

July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
LLMOPs, auch bekannt als Large Language Model Operations, umfassen die speziellen Praktiken und Prozesse, die für die effiziente Verwaltung und Operationalisierung großer Sprachmodelle (LLMs) unerlässlich sind. LLMs sind fortschrittliche Modelle zur Verarbeitung natürlicher Sprache, die in der Lage sind, menschenähnlichen Text zu generieren und eine Vielzahl sprachbezogener Aufgaben auszuführen. Diese Modelle stellen einen bedeutenden Fortschritt in der KI dar und haben in verschiedenen Bereichen wie Chatbots, Übersetzungsdiensten, Inhaltsgenerierung und mehr Anwendung gefunden.
Die Rolle von LLMops besteht darin, die reibungslose Entwicklung, Bereitstellung und Wartung von LLMs während ihres gesamten Lebenszyklus sicherzustellen. Es umfasst verschiedene Phasen, von der Datenerfassung und Vorverarbeitung über die Feinabstimmung des Modells bis hin zur Bereitstellung in der Produktion und der kontinuierlichen Überwachung und Aktualisierung, um eine optimale Leistung zu gewährleisten.
Die Entwicklung und Bereitstellung großer Sprachmodelle ist aufgrund ihrer Komplexität und ihres ressourcenintensiven Charakters mit einer Reihe einzigartiger Herausforderungen verbunden:
LLMOPs haben zwar Ähnlichkeiten mit traditionellen MLOPs (Machine Learning Operations), es gibt jedoch einige unterschiedliche Aspekte, die sie auszeichnen:
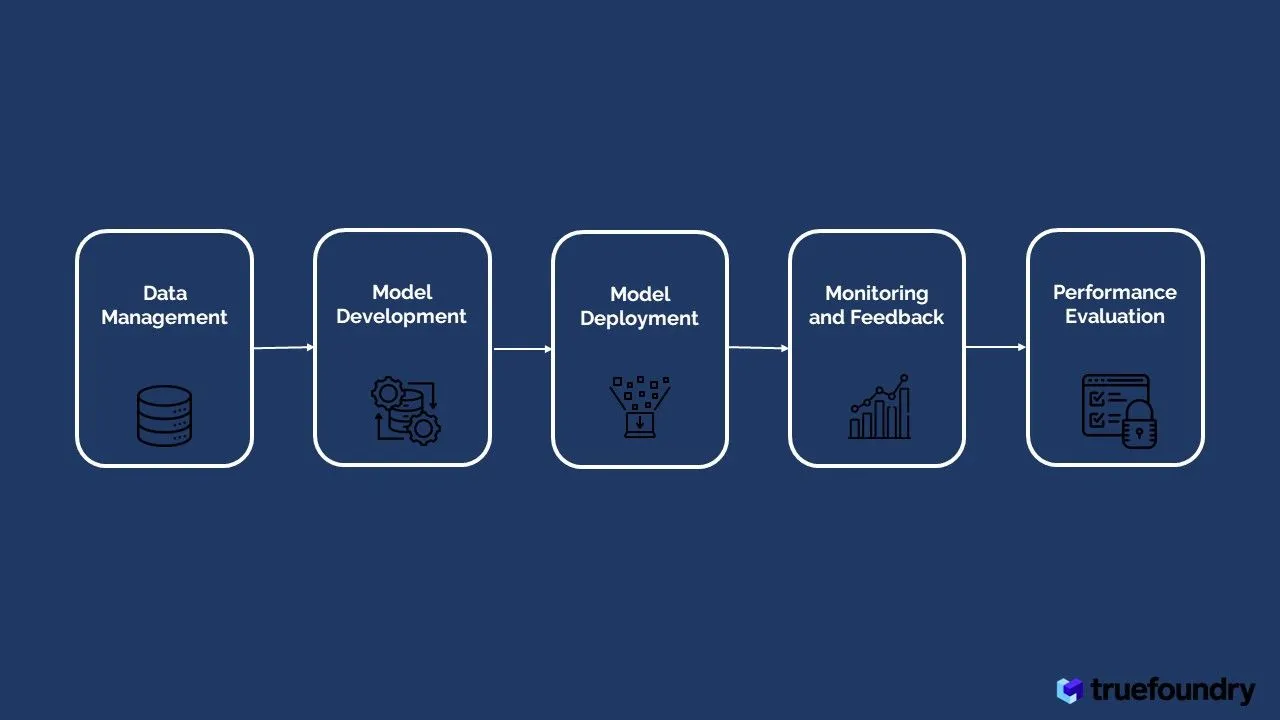
Daten sind der Eckpfeiler jedes erfolgreichen Large Language Model (LLM) — ein leistungsstarkes Tool, das die Verarbeitung natürlicher Sprache revolutioniert hat. Der Weg von den Rohdaten zu einem leistungsstarken LLM erfordert jedoch eine Reihe entscheidender Schritte im Datenmanagement. In diesem Abschnitt werden wir uns mit den Feinheiten der Datenbeschaffung, Vorverarbeitung, Kennzeichnung und Modellentwicklung befassen und die Herausforderungen und Best Practices beleuchten, mit denen LLMOps-Teams in dieser entscheidenden Phase der KI-Sprachkompetenz konfrontiert sind.
Das Sammeln vielfältiger und repräsentativer Daten ist eine enorme Herausforderung, die die Wirksamkeit eines LLM erheblich beeinflussen kann. LLMOps-Teams durchqueren die Weiten des Webs und kuratieren eine Vielzahl von Texten, Konversationen und Dokumenten, um einen robusten und umfassenden Datensatz zu erstellen. Strategien wie Web Scraping, die Nutzung von Open-Source-Repositorys und die Zusammenarbeit mit Fachexperten ermöglichen es Teams, Datensätze zu erstellen, die die reale Komplexität der Sprache widerspiegeln.
Nach der Erfassung werden die Daten einer strengen Vorverarbeitung unterzogen, um für das LLM-Training bereit zu sein. Zur Bereinigung der Daten gehören das Entfernen von Rauschen und irrelevanten Informationen sowie der Umgang mit Rechtschreib- und Grammatikfehlern. Die Tokenisierung zerlegt den Text in sinnvolle Einheiten wie Wörter oder Teilwörter, sodass das Modell die Sprache besser verarbeiten und verstehen kann. Die Normalisierung sorgt für Einheitlichkeit, indem der Text in ein Standardformat konvertiert wird, wodurch potenzielle Diskrepanzen während des Trainings reduziert werden.
Überwachtes Lernen erfordert beschriftete Daten, und LLMOPS-Teams investieren erhebliche Anstrengungen in die Erstellung kommentierter Datensätze für bestimmte LLM-Aufgaben. Manuelle Anmerkungen durch menschliche Experten oder Crowdsourcing-Plattformen helfen bei der Bereitstellung von Labels für Stimmungsanalysen, die Erkennung benannter Entitäten und mehr. Techniken wie aktives Lernen und Datenerweiterung optimieren die Kennzeichnungsbemühungen weiter und nutzen Ressourcen effektiv, um eine bessere Modellleistung zu erzielen.
Große Sprachmodelle (LLMs) gewinnen in einer Vielzahl von Anwendungen zunehmend an Bedeutung, z. B. in der Verarbeitung natürlicher Sprache, maschineller Übersetzung und Beantwortung von Fragen. LLMs können jedoch komplex und schwer zu verwalten sein. Vektordatenbanken können dazu beitragen, die Verwaltung von LLMs zu vereinfachen, indem sie eine Möglichkeit bieten, ihre großen Vektordarstellungen zu speichern und zu durchsuchen.
