

May 23, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Large Language Models (LLMs) haben die KI-Welt im Sturm erobert — aber sie sind erst der Anfang. Die wahre Magie entsteht, wenn sich LLMs zu Agenten entwickeln: intelligente, zielorientierte Systeme, die selbstständig argumentieren, Entscheidungen treffen und Maßnahmen ergreifen können. LLM-Agenten verändern die Art und Weise, wie wir KI-Produkte entwickeln, und ermöglichen alles, von automatisierten Forschungsassistenten bis hin zu komplexen, mehrstufigen Aufgabenlösern. In diesem ultimativen Leitfaden werden wir aufschlüsseln, was LLM-Agenten sind, wie sie arbeiten, welche Typen, reale Anwendungsfälle und die Herausforderungen, mit denen sie konfrontiert sind. Egal, ob Sie Entwickler, Gründer oder KI-Enthusiast sind — dieser Leitfaden vermittelt Ihnen ein kristallklares Verständnis der Zukunft intelligenter Agenten.
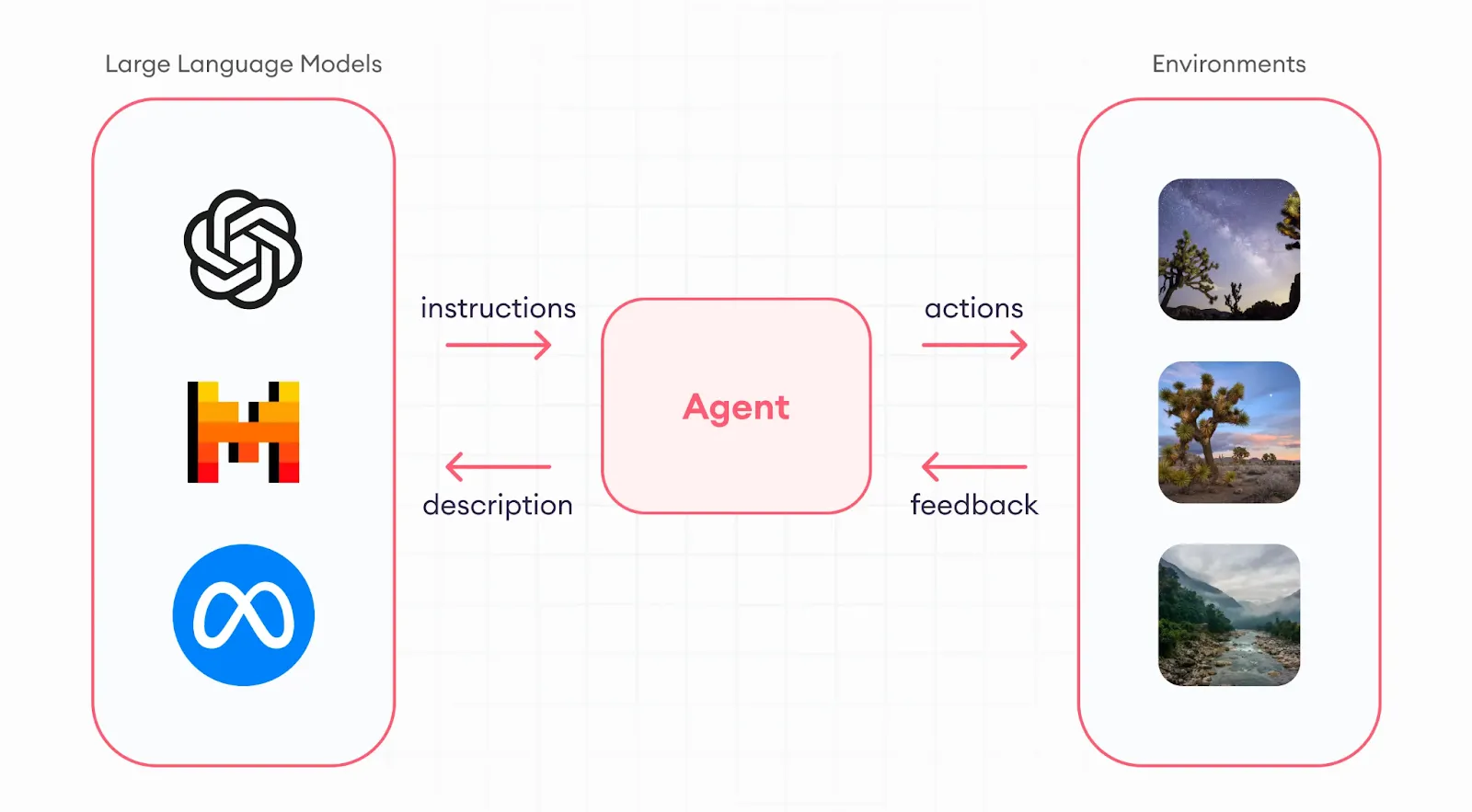
LLM-Agenten sind intelligente Systeme, die auf Large Language Models aufbauen und darauf ausgelegt sind, nicht nur auf Aufforderungen zu reagieren, sondern auch Maßnahmen zu ergreifen. Sie können planen, argumentieren, Tools verwenden, das Gedächtnis behalten und autonom arbeiten, um Aufgaben zu erledigen, die aus mehreren Schritten bestehen. Einfach ausgedrückt: Sie verwandeln passive LLMs in zielorientierte KI-Einheiten.
