

May 22, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Vektoreinbettungen sind ausgeklügelte Tools, mit denen komplexe und oft nichtnumerische Daten — wie Text, Bilder und Audio — in ein numerisches Format konvertiert werden, das Algorithmen für maschinelles Lernen verstehen und verarbeiten können. Diese Transformation wird erreicht, indem die Daten als Punkte in einem hochdimensionalen Raum dargestellt werden. Jede Dimension entspricht einem Merkmal der Daten und erfasst dessen einzigartige Eigenschaften.
Im Bereich der Textverarbeitung können beispielsweise Wörter oder Phrasen in Vektoren umgewandelt werden, wobei jeder Vektor die semantische und syntaktische Essenz des Wortes darstellt. Ähnlich können bei der Bildverarbeitung durch Einbettungen verschiedene visuelle Merkmale wie Kanten, Farben oder Texturen erfasst werden. Das Schöne an Vektoreinbettungen liegt in ihrer Fähigkeit, die Beziehungen und Ähnlichkeiten zwischen Datenpunkten aufrechtzuerhalten, was für Aufgaben wie Ähnlichkeitssuchen, Clustering und Klassifikation von entscheidender Bedeutung ist.
Vektoreinbettungen sind in zahlreichen Anwendungen für maschinelles Lernen unverzichtbar und verbessern die Effizienz und Effektivität verschiedener Algorithmen erheblich. Im Zusammenhang mit Empfehlungssystemen helfen Einbettungen dabei, Elemente zu identifizieren, die den früheren Präferenzen eines Benutzers ähneln, und so die Vorschläge zu personalisieren, um die Nutzerbindung und -zufriedenheit zu verbessern. Im NLP sind Einbettungen von zentraler Bedeutung für Aufgaben wie maschinelle Übersetzung und Stimmungsanalyse, bei denen die Beziehung zwischen Wörtern verstanden und quantifiziert werden muss.
Darüber hinaus spielen Einbettungen in Bild- und Spracherkennungssystemen eine entscheidende Rolle, sodass diese Technologien visuelle und auditive Eingaben mit bemerkenswerter Genauigkeit interpretieren und darauf reagieren können. Diese Fähigkeit ist nicht nur für benutzerorientierte Anwendungen wie digitale Assistenten und automatische Kundenbetreuung von entscheidender Bedeutung, sondern auch in Bereichen wie der medizinischen Bildgebung, in denen präzise und schnelle Interpretationen bei der Diagnose helfen können.
Vektoreinbettungen transformieren abstrakte, komplexe Daten in ein strukturiertes Format und machen sie für Analysen und Interpretationen zugänglich. Diese Transformation ist der Schlüssel zur Entwicklung von KI-Lösungen, die sowohl skalierbar als auch anpassungsfähig sind, was Vektoreinbettungen zu einer Eckpfeilertechnologie des modernen maschinellen Lernens macht.