Eine Vektordatenbank ist eine Art von Datenbank, die Daten in Form von Vektoren speichert. Vektoren sind eine Art mathematisches Objekt, das zur Darstellung komplexer Daten wie Text, Bilder und Audio verwendet werden kann. Vektordatenbanken eignen sich gut zum Speichern und Durchsuchen von LLMs, da sie die großen Vektordarstellungen, die LLMs verwenden, effizient speichern und abrufen können.
Es gibt eine Reihe von Vektordatenbanken, darunter Pinceone, Milvus, Vespa AI, Qdrant, Redis, SingleStore, Weviate usw. Diese Vektordatenbanken bieten eine Vielzahl von Funktionen, die zur Verwaltung von LLMs verwendet werden können. Hier sind einige konkrete Beispiele dafür, wie Vektordatenbanken in LLMOPs verwendet werden können:
Die Modellentwicklung steht im Mittelpunkt von Large Language Model Operations (LLMOPs), wo das Streben nach optimaler Leistung und sprachlicher Brillanz beginnt. In dieser entscheidenden Phase begeben sich die LLMOps-Teams auf eine Reise der Architekturauswahl, Feinabstimmung und Hyperparameter-Optimierung, um Sprachmodelle zu kompetenten und vielseitigen Einheiten zu formen. In dieser umfassenden Untersuchung gehen wir in die Feinheiten jedes einzelnen Schritts ein und beleuchten die Herausforderungen und modernsten Techniken, die KI-Sprachkompetenz fördern.
Die Wahl der richtigen LLM-Architektur ist ein entscheidender Faktor, der ihre Fähigkeiten maßgeblich beeinflusst. LLMOps-Teams evaluieren sorgfältig verschiedene Architekturoptionen und berücksichtigen dabei Faktoren wie Modellgröße, Komplexität und die spezifischen Anforderungen der vorgesehenen Aufgaben. Transformer-basierte Architekturen wie die GPT-Familie (Generative Pre-trained Transformer) haben den Bereich der Verarbeitung natürlicher Sprache revolutioniert. Neue Architekturen, die Innovationen wie Aufmerksamkeitsmechanismen, Gedächtniserweiterung und adaptive Berechnungen beinhalten, werden jedoch kontinuierlich erforscht, um spezifische Herausforderungen zu bewältigen, die Leistung zu verbessern und vielfältige Anwendungen abzudecken.
Die Nachverfolgung von Experimenten ist ein entscheidender Aspekt von Large Language Model Operations (LLMOPs) und ermöglicht es Teams, die unzähligen Experimente, die während der LLM-Entwicklung durchgeführt wurden, systematisch zu verwalten und zu analysieren. Durch die Implementierung robuster Tracking-Frameworks protokollieren LLMOps-Teams effizient Modellkonfigurationen, Hyperparameter und Ergebnisse und ermöglichen so datengestützte Entscheidungen. Es fördert Reproduzierbarkeit, Transparenz und Zusammenarbeit, unterstützt den Verfeinerungsprozess und passt die Modellreaktionen an den Erwartungen der Benutzer an. Das Tracking von Experimenten spielt eine zentrale Rolle im Human-in-the-Loop-Ansatz. Es berücksichtigt wertvolles Feedback und bringt uns der Realisierung von KI-gestützter Intelligenz vom Feinsten näher.
Vortrainierte LLMs dienen als Ausgangspunkt für die aufgabenspezifische Feinabstimmung. Dieser Prozess beinhaltet die Anpassung des Wissens und Verständnisses des Modells, um gezielte Aufgaben optimal zu bewältigen. LLMOps-Teams navigieren geschickt durch die Feinabstimmung und finden dabei das richtige Gleichgewicht zwischen der Beibehaltung des vorab trainierten Wissens des Modells und der Einbeziehung aufgabenspezifischer Informationen. Die Auswahl geeigneter Hyperparameter, einschließlich Lernraten, Chargengrößen und Optimierungsalgorithmen, spielt eine entscheidende Rolle beim Erreichen der gewünschten Leistung. Darüber hinaus wird die Menge der zusätzlichen Trainingsdaten, die für die Feinabstimmung erforderlich sind, sorgfältig festgelegt, um zu verhindern, dass das Potenzial des Modells über- oder unterschätzt wird.
Hyperparameter dienen als Einstellräder, die das Verhalten des Modells während des Trainings steuern. Die optimale Konfiguration dieser Hyperparameter zu finden, ist ein entscheidender Schritt zur Maximierung der Modellleistung. LLMOps-Teams wenden eine Vielzahl von Techniken an, um sich auf die Optimierung der Hyperparameter zu begeben. Von der Rastersuche über die Bayes-Optimierung bis hin zu evolutionären Algorithmen untersucht jede Methode den riesigen Hyperparameterraum, um den Sweetspot zu identifizieren, an dem das Modell seine Spitzenleistung erzielt. Darüber hinaus werden Methoden wie Lernrhythmuspläne und Gewichtsabbau genutzt, um die Generalisierung zu verbessern und Überanpassungen zu verhindern.
LLMOPS-Teams nutzen Transfer Learning- und Multitask-Lernparadigmen, um die Anpassungsfähigkeit und Effizienz von Modellen zu verbessern. Transferlernen beinhaltet das Vortraining eines Sprachmodells auf einem riesigen Korpus, gefolgt von einer aufgabenspezifischen Feinabstimmung. Diese Technik ermöglicht es dem Modell, von dem Wissen zu profitieren, das aus einer Vielzahl von Sprachdaten gewonnen wurde. Multitask-Lernen ermöglicht es Modellen, gleichzeitig aus mehreren Aufgaben zu lernen, sodass sie die Beziehungen und gemeinsamen Muster zwischen den Aufgaben nutzen können, was zu einer besseren Generalisierung und Leistung führt.
Der Erfolg von Große Sprachmodelle (LLMs) hängt nicht nur von ihren beeindruckenden Fähigkeiten ab, sondern auch von ihrer reibungslosen Bereitstellung und ihrem effizienten Betrieb. In dieser entscheidenden Phase von Large Language Model Operations (LLMOPs) sind sorgfältige Planung und Ausführung von größter Bedeutung. Dieser Abschnitt befasst sich mit den Feinheiten von Einsatz von KI-Modellen Strategien, die Bedeutung kontinuierlicher Überwachung und Wartung sowie die unschätzbare Rolle von menschlichem Feedback und schnellem Engineering bei der Gestaltung von LLMs, um herausragende KI-Sprachkenntnisse zu erreichen.
Der Einsatz von LLMs in Produktionsumgebungen erfordert strategische Überlegungen, um eine optimale Leistung und Benutzerzufriedenheit zu gewährleisten. LLMOps-Teams evaluieren die Bereitstellungsstrategien sorgfältig und berücksichtigen dabei Infrastrukturanforderungen, Skalierbarkeits- und Leistungsaspekte. Die Cloud-basierte Bereitstellung bietet Flexibilität und Ressourcen auf Abruf, während lokale Lösungen Datenschutz- und Sicherheitsbedenken berücksichtigen. Die Edge-Bereitstellung ermöglicht es LLMs, näher an den Endbenutzern zu arbeiten, wodurch die Latenz reduziert und die Interaktion in Echtzeit verbessert wird. Die Wahl der am besten geeigneten Bereitstellungsstrategie verbessert die Verfügbarkeit und Reaktionsfähigkeit des LLM und erfüllt so die unterschiedlichen Anforderungen von Anwendungen in der realen Welt.
Die Bereitstellung und der Betrieb von LLMs erfordern einen ganzheitlichen und kollaborativen Ansatz. LLMOps-Teams arbeiten mit Fachexperten, Ethikern und Benutzeroberflächendesignern zusammen, um Herausforderungen umfassend anzugehen. Durch die Einbeziehung von Experten aus verschiedenen Bereichen wird sichergestellt, dass LLMs darauf zugeschnitten sind, bestimmte Branchen und Bereiche effektiv zu bedienen. Ethische Überlegungen spielen eine entscheidende Rolle bei der Minderung von Vorurteilen und der Sicherstellung eines verantwortungsvollen Einsatzes von KI. So entstehen LLMs, die in ihren Interaktionen mit den Nutzern fair, inklusiv und gerecht sind. Designer von Benutzeroberflächen verbessern das allgemeine Benutzererlebnis, machen LLMs intuitiver und benutzerfreundlicher und fördern reibungslose und produktive Interaktionen.
