

July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Fraktionierte GPUs ermöglichen es uns, einer einzelnen GPU mehrere Workloads zuzuweisen, was in den folgenden Szenarien nützlich sein kann:
Um fraktionierte GPUs zu aktivieren, müssen wir einen separaten Nodepool der GPUs erstellen. Dies funktioniert nicht über die standardmäßige dynamische Knotenbereitstellung in AWS/ GCP. Damit Truefoundry diese Nodepools lesen kann, müssen wir sicherstellen, dass die Cloud-Integration bereits mit Truefoundry abgeschlossen ist.
Wenn es noch nicht aktiviert ist, bitte folge dieser Anleitung um die Cloud-Integration zu aktivieren.
Sobald die Cloud-Integration hinzugefügt wurde, müssen Sie „Nodepools“ für MIG- oder TimeSlicing-fähige GPUs erstellen. Diese Konfiguration ist für verschiedene Cloud-Anbieter unterschiedlich. Bitte folgen Sie der nachstehenden Anleitung, um fraktionierte GPUs in Ihrem Cluster zu aktivieren.
Bereitstellungen -> Helm -> tfy-gpu-Operator.1. Erstellen Sie mithilfe des Arguments einen Nodepool mit aktivierter MIG --gpu-instanzprofil von Azure CLI. Hier ist ein Beispielbefehl, um dasselbe zu tun:
als auch nodepool add\
<your cluster name>--Clustername\
<your resource group>--Ressourcengruppe\
--keine Wartezeit\
--enable-cluster-autoscaler\
--eviction-policy Löschen\
--node-count 0\
--max. Anzahl 20\
--min-Anzahl 1\
--node-osdisk-size 200\
--scale-down-mode Löschen\
--os-type Linux\
--node-taints „nvidia.com/gpu=present:noschedule“\
--name a100mig7\
--node-vm-size Standard_NC24ADS_A100_v4\
--priority Spot\
--os-sku Ubuntu\
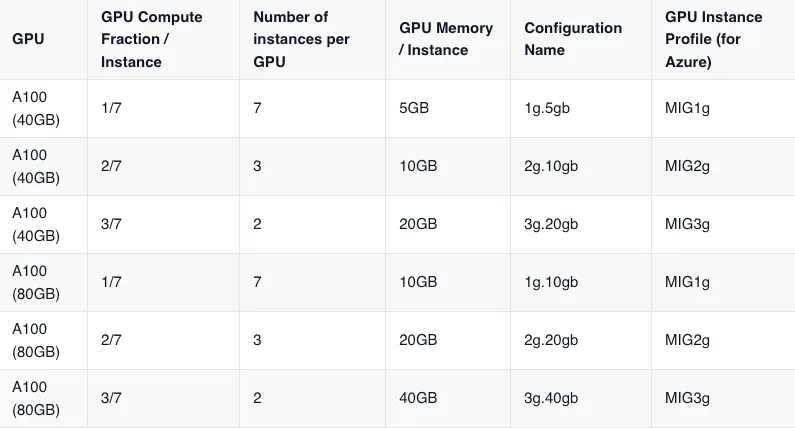
--gpu-instanzprofil mig1G
2. Aktualisieren Sie die Nodepools im Truefoundry-Cluster.
3. Stellen Sie Ihren Workload bereit, indem Sie GPU (mit Zählung 1) und den richtigen Nodepool auswählen.
Erstellen Sie einen Nodepool und übergeben Sie das mig_profile Gaspedal durch Passieren gpu_partition_size=1g.5gb[ODER einen der zulässigen Werte für das MIG-Profil finden Sie oben auf dieser Seite]
gcloud-Container-Knotenpools erstellen a100-40-mig-1g5gb\ INT ✘
<enter your project name>--projekt=\
<enter your region>--region=\
<enter your cluster name here>--cluster=\
--machine-type=a2-highgpu-1g\
--accelerator type=nvidia-tesla-a100, anzahl=1, gpu-partitionsgröße=1g.5gb\
--enable-autoscaling\
--total-min-nodes 0\
--total-max-Knoten 4\
--min-Provision-Knoten 0\
--num-nodes 0
Es ist nicht trivial, MIG-GPUs auf AWS derzeit auf verwaltete Weise zu unterstützen. Wenn Sie die Funktion jedoch ausprobieren möchten, lesen Sie bitte diese Dokumente
Nvidia-Geräte-Plugin Die Konfiguration ist korrekt eingestellt tfy-gpu-OperatorDiagramm.Helm -> tfy-gpu-Operator, klicken Sie auf Bearbeiten und stellen Sie sicher, dass die folgenden Zeilen in der Werteazure-aks-gpu-Operator:
Geräte-Plugin:
Konfiguration:
daten:
alle: „“
time-Sliced-10: |-
Ausführung: v1
teilen:
Zeitliches Aufschneiden:
renameByDefault: wahr
Ressourcen:
- Name: nvidia.com/gpu
Repliken: 10
Name: Time-Slicing-Konfiguration
erstellen: wahr
Standard: alle
Gerät-Plugin.config zeigt auf die richtige Time-Slicing-Konfiguration mit Azure CLI. Hier ist ein Beispielbefehl, um dasselbe zu tun.als auch nodepool add\
<your cluster name>--Clustername\
<your resource group>--Ressourcengruppe\
--keine Wartezeit\
--enable-cluster-autoscaler\
--eviction-policy Löschen\
--node-count 0\
--max. Anzahl 20\
--min-Anzahl 0\
--node-osdisk-size 200\
--scale-down-mode Löschen\
--os-type Linux\
--node-taints „nvidia.com/gpu=present:noschedule“\
--name a100mig7\
--node-vm-size Standard_NC24ADS_A100_v4\
--priority Spot\
--os-sku Ubuntu\
--labels nvidia.com/device-plugin.config=time-Sliced-10
gcloud-Container-Knotenpools erstellen a100-40-frac-10\ ✔
--project=tfy-devtest\
--region=us-zentral1\
--cluster=tfy-gtl-b-us-central-1\
--machine-type=a2-highgpu-1g\
--accelerator type=nvidia-tesla-a100, count=1, gpu-sharing-strategy=Zeitteilung, maximal gemeinsam genutzte Clients pro GPU=10\
--enable-autoscaling\
--total-min-nodes 0\
--total-max-Knoten 4\
--min-Provision-Knoten 0\
--num-nodes 0
1. Stellen Sie sicher, dass Nvidia-Geräte-Plugin Die Konfiguration ist korrekt eingestellt tfy-gpu-OperatorDiagramm.
Gehe zu Helm -> tfy-gpu-Operator, klicken Sie auf Bearbeiten und stellen Sie sicher, dass die folgenden Zeilen in der Werte
aws-eks-gpu-Operator:
Geräte-Plugin:
Konfiguration:
daten:
alle: „“
time-Sliced-10: |-
Ausführung: v1
teilen:
Zeitliches Aufschneiden:
renameByDefault: wahr
Ressourcen:
- Name: nvidia.com/gpu
Repliken: 10
Name: Time-Slicing-Konfiguration
erstellen: wahr
Standard: alle
2. Erstellen Sie eine Knotengruppe auf AWS EKS mit der folgenden Bezeichnung:
Beschriftungen:
„nvidia.com/device-plugin.config“: „zeitversetzt-10"
So verwenden Sie fraktionierte GPUs in Ihrem Service:
1. Stellen Sie sicher, dass Sie die gewünschten Nodepools hinzugefügt haben.
2. Bitte synchronisieren Sie die Cluster-Nodepools von Ihrem Cloud-Konto aus, indem Sie wie unten gezeigt zu Integrationen -> Clusters -> Sync gehen:

3. Sie können die Bereitstellung entweder über die Benutzeroberfläche von Truefoundry oder über das Python SDK durchführen.
Hinweis: Autoscaling von Nodepools funktioniert nur in GCP Cluster. Sie müssen Nodepools in Azure/AWS manuell hoch-/herunterskalieren.