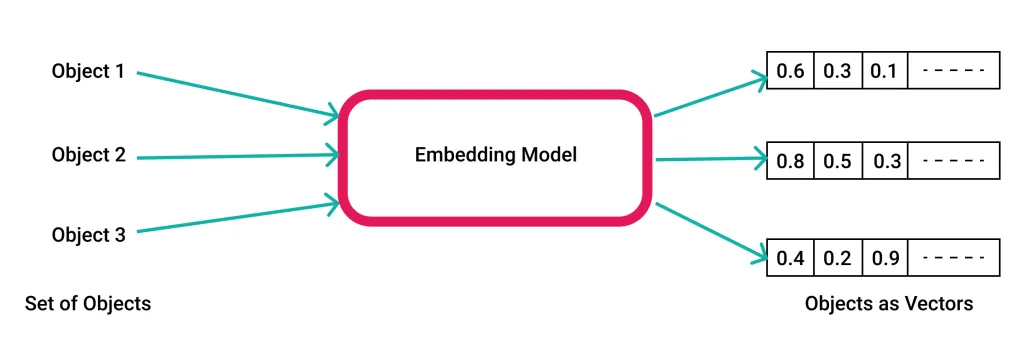
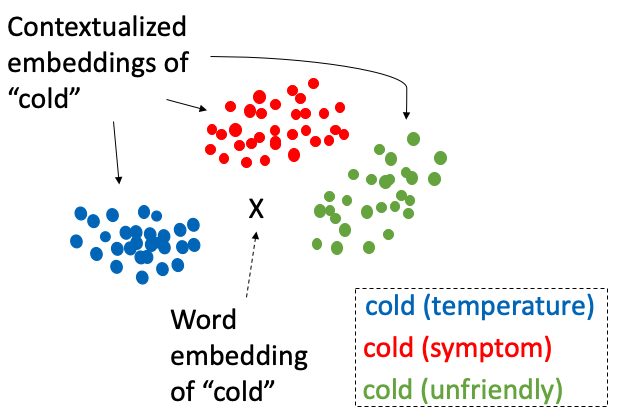
Vektoreinbettungen sind mathematische Repräsentationen, bei denen Objekte wie Wörter, Bilder oder Töne Vektoren reeller Zahlen in einem vordefinierten Vektorraum zugeordnet werden. Jeder Punkt in diesem Raum steht für ein bestimmtes Objekt, und das Layout dieser Punkte spiegelt die zugrunde liegenden Beziehungen und Eigenschaften der Objekte wider. Im Fall von Worteinbettungen haben Wörter, die in ähnlichen Kontexten vorkommen, beispielsweise Vektoren, die im Vektorraum nahe beieinander liegen.
Diese Darstellungsmethode ermöglicht die Übersetzung komplexer Daten in eine Sprache, die maschinelle Lernmodelle effizient verarbeiten können. Durch die Umwandlung von Daten in Vektoren helfen Einbettungen Modellen dabei, Muster zu erkennen, Vorhersagen zu treffen oder Erkenntnisse abzuleiten, deren Extraktion aus Rohdaten schwierig wäre.
Der Prozess der Umwandlung von Daten in Vektoreinbettungen umfasst mehrere Schritte, wobei in der Regel mit der Auswahl von Merkmalen begonnen wird, die die Objekte auf aussagekräftige Weise beschreiben. Diese Merkmale können vom Vorhandensein bestimmter Wörter in einem Text bis hin zur Intensität und Häufigkeit von Pixeln in einem Bild reichen. Im nächsten Schritt werden diese Merkmale in ein numerisches Format codiert, das die Essenz der Daten effektiv erfasst.
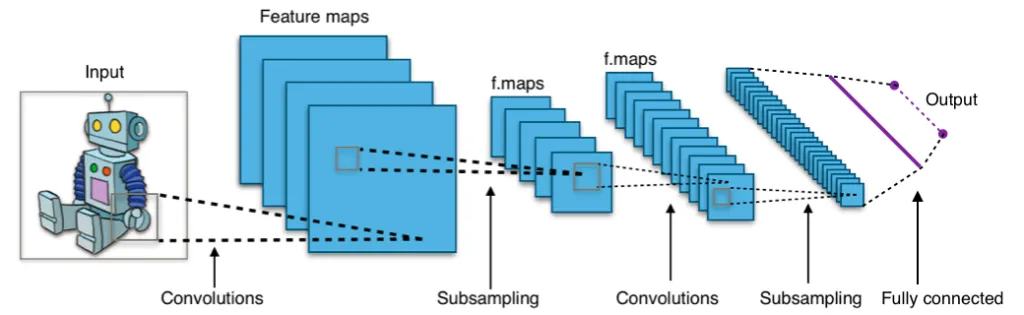
Beim Umgang mit Text ist es beispielsweise üblich, Modelle wie Word2Vec oder BERT zu verwenden, die die Kontexte analysieren, in denen Wörter vorkommen, und Wörtern mit ähnlichen Bedeutungen ähnliche numerische Vektoren zuweisen. Bei der Bildverarbeitung identifizieren Techniken wie Convolutional Neural Networks (CNNs) Muster und Strukturen innerhalb des Bildes und kodieren sie in ein Vektorformat.