Während ein Standard-LLM wie GPT-4 oder Claude isoliert auf eine einzelne Aufforderung reagiert, hat ein LLM-Agent ein Ziel und einen fortlaufenden Prozess: Er bewertet die Aufgabe, entscheidet, was als Nächstes zu tun ist, führt Aktionen aus (z. B. das Aufrufen eines Tools oder das Durchsuchen einer Datenbank), beobachtet das Ergebnis und fährt fort, bis das Ziel erreicht ist.
Dies ist möglich, weil Agenten dem Basissprachenmodell mehrere Ebenen hinzufügen:
LLM-Agenten arbeiten, indem sie Struktur-, Gedächtnis- und Entscheidungsfähigkeiten auf einem grundlegenden Large Language Model aufbauen. Auf einer übergeordneten Ebene folgt ein LLM-Agent einer Schleife von Sinn, Denken und Handeln — er beobachtet seine Umgebung oder Eingaben, überlegt über den nächsten Schritt und führt Aktionen aus, um ein definiertes Ziel zu erreichen.
Der Workflow beginnt in der Regel mit einer Benutzerabfrage oder Aufgabe. Anstatt wie bei einem herkömmlichen LLM sofort zu antworten, unterteilt der Agent die Aufgabe, bestimmt, ob externe Tools benötigt werden, entscheidet, welche Maßnahmen zu ergreifen sind, und interagiert weiter mit der Umgebung, bis das Ziel erreicht ist. Jeder dieser Schritte hängt von einer Wiederholung ab LLM-Inferenz, wobei das Modell den Zwischenkontext bewertet, bevor es über die nächste Aktion entscheidet.
Wichtige Schritte im Arbeitsablauf eines LLM-Agenten:
Initialisierung der Aufgabe
Der Agent erhält Eingaben oder ihm wird ein Ziel zugewiesen, z. B. „Einen Konkurrenzbericht erstellen“ oder „ein Meeting basierend auf dem E-Mail-Kontext buchen“.
Planung
Es verwendet das LLM, um einen Plan zu erstellen, oft indem es die Schritte in natürlicher Sprache durchdenkt oder aus vordefinierten Optionen auswählt.
Werkzeugauswahl und Aufruf
Wenn Tools wie Suchmaschinen, APIs, Code-Interpreter oder Datenbanken verfügbar sind, entscheidet der Agent, welche Tools verwendet werden sollen, und führt strukturierte Aufrufe durch, um auf sie zuzugreifen.
Beobachtungs- und Feedback-Schleife
Sobald ein Tool ein Ergebnis zurückgibt, wertet der Agent die Ausgabe aus. Es entscheidet, ob die Informationen ausreichen, ob weitere Maßnahmen erforderlich sind oder ob die Aufgabe abgeschlossen ist.
Speicher (optional)
In fortgeschritteneren Konfigurationen behält der Agent das Kurz- oder Langzeitgedächtnis bei, um frühere Interaktionen zu verfolgen, Wissen zu speichern oder Benutzerprofile zu erstellen.