Continuous Integration (CI) ist die Praxis, bei der das Erstellen und Testen von Code jedes Mal automatisiert wird, wenn dieser einem Versionskontrollsystem zugewiesen wird. Auf diese Weise wird sichergestellt, dass der Code immer funktionsfähig ist und dass Änderungen schnell erkannt und behoben werden.
Continuous Delivery (CD) ist die Praxis der Automatisierung der Bereitstellung von Code in einer Produktionsumgebung. Auf diese Weise wird sichergestellt, dass Code schnell und zuverlässig bereitgestellt werden kann und dass alle Änderungen bei Bedarf rückgängig gemacht werden.
Wenn CI und CD kombiniert werden, bilden sie eine CI/CD-Pipeline. Eine CI/CD-Pipeline kann den gesamten Prozess der Erstellung, des Testens und der Bereitstellung von Modellen für maschinelles Lernen automatisieren. Dies kann dazu beitragen, die Zuverlässigkeit, Effizienz und Transparenz des Entwicklungs- und Bereitstellungsprozesses von Modellen für maschinelles Lernen zu verbessern.
Hier sind einige der Vorteile der Verwendung von CI/CD für LLMOPs:
Hier sind einige Beispiele für CI/CD-Tools für LLMOPs:
Dies sind nur einige der Vorteile der Verwendung von CI/CD für LLMOPs. Wenn Sie die Zuverlässigkeit, Effizienz und Sichtbarkeit Ihres Modellentwicklungs- und Bereitstellungsprozesses für maschinelles Lernen verbessern möchten, ist CI/CD ein wertvolles Tool, das Sie in Betracht ziehen sollten.
Kontinuierliche Überwachung ist der Herzschlag erfolgreicher LLM-Operationen. Es ermöglicht LLMOps-Teams, Probleme umgehend zu identifizieren und zu beheben, um Spitzenleistung und Zuverlässigkeit zu gewährleisten. Die Überwachung umfasst Leistungskennzahlen wie Reaktionszeit, Durchsatz und Ressourcenauslastung, sodass bei Engpässen oder Leistungseinbußen rechtzeitig eingegriffen werden kann. Darüber hinaus ist die Erkennung von Verzerrungen oder schädlichen Ergebnissen für einen verantwortungsvollen KI-Einsatz von entscheidender Bedeutung. Durch den Einsatz fairnessbewusster Überwachungstechniken stellen die LLMOps-Teams sicher, dass LLMs ethisch handeln, wodurch unbeabsichtigte Vorurteile reduziert und das Vertrauen der Nutzer gestärkt wird. Regelmäßige Modellaktualisierungen und -wartungen, die durch automatisierte Pipelines erleichtert werden, garantieren, dass das LLM über die neuesten Entwicklungen und Datentrends auf dem Laufenden bleibt, was eine nachhaltige Effizienz und Anpassungsfähigkeit garantiert
Menschliches Feedback ist eine entscheidende treibende Kraft bei der Verbesserung der LLM-Leistung. Die LLMOps-Teams verfolgen einen Ansatz, bei dem Experten und Endbenutzer wertvolles Feedback zu den Ergebnissen des LLM geben können. Dieser iterative Prozess erleichtert die Verbesserung und Feinabstimmung des Modells und passt die Antworten des LLM an den menschlichen Erwartungen und realen Bedürfnissen an. Reinforcement Learning from Human Feedback (RLHF) ist eine Technik des maschinellen Lernens, bei der Modelle trainiert werden, um Texte zu generieren, die auf menschliche Vorlieben abgestimmt sind. RLHF funktioniert, indem es dem Modell ein Belohnungssignal für die Generierung von Text gibt, der von einem menschlichen Evaluator als „gut“ eingestuft wird. Das Modell lernt dann, Text zu generieren, der das Belohnungssignal maximiert. RLHF kann verwendet werden, um die Leistung von LLMs bei einer Vielzahl von Aufgaben zu verbessern, z. B. bei der Zusammenfassung von Texten, bei der Beantwortung von Fragen und bei der Generierung von Dialogen. Durch die Kombination von menschlichem Feedback mit maschinellem Lernen kann RLHF Modelle erstellen, die genauer, informativer und ansprechender sind.
Darüber hinaus spielt Prompt Engineering eine zentrale Rolle dabei, LLMs dazu zu bringen, die gewünschten Ergebnisse zu erzielen. Die Erstellung geeigneter Prompts hilft dabei, die Reaktionen des Modells zu steuern, sodass die LLMOps-Teams experimentieren und Prompts für verschiedene Anwendungsfälle, Domänen und Benutzerpräferenzen optimieren können. Dadurch werden LLMs kontrollierbarer, anpassungsfähiger und effizienter, wenn es darum geht, aussagekräftige Antworten zu liefern
Testen ist ein integraler Aspekt von Large Language Model Operations (LLMOPs), das die Robustheit und Zuverlässigkeit von LLMs in realen Szenarien gewährleistet. Gründliche Testverfahren helfen den LLMOps-Teams dabei, die Leistung und Genauigkeit des Sprachmodells für eine Vielzahl von Aufgaben und Eingabeszenarien zu validieren. Verschiedene Testmethoden, darunter Komponententests, Integrationstests und umfassende Tests, werden eingesetzt, um verschiedene Aspekte der LLM-Funktionalität zu bewerten. Darüber hinaus helfen Stresstests und kontradiktorische Tests dabei, potenzielle Schwächen oder Schwachstellen in den Reaktionen des Modells zu identifizieren und sicherzustellen, dass es mit herausfordernden Eingaben und kontradiktorischen Beispielen souverän umgehen kann. Durch die Durchführung strenger Tests schaffen die LLMOps-Teams Vertrauen in die Fähigkeiten des Modells und fördern so den verantwortungsvollen und wirkungsvollen Einsatz von LLMs in praktischen Anwendungen.
Die Bewertung der Leistung von Large Language Models (LLMs) ist entscheidend für die Bewertung ihrer Fähigkeiten und ihres Potenzials für verschiedene Aufgaben der Verarbeitung natürlicher Sprache. Es gibt zahlreiche Bewertungsmethoden, die jeweils unterschiedliche Aspekte der Effektivität eines Modells beleuchten. Im Folgenden sind fünf häufig verwendete Bewertungsdimensionen aufgeführt, die wertvolle Einblicke in die Leistung von LLMs bieten:
Ratlosigkeit ist ein grundlegendes Maß, das häufig zur Bewertung der Leistung von Sprachmodellen verwendet wird. Es quantifiziert, wie effektiv das Modell eine bestimmte Textprobe vorhersagt. Ein niedrigerer Perplexitätswert bedeutet, dass das Modell das nächste Wort in einer Sequenz besser vorhersagen kann, was auf eine kohärentere und flüssigere Ausgabe schließen lässt. Diese Metrik hilft Forschern und Entwicklern bei der Feinabstimmung ihrer Modelle zur Verbesserung der Sprachgenerierung und des Sprachverständnisses.