Vektoreinbettungen sind vielseitig und können auf eine Vielzahl von Datentypen angewendet werden:
Vektoreinbettungen ermöglichen nicht nur die Verarbeitung und Analyse dieser unterschiedlichen Datentypen mithilfe von maschinellem Lernen, sondern verbessern auch die Genauigkeit und Leistung der darauf angewandten Algorithmen.
Vektoreinbettungen befinden sich in der Regel in einem hochdimensionalen Raum, was schwierig zu visualisieren sein kann, aber für die Erfassung der komplexen Beziehungen innerhalb der Daten von entscheidender Bedeutung ist. Ein hochdimensionaler Raum bezieht sich in diesem Zusammenhang auf einen mathematischen Raum mit mehr Dimensionen als die drei räumlichen Dimensionen, an die wir gewöhnt sind. Diese zusätzlichen Dimensionen ermöglichen Einbettungen zur Kodierung verschiedener Merkmale und Aspekte der Daten, wodurch eine reichhaltigere und nuanciertere Darstellung ermöglicht wird.
Die hohe Dimensionalität hilft dabei, Datenpunkte effektiv zu unterscheiden. Selbst wenn beispielsweise in einem hochdimensionalen Raum zwei Wörter wie „glücklich“ und „freudig“ ähnlich sind, können sie dennoch anhand ihrer Verwendung in unterschiedlichen Kontexten unterschieden werden, was als subtile Unterschiede in ihren Vektorkoordinaten dargestellt würde.
Entfernungsmetriken sind für den Nutzen von Vektoreinbettungen von grundlegender Bedeutung. Sie messen, wie ähnlich oder unähnlich sich zwei Datenpunkte innerhalb des Vektorraums befinden. Zu den häufig verwendeten Entfernungsmetriken gehören:
Diese Metriken sind entscheidend für Aufgaben wie Clustering, bei denen das Ziel darin besteht, ähnliche Elemente zu gruppieren, oder Suchen nach nächstgelegenen Nachbarn, bei denen die Elemente gefunden werden, die einem bestimmten Abfrageelement am nächsten oder ähnlichsten sind.
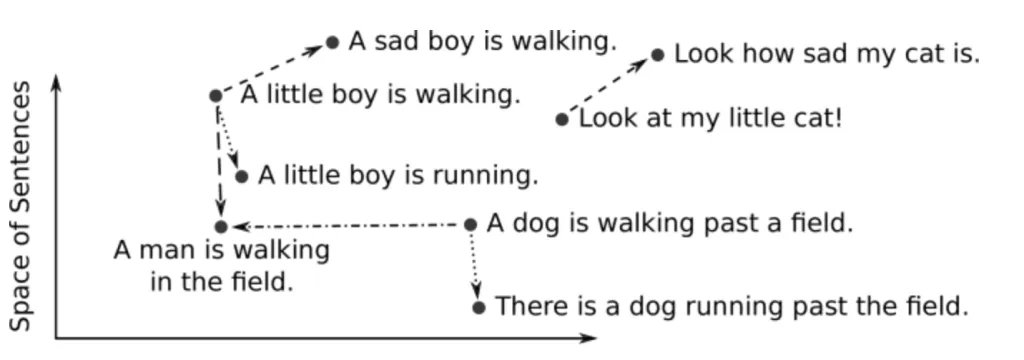
Vektoreinbettungen ermöglichen es uns, die Beziehungen zwischen verschiedenen Datenpunkten zu visualisieren und zu interpretieren, indem wir ihre Nähe im Vektorraum untersuchen. In einem gut konstruierten Modell zur Worteinbettung liegen beispielsweise Wörter mit ähnlichen Bedeutungen näher beieinander. Diese Nähe kann mithilfe von Techniken zur Reduzierung der Dimensionalität wie t-SNE oder PCA visualisiert werden. Dabei werden die hochdimensionalen Daten in zwei oder drei Dimensionen reduziert, die sich leicht grafisch darstellen und untersuchen lassen.
