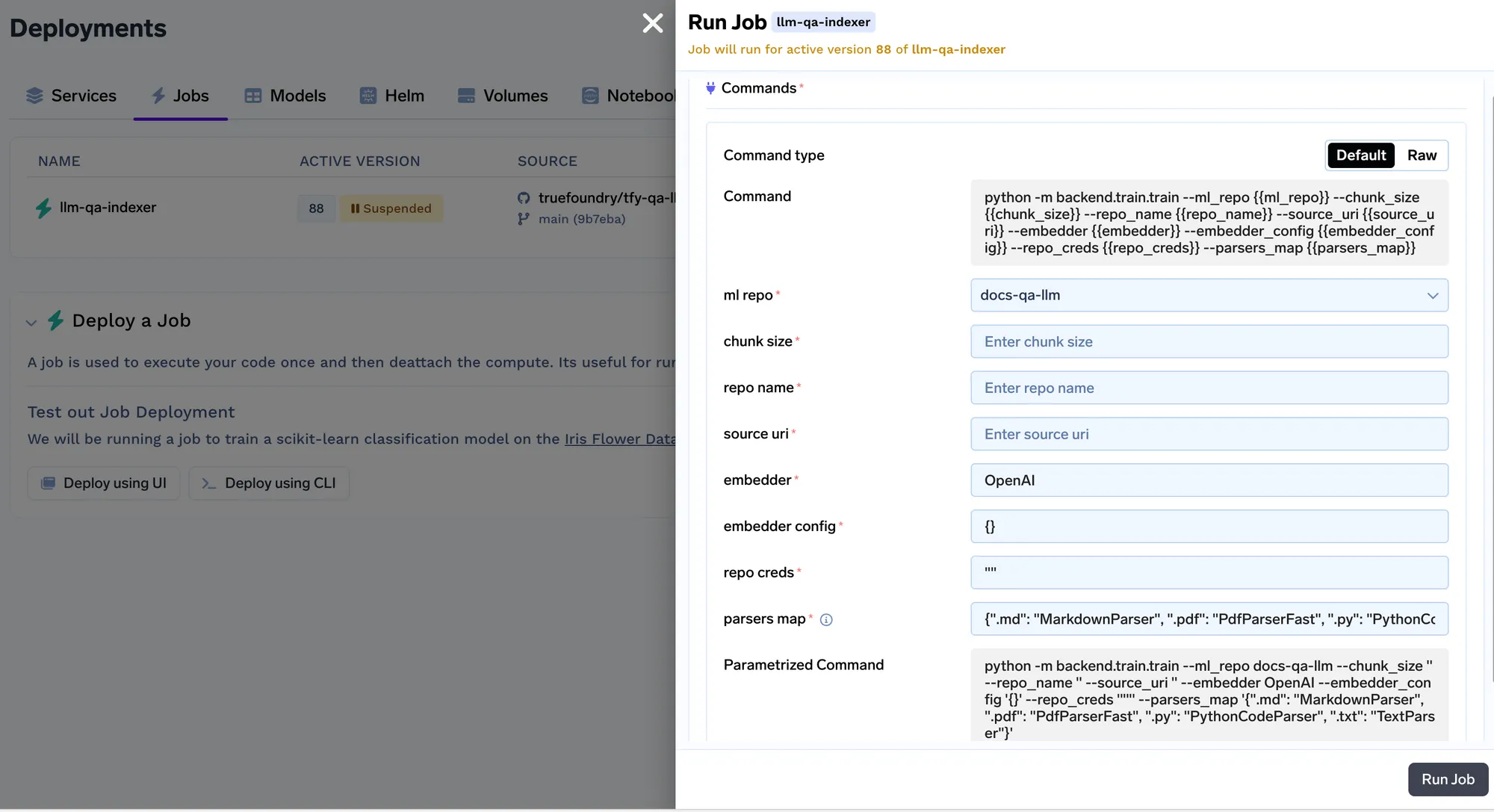
Jedes Mal, wenn der Job ausgeführt wird, erstellen wir einen Lauf im ML-Repo, der alle Einbettungseinstellungen und die Parameter des Indexer-Jobs speichert. Diese Einstellungen werden später vom Abfragedienst verwendet, um die Einbettungseinstellungen zu ermitteln, die zum Einbetten der Abfrage verwendet werden sollen. Sie können die Details aller Indizierungsaufträge auf der Registerkarte „Ausführungen“ verfolgen.