Automatisierte Metriken sind zwar wertvoll, aber die menschliche Bewertung spielt eine zentrale Rolle bei der Bewertung der wahren Qualität von Sprachmodellen. Bei diesem Ansatz werden menschliche Gutachter beauftragt, die generierten Antworten anhand mehrerer Kriterien wie Relevanz, Sprachkompetenz, Kohärenz und Gesamtqualität zu überprüfen und zu bewerten. Das menschliche Urteilsvermögen liefert subjektives Feedback und erfasst Nuancen, die bei automatisierten Metriken möglicherweise übersehen werden. Dies ist ein entscheidender Schritt, um zu verstehen, wie gut das Modell in realen Szenarien abschneidet, und ermöglicht es Forschern, auf spezifische Bedenken oder Einschränkungen einzugehen.
BLEU wird hauptsächlich bei maschinellen Übersetzungsaufgaben verwendet und vergleicht die generierte Ausgabe mit einer oder mehreren Referenzübersetzungen, um die Ähnlichkeit zwischen ihnen zu messen. Ein höherer BLEU-Score bedeutet, dass die generierte Übersetzung des Modells gut mit den bereitgestellten Referenzübersetzungen übereinstimmt. Es hilft bei der Bewertung der Übersetzungsgenauigkeit und Effektivität des Modells.
ROUGE ist eine Reihe von Metriken, die in großem Umfang zur Bewertung der Qualität von Textzusammenfassungen verwendet werden. Es misst die Überschneidung zwischen der generierten Zusammenfassung und einer oder mehreren Referenzzusammenfassungen unter Berücksichtigung von Präzision, Erinnerung und F1-Score. ROUGE-Scores liefern wertvolle Erkenntnisse darüber, wie gut das Sprachmodell präzise und informative Zusammenfassungen generieren kann. Daher ist es für Aufgaben wie die Zusammenfassung von Dokumenten und die Generierung von Inhalten von unschätzbarem Wert.
Insbesondere in Anwendungen wie Chatbots oder Textgenerierungssystemen ist es unerlässlich, sicherzustellen, dass ein Sprachmodell vielfältige und einzigartige Ergebnisse liefert. Diversitätsmessungen umfassen die Analyse von Metriken wie der N-Gramm-Diversität oder die Messung der semantischen Ähnlichkeit zwischen den generierten Antworten. Höhere Diversitätswerte deuten darauf hin, dass das Modell ein breiteres Spektrum an Antworten liefern und sich wiederholende oder monotone Ausgaben vermeiden kann.
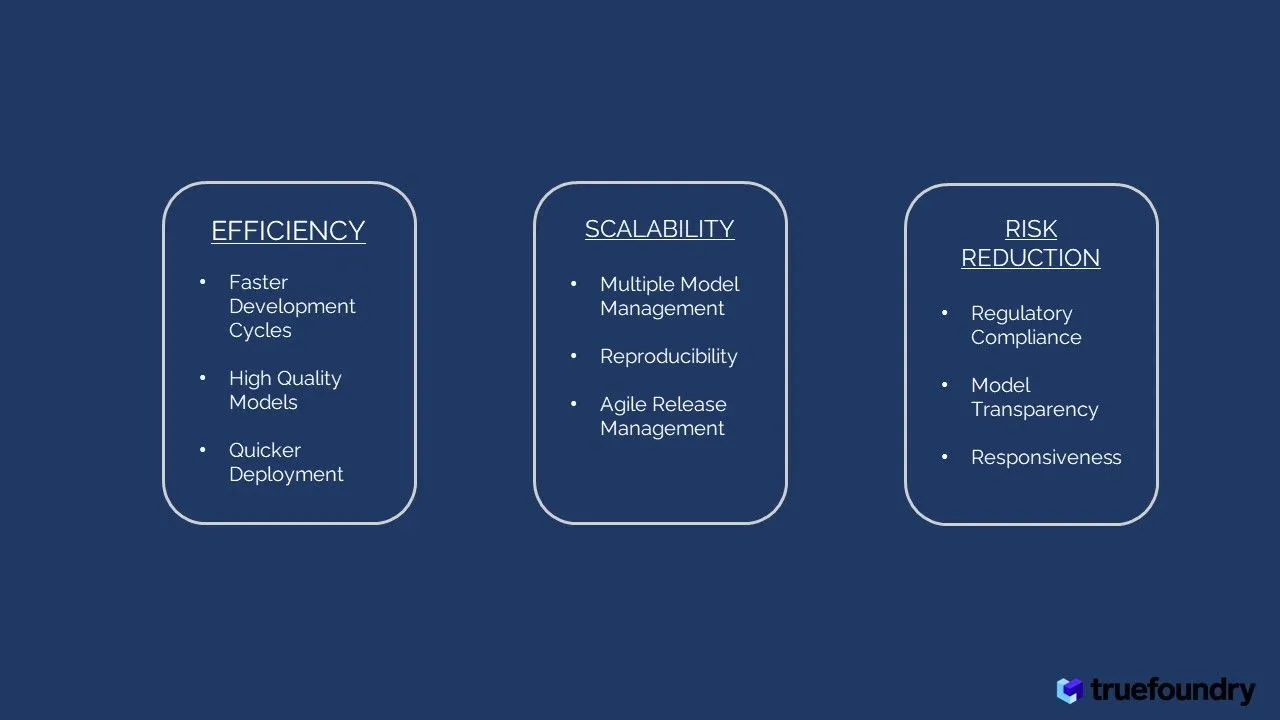
LLMOPs rationalisieren den LLM-Entwicklungsprozess und bieten mehrere Vorteile:
LLMOPs unterstützen die Skalierbarkeit und Reproduzierbarkeit von LLM-Pipelines:
LLMops befasst sich mit potenziellen Risiken im Zusammenhang mit der LLM-Bereitstellung:
Zusammenfassend lässt sich sagen, dass LLMOPs eine entscheidende Rolle bei der Verwaltung des komplexen und ressourcenintensiven Prozesses der Entwicklung, Bereitstellung und Wartung großer Sprachmodelle spielen. Durch die Bewältigung einzigartiger Herausforderungen und den Einsatz spezialisierter Techniken stellen LLMOPs den effizienten und ethischen Einsatz dieser leistungsstarken KI-Modelle in verschiedenen realen Anwendungen sicher.
Wenn das LLM-Ökosystem reift, evaluieren Teams häufig verschiedene Plattformen, um die Die besten LLMops-Tools für ihre spezifischen Arbeitsabläufe — unabhängig davon, ob dies die Versuchsverfolgung, die Modellbereitstellung, die Datenkennzeichnung oder die Produktionsüberwachung umfasst.
HuggingFace ist eine Open-Source-Plattform für den Aufbau und die Verwendung großer Sprachmodelle. Es bietet eine Bibliothek mit vortrainierten Modellen, eine Befehlszeilenschnittstelle und eine Web-App zum Experimentieren mit Modellen. Die Spezialität von HuggingFace liegt darin, große Sprachmodelle für jedermann zugänglich zu machen.
Die Bibliothek vortrainierter Modelle von HuggingFace umfasst eine Vielzahl von Modellen, von BERT bis GPT-3. Diese Modelle können für eine Vielzahl von Aufgaben verwendet werden, z. B. für das Verstehen natürlicher Sprache, die Generierung natürlicher Sprache und die Beantwortung von Fragen. Die Befehlszeilenschnittstelle von HuggingFace erleichtert das Laden und Verwenden dieser Modelle. Die Web-App bietet eine visuelle Oberfläche zum Experimentieren mit Modellen.
ClearML ist eine Plattform für die Verwaltung von Experimenten mit maschinellem Lernen. Es bietet eine Möglichkeit, Experimente zu verfolgen, Daten zu speichern und Ergebnisse zu visualisieren. Die Spezialität von ClearML ist die Fähigkeit, Experimente auf mehreren Plattformen für maschinelles Lernen zu verfolgen. Die Funktionen zur Versuchsverfolgung von ClearML machen es einfach, den Fortschritt Ihrer Machine-Learning-Projekte im Auge zu behalten. Sie können die von Ihnen verwendeten Parameter, die gemessenen Metriken und die erzielten Ergebnisse verfolgen. Mit ClearML können Sie auch Daten aus Ihren Experimenten speichern, sodass Sie Ihre Ergebnisse einfach reproduzieren können.