Diese Visualisierungen sind nicht nur hilfreich, um die Qualität der Einbettungen zu überprüfen, sondern dienen auch als leistungsstarkes Werkzeug, um die den Daten zugrunde liegenden Muster zu untersuchen und zu verstehen.
Das Feature-Engineering ist ein entscheidender Schritt bei der Erstellung effektiver Vektoreinbettungen, insbesondere wenn spezifisches Fachwissen genutzt werden kann, um die Leistung des Modells zu verbessern. Dieser Prozess beinhaltet die Auswahl, Änderung oder Erstellung von Merkmalen aus Rohdaten, die die daraus resultierenden Einbettungen für bestimmte Anwendungen aussagekräftiger und nützlicher machen.
In der medizinischen Bildgebung können beispielsweise Merkmale wie die Intensität von Pixeln, die Textur des Bildes und das Vorhandensein bestimmter Formen entscheidend sein. Anhand dieser technischen Funktionen erstellte Einbettungen können Modellen für maschinelles Lernen helfen, Anomalien zu erkennen oder Krankheiten genauer zu diagnostizieren, indem medizinisch relevante Muster in den Daten hervorgehoben werden.
Während Feature-Engineering auf manuellen Techniken und Fachwissen basiert, lernen automatisierte Lernmethoden mithilfe von Algorithmen, wie Einbettungen direkt aus Daten erstellt werden können. Dieser Ansatz ist besonders bei der Verarbeitung großer Datenmengen oder wenn manuelles Feature-Engineering nicht durchführbar ist, weit verbreitet.
Bei Textdaten lernen Modelle wie Word2Vec, GloVE und BERT automatisch Worteinbettungen, indem sie große Textkorpora analysieren. Diese Modelle erfassen semantische und syntaktische Wortbeziehungen auf der Grundlage ihrer Kontexte innerhalb des Korpus und erzeugen Einbettungen, die die Bedeutung von Wörtern effektiv darstellen können.
Im Bereich der Bildverarbeitung werden Convolutional Neural Networks (CNNs) verwendet, um automatisch Einbettungen zu generieren. Populäre Architekturen wie VGG und Inception sind so konzipiert, dass sie komplexe Bildmerkmale auf verschiedenen Abstraktionsebenen erfassen. Indem Bilder durch diese Netzwerke geleitet werden, erfasst jede Ebene verschiedene Aspekte des Bildes, was in einer umfassenden Einbettung gipfelt, die das gesamte Bild repräsentiert.
Für Audiodaten können Einbettungen aus Spektrogrammen erstellt werden — visuellen Darstellungen des Spektrums der Schallfrequenzen, die sich mit der Zeit ändern. Diese Einbettungen erfassen wichtige Eigenschaften des Audios, wie Tonhöhe, Ton und Rhythmus, die für Aufgaben wie Spracherkennung oder Klassifikation von Musikgenres von entscheidender Bedeutung sind.
Vektoreinbettungen sind besonders nützlich in Clustering-Anwendungen, bei denen das Ziel darin besteht, ähnliche Elemente anhand ihrer in den Einbettungen kodierten Merkmale zu gruppieren. Diese Fähigkeit ist in zahlreichen Bereichen von entscheidender Bedeutung, von der Organisation großer Datensätze bis hin zur Identifizierung von Mustern in Daten, die nicht sofort erkennbar sind.
Beispielsweise ermöglicht das Clustern ähnlicher Produkte im E-Commerce eine effizientere Bestandsverwaltung und verbesserte Kundenempfehlungssysteme. In ähnlicher Weise kann Clustering bei der Analyse sozialer Medien dazu beitragen, Nutzergruppen mit ähnlichen Interessen zu identifizieren, wodurch gezielte Werbung und Inhaltsbereitstellung verbessert werden.
Vektoreinbettungen sind ein integraler Bestandteil der Funktionsweise von Empfehlungssystemen, die in hohem Maße darauf angewiesen sind, Ähnlichkeiten zwischen Artikeln und Benutzern zu finden. Indem Nutzer und Produkte demselben Einbettungsbereich zugeordnet werden, können diese Systeme anhand der Nähe der Benutzer- und Artikelvektoren leicht erkennen, welche Produkte empfohlen werden sollten.