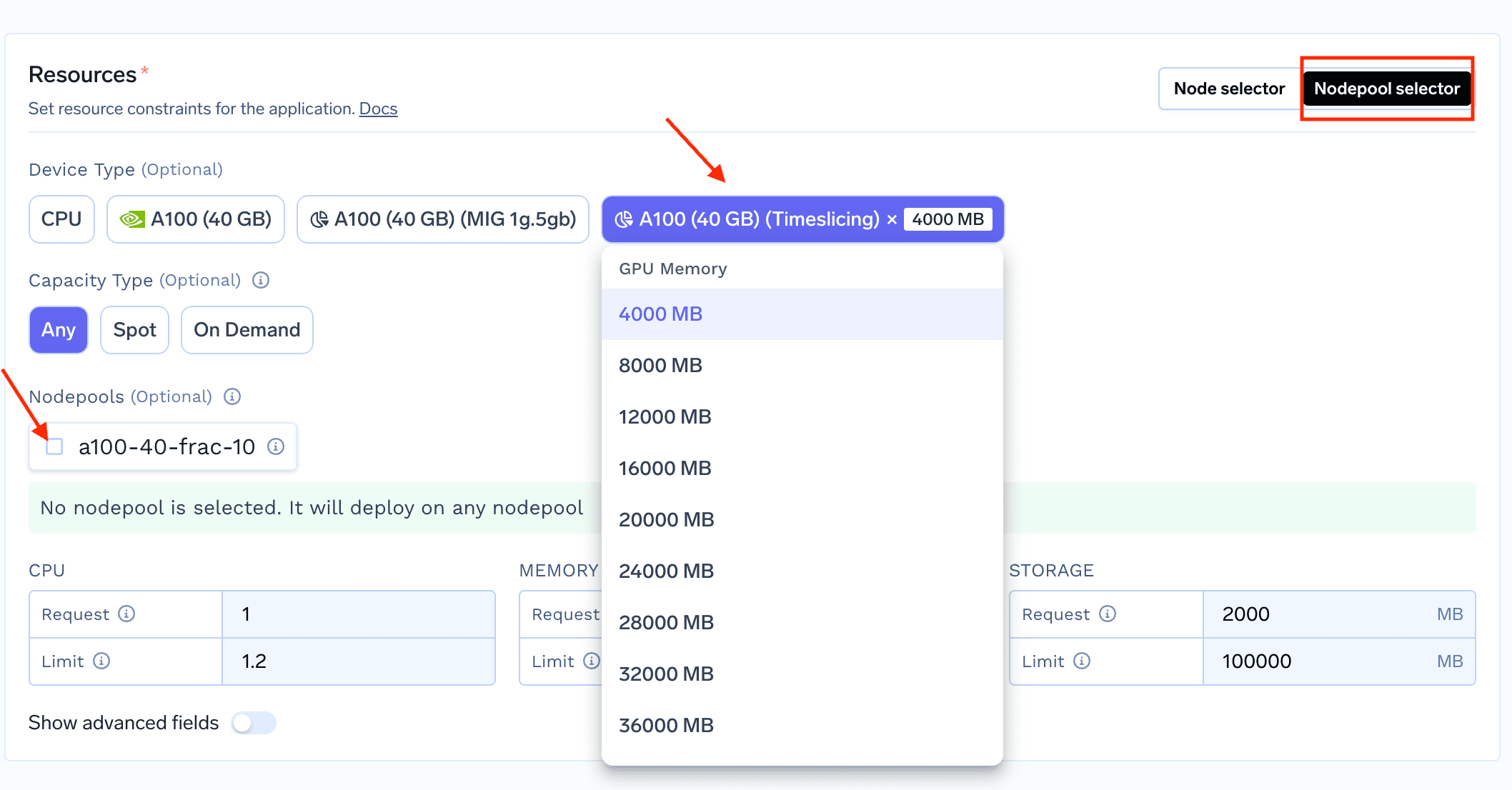
1. Um einen Workload bereitzustellen, der einen Bruchteil der GPU nutzt, beginnen Sie mit der Bereitstellung Ihres Dienstes/Jobs auf Truefoundry und wählen Sie im Abschnitt „Ressourcen“ die Option nodepool selector
2. Sobald Sie den Nodepool Selector oben rechts im Abschnitt Ressourcen ausgewählt haben, können Sie nun die Fractional GPUs auf der Benutzeroberfläche sehen, die Sie auswählen können (wie unten gezeigt)

Sie können fraktionierte GPUs mithilfe des Python-SDK verwenden, wobei sich die Ressourcen wie folgt ändern:
1. Verwenden von MIG-GPUs
von servicefoundry import (
...
Bedienung,
Nvidia-MigGPU,
Knotenpool-Selektor,
)
Dienst = Dienst (
...
Resources=Ressourcen (
...
node=NodePoolSelector (
<add your nodepool name>nodepools = [“ „],
),
Geräte = [
NvidiaMigGPU (profile="1g.5gb“)
],
),
)
2. Verwenden der Timeslicing-GPU
von servicefoundry import (
Bedienung,
NVIDIA Timeslicing-GPU,
Knotenpool-Selektor,
)
Dienst = Dienst (
...
Resources=Ressourcen (
...
node=NodePoolSelector (
<add your nodepool name>nodepools = [“ „],
),
Geräte = [
NVIDIA TimeSlicing-GPU (gpu_memory=4000),
],
),
)
Wir bei Wahre Gießerei unterstützt Fractional GPUs auf extrem optimierte Weise.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