AWS SageMaker ist eine vollständig verwaltete Plattform, die umfassende Funktionen für die Erstellung, Schulung und Bereitstellung von Modellen für maschinelles Lernen bietet. Sie umfasst eine Vielzahl von Tools und Services für die Verwaltung des gesamten Lebenszyklus des maschinellen Lernens, von der Datenaufbereitung bis zur Modellbereitstellung. SageMaker ist eine beliebte Wahl für LLMOPs, da es eine Reihe von Funktionen bietet, die speziell für große Sprachmodelle entwickelt wurden, wie z. B.:
Bedrock ist eine neue Plattform von AWS, die speziell für generative KI entwickelt wurde. Sie bietet eine Reihe von Funktionen, die das Erstellen, Trainieren und Bereitstellen generativer KI-Modelle vereinfachen sollen, darunter:
Azure OpenAI-Dienste sind eine Reihe von Diensten, mit denen Sie die großen Sprachmodelle von OpenAI in Azure verwenden können. Zu diesen Diensten gehören ein verwalteter Endpunkt für die GPT-3-Modellfamilie, ein Text-to-Code-Dienst und ein Dienst zur Beantwortung von Fragen. Die Spezialität der Azure OpenAI-Dienste ist die Integration mit Azure. Die Azure OpenAI-Dienste machen es einfach, die großen Sprachmodelle von OpenAI in Ihren Azure-Anwendungen zu verwenden. Sie können den verwalteten Endpunkt verwenden, um auf ein GPT-3-Modell zuzugreifen, oder Sie können den Text-to-Code-Dienst verwenden, um Code aus Beschreibungen in natürlicher Sprache zu generieren. Die Azure OpenAI-Dienste bieten auch einen Dienst zur Beantwortung von Fragen, sodass Sie Fragen zu den Modellen von OpenAI stellen und Antworten erhalten können.
Die GCP Palm API ist eine API zur Verarbeitung natürlicher Sprache, die verwendet werden kann, um Text zu generieren, Sprachen zu übersetzen und Fragen zu beantworten. Sie basiert auf Googles LLMs wie BERT und GPT-3. Die Spezialität der GCP Palm API ist die Fähigkeit, Text zu generieren, Sprachen zu übersetzen und Fragen zu beantworten. Die GCP Palm API bietet eine Vielzahl von Funktionen zum Generieren von Text, zum Übersetzen von Sprachen und zum Beantworten von Fragen. Sie können es verwenden, um realistischen Text zu generieren, Sprachen präzise zu übersetzen und Fragen umfassend und informativ zu beantworten. Die GCP Palm API ist ein leistungsstarkes Tool für Entwickler, die in ihren Anwendungen die Verarbeitung natürlicher Sprache verwenden müssen.
LlamaIndex ist eine Plattform für die Indizierung und Suche großer Sprachmodelle. LLamaIndex eignet sich besonders gut für LLMOPs, da es eine Vielzahl von Funktionen für die Indizierung und Suche nach LLMs bietet, darunter schnelle Abfragen, Relevanzranking und Facettierung. Die schnelle Abfragefunktion von LlamaIndex ermöglicht es Ihnen, Ihre LLMs schnell nach den benötigten Informationen zu durchsuchen. Mit der Funktion „Relevanz-Ranking“ können Sie die Ergebnisse Ihrer Suchanfragen anhand ihrer Relevanz für Ihre Anfrage einordnen. Mit der Facettierungsfunktion können Sie die Ergebnisse Ihrer Suchanfragen nach verschiedenen Kriterien filtern.
LangChain ist ein LLMOPS-Plattform das Teams hilft, große Sprachmodelle (LLMs) in großem Maßstab zu erstellen, bereitzustellen und zu verwalten. Es bietet eine Vielzahl von Funktionen für die Verwaltung von LLMs, darunter Versionskontrolle, Versuchsverfolgung und Produktionsbereitstellung. Die Spezialität von LangChain ist die Fähigkeit, LLMs zu skalieren, um große Datenmengen zu verarbeiten. Es bietet auch eine Vielzahl von Funktionen zur Überwachung von LLMs, sodass Teams sicherstellen können, dass sie wie erwartet funktionieren.
Toloka ist eine Crowdsourcing-Plattform, mit der Sie Daten für Modelle des maschinellen Lernens kennzeichnen können. Toloka eignet sich besonders gut für LLMOPs, da damit große Datenmengen schnell und effizient etikettiert werden können. Toloka verfügt über einen großen Pool an Mitarbeitern, die rund um die Uhr für die Kennzeichnung von Daten zur Verfügung stehen. Die Plattform hilft dabei, in allen Phasen der LLM-Entwicklung menschlichen Input einzuholen: Vortraining, Feinabstimmung und RLHF.
LabelBox ist eine Cloud-basierte Plattform zur Kennzeichnung von Daten für Modelle des maschinellen Lernens. LabelBox eignet sich besonders gut für LLMops, da es eine Vielzahl von Tools und Funktionen zum Kennzeichnen von Daten bietet, darunter eine webbasierte Oberfläche, eine mobile App und eine REST-API. Die webbasierte Oberfläche von LabelBox ist einfach zu bedienen und kann von jedem Gerät aus aufgerufen werden. Mit der mobilen App können Sie Daten unterwegs kennzeichnen. Die REST-API ermöglicht es Ihnen, LabelBox in Ihre bestehenden Workflows zu integrieren.
Argilla ist eine Plattform für die Verwaltung und Bereitstellung von Modellen für maschinelles Lernen. Argilla eignet sich besonders gut für LLMops, da es eine Open-Source-Plattform zur Datenkuration für LLMs bietet, die menschliche und maschinelle Feedback-Schleifen verwendet. Argilla bietet auch eine Vielzahl von Funktionen für die Verwaltung von Modellen, darunter Versionierung, Versuchsverfolgung und Produktionsbereitstellung. Das Versionierungssystem von Argilla ermöglicht es Ihnen, Änderungen an Ihren Modellen im Laufe der Zeit zu verfolgen. Das Experiment-Tracking-System ermöglicht es Ihnen, die Hyperparameter und Ergebnisse Ihrer Experimente aufzuzeichnen. Das Produktionssystem ermöglicht es Ihnen, Ihre Modelle in Produktionsumgebungen bereitzustellen.
Surge ist eine Plattform für den Einsatz von Modellen für maschinelles Lernen in der Produktion. Surge verfügt über eine spezielle RLHF-Plattform mit wichtigen Funktionen wie fachkundigen Etikettierern, einer Rapid Experimentation Interface, RLHF- und Sprachmodellkompetenz. Surge bedient eine Vielzahl von Anwendungsfällen, wie z. B. die Bewertung von Suchanfragen und die Moderation von Inhalten. Surge eignet sich besonders gut für LLMOPs, da es verschiedene Funktionen für die Bereitstellung von Modellen in der Produktion bietet, darunter Autoscaling, Überwachung und Warnmeldungen. Mit der Autoscaling-Funktion von Surge können Sie Ihre Modelle je nach Bedarf automatisch nach oben oder unten skalieren. Mit der Überwachungsfunktion können Sie die Leistung Ihrer Modelle in der Produktion verfolgen. Mit der Warnfunktion können Sie benachrichtigt werden, wenn Probleme mit Ihren Modellen auftreten.