Auf Streaming-Plattformen wie Netflix oder Spotify helfen Einbettungen beispielsweise dabei, die Bereitstellung von Inhalten zu personalisieren und sicherzustellen, dass den Nutzern mit größerer Wahrscheinlichkeit Filme, Serien oder Musik präsentiert werden, die ihren früheren Vorlieben und Sehgewohnheiten entsprechen. Dies erhöht nicht nur die Nutzerzufriedenheit, sondern fördert auch das Engagement und die Kundenbindung.
Bei Klassifikationsaufgaben werden Vektoreinbettungen verwendet, um Datenpunkten auf der Grundlage der gelernten Repräsentationen Beschriftungen zuzuweisen. Diese Anwendung ist weit verbreitet in Bereichen wie der Spam-Erkennung, bei der E-Mails aufgrund ihrer Inhaltseinbettung als Spam oder nicht als Spam eingestuft werden, und in der Stimmungsanalyse, bei der Text als positiv, negativ oder neutral klassifiziert wird.
Darüber hinaus können im Gesundheitswesen Klassifikationsmodelle, die Einbettungen verwenden, dazu beitragen, Patientendiagnosen auf der Grundlage ihrer Symptome und Testergebnisse vorherzusagen, sodass Ärzte schnellere und genauere medizinische Entscheidungen treffen können.
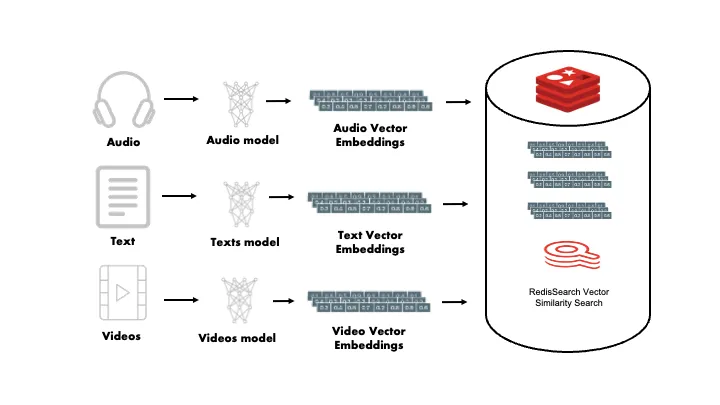
Vektoreinbettungen vereinfachen den Prozess der Ähnlichkeitssuche, bei dem Elemente in einem Datensatz gefunden werden, die einem Abfrageelement ähnlich sind. Diese Funktion ist für Aufgaben wie die Deduplizierung unerlässlich, bei denen ähnliche oder doppelte Dateneinträge identifiziert und zusammengeführt oder entfernt werden müssen.
Bei der Erkennung von Anomalien können Einbettungen dazu beitragen, Ausreißer in Daten zu identifizieren, die von der Norm abweichen, was für die Betrugserkennung oder die Netzwerksicherheit von entscheidender Bedeutung ist. In ähnlicher Weise ermöglichen Einbettungen bei der umgekehrten Bildsuche den Systemen, Bilder abzurufen, die einem Abfragebild visuell ähnlich sind. Dies ist in digitalen Medienbibliotheken und im Online-Handel nützlich.
Vektoreinbettungen bieten zwar erhebliche Vorteile, ihre Implementierung und Verwendung sind jedoch mit Herausforderungen verbunden, vor allem in Bezug auf die Rechenressourcen. Das Generieren und Speichern von Einbettungen, insbesondere in großen Anwendungen, erfordert eine erhebliche Speicher- und Rechenleistung. Darüber hinaus kann die Dimensionalität der Einbettungen — ein Schlüsselfaktor für ihre Wirksamkeit — diese Anforderungen weiter verschärfen.
Unternehmen müssen die Kompromisse zwischen der Qualität der Einbettung und den Rechenkosten berücksichtigen. Um diese Herausforderungen in Produktionsumgebungen effektiv zu bewältigen, sind häufig Skalierbarkeitslösungen wie verteilte Rechenframeworks oder effiziente Speichersysteme wie die ANN-Indexierung (Approxime Nearest Neighbor) erforderlich.