Iteration bis zur Zielerreichung
Diese Schleife — Planen, Handeln, Beobachten — setzt sich fort, bis der Agent sein beabsichtigtes Ergebnis erreicht oder eine Kündigungsbedingung erreicht.
Da sich LLM-Agenten ständig weiterentwickeln, werden sie in einer Vielzahl von Formen entworfen, die auf Komplexität, Autonomie und Zweck basieren. Obwohl alle Agenten auf der Grundlage eines umfassenden Sprachmodells aufgebaut sind, variiert die Art und Weise, wie sie Aufgaben planen, mit Tools interagieren und Aufgaben erledigen, erheblich. Im Großen und Ganzen können LLM-Agenten in verschiedene Typen eingeteilt werden:
Aufgabenspezifische Agenten
Diese Agenten sind so konzipiert, dass sie genau definierte, eng begrenzte Aufgaben ausführen. Sie folgen voreingestellten Arbeitsabläufen oder Logiken, profitieren aber dennoch von der Flexibilität eines LLM, um Randfälle oder Unklarheiten zu behandeln. Zum Beispiel:
Sie werden häufig in der Produktion verwendet, da sie einfacher zu testen, zu validieren und zu kontrollieren sind.
Autonome Agenten
Diese Agenten arbeiten mit minimalem menschlichem Eingreifen und können entscheiden, wie eine Aufgabe angegangen werden soll. Ausgehend von einem allgemeinen Ziel wie „Markttrends untersuchen und einen Bericht verfassen“ plant der Agent den Prozess, sammelt Daten, analysiert sie und erstellt einen Bericht — ganz alleine.
Autonome Agenten enthalten typischerweise Speicher, rekursive Schleifen und sogar Selbstkorrekturmechanismen. AutoGPT und BabyAGI sind Beispiele für Open-Source-Projekte, die dieses Verhalten von Agenten demonstrieren.
Agenten, die Tools verwenden
Diese Kategorie umfasst Agenten, die zur Erreichung ihrer Ziele in hohem Maße auf externe Tools, APIs und Umgebungen angewiesen sind. Sie sind zwar nicht vollständig autonom, aber sie zeichnen sich durch das Aufrufen von Funktionen, das Abrufen von Daten oder das Ausführen von Skripten aus, wenn dies erforderlich ist.
Diese Agenten verwenden Strategien wie ReACT (Reasoning + Acting) oder den Funktionsaufruf von OpenAI, um zu entscheiden:
Sie eignen sich ideal für Unternehmensszenarien, in denen der Agent CRMs, Datenbanken oder interne APIs integrieren muss.
Systeme mit mehreren Agenten
Anstatt dass ein Agent alles erledigt, arbeiten mehrere Agenten mit speziellen Rollen zusammen, um eine komplexe Aufgabe zu lösen. Ein Agent könnte beispielsweise Recherchen sammeln, ein anderer könnte Daten verifizieren und ein dritter könnte Erkenntnisse zusammenfassen. Sie kommunizieren, geben Kontext weiter und lösen Konflikte, wenn nötig.
Frameworks wie CrewAI und MetaGPT ermöglichen eine solche Koordination zwischen mehreren Agenten.