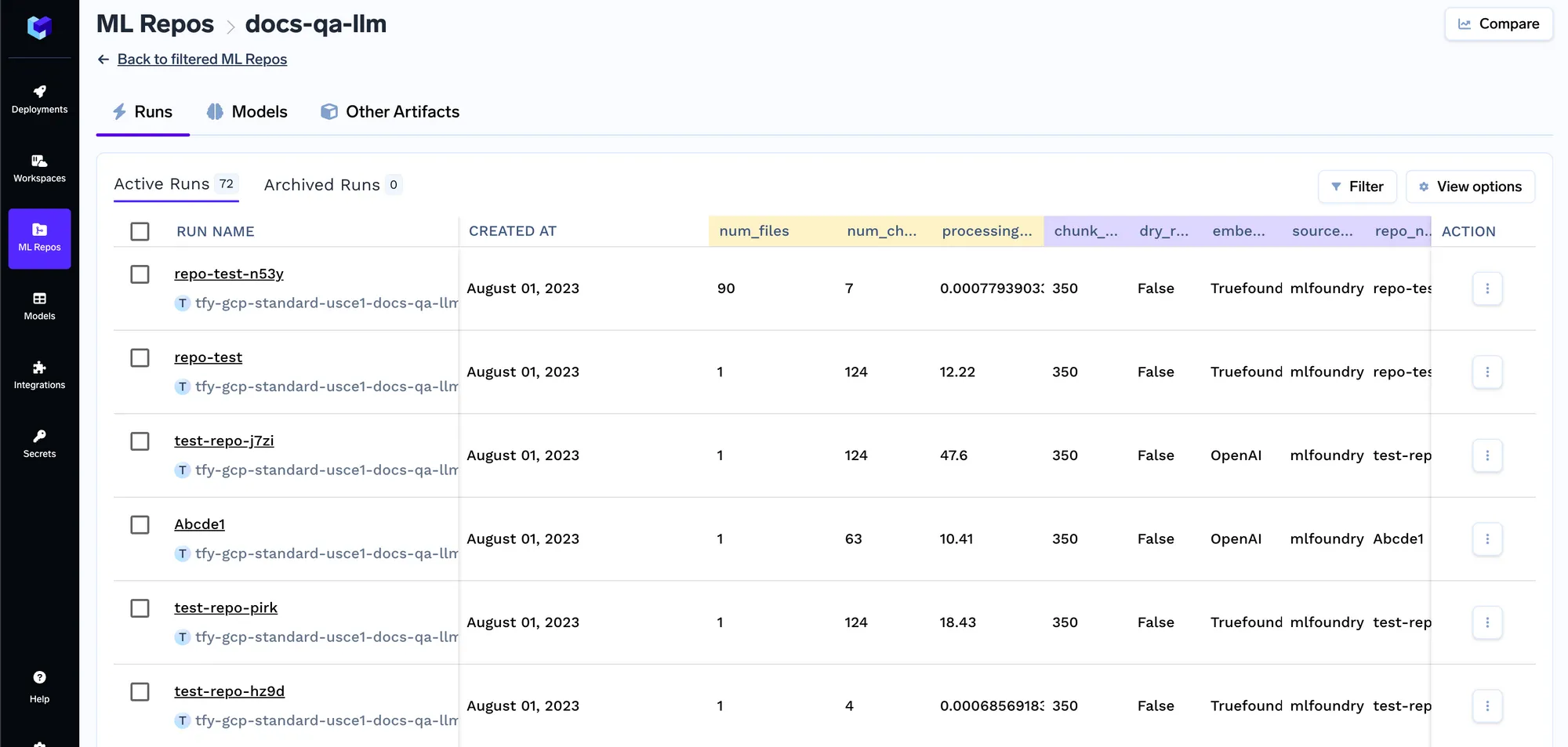
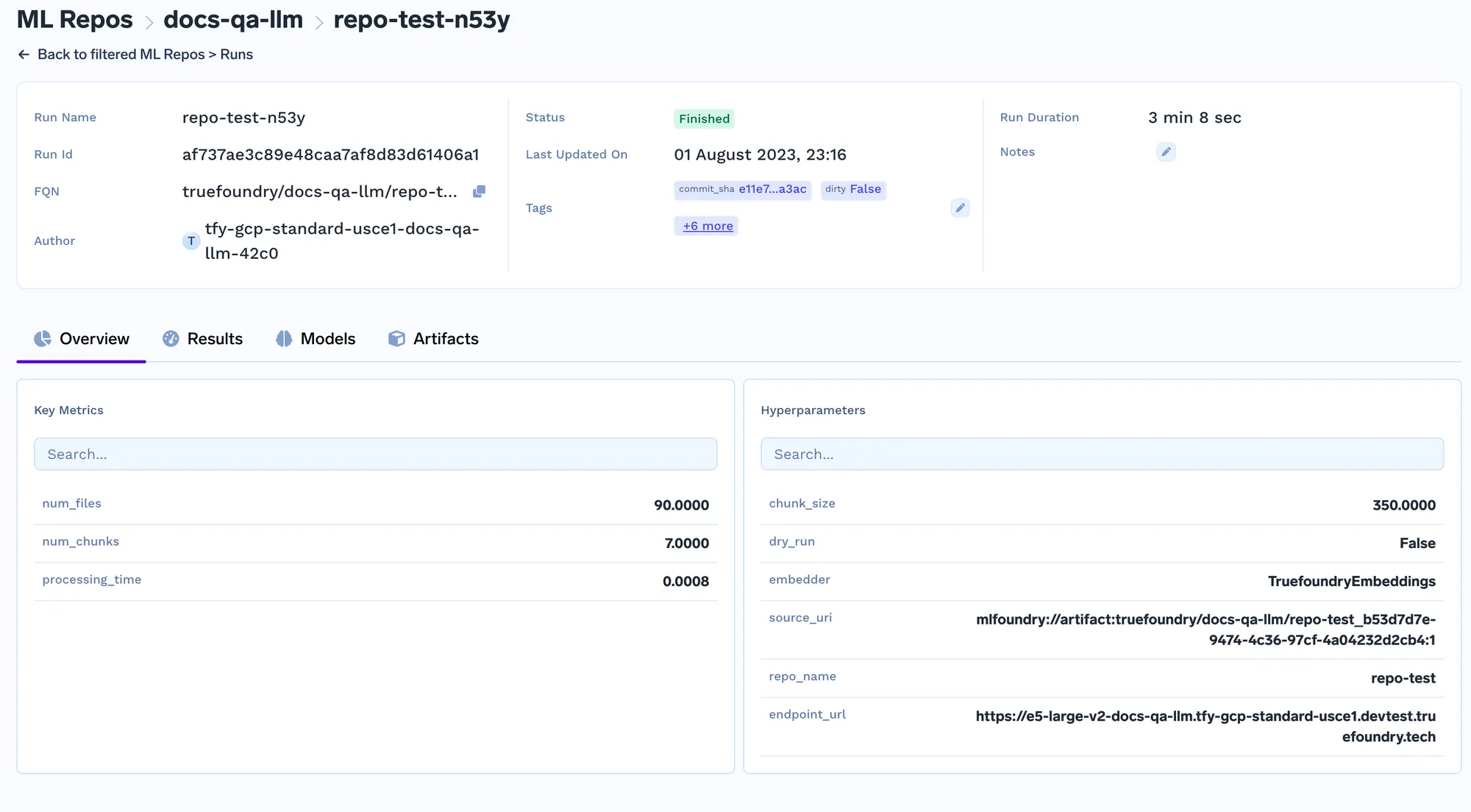
Der Abfragedienst ist ein Fastapi-Server, der über eine API verfügt, um die Abfrage abzurufen und die Antwort vom LLM abzurufen. Sobald Sie ihn bereitgestellt haben, können Sie mithilfe der Swagger-Benutzeroberfläche auf Fastapi Abfragen stellen.
