

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Der Boom großer Sprachmodelle hat die Art und Weise, wie Teams KI-gestützte Produkte entwickeln, verändert, aber auch neue Herausforderungen mit sich gebracht. Entwickler müssen die Modellleistung überwachen, die Kosten optimieren, die Aufforderungen verfeinern und die Zuverlässigkeit in großem Maßstab sicherstellen. Die Verwaltung all dieser beweglichen Teile erfordert Transparenz und Kontrolle über jeden API-Aufruf und jede Antwort.
Helicone ist entstanden, um genau dieses Problem zu lösen. Es bietet eine einheitliche Plattform zur Verfolgung, Analyse und Optimierung von Anfragen an Sprachmodelle wie OpenAI oder Anthropic, sodass Teams schneller debuggen und den Betriebsaufwand reduzieren können.
Da sich Unternehmen jedoch weiterentwickeln, übertreffen ihre Anforderungen oft das, was Helicone bietet. Einige benötigen tiefere Analysen, eine Bereitstellung vor Ort oder eine stärkere Kontrolle über den Datenschutz. Andere suchen nach Tools mit mehr Flexibilität oder erweiterter Routing-Logik.
Dort gibt es Alternativen wie Wahre Gießerei komm rein. TrueFoundry's wurde für den KI-Betrieb in Unternehmen entwickelt KI-Gateway und MCP-Gateway bieten umfassende Transparenz, Routing mit mehreren Modellen und eine Infrastruktur, bei der die Einhaltung von Vorschriften an erster Stelle steht, und helfen Teams dabei, die Modellnutzung sicher und effizient zu skalieren.
In diesem Leitfaden werden wir untersuchen, was Helicone ist, wie es funktioniert, warum Teams nach Alternativen suchen und die 5 besten Helicone-Alternativen besprechen, um Ihnen bei der Auswahl der richtigen Lösung für Ihre KI-Infrastruktur zu helfen.
Helicone ist eine Open-Source-LLM-Beobachtungs- und Überwachungsplattform, die Entwicklern die vollständige Kontrolle und Transparenz über ihre KI-Anwendungen bietet. Es dient als leistungsstarkes Gateway, das Ihre App über eine einzige einheitliche Oberfläche mit führenden Anbietern von Sprachmodellen wie OpenAI, Anthropic, Google Gemini, Together AI und vielen anderen verbindet.
In einem sich schnell entwickelnden KI-Ökosystem sind Sichtbarkeit und Rückverfolgbarkeit von entscheidender Bedeutung. Helicone vereinfacht den LLM-Betrieb, indem es automatisch jedes Detail einer Anfrage erfasst, von Aufforderungen und Antworten bis hin zu Token-Nutzung, Latenz und Kosten. Diese Zentralisierung macht manuelles Tracking über mehrere APIs hinweg überflüssig und hilft Teams, Probleme zu erkennen, die Leistung zu verbessern und das Modellverhalten präzise zu optimieren.
Hauptmerkmale von Helicone
Neben seinen Kernfunktionen hat Helicone eine starke Open-Source-Community aufgebaut. Mit mehr als 4.000 Sternen auf GitHub und Beiträgen von Hunderten von Entwicklern wächst sie weiterhin schnell. Der Fokus der Community auf Transparenz und Erweiterbarkeit macht sie zu einer vertrauenswürdigen Wahl für KI-Ingenieure, die Zuverlässigkeit ohne Herstellerbindung wünschen.
Ganz gleich, ob es Ihr Ziel ist, die Modellzuverlässigkeit zu verbessern, die Betriebskosten zu senken oder die Beobachtbarkeit Ihres gesamten KI-Stacks in Echtzeit zu verbessern, Helicone bietet die Infrastruktur, die Sie benötigen, um intelligente Anwendungen zuverlässig zu erstellen, zu überwachen und zu skalieren.
Helicone dient als einheitliches API-Gateway, das Ihre Anwendung mit über 100 Anbietern von Sprachmodellen verbindet. Durch das Weiterleiten von Anfragen über Helicone können Entwickler Integrationen vereinfachen, die Beobachtbarkeit verbessern und die Modellleistung ohne größere Codeänderungen optimieren.