Vektoreinbettungen können empfindlich auf kleine Änderungen der Eingabedaten reagieren, was zu unverhältnismäßig großen Änderungen im Einbettungsbereich führt. Diese Empfindlichkeit kann sich negativ auf die Leistung von ML-Modellen auswirken, insbesondere in dynamischen Umgebungen, in denen sich Daten im Laufe der Zeit weiterentwickeln.
Die Entwicklung robuster Einbettungen, die solche Schwankungen ohne nennenswerte Leistungseinbußen bewältigen können, ist von entscheidender Bedeutung. Techniken wie Datenerweiterung, robuste Trainingsmethoden und kontinuierliches Lernen werden eingesetzt, um die Stabilität und Haltbarkeit von Einbettungen zu verbessern.
Die Dimensionalität von Vektoreinbettungen ist ein kritischer Parameter, der sich sowohl auf ihre Effektivität als auch auf ihre Effizienz auswirkt. Höhere Dimensionen können detailliertere Informationen über die Daten erfassen, allerdings auf Kosten einer erhöhten Rechenkomplexität und des Risikos einer Überanpassung.
Bei der Auswahl der richtigen Dimensionalität muss die Granularität der durch die Einbettungen erfassten Informationen gegen die Recheneffizienz und Generalisierungsfähigkeit der Modelle, die sie verwenden, abgewogen werden. Techniken wie die Reduzierung der Dimensionalität oder die Anwendung von Regularisierungsstrategien während des Trainings können dabei helfen, dieses Gleichgewicht effektiv herzustellen.
Vektoreinbettungen haben sich als zentrale Innovation im maschinellen Lernen erwiesen und verändern die Art und Weise, wie komplexe Daten in verschiedenen Branchen analysiert und genutzt werden. Einbettungen ermöglichen die Übersetzung abstrakter, unstrukturierter Daten in umsetzbare numerische Formate und haben so die Tür zu ausgeklügelten Anwendungen geöffnet, die die Entscheidungsfindung verbessern, Erlebnisse personalisieren und Abläufe rationalisieren.
Von der Verbesserung der Genauigkeit von Empfehlungssystemen bis hin zur effektiveren Clusterbildung und Klassifizierung — die Vielseitigkeit und Nützlichkeit von Vektoreinbettungen sind unbestreitbar. Da wir jedoch die Grenzen dessen, was diese Tools leisten können, immer weiter ausloten, ist es unerlässlich, die mit ihrer Verwendung verbundenen Herausforderungen zu bewältigen, einschließlich der Rechenanforderungen, der Sensibilität gegenüber Datentransformationen und der ethischen Implikationen automatisierter Entscheidungsfindung.
Mit Blick auf die Zukunft sieht die Zukunft der Vektoreinbettung vielversprechend aus und verspricht weitere Fortschritte bei Algorithmen und Modellarchitekturen. Da diese Technologien zunehmend in Echtzeitanwendungen integriert werden, werden ihre Auswirkungen sowohl auf den Geschäftsbetrieb als auch auf das tägliche Leben nur noch zunehmen. Für Forscher, Entwickler und Unternehmen ist die kontinuierliche Weiterentwicklung der Vektoreinbettung ein fruchtbarer Boden für Innovationen und eine Gelegenheit, die Fähigkeiten der künstlichen Intelligenz weiterzuentwickeln.
Im weiteren Verlauf werden die Erforschung und der verantwortungsvolle Einsatz von Vektoreinbettungen entscheidend sein, um das volle Potenzial der KI auszuschöpfen, was dies zu einem spannenden Bereich für weitere Forschung und Entwicklung macht.
Um tiefer in die faszinierende Welt der Vektoreinbettung einzutauchen und Ihr Verständnis der Anwendungen und der zugrunde liegenden Technologien zu verbessern, finden Sie hier einige empfohlene wissenschaftliche Artikel, Tutorials und Tools:
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