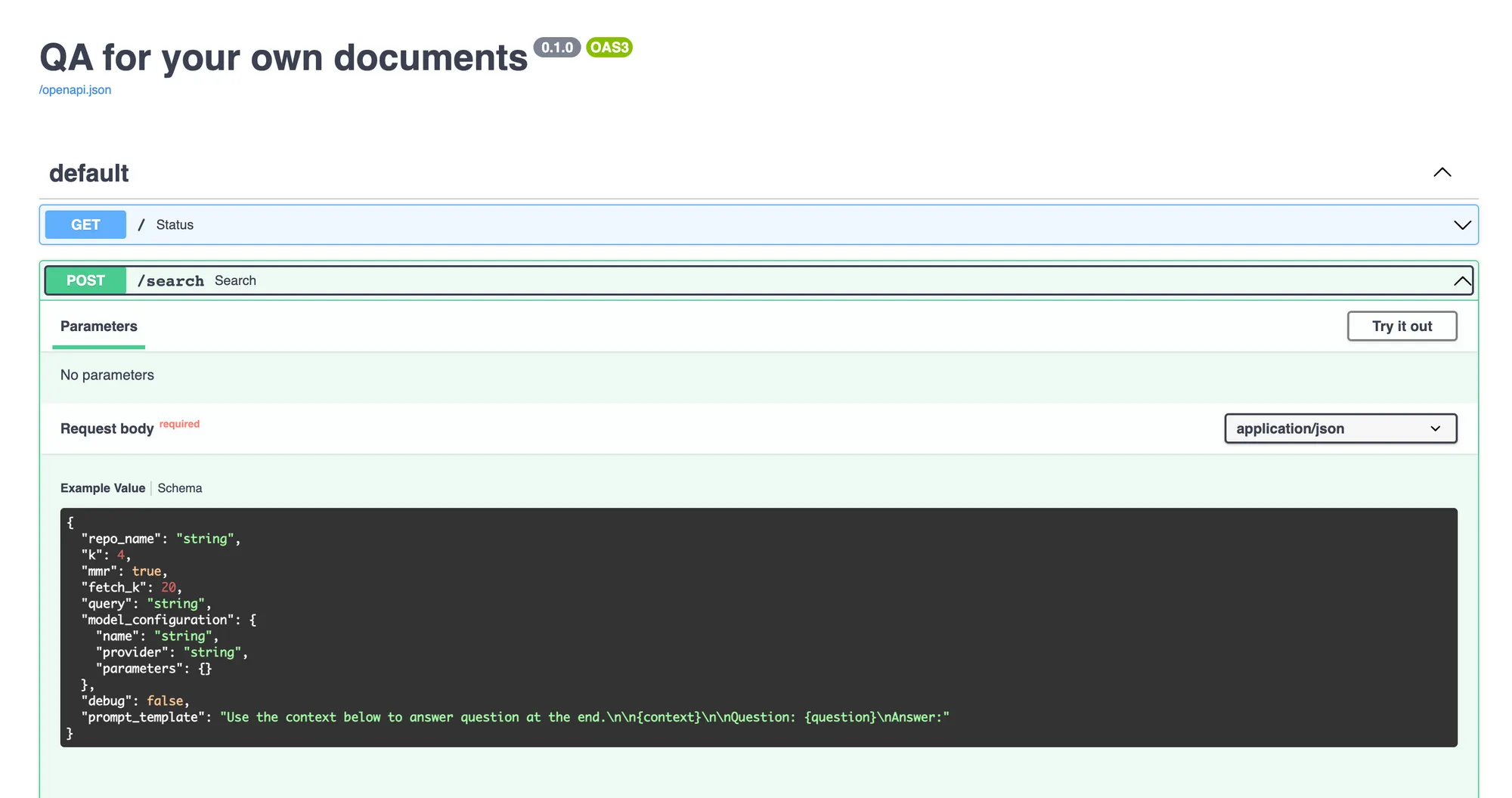
Dies ist erforderlich, wenn Sie planen, ein Open-Source-LLM und nicht OpenAI zu verwenden. Sie können das LLM aus dem Modellkatalog bereitstellen.