Nahtlose Integration
Die Integration von Helicone ist unkompliziert. Entwickler können ihre vorhandenen OpenAI- oder andere LLM-SDKs so konfigurieren, dass sie auf den Gateway-Endpunkt von Helicone verweisen:
const client = new OpenAI({
apiKey: process.env.HELICONE_API_KEY,
baseURL: "https://ai-gateway.helicone.ai"
});
Dieser Ansatz ermöglicht es Anwendungen, über eine konsistente Schnittstelle mit mehreren LLM-Anbietern zu interagieren, wodurch die Komplexität der Verwaltung verschiedener APIs reduziert wird.
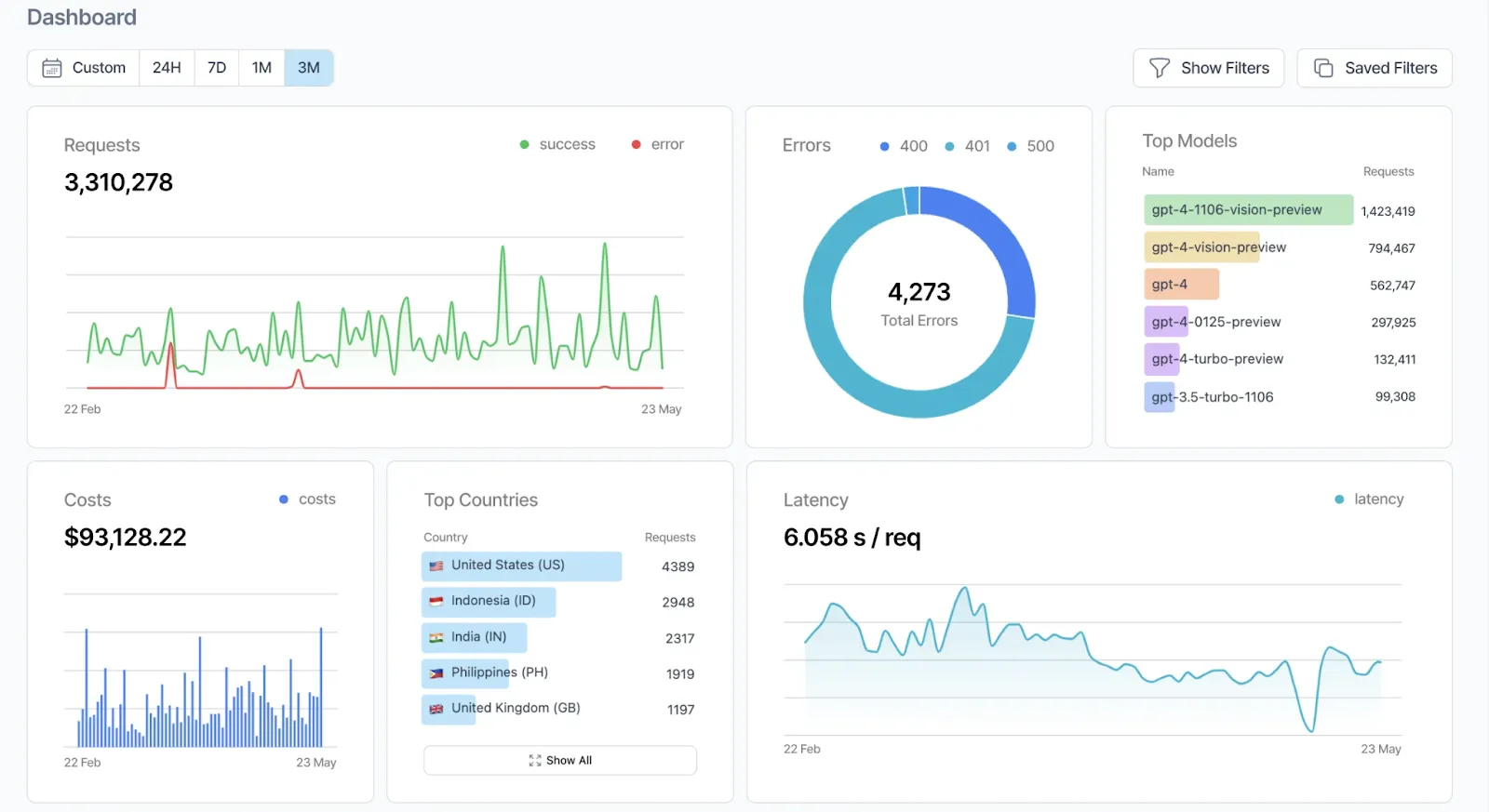
Umfassende Beobachtbarkeit
Helicone protokolliert automatisch detaillierte Metadaten für jede Anfrage, sodass Entwickler in Echtzeit Einblicke in ihre KI-Workflows erhalten. Zu den protokollierten Daten gehören:
All diese Informationen sind über ein zentrales Dashboard verfügbar, sodass Teams die Leistung überwachen, Engpässe identifizieren und Nutzungstrends effizient analysieren können.