Scale ist eine Full-Stack-Plattform, die die generative KI-Strategie unterstützt — einschließlich Feinabstimmung, zeitnaher Entwicklung, Sicherheit, Modellsicherheit, Modellbewertung und Unternehmensapps. Sie bietet auch Unterstützung für RLHF, Datengenerierung, Sicherheit und Ausrichtung. Scale eignet sich besonders gut für LLMOPs, da es eine Vielzahl von Funktionen für die Verwaltung von Modellen im großen Maßstab bietet, darunter Autoscaling, Lastausgleich und Fehlertoleranz. Mit der Autoscaling-Funktion von Scale können Sie Ihre Modelle je nach Bedarf automatisch nach oben oder unten skalieren. Die Load-Balancing-Funktion verteilt den Verkehr auf Ihre Modelle, um sicherzustellen, dass diese nicht überlastet werden. Mit der Fehlertoleranzfunktion können Ihre Modelle auch dann weiterbetrieben werden, wenn einige von ihnen ausfallen.
Databricks hat kürzlich ihr Open Instruction-Tuned LLM Dolly veröffentlicht. Databricks MLFlow eignet sich besonders gut für LLMops, da es verwendet werden kann, um die Leistung von LLMs im Laufe der Zeit zu verfolgen und sie in Produktionsumgebungen bereitzustellen. Es bietet ein zentrales Repository zum Speichern von ML-Experimenten, Modellen und Artefakten. Databricks MLflow bietet auch eine Vielzahl von Funktionen zur Leistungsverfolgung von ML-Modellen, darunter Versuchsverfolgung, Modellversionierung und Artefaktverwaltung.
Hier sind einige der wichtigsten Funktionen von Databricks MLFlow:
Eine Suite von LLMOps-Tools innerhalb der W&B MLOps-Plattform, die für Entwickler an erster Stelle steht. Verwenden Sie W&B Prompts, um den LLM-Ausführungsablauf zu visualisieren und zu überprüfen, Eingaben und Ausgaben zu verfolgen, Zwischenergebnisse anzuzeigen und Prompts und LLM-Kettenkonfigurationen sicher zu verwalten. Mit W&B können Sie Ihre Experimente auch mit anderen Teams teilen, was für die Zusammenarbeit und den Wissensaustausch hilfreich sein kann. W&B eignet sich besonders gut für LLMops, da es verwendet werden kann, um die Leistung von LLMs im Laufe der Zeit zu verfolgen und sie mit anderen Teams zu teilen.
Hier sind einige der wichtigsten Funktionen von W&B:
TrueLens ist eine Plattform für die Verwaltung und Bereitstellung großer Sprachmodelle (LLMs). TrueLens bietet eine Vielzahl von Funktionen für die Verwaltung von LLMs, darunter Versionierung, Versuchsverfolgung und Produktionsbereitstellung. TrueLens verwendet Feedback-Funktionen, um die Qualität und Effektivität Ihrer LLM-Anwendung zu messen. Mit TrueLens können Sie LLMs auch für eine Vielzahl von Cloud-Anbietern bereitstellen, was für Skalierbarkeit und Zuverlässigkeit hilfreich sein kann. TrueLens eignet sich besonders gut für Teams, die eine Vielzahl von ML-Frameworks verwenden, da es zur Verwaltung von Modellen aus verschiedenen Frameworks verwendet werden kann.
Hier sind einige der wichtigsten Funktionen von TrueLens:
Mit MosaicML können Sie kommerziell lizenzierte Open-Source-Modelle ausführen. Integrieren Sie LLMs einfach in Ihre Anwendungen. Außerdem können Sie sofort einsatzbereite Modelle bereitstellen oder Modelle für Ihre Daten optimieren. Mosaic ML ist eine Plattform für die Erstellung, Bereitstellung und Verwaltung von Modellen für maschinelles Lernen in großem Maßstab. Mosaic ML bietet eine Vielzahl von Funktionen für die Verwaltung von Modellen im großen Maßstab, darunter Autoscaling, Lastenausgleich und Fehlertoleranz. Mit Mosaic ML können Sie auch die Leistung Ihrer Modelle in der Produktion überwachen, was Ihnen helfen kann, Probleme schnell zu identifizieren und zu lösen.
Hier sind einige der wichtigsten Funktionen von Mosaic ML:
Stellen Sie LLMOPS-Tools wie Vector DBs, Embedding Server usw. auf Ihrer eigenen Kubernetes-Infrastruktur (EKS, AKS, GKE, On-Prem) bereit, einschließlich der Bereitstellung, Feinabstimmung, Nachverfolgung von Eingabeaufforderungen und Bereitstellung von Open-Source-LLM-Modellen mit vollständiger Datensicherheit und optimalem GPU-Management. Trainieren und starten Sie Ihre LLM-Anwendung im Produktionsmaßstab mit den besten Methoden der Softwareentwicklung. TrurFoundry bietet eine 5-mal schnellere Feinabstimmung und 10-mal schnellere Bereitstellungen für LLM-Modelle. TrueFoundry konzentriert sich auch auf die Senkung der Kosten (50% weniger) und die Datensicherheit für Ihre Large Language Model Operations.
Run:AI ist eine Plattform für ein durchgängiges LLM-Lifecycle-Management, mit der Unternehmen LLM-Modelle mühelos optimieren, entwickeln und bereitstellen können. Es eignet sich besonders gut für groß angelegte Bereitstellungen, da es skaliert werden kann, um jede Menge an Traffic zu bewältigen. Die Spezialität von Run:AI ist die Fähigkeit, den gesamten ML-Lebenszyklus zu automatisieren, von der Datenaufbereitung bis hin zur Modellbereitstellung und Überwachung. Dies kann Zeit und Mühe sparen und dazu beitragen, dass Machine-Learning-Projekte pünktlich und innerhalb des Budgets abgeschlossen werden
ZenML ist eine Plattform für den Aufbau, die Verwaltung und Bereitstellung von LLMs. Es eignet sich besonders für Teams, die ihre LLMops-Workflows automatisieren möchten. Die Spezialität von ZenML ist seine einfache Bedienung. Es bietet eine Drag-and-Drop-Oberfläche und eine Bibliothek mit vorgefertigten Komponenten, sodass Teams ML-Pipelines schnell und einfach erstellen und bereitstellen können.
Iguazio ermöglicht die wichtigsten Aspekte von LLMOPs: Automatisierung des Ablaufs, skalierbare Verarbeitung, fortlaufende Upgrades, schnelle Pipeline-Entwicklung und -Bereitstellung sowie Modellüberwachung. Allerdings müssen einige der Schritte angepasst werden. Beispielsweise müssen die Schritte zur Einbettung, Tokenisierung und Datenbereinigung angepasst werden, um nur einige zu nennen. Es eignet sich besonders gut für Teams, die ML-Anwendungen in mehreren Clouds bereitstellen müssen. Die Spezialität von Iguazio ist die Fähigkeit, ML-Anwendungen so zu skalieren, dass sie jede Menge an Traffic bewältigen können. Es bietet auch eine einzige Plattform für die Verwaltung aller ML-Bereitstellungen eines Teams, was Zeit und Mühe sparen kann.
Aviary von Anyscale ist eine vollständig Open-Source-, kostenlose, cloudbasierte LLM-Serving-Infrastruktur, die Entwicklern dabei helfen soll, die richtigen Technologien und Ansätze für ihre LLM-basierten Anwendungen auszuwählen und bereitzustellen. Aviary von Anyscals macht es einfach, kontinuierlich zu beurteilen, wie mehrere LLMs im Vergleich zu Ihren Daten abschneiden, und das richtige LLMs für Ihre Apps auszuwählen und bereitzustellen. Die Spezialität von Anyscale ist der verwaltete Kubernetes-Service. Dies erleichtert die Skalierung von ML-Workloads und stellt sicher, dass sie immer verfügbar sind.