Wir bieten auch eine optimierte App, die mit Ihrem Indexierungs-Backend, Ihrem Abfragedienst und Ihrem Metadatenspeicher verbunden werden kann, um alle indizierten Repositorys aufzulisten und abzufragen. Eine Beispieldemo dazu finden Sie unter https://www.truefoundry.com/docs/introduction. Den Code findest du im Github-Repo hier. Damit dieses Frontend funktioniert, müssen Sie es mithilfe von Umgebungsvariablen mit Ihrem Abfragedienst und Job verknüpfen:
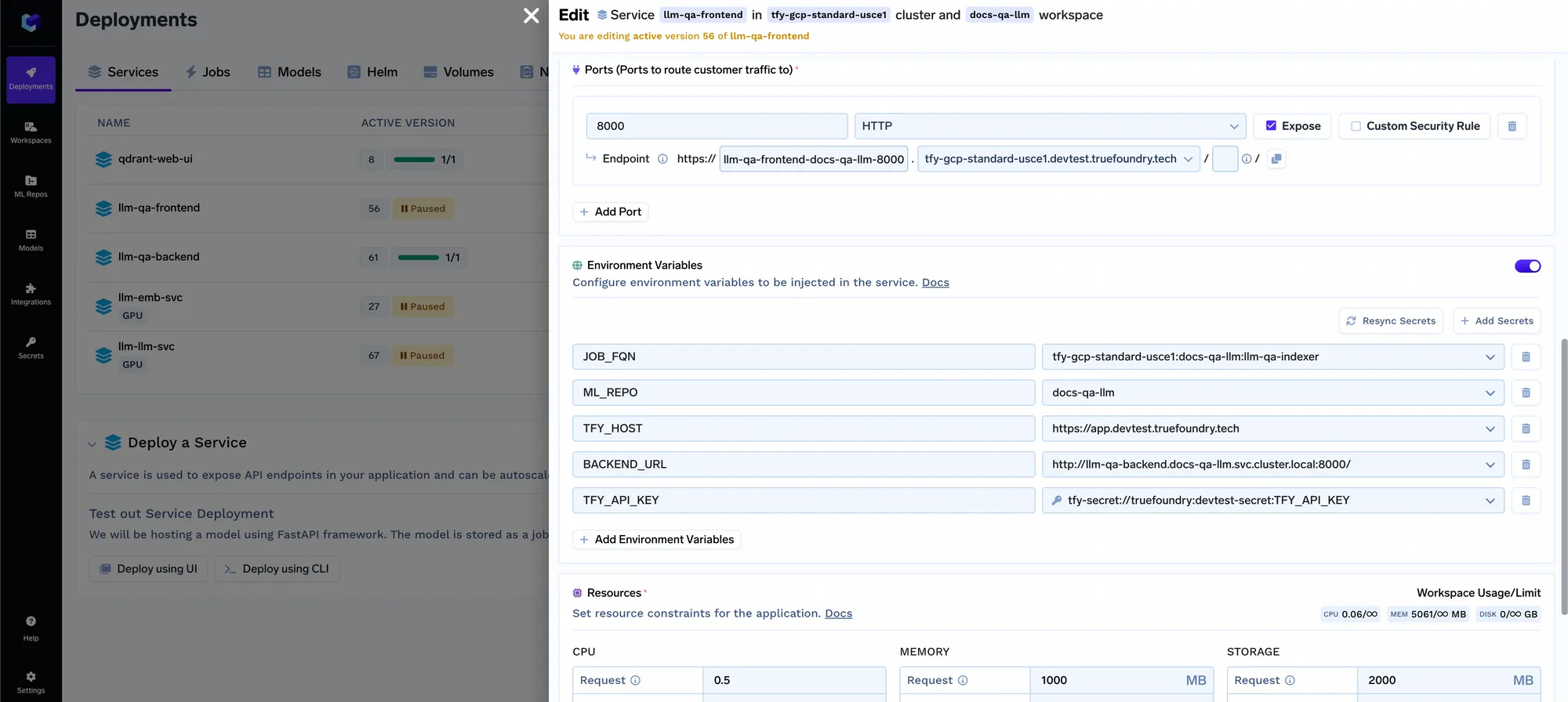
Jetzt haben wir ein durchgängiges System mit einem Frontend, das auf beliebig viele verschiedene Anwendungsfälle und Dokumentensätze innerhalb des Unternehmens skaliert werden kann. Es gibt ein paar Dinge, die wir in Zukunft berücksichtigen wollen:
Diese Architektur ermöglicht auch einen zentralen Dokumentenindexierungsdienst in einer Organisation, die auf einer zentralen Bibliothek von Datenladern und Parsern basiert.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