Intelligentes Routing und Failover
Helicone enthält eine intelligente Routing-Engine, die die Anforderungszustellung optimiert. Zu den wichtigsten Funktionen gehören:
Dieses Routing-System gewährleistet eine hohe Zuverlässigkeit und konsistente Leistung in verschiedenen Einsatzszenarien.
Edge-Caching zur Leistungsoptimierung
Um Latenz und API-Kosten zu reduzieren, bietet Helicone Edge-Caching an. Häufig angeforderte Antworten werden am Edge gespeichert, was einen schnelleren Abruf ermöglicht und redundante API-Aufrufe minimiert, was sowohl die Geschwindigkeit als auch die Kosteneffizienz verbessert.
Flexible Bereitstellungsoptionen
Helicone unterstützt sowohl Cloud-gehostete als auch selbst gehostete Bereitstellungen:
Beide Bereitstellungsoptionen entsprechen Unternehmensstandards, einschließlich SOC 2 und HIPAA, und eignen sich daher für sichere und regulierte Umgebungen.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Helicone bietet zwar umfassende Observability, Routing und Logging für LLM-Anwendungen, erfüllt aber möglicherweise nicht die spezifischen Anforderungen jedes Unternehmens. Teams ziehen häufig Alternativen in Betracht, um Einschränkungen in Bezug auf Flexibilität, Kostenstruktur oder spezielle Funktionen zu beheben — insbesondere bei der Bewertung der Kompromisse, die in Helicone gegen Portkey Vergleiche.
Ein Grund, nach Alternativen zu suchen, sind Modellvielfalt und Kontrolle. Helicone unterstützt über 100 Modelle, aber einige Organisationen benötigen möglicherweise native Integrationen mit Nischen- oder proprietären LLMs, die nicht vollständig unterstützt werden. Alternativen bieten möglicherweise eine einfachere Integration mit diesen Modellen oder eine fortschrittlichere Routing-Logik.
Zu den wichtigsten Überlegungen bei der Erforschung von Alternativen gehören:
Flexibilität bei Anpassung und Bereitstellung ist ein weiterer Faktor. Helicone unterstützt zwar das Self-Hosting über Helm-Charts, aber einige Teams benötigen eine tiefere Kontrolle über Caching-Strategien, Logging-Formate oder Bereitstellungen in mehreren Regionen. Überlegungen zu Kosten und Skalierbarkeit sind ebenfalls ausschlaggebend für die Bewertung. Helicone bietet eine Passthrough-Abrechnung an, aber Unternehmen mit hohen Anfragen oder strengen Budgetbeschränkungen können von Tools profitieren, die die Nutzung weiter optimieren.
Die Erkundung von Helicone-Alternativen hilft Unternehmen dabei, Lösungen zu finden, die besser auf ihre technischen Bedürfnisse, betrieblichen Ziele und Kostenüberlegungen abgestimmt sind, und gleichzeitig eine robuste LLM-Beobachtbarkeit und Zuverlässigkeit aufrechtzuerhalten.
Helicone bietet zwar leistungsstarke Observability und Routing für LLM-Anwendungen, ist aber möglicherweise nicht für die spezifischen Anforderungen jedes Teams geeignet. Entwickler suchen häufig nach Alternativen, um mehr Flexibilität, verbesserte Analysen oder spezielle Integrationen zu erhalten.
Die folgenden fünf Plattformen bieten zuverlässige Optionen für die Überwachung, Nachverfolgung und Optimierung umfangreicher Sprachmodelle, von denen jede über einzigartige Stärken verfügt und für unterschiedliche Workflows geeignet ist.