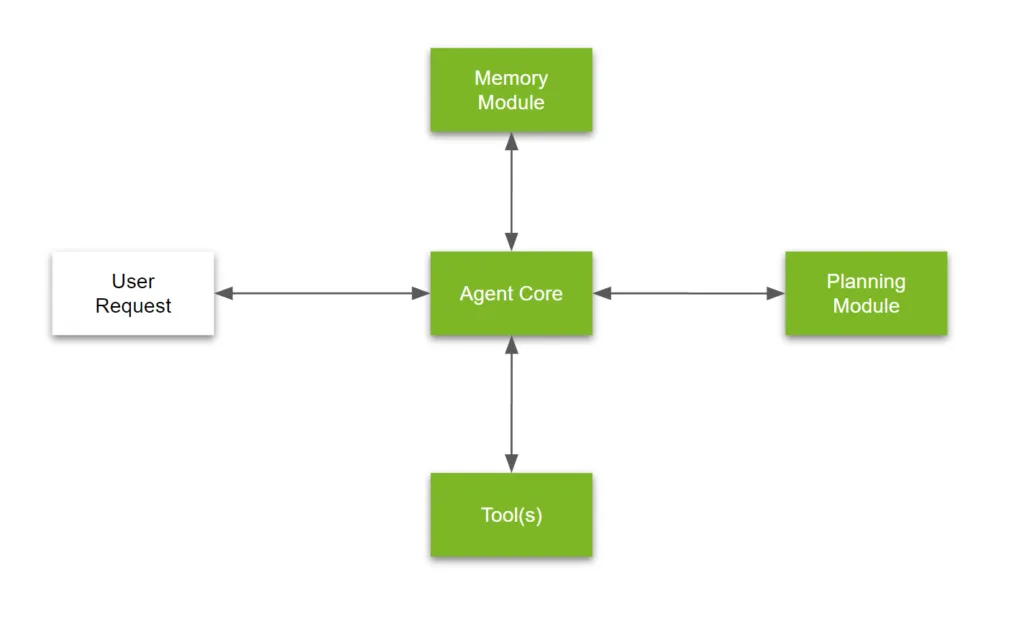
Ein LLM-Agent ist kein einzelnes Modell oder Skript — es ist ein modulares System, das darauf ausgelegt ist, autonom zu denken, sich zu erinnern, zu interagieren und zu handeln. Diese Architektur besteht in der Regel aus vier Kernkomponenten: dem Agentenkern, dem Speichermodul, den Tools und dem Planungsmodul. Diese Komponenten arbeiten zusammen, um aus einem reinen Sprachmodell einen leistungsfähigen, zielorientierten Agenten zu machen.
1. Agent Core
Im Mittelpunkt des Agenten steht das Sprachmodell selbst — oft ein Grundmodell wie GPT-4, Claude, LLama 2 oder Mistral. Diese Komponente ist dafür verantwortlich, Eingaben zu verstehen, Antworten zu generieren und anhand von Aufgaben Überlegungen anzustellen.
Das Modell ist zwar leistungsstark, aber für sich genommen reaktiv. Es braucht unterstützende Logik, um proaktiv zu werden. Der Agentenkern fungiert als „Gehirn“ und interpretiert Aufforderungen und Anweisungen. Es hängt jedoch von den anderen Modulen ab, um Aktionen auszuführen, sich den Kontext zu merken und komplexe Probleme zu lösen.
2. Speichermodul
Der Speicher ermöglicht es dem Agenten, Informationen über Schritte, Interaktionen oder Sitzungen hinweg zu speichern. Dadurch wird der Agent im Laufe der Zeit anpassungsfähiger und personalisierter.
Dieses Modul kann je nach den Bedürfnissen des Agenten mithilfe einer Vektordatenbank, eines Dokumentenspeichers oder sogar eines strukturierten Schlüsselwertspeichers implementiert werden.
3. Werkzeuge
Die Tools-Ebene bietet Agenten praktische Vorteile. Sie ermöglicht es dem Agenten, über die Sprachgenerierung hinauszugehen und tatsächlich Maßnahmen zu ergreifen.
Zu den Tools können gehören:
Wenn der Agent eine Lücke in seinen eigenen Kenntnissen oder Fähigkeiten feststellt, kann er ein Tool aufrufen, das Ergebnis verarbeiten und mit der Aufgabe fortfahren. Dies bietet LLM-Agenten eine Plugin-ähnliche Erweiterbarkeit, die sich an die Anwendungsfälle im Unternehmen anpassen lässt.
4. Modul Planung
Hier wird der Agent zielorientiert. Das Planungsmodul ermöglicht es ihm, komplexe Aufgaben aufzuschlüsseln, die Reihenfolge der Operationen festzulegen und Aktionen intelligent abzuarbeiten.
Es behandelt:
Ohne Planung sind Agenten nur One-Shot-Responder. Damit können sie mit Unsicherheiten umgehen, iterieren und sich selbst korrigieren.
Eine der wichtigsten Funktionen, die LLM-Agenten von Standardsprachmodellen unterscheidet, ist ihre Fähigkeit, Tools zu nutzen. Auf diese Weise können Agenten mit der realen Welt interagieren und aktuelle Informationen abrufen, Berechnungen durchführen, auf Datenbanken zugreifen oder Aktionen auslösen. Ohne Tools sind die Agenten auf ihr vortrainiertes Wissen beschränkt und bleiben rein reaktiv. Mit Tools werden sie zu interaktiven Systemen, die Aufgaben erledigen.