Arize ist eine LLMops-Plattform, die Teams dabei unterstützt, LLMs für eine Vielzahl von Aufgaben zu erstellen, bereitzustellen und zu verwalten, darunter das Verstehen natürlicher Sprache, die Generierung natürlicher Sprache und die Beantwortung von Fragen. Sie bietet eine Vielzahl von Funktionen für die Verwaltung von LLMs, darunter Versionskontrolle, Versuchsverfolgung und Produktionsbereitstellung. Die Spezialität von Arize ist die Fähigkeit, sich in eine Vielzahl anderer Plattformen für maschinelles Lernen zu integrieren, sodass Teams ihre bestehende Infrastruktur nutzen können. Es bietet auch eine Vielzahl von Funktionen zur Überwachung von LLMs, sodass Teams sicherstellen können, dass sie die erwartete Leistung erbringen.
Die LLMOPS-Tools von Comet wurden so konzipiert, dass Benutzer die neuesten Fortschritte im Bereich Prompt Management und Abfragemodelle in Comet nutzen können, um schneller zu iterieren, Leistungsengpässe zu identifizieren und den internen Zustand der Prompt-Chains zu visualisieren. Comet bietet auch Integrationen mit führenden großen Sprachmodellen und Bibliotheken wie LangChain und dem Python SDK von OpenAI. Die Spezialität von Comet ist die Fähigkeit, Experimente auf mehreren Plattformen für maschinelles Lernen zu verfolgen. Es bietet auch eine Vielzahl von Funktionen für die Verwaltung von Projekten zum maschinellen Lernen, sodass Teams ihren Fortschritt verfolgen und effektiv zusammenarbeiten können.
PromptLayer ist eine Plattform für die Erstellung und Bereitstellung großer Sprachmodelle (LLMs) als APIs. Sie bietet eine Vielzahl von Funktionen für die Erstellung von LLMs, darunter eine Bibliothek mit vorgefertigten Komponenten und eine Drag-and-Drop-Oberfläche. Die Spezialität von PromptLayer ist die Fähigkeit, LLMs als APIs bereitzustellen. Dies macht es einfach, LLMs in einer Vielzahl von Anwendungen wie Chatbots und Frage-Antwort-Systemen zu verwenden.
OpenPrompt ist ein Open-Source-Framework für die Erstellung und Bereitstellung großer Sprachmodelle (LLMs). Es bietet eine Vielzahl von Funktionen für die Erstellung von LLMs, darunter eine Bibliothek mit vorgefertigten Komponenten und eine Befehlszeilenschnittstelle. Die Spezialität von OpenPrompt ist sein Open-Source-Charakter. Dies macht es Teams leicht, OpenPrompt an ihre spezifischen Bedürfnisse anzupassen.
Orquesta ist eine Plattform für die Orchestrierung von Pipelines für maschinelles Lernen. Sie bietet eine Vielzahl von Funktionen für die Orchestrierung von Pipelines, darunter eine Drag-and-Drop-Oberfläche und eine Bibliothek mit vorgefertigten Komponenten. Die Spezialität von Orquesta ist die Fähigkeit, Pipelines über mehrere Plattformen für maschinelles Lernen hinweg zu orchestrieren. Dies macht es einfach, Pipelines für maschinelles Lernen in der Produktion einzusetzen.
Pinceone ist eine Vektor-Suchmaschine, die für große Sprachmodelle (LLMs) entwickelt wurde. Es kann verwendet werden, um anhand ihrer Vektordarstellungen nach LLMs zu suchen, was es einfach macht, das LLM zu finden, das einer bestimmten Abfrage am ähnlichsten ist. Die Spezialität von Pinceone ist die Fähigkeit, anhand ihrer Vektordarstellungen nach LLMs zu suchen. Wenn Sie beispielsweise daran interessiert sind, das GPT-3-Sprachmodell zu verwenden, könnten Sie Pinceone verwenden, um nach LLMs zu suchen, die GPT-3 ähneln. Pinceone würde dann eine Liste von LLMs zurückgeben, die ähnliche Vektordarstellungen wie GPT-3 haben. Auf diese Weise können Sie leicht das LLM finden, das Ihren Bedürfnissen am besten entspricht.
Zilliz ist eine Vektordatenbank, die für LLMs konzipiert ist. Es kann zum Speichern und Abfragen von LLMs sowie zum Verfolgen der Leistung von LLMs im Laufe der Zeit verwendet werden. Die Spezialität von Zilliz ist die Fähigkeit, LLMs effizient zu speichern und abzufragen. Zilliz ist eine gute Wahl für das Speichern und Abfragen von LLMs, da es so konzipiert ist, dass es mit großen Datenmengen effizient umgehen kann. Das bedeutet, dass Sie LLMs in Zilliz speichern und abfragen können, ohne sich um Leistungsprobleme kümmern zu müssen.
Milvus ist eine Vektordatenbank, die für umfangreiche maschinelle Lernanwendungen konzipiert ist. Sie kann zum Speichern und Abfragen von Vektoren sowie zur Durchführung von Ähnlichkeitssuchen verwendet werden. Die Spezialität von Milvus ist die Fähigkeit, Ähnlichkeitssuchen effizient durchzuführen. Milvus ist eine gute Wahl für die Durchführung von Ähnlichkeitssuchen an großen Datensätzen, da es so konzipiert ist, dass es mit großen Datenmengen effizient umgehen kann. Das bedeutet, dass Sie Ähnlichkeitssuchen an großen Datensätzen in Milvus durchführen können, ohne sich über Leistungsprobleme Gedanken machen zu müssen.
Elastic ist eine Suchmaschine, die für eine Vielzahl von Anwendungen entwickelt wurde, einschließlich der Vektorsuche. Sie kann verwendet werden, um anhand ihrer Vektordarstellungen nach Vektoren zu suchen und eine Ähnlichkeitssuche. Die Spezialität von Elastic ist seine Flexibilität und Skalierbarkeit. Elastic ist eine gute Wahl für die Vektorsuche, da es flexibel und skalierbar ist. Das bedeutet, dass Sie Elastic für eine Vielzahl von Vektorsuchanwendungen verwenden und Elastic an Ihre Bedürfnisse anpassen können.
Vespa AI ist eine Suchmaschine, die für umfangreiche maschinelle Lernanwendungen entwickelt wurde. Sie kann zum Speichern und Abfragen von Vektoren sowie zur Durchführung einer Ähnlichkeitssuche verwendet werden. Die Spezialität von Vespa AI ist die Fähigkeit, Ähnlichkeitssuchen effizient und in großem Maßstab durchzuführen. Vespa AI ist eine gute Wahl für die Suche nach Ähnlichkeiten in großem Maßstab, da sie so konzipiert ist, dass sie mit großen Datenmengen effizient arbeitet. Das bedeutet, dass Sie in Vespa AI eine Ähnlichkeitssuche an großen Datensätzen durchführen können, ohne sich Gedanken über Leistungsprobleme machen zu müssen.
Searchium AI ist eine Suchmaschine, die für Anwendungen zur Verarbeitung natürlicher Sprache entwickelt wurde. Sie kann sowohl zur Suche nach Textdokumenten als auch zur Durchführung einer Ähnlichkeitssuche für Text verwendet werden. Die Spezialität von Searchium AI ist die Fähigkeit, Ähnlichkeitssuchen in Textdokumenten durchzuführen. Searchium AI ist eine gute Wahl für Anwendungen zur Verarbeitung natürlicher Sprache, da es so konzipiert ist, dass es Textdaten effizient verarbeitet. Das bedeutet, dass Sie in Searchium AI eine Ähnlichkeitssuche für Textdokumente durchführen können, ohne sich um Leistungsprobleme kümmern zu müssen.