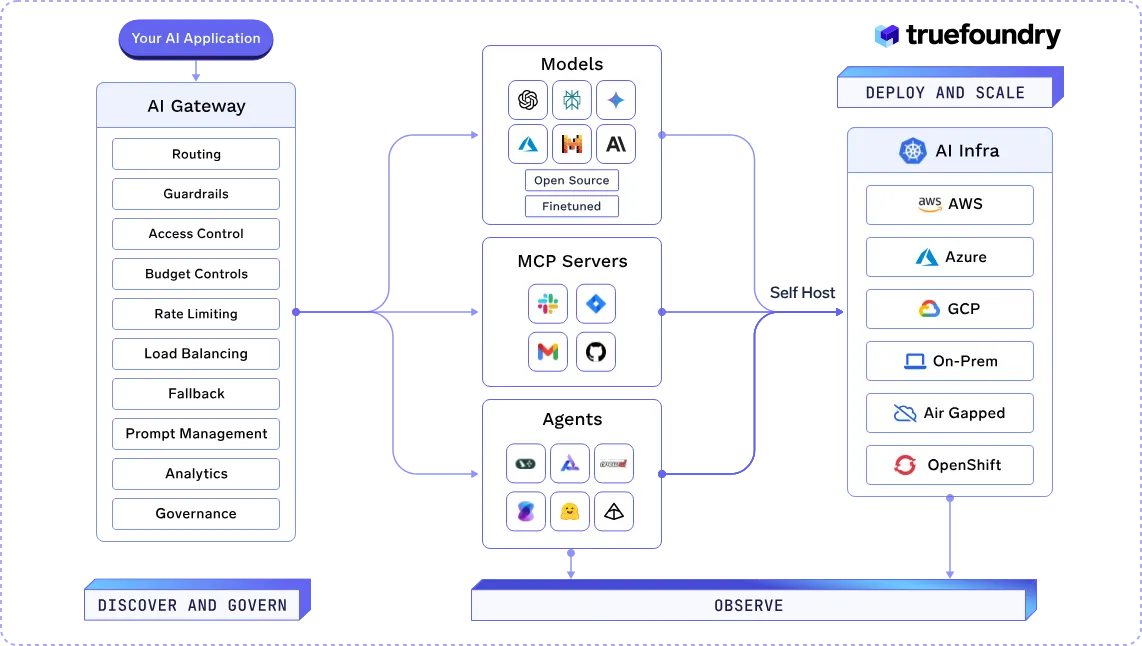
Wahre Gießerei bietet eine einheitliche Infrastruktur für die Erstellung, Bereitstellung und Verwaltung von KI-Anwendungen in großem Maßstab. Es bietet Tools zur Orchestrierung von KI-Agenten, zur Verwaltung von Modellbereitstellungen und zur Gewährleistung von Sicherheit und Compliance in verschiedenen Umgebungen.
Zu den Kernkomponenten der Plattform gehören das AI Gateway, die Model Control Protocol (MCP) -Server und die Tracing-Funktionen, die jeweils auf spezifische Herausforderungen bei der Entwicklung und Bereitstellung von KI-Anwendungen zugeschnitten sind.
TrueFoundry ist eine führende Unternehmensplattform, da sie KI-Bereitstellung, Beobachtbarkeit und Governance in einer skalierbaren Lösung vereint. Ihre fortschrittlichen Funktionen, wie das AI Gateway, die MCP-Server und das durchgängige Tracing, geben Unternehmen die volle Kontrolle, Sicherheit und Transparenz und eignen sich daher ideal für die Verwaltung komplexer KI-Anwendungen in großem Maßstab.