Auf einer hohen Ebene folgt die Toolnutzung in LLM-Agenten einem einfachen Zyklus:
Toolabstraktion und -aufruf
Werkzeuge werden dem Agenten in der Regel als Funktionssignaturen oder Werkzeugschemas zur Verfügung gestellt. Diese können benutzerdefiniert oder über ein Framework wie LangChain, Function Calling von OpenAI, ReAct oder AgentOps registriert werden. Der Agent führt Code nicht direkt aus, sondern generiert einen strukturierten Funktionsaufruf (wie ein JSON-Objekt), der von einer Ausführungsebene im Backend verarbeitet wird.
Stellen Sie sich zum Beispiel ein Tool zur Wetterkontrolle vor:
{
„tool“: „get_weather“,
„Eingaben“: {
„location“: „New York City“
}
}
Der Agent stellt fest, dass Wetterinformationen benötigt werden, erstellt diesen Tool-Aufruf, und dann führt das Backend die Funktion aus (in diesem Fall ein API-Aufruf). Das Ergebnis wird an den Agentenkern zurückgemeldet, der die Argumentation fortsetzt.
Wann und warum Werkzeuge verwendet werden
LLM-Agenten rufen Tools auf, wenn:
Tools sind die Brücke des Agenten zu externen Systemen. Sie erweitern die Fähigkeiten des Agenten von einem „intelligenter Textgenerator“ zu einem „Handlungsassistent“.
Strategie zur Werkzeugnutzung: ReACT und Planung
Die meisten modernen Agenten verwenden das ReAct-Paradigma (Reason + Act). Der Agent überlegt, was als Nächstes zu tun ist, wählt ein Tool aus, beobachtet die Ausgabe und fährt fort, bis die Aufgabe erledigt ist. Dieser enge Kreislauf ermöglicht eine mehrstufige Problemlösung, Validierung und Korrektur.
In fortgeschritteneren Systemen entscheiden Planungsmodule, welches Tool in jedem Schritt eines Workflows verwendet werden soll — wie ein Entscheidungsbaum, der dynamisch auf der Grundlage des Aufgabenkontextes erstellt wird.
LLM-Agenten stellen einen großen Fortschritt in der Art und Weise dar, wie KI bei realen Aufgaben eingesetzt werden kann. Durch die Kombination der Argumentationskraft großer Sprachmodelle mit Gedächtnis, Planung und Werkzeuggebrauch entwickeln sich Agenten von statischen Assistenten zu autonomen Mitarbeitern. Dieser architektonische Wandel bringt eine Reihe greifbarer Vorteile sowohl in technischen als auch in geschäftlichen Bereichen mit sich.
Autonomie und mehrstufiges Denken
Im Gegensatz zu herkömmlichen LLMs, die auf einzelne Eingabeaufforderungen reagieren, können Agenten komplexe Arbeitsabläufe verwalten, indem sie Aufgaben aufteilen, Tools aufrufen und iterieren, bis die Arbeit erledigt ist. Aufgrund dieser Autonomie eignen sie sich für die Ausführung mehrstufiger Geschäftsprozesse — wie das Analysieren eines Datensatzes, das Zusammenfassen von Erkenntnissen, das Erstellen einer Präsentation und das Versenden der Ergebnisse per E-Mail — und das alles ohne menschliches Eingreifen.
Interaktion mit Systemen in Echtzeit
Durch die Toolintegration können Agenten Live-Daten abrufen, mit APIs interagieren und sogar Dateien oder Datenbanken bearbeiten. Diese Fähigkeit, auf aktuelle Informationen zuzugreifen, beseitigt die Einschränkungen des statischen Wissens, das vortrainierten Modellen innewohnt. Für Unternehmen bedeutet dies, dass Agenten mit CRMs, Analysesystemen, Kalendern und internen Tools interagieren können, sodass sie sofort einsatzbereit sind.