Chroma ist eine Vektor-Suchmaschine, die für Anwendungen zur Verarbeitung natürlicher Sprache entwickelt wurde. Sie kann sowohl zur Suche nach Textdokumenten als auch zur Durchführung einer Ähnlichkeitssuche für Text verwendet werden. Die Spezialität von Chroma ist die Fähigkeit, Ähnlichkeitssuchen in Textdokumenten in Echtzeit durchzuführen. Chroma ist eine gute Wahl für die Ähnlichkeitssuche in Echtzeit, da es so konzipiert ist, dass es Textdaten effizient verarbeitet. Das bedeutet, dass Sie in Chroma eine Ähnlichkeitssuche in Textdokumenten durchführen können, ohne sich Gedanken über Leistungsprobleme machen zu müssen.
Varch ist eine Vektordatenbank, die für Anwendungen zur Verarbeitung natürlicher Sprache entwickelt wurde. Sie kann zum Speichern und Abfragen von Textdokumenten sowie zur Durchführung einer Ähnlichkeitssuche für Text verwendet werden. Die Spezialität von Vearch ist die Fähigkeit, Textdokumente effizient zu speichern und abzufragen. Vearch ist eine gute Wahl für das Speichern und Abfragen von Textdokumenten, da es darauf ausgelegt ist, Textdaten effizient zu verarbeiten. Das bedeutet, dass Sie Textdokumente in Varch speichern und abfragen können, ohne sich Gedanken über Leistungsprobleme machen zu müssen.
Qdrant ist eine Vektordatenbank, die für umfangreiche Machine-Learning-Anwendungen konzipiert ist. Sie kann zum Speichern und Abfragen von Vektoren sowie zur Durchführung von Ähnlichkeitssuchen verwendet werden. Die Spezialität von Qdrant ist seine Fähigkeit, Ähnlichkeitssuchen effizient und in großem Maßstab durchzuführen, und seine Unterstützung für verteiltes Rechnen. Qdrant ist eine gute Wahl für die Suche nach Ähnlichkeiten in großem Maßstab und verteiltes Rechnen, da es so konzipiert ist, dass es effizient mit großen Datenmengen arbeitet und verteiltes Rechnen unterstützt. Das bedeutet, dass Sie in Qdrant eine Ähnlichkeitssuche an großen Datensätzen durchführen können, ohne sich Gedanken über Leistungsprobleme machen zu müssen.
Da große Sprachmodelle in verschiedenen Anwendungen immer häufiger vorkommen, ist die Gewährleistung des Datenschutzes zu einem wichtigen Anliegen geworden. Künftige LLMOP-Trends werden die Einführung von Techniken zum Schutz der Privatsphäre zum Schutz sensibler Daten in den Vordergrund rücken. Föderiertes Lernen ist ein solcher Ansatz, der zunehmend an Bedeutung gewinnt. Modelle werden direkt auf den Geräten der Benutzer trainiert und nur aggregierte Modellaktualisierungen werden mit dem zentralen Server geteilt. Auf diese Weise können LLMOPs Datenschutzrisiken mindern und vertrauenswürdigere Modelle entwickeln, ohne die Benutzerdaten zu gefährden.
Der ressourcenintensive Charakter von Large Language Models erfordert kontinuierliche Bemühungen, diese Modelle zu optimieren und zu komprimieren. Zukünftige LLMOPs werden sich auf die Entwicklung effizienterer Architekturen und Algorithmen konzentrieren, die eine hohe Leistung aufrechterhalten und gleichzeitig die Speicher- und Rechenanforderungen reduzieren. Techniken wie Quantisierung, Destillation und Bereinigung werden eine entscheidende Rolle bei der Entwicklung leichter und dennoch leistungsstarker LLMs spielen, die auf verschiedenen Geräten und Plattformen besser einsetzbar und skalierbar sind.
Open-Source-Beiträge werden weiterhin Innovation und Zusammenarbeit innerhalb der LLMOPS-Community vorantreiben. Da LLMs zu einem wesentlichen Bestandteil der KI-Landschaft werden, werden Forscher, Entwickler und Praktiker aktiv zu LLMOps-Tools, -Bibliotheken und -Frameworks beitragen. Diese Zusammenarbeit wird die LLMOPS-Praktiken beschleunigen, die Modellfeinabstimmung verbessern und die Entwicklung modernster Anwendungen fördern.
Mit der zunehmenden Einführung von LLMs in kritischen Anwendungen steigt die Nachfrage nach Interpretierbarkeit und Erklärbarkeit. Künftige LLMOPs werden sich auf Techniken konzentrieren, um diese Modelle transparenter und verständlicher zu machen. Methoden wie Aufmerksamkeitsvisualisierung, Saliency Maps und modellspezifische Erklärungen werden dabei helfen, Erkenntnisse darüber zu gewinnen, wie LLMs zu ihren Entscheidungen kommen. Dadurch wird das Vertrauen der Nutzer gestärkt und das Debuggen und Verbessern von Modellen wird verbessert.
Große Sprachmodelle sind nur eine Komponente komplexer KI-Systeme. In Zukunft werden LLMOPs über die Feinabstimmung und den Einsatz einzelner LLMs hinausgehen und eine nahtlose Integration mit anderen KI-Technologien umfassen. Diese Integration wird multimodale KI-Systeme ermöglichen, die Funktionen zur Bild-, Sprach- und Sprachverarbeitung kombinieren, um ganzheitlichere und leistungsfähigere KI-Lösungen zu entwickeln.
Die Entwicklung von Large Language Models hat die Verarbeitung natürlicher Sprache revolutioniert und bahnbrechende KI-Anwendungen ermöglicht. Ihr effektives Management erfordert jedoch spezielle Praktiken und Prozesse, die unter das Dach von LLMOPs fallen.
LLMops spielt eine entscheidende Rolle bei der Bewältigung der Herausforderungen bei der Entwicklung, Bereitstellung und Wartung von LLMs. Durch die Einhaltung von Best Practices, die Einführung spezialisierter Tools und Plattformen und den Einsatz fortschrittlicher Techniken können LLMOps-Teams rechnerische Herausforderungen bewältigen, die Datenqualität sicherstellen und die Modellleistung optimieren.
Da der Bereich der KI weiterhin rasant voranschreitet, wird LLMops weiterhin an der Spitze der Innovation stehen. Zukünftige LLMOP-Trends werden sich auf Techniken zum Schutz der Privatsphäre, Modelloptimierung und Erklärbarkeit konzentrieren, um ethischen Bedenken und regulatorischen Anforderungen Rechnung zu tragen. Open-Source-Beiträge werden die Zusammenarbeit und den Wissensaustausch innerhalb der LLMOPS-Community fördern und die Entwicklung robusterer Tools und Frameworks vorantreiben.
Darüber hinaus wird die Integration großer Sprachmodelle mit anderen KI-Technologien zu aufregenden Fortschritten führen und multimodale KI-Systeme mit transformativen Fähigkeiten ermöglichen. Im Zuge der Weiterentwicklung wird LLMOPs eine entscheidende Rolle dabei spielen, das volle Potenzial großer Sprachmodelle auszuschöpfen und sie in vielfältigen realen Anwendungen zugänglicher, effizienter und verantwortungsbewusster zu machen.
Zusammenfassend lässt sich sagen, dass LLMOPs das Rückgrat eines erfolgreichen Large Language Model-Managements sind. Es stellt sicher, dass sie verantwortungsbewusst eingesetzt werden und ihr Potenzial bei der Gestaltung der Zukunft der KI entfalten. Während die KI weiter voranschreitet, wird LLMops den Weg für effizientere, vertrauenswürdigere und transformativere sprachbasierte KI-Anwendungen ebnen.
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, das es ML-Teams ermöglicht, Modelle in 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden ein Rollback durchzuführen, bereitzustellen und zu überwachen. Falls Sie versuchen, MLOps in Ihrer Organisation zu nutzen, würden wir uns freuen, mit Ihnen zu chatten und Notizen auszutauschen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