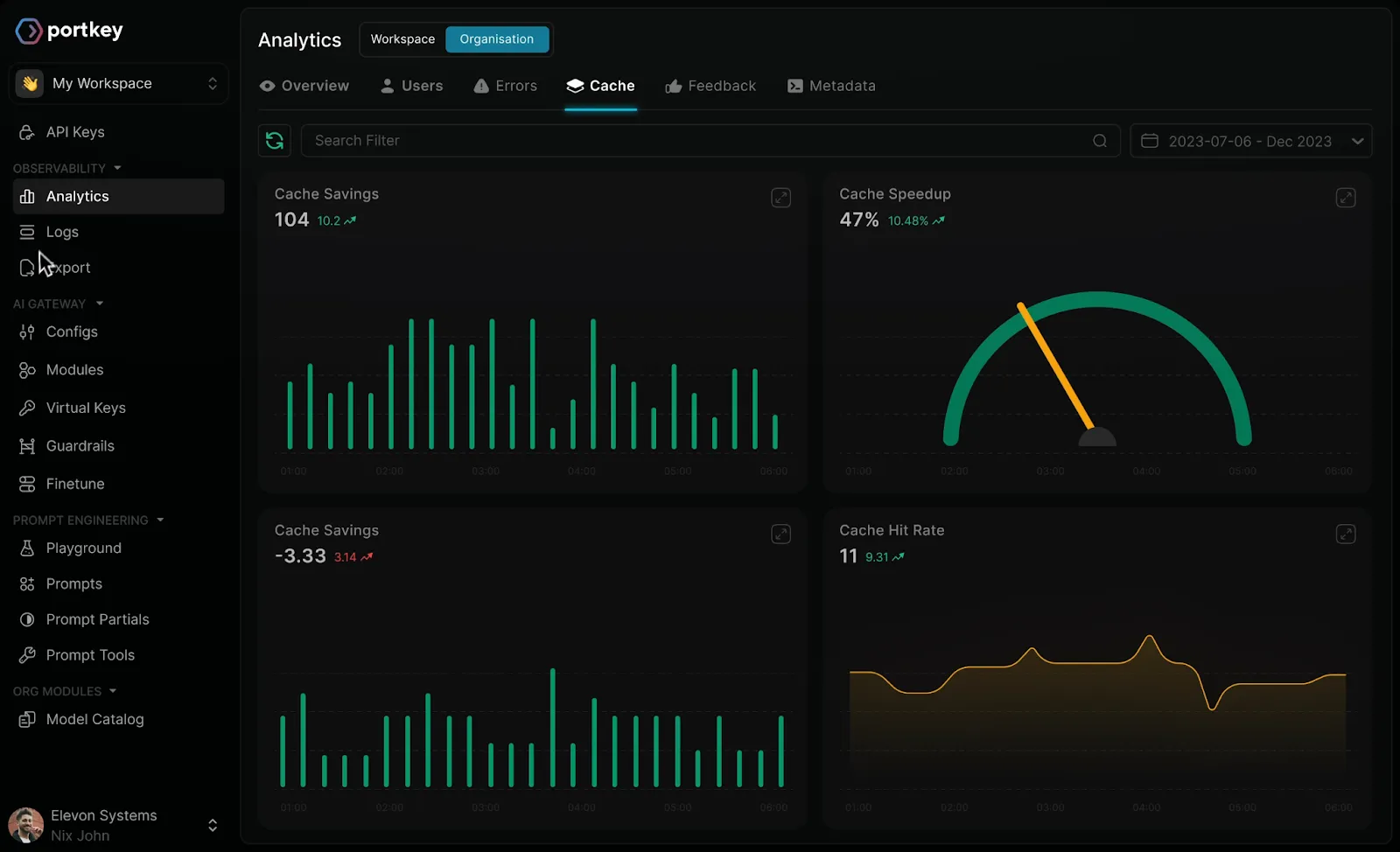
Portkey ist ein Open-Source-KI-Gateway, das entwickelt wurde, um die Art und Weise zu optimieren, wie Unternehmen mit mehreren Sprachmodellen interagieren. Anstatt separate APIs für jeden Anbieter zu verwalten, können Entwickler Portkey als eine einzige Schnittstelle verwenden, um Anfragen zu senden, die Leistung zu überwachen und den Datenverkehr effizient weiterzuleiten.
Dies vereinfacht Arbeitsabläufe und reduziert den Aufwand für die gleichzeitige Integration und Wartung mehrerer Modelle.
Neben der grundlegenden Konnektivität bietet Portkey intelligente Routing-Funktionen, mit denen Anfragen basierend auf Leistung, Kosten oder vordefinierten Regeln automatisch an das am besten geeignete Modell weitergeleitet werden können. Dies wird beim Vergleich häufig zwischen Teams besprochen Alternativen zu Portkey. Es unterstützt auch Fallback-Mechanismen und Wiederholungsversuche und gewährleistet so die Zuverlässigkeit auch dann, wenn an einigen Endpunkten Latenz oder Ausfallzeiten auftreten. Die Beobachtbarkeit ist in die Plattform integriert und bietet detaillierte Kennzahlen zu den Erfolgsraten von Anfragen, zur Latenz und zu den Nutzungsmustern.