Kontextbewusstsein und Personalisierung
Speichermodule geben Agenten die Möglichkeit, den Kontext interaktionsübergreifend beizubehalten. Auf diese Weise können sie sich Benutzerpräferenzen merken, frühere Schritte verfolgen und die Ergebnisse personalisieren. Im Laufe der Zeit können Agenten ihren Ton, ihren Inhalt und ihre Empfehlungen auf der Grundlage des erlernten Nutzerverhaltens anpassen und so ein menschlicheres Erlebnis bieten.
Skalierbarkeit für alle Anwendungsfälle
LLM-Agenten sind hochgradig zusammensetzbar. Derselbe Agentenkern kann abteilungsübergreifend (z. B. Vertrieb, Marketing, Finanzen) wiederverwendet werden, indem die Tools und die dazugehörende Planungslogik geändert werden. Diese Modularität beschleunigt die Amortisierungszeit und reduziert überflüssigen Entwicklungsaufwand.
Höhere Effizienz und Kosteneinsparungen
Durch die Automatisierung sich wiederholender oder analytischer Aufgaben setzen Agenten die menschliche Bandbreite frei. Teams können sich auf wichtigere Strategien und Entscheidungen konzentrieren, während sich die Agenten um operative Aufgaben kümmern — was zu messbaren Verbesserungen der Produktivität und der Betriebskosten führt.
LLM-Agenten sind leistungsstarke Systeme, aber ihre Komplexität bringt mehrere technische und betriebliche Herausforderungen mit sich. Von der Entscheidungsgenauigkeit bis hin zur Systemzuverlässigkeit erfordert der Aufbau robuster, produktionsbereiter Agenten mehr als nur das Einbinden eines LLM in eine Prompt-Schleife. Im Folgenden sind einige der häufigsten Herausforderungen aufgeführt — zusammen mit einfachen Beispielen, die ihre Auswirkungen veranschaulichen.
Halluzination und Entscheidungsfehler
LLMs können immer noch sichere, aber falsche oder irreführende Informationen generieren — ein Phänomen, das als Halluzination bekannt ist. In einer Agentenpipeline kann dies zu fehlerhaften Aktionen führen.
Werkzeugmissbrauch und Aufruffehler
Agenten müssen APIs oder Tools mithilfe strukturierter Eingaben korrekt aufrufen. Das Generieren des richtigen Formats oder die dynamische Bearbeitung von Randfällen ist jedoch fehleranfällig.
Latenz und Kostenaufwand
Mehrstufiges Denken und Tool-Ketten führen zu hohen Latenz- und Modelltokenkosten, insbesondere wenn für jeden Schritt große Modelle verwendet werden.
Komplexität des Speichers
Es ist eine ständige Herausforderung, zu verwalten, woran man sich erinnern und was zu vergessen ist und wie relevante Erinnerungen effizient abgerufen werden können.
Sicherheit, Datenschutz und Leitplanken
Agenten berühren häufig sensible Systeme und Daten. Ohne Schutzmaßnahmen können sie interne Logik offenlegen oder bei Antworten private Daten preisgeben.
Debugging und Beobachtbarkeit
Agenten sind nicht deterministisch. Ohne geeignete Tools ist es schwierig nachzuvollziehen, warum ein Agent versagt hat oder wie er eine Entscheidung getroffen hat.
LLM-Agenten sind nicht mehr nur theoretische Konzepte — sie werden bereits branchenübergreifend eingesetzt, um autonome Aufgaben auszuführen, Arbeitsabläufe zu automatisieren und intelligent mit Benutzern zu interagieren. Schauen wir uns einige praktische Beispiele an, die veranschaulichen, wie LLM-Agenten in realen Umgebungen funktionieren.
AutoGPT und BabyAGI
Diese Open-Source-Projekte demonstrierten die Idee autonomer Agenten, die in der Lage sind, Aufgaben ohne menschliche Aufsicht auszuführen. Ausgehend von einem übergeordneten Ziel wie „Wettbewerber analysieren und eine Strategie entwickeln“ plant AutoGPT Schritte, durchsucht das Internet, schreibt Zusammenfassungen, bewertet die Ergebnisse und passt seinen Plan iterativ an. Diese Agenten befinden sich zwar noch im Versuchsstadium und benötigen Leitplanken, aber sie weckten großes Interesse an autonomen Ablaufschleifen zur Aufgabenausführung.