Die wichtigsten Funktionen:
Nachteile:
OpenLLMetry von Traceloop ist ein Open-Source-Observability-Framework, das auf OpenTelemetry basiert und auf die Überwachung und das Debuggen großer Sprachmodellanwendungen zugeschnitten ist. Es bietet tiefe Einblicke in die Interaktionen und die Leistung von Modellen und ermöglicht so eine effektive Fehlerbehebung und Optimierung.
Die wichtigsten Funktionen:
Nachteile:
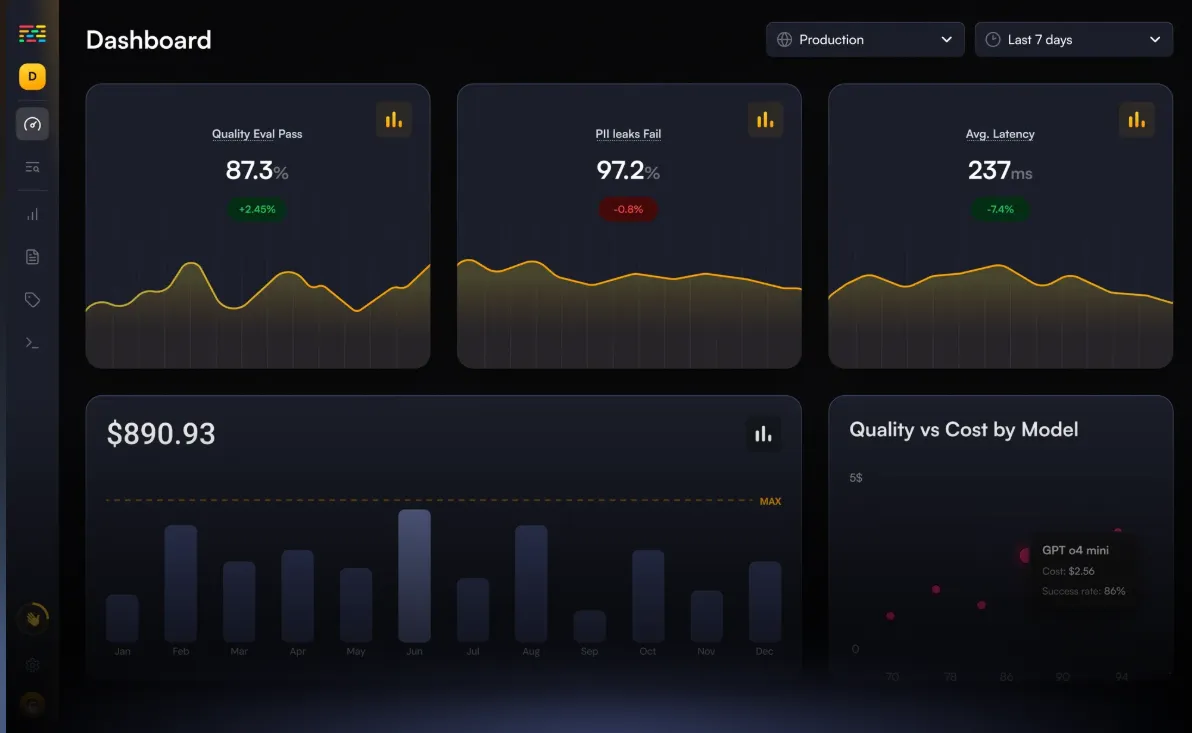
LangSmith, entwickelt von der LangChain-Community, ist eine einheitliche Beobachtbarkeits- und Evaluierungsplattform für große Sprachmodellanwendungen. Sie bietet Tools zur Verfolgung, Überwachung und Analyse von KI-Workflows und verbessert so das Debugging und die Leistungsoptimierung.
Die wichtigsten Funktionen:
Nachteile:
Langfuse ist eine Open-Source-Plattform, die sich auf Beobachtbarkeit und Analytik für große Sprachmodellanwendungen konzentriert. Sie ermöglicht es Teams, KI-Arbeitsabläufe zu verfolgen, zu analysieren und zu optimieren und bietet so tiefe Einblicke in die Interaktionen und die Leistung von Modellen.
Die wichtigsten Funktionen:
Nachteile:
Helicone bietet eine leistungsstarke Open-Source-Plattform für LLM-Observability, Routing und Analytik und ist damit eine gute Wahl für Teams, die eine umfassende Überwachung von KI-Anwendungen suchen. Die Fähigkeit, die Protokollierung zu zentralisieren, die Token-Nutzung zu verfolgen und Einblicke über mehrere Modellanbieter hinweg bereitzustellen, vereinfacht die betrieblichen Herausforderungen beim Aufbau zuverlässiger LLM-basierter Systeme.
Da KI-Anwendungen jedoch immer komplexer werden, benötigen Unternehmen häufig Lösungen, die auf bestimmte Workflows, Bereitstellungsumgebungen oder Integrationsanforderungen zugeschnitten sind. Die Erkundung von Helicone-Alternativen ermöglicht es Teams, Plattformen auszuwählen, die ihren technischen und betrieblichen Anforderungen besser entsprechen. TrueFoundry bietet beispielsweise Orchestrierung, Tracing und Governance auf Unternehmensebene mit fortschrittlichen AI-Gateway- und MCP-Serverfunktionen und ist damit ideal für Unternehmen, die Wert auf Sicherheit, Compliance und Skalierbarkeit legen.
Portkey zeichnet sich durch den einheitlichen API-Zugriff und das Routing über verschiedene Modelle hinweg aus, während Traceloop durch OpenTelemetry-basiertes Tracing eine umfassende Beobachtbarkeit bietet. LangSmith bietet speziell entwickelte Evaluierungs- und Debugging für LangChain-Anwendungen, und Langfuse bietet detaillierte Protokollierung und Analysen für asynchrone Beobachtbarkeit.
Die Wahl der richtigen LLM-Observability-Plattform hängt von Faktoren wie Einsatzflexibilität, Modellunterstützung, Überwachungstiefe und Kosteneffizienz ab.
Durch die Bewertung der Funktionen, Stärken und Einschränkungen jeder Option können Entwicklungsteams robuste, transparente und skalierbare KI-Systeme implementieren, die Leistung, Sicherheit und Zuverlässigkeit über reale Produktionsworkloads hinweg aufrechterhalten.
Zu den besten Helicone-Alternativen für Unternehmen gehören TrueFoundry, Portkey und Traceloop. Während sich Helicone auf einfache Observability konzentriert, bietet TrueFoundry eine einheitliche Infrastruktur mit integriertem KI-Gateway und Sicherheitsfunktionen. Andere bemerkenswerte Optionen wie Langfuse und Lunary bieten Open-Source-Tracing für Teams, die gründliche Analysen und spezielle Evaluierungstools für Produktionsanwendungen benötigen.
Teams wechseln häufig, wenn sie der grundlegenden Proxy-Überwachung nicht mehr gewachsen sind und eine Unternehmensführung benötigen. Helicone wird häufig durch einen Mangel an leistungsfähigem RBAC, Auditprotokollierung und umfassender Unterstützung für mehrstufige agentische Workflows eingeschränkt. Der Wechsel zu einer Plattform wie TrueFoundry ermöglicht die Bereitstellung innerhalb einer privaten VPC und bietet erweiterte Richtlinien zur Kostenkontrolle, die für die Verwaltung von KI-Systemen im Produktionsmaßstab erforderlich sind.
Ja, mehrere prominente Open-Source-Alternativen sind Portkey, Langfuse und Traceloop. Diese Plattformen ermöglichen Self-Hosting und eine tiefere Integration in bestehende OpenTelemetry-Pipelines. Für Entwickler, die einen einfachen Python-basierten Proxy suchen, ist LitelLM ein beliebter Community-Favorit, der API-Aufrufe für Hunderte von Modellen standardisiert, ohne den Aufwand und die Datenrisiken eines verwalteten SaaS-Anbieters.
Ja, Helicone unterstützt über seine einheitliche API grundlegendes Routing mit mehreren Modellen und Provider-Failover. Es fehlt jedoch die ausgeklügelte, metadatenfähige Routing-Logik, die in Unternehmens-Gateways zu finden ist. Plattformen wie TrueFoundry erweitern diese Funktion, indem sie es Teams ermöglichen, komplexe Fallback-Ketten und Kontingente auf Teamebene zu definieren, wodurch eine hohe Verfügbarkeit sowohl bei kommerziellen als auch bei selbst gehosteten Modellanbietern gewährleistet wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