LangChain-Agenten
LangChain bietet ein Framework zum Erstellen von Agenten mithilfe modularer Komponenten wie Eingabeaufforderungsvorlagen, Toolschnittstellen, Speicher und Planer. Ein Agent könnte beispielsweise komplexe Anfragen anhand einer Sammlung von PDFs beantworten, indem er relevante Dokumente abruft, Inhalte zusammenfasst und eine Antwort synthetisiert. LangChain macht es einfach, sowohl aufgabenspezifische Agenten als auch Agenten, die Tools verwenden, zu erstellen, indem Workflows definiert und APIs integriert werden, während Sie gleichzeitig Folgendes verstehen LangChain gegen LangGraph hilft Teams bei der Entscheidung, wann eine grafbasierte Orchestrierung für die mehrstufige Agentenausführung besser geeignet ist.
OpenAI-Agenten, die Funktionen aufrufen
Der Funktionsaufruf von OpenAI ermöglicht strukturierte, Tools verwendende Agenten. Entwickler definieren Tools als JSON-Schemas, und das Modell entscheidet, wann und wie sie aufgerufen werden. Ein praktischer Anwendungsfall ist ein Kundendienstmitarbeiter, der, sobald er eine Absicht erkennt, automatisch den Bestellstatus abruft, Lieferinformationen aktualisiert oder ein Support-Ticket einreicht — ohne manuelles API-Engineering.
CrewAI und MetaGPT
Diese Frameworks führen die Zusammenarbeit mehrerer Agenten ein, bei der Agenten bestimmte Rollen — wie Entwickler, Prüfer oder Stratege — zugewiesen werden und miteinander kommunizieren, um komplexe Aufgaben zu lösen. In MetaGPT erstellt beispielsweise ein Projektmanager-Agent die Anforderungen, ein Entwickleragent schreibt den Code und ein Tester-Agent validiert ihn — was effektiv den Arbeitsablauf eines echten Softwareteams widerspiegelt.
Die meisten LLM-Agenten funktionieren hervorragend in einer Sandbox — fallen aber in freier Wildbahn schnell auseinander. Sie halluzinieren, scheitern bei Toolaufrufen, haben mit Latenz zu kämpfen und bieten wenig Transparenz, wenn etwas kaputt geht. Es ist einfach, einen intelligenten Agenten zu entwickeln. Es ist der schwierige Teil, ihn in der Produktion zuverlässig, skalierbar und sicher zu machen.
Hier kommt TrueFoundry ins Spiel. Es bietet ein Komplettpaket LLMOPS-Plattform entwickelt, um vielversprechende Prototypen in Agentensysteme der Enterprise-Klasse umzuwandeln, die schnell, beobachtbar, konform und skalierbar sind.
TrueFoundry ermöglicht es Teams, Agenten einzusetzen, die mit LangChain, AutoGen, CrewAI oder benutzerdefinierten Architekturen erstellt wurden — ohne sich Gedanken über die Komplexität der Infrastruktur machen zu müssen. Ganz gleich, ob es sich um einen Einzelagenten oder eine Pipeline mit mehreren Agenten handelt, TrueFoundry bietet das Orchestrierungs-Backbone für die Verwaltung von Workflows in Cloud- oder lokalen Umgebungen.
Um Agenteninteraktionen in Echtzeit zu ermöglichen, bietet die Plattform eine optimierte Modellbereitstellung mit leistungsstarken Backends wie vLLM und sGLang. In Kombination mit Autoscaling und intelligenter Ressourcenbereitstellung können Agenten schneller reagieren und gleichzeitig die Kosten für Inferenzen unter Kontrolle halten.
Agenten, die externe Tools oder APIs von Drittanbietern aufrufen, profitieren vom einheitlichen API-Gateway von TrueFoundry. Es bietet:
LLM-Agenten gestalten die Art und Weise, wie wir mit KI interagieren, neu — von reaktiven Chatbots bis hin zu autonomen Systemen, die in der Lage sind, zu denken, zu planen und zu handeln. Ihre Architektur, die auf Sprachmodellen, Tools, Speicher und Orchestrierung basiert, entwickelt sich rasant weiter, um komplexere, reale Aufgaben zu unterstützen. Die Möglichkeiten sind zwar riesig, aber der Einsatz von Agenten in der Produktion erfordert mehr als clevere Eingabeaufforderungen — es erfordert eine skalierbare Infrastruktur, Beobachtbarkeit und ein sorgfältiges Systemdesign.
Unternehmen setzen LLM-Agenten ein, um komplexe, mehrstufige Workflows zu automatisieren, die eine dynamische Entscheidungsfindung erfordern. Diese Systeme verwenden Sprachmodelle, um Probleme zu analysieren und Aktionen mithilfe externer Tools auszuführen. Sie bieten autonome Ausführungsfunktionen, die herkömmliche, statische Chatbots in skalierbaren Produktionsumgebungen nicht erreichen können.
LLM-Agenten haben oft mit Denkschleifen, Werkzeugfehlern oder Datenhalluzinationen zu kämpfen, wenn sie in uneingeschränkten Umgebungen arbeiten. Diese Fehler treten in der Regel auf, wenn dem Agenten klare Anweisungen fehlen oder er auf unerwartete API-Antworten stößt. Die Implementierung umfassender Beobachtbarkeit hilft den Teams, die Schritte der Agenten nachzuverfolgen und diese logischen Störungen zu beheben, um die Zuverlässigkeit der Produktion zu gewährleisten.
Die Zuverlässigkeit von LLM-Agenten hängt von der Komplexität der Aufgabe und den zugrunde liegenden Modellfunktionen ab. Ein einfacher Datenabruf ist zwar äußerst zuverlässig, komplexe Überlegungen erfordern jedoch strenge Bewertungsrahmen. Die Überwachung auf Plattformebene ermöglicht es den Teams, diese Erfolgsraten zu messen und die Aufforderungen der Agenten systematisch zu wiederholen, um die Genauigkeit der Schlussfolgerungen zu erhöhen.
Ein LLM-Agent bezieht sich speziell auf ein autonomes System, das ein großes Sprachmodell als zentrale Argumentationsmaschine verwendet. Während „KI-Agent“ eine breitere Kategorie ist, die verschiedene Algorithmen umfasst, zeichnen sich LLM-basierte Versionen durch das Verständnis natürlicher Sprache und die Planung komplexer Aufgaben aus. Sie wandeln textbasierte Anweisungen in umsetzbare Schritte für integrierte Softwaretools um.
Während viele moderne Systeme LLM-Agenten sind, verwenden einige KI-Agenten traditionelles Reinforcement Learning oder eine feste regelbasierte Logik. Die Integration von LLMs ermöglicht es den Agenten jedoch, mit weitaus vielfältigeren und unstrukturierten Informationen umzugehen. Unternehmensplattformen wie TrueFoundry unterstützen Hybridarchitekturen und geben Teams so die Flexibilität, die optimale Intelligenz für spezifische Workflows auszuwählen, bei denen viel auf dem Spiel steht.
MCP-Agenten konzentrieren sich darauf, LLMs über das Model Context Protocol mit externen Tools oder Daten zu verbinden und agieren dabei als kontrollierte Vermittler. LLM-Agenten arbeiten dagegen autonom und treffen ohne direkte menschliche Anweisung Entscheidungen, führen Aufgaben aus oder interagieren mit mehreren Tools, wobei sie Argumentation und Workflow-Orchestrierung nutzen.
Zu den Risiken gehören die Generierung ungenauer oder voreingenommener Ergebnisse, das Durchsickern vertraulicher Informationen, das Treffen autonomer Entscheidungen, die gegen Richtlinien verstoßen, oder der Missbrauch integrierter Tools. Ohne angemessene Aufsicht können LLM-Agenten Fehler verbreiten, rechtliche Verbindlichkeiten nach sich ziehen oder die Sicherheit gefährden, weshalb Governance-, Überwachungs- und Sicherheitsmechanismen für Unternehmensumgebungen unverzichtbar sind.
Wenn sie unbeaufsichtigt bleiben, führen LLM-Agenten die zugewiesenen Aufgaben innerhalb ihrer programmierten Einschränkungen weiter aus. Sie können Workflows iterieren, verbundene Tools abfragen oder Ergebnisse autonom verfeinern. Ohne menschliche Aufsicht oder Leitplanken können sie jedoch von den angestrebten Zielen abweichen, zu inkonsistenten oder unsicheren Ergebnissen führen und Kontextänderungen nicht erkennen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




