Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
Reduzieren Sie Ihre Infrastrukturkosten für ML/LLM-Modelle
Die Ausführung von Workloads für maschinelles Lernen (ML) und Large Language Model (LLM) in der Cloud ist bekanntermaßen teuer. Das liegt daran, dass sie erhebliche Mengen an Rechenleistung, Arbeitsspeicher und Speicherplatz benötigen. Es gibt jedoch Möglichkeiten, Ihre Cloud-Kosten für ML/LLM-Workloads zu senken, ohne die Skalierbarkeit oder Zuverlässigkeit zu beeinträchtigen.
Grundprinzipien zur Kostensenkung
Bessere Sichtbarkeit für DevOps-Ingenieure und Entwickler: Es ist schwierig, einen Überblick über die Cloud-Kosten zu erhalten, insbesondere wenn Sie mehrere Komponenten in mehreren Clouds bereitstellen. TrueFoundry bietet Einblick in die Cloud-Kosten auf Cluster-, Workspace- und Bereitstellungsebene und ermöglicht es DevOps-Teams und Entwicklern, Kosteneinsparungsmöglichkeiten während des gesamten ML/LLM-Lebenszyklus zu identifizieren und zu optimieren.
Einfache Anpassung der Ressourcen: TrueFoundry ermöglicht es DevOps-Teams und Entwicklern, Maßnahmen zu ergreifen, um die gewonnene Kostentransparenz zu nutzen.
DevOps-Teams kann Ressourcenbeschränkungen auf Projektebene festlegen und so sicherstellen, dass die Arbeitslasten jedes Teams auf die Ressourcen zugreifen können, die sie benötigen, ohne das Budget zu überschreiten.
Entwickler können Ressourcen auch unterwegs problemlos anpassen, basierend auf den Erkenntnissen, die sie erhalten. Darüber hinaus ermöglicht TrueFoundry die einfache Skalierung von Anwendungen und IDEs in Umgebungen ohne Produktionsbetrieb bis auf Null. Dadurch entfallen die Kosten ungenutzter Ressourcen und Iterationszyklen zur Kostensenkung werden effizienter.
Optimierung der Infrastruktur aus Kostengründen: Die auf Kubernetes basierenden Architektur- und Infrastrukturoptimierungen von TrueFoundry wurden entwickelt, um die Cloud-Kosten zu senken.
Insgesamt bieten die kostensparenden Funktionen von TrueFoundry DevOps-Teams und Entwicklern die Transparenz, Kontrolle und Optimierungsfunktionen, die sie benötigen, um die Cloud-Kosten während des gesamten ML/LLM-Lebenszyklus zu senken.
Übergang von AMI zu Docker: Unsere Plattform hat es vielen Unternehmen erleichtert, von AMI zu Docker zu migrieren, wo Unternehmen bereits Kosteneinsparungen von 30 bis 40 Prozent erzielt haben.
TrueFoundry: Ihre kostenorientierte Plattform
Truefoundry ist ein „Kostenzuerst“ Plattform, die auf Kubernetes basiert und mit einer Architektur entwickelt wurde, bei der Effizienz, Skalierbarkeit und Kostensenkung im Vordergrund stehen.
Lassen Sie uns herausfinden, wie Sie mit der einzigartigen Architektur von TrueFoundry Kosten sparen und gleichzeitig die Zuverlässigkeit und Skalierbarkeit optimieren können. Hier ist die hierarchische Struktur der Plattform:
Cluster: Verbinden Sie alle Ihre Cluster, egal ob es sich um AWS EKS, Azure AKS, GCP GKE oder einen lokalen Cluster handelt, mit der Plattform. Auf diese Weise können Sie alle Ihre Cluster nahtlos an einem Ort integrieren. Diese Cluster bilden die Grundlage für die Bereitstellung einer Vielzahl von Diensten, Modellen und Jobs.
Arbeitsbereiche: Innerhalb von Clustern führen wir Arbeitsbereiche ein und bieten einen optimierten Ansatz, um Zugriffskontrolle und Isolierung hinzuzufügen, um sicherzustellen, dass jedes Projekt oder jede Umgebung über eigene dedizierte Ressourcen verfügt und vor unbefugtem Zugriff geschützt ist. Stellen Sie sich diese als Gruppen von Bereitstellungen vor.
Bereitstellungen: In diesen Arbeitsbereichen haben wir Bereitstellungen und wir unterstützen Sie dabei, verschiedene Dinge bereitzustellen. Mit TrueFoundry können Sie mühelos jeden Aspekt Ihres ML-Entwicklungszyklus abdecken.
Interaktive Entwicklungsumgebungen: Stellen Sie Jupyter Notebook und VS Code für kollaboratives Experimentieren bereit.
Ausbildungs- und Feinabstimmungsjobs: Trainieren Sie ML-Modelle effizient oder optimieren Sie LLM-Modelle, indem Sie sie als Job bereitstellen.
Vortrainierte LLMs: Stellen Sie mithilfe unseres Modellkatalogs schnell vortrainierte Large Language Models für bestimmte Anwendungsfälle bereit.
Dienste und Apps: Stellen Sie eine Vielzahl von Diensten und Anwendungen bereit, darunter Modelle, Web-Apps usw.
Anwendungskatalog: Stellen Sie beliebte Software wie Label Studio, Redis, Qdrant usw. mühelos bereit.
Kosteneinsparungen auf Cluster-Ebene
Kuberenetes-basierte Infrastruktur
Kubernetes trägt zur Kostensenkung bei, indem es Bin Packing einsetzt, um die Ressourcennutzung zu optimieren, Container effizient zu platzieren und letztendlich die Infrastrukturkosten zu senken.
Um mehr darüber zu erfahren, wie TrueFoundry Kubernetes nutzt, lesen Sie hier.
💡
Migration von EC2 zu Kubernetes: Viele Unternehmen sind nach dem Onboarding in unsere Plattform erfolgreich von EC2-Computern auf Kubernetes umgestiegen, was aufgrund der verbesserten Ressourcenzuweisung zu Kosteneinsparungen geführt hat
Multi-Cloud-Unterstützung
Die Multi-Cloud-Architektur von TrueFoundry macht es einfach, eine Verbindung zu verschiedenen Cloud-Anbietern herzustellen.
Flexibilität beim Umschalten zwischen Clouds: Durch die einfache Möglichkeit, zwischen verschiedenen Cloud-Anbietern zu wechseln, können Sie die besten Preise und Funktionen verschiedener Anbieter nutzen.
Workloads auf Clouds und Regionen verteilen: Indem Sie Ihre Workloads auf mehrere Cloud-Anbieter und Regionen verteilen. Dies kann zur Kostensenkung beitragen, indem Sie Ihre Workloads auf verschiedene Preisstufen und Regionen verteilen. Es hilft auch, Leistung und Zuverlässigkeit zu verbessern, indem Sie Ihre Abhängigkeit von einem einzigen Cloud-Anbieter verringern.
Verfügbarkeit hoher Instance-Kontingente: Wenn Sie mehrere Cloud-Anbieter verwenden, können Sie auf mehr Ressourcen zugreifen. Dies kann Ihnen helfen, Geld zu sparen und Einschränkungen der benötigten Ressourcen zu vermeiden.
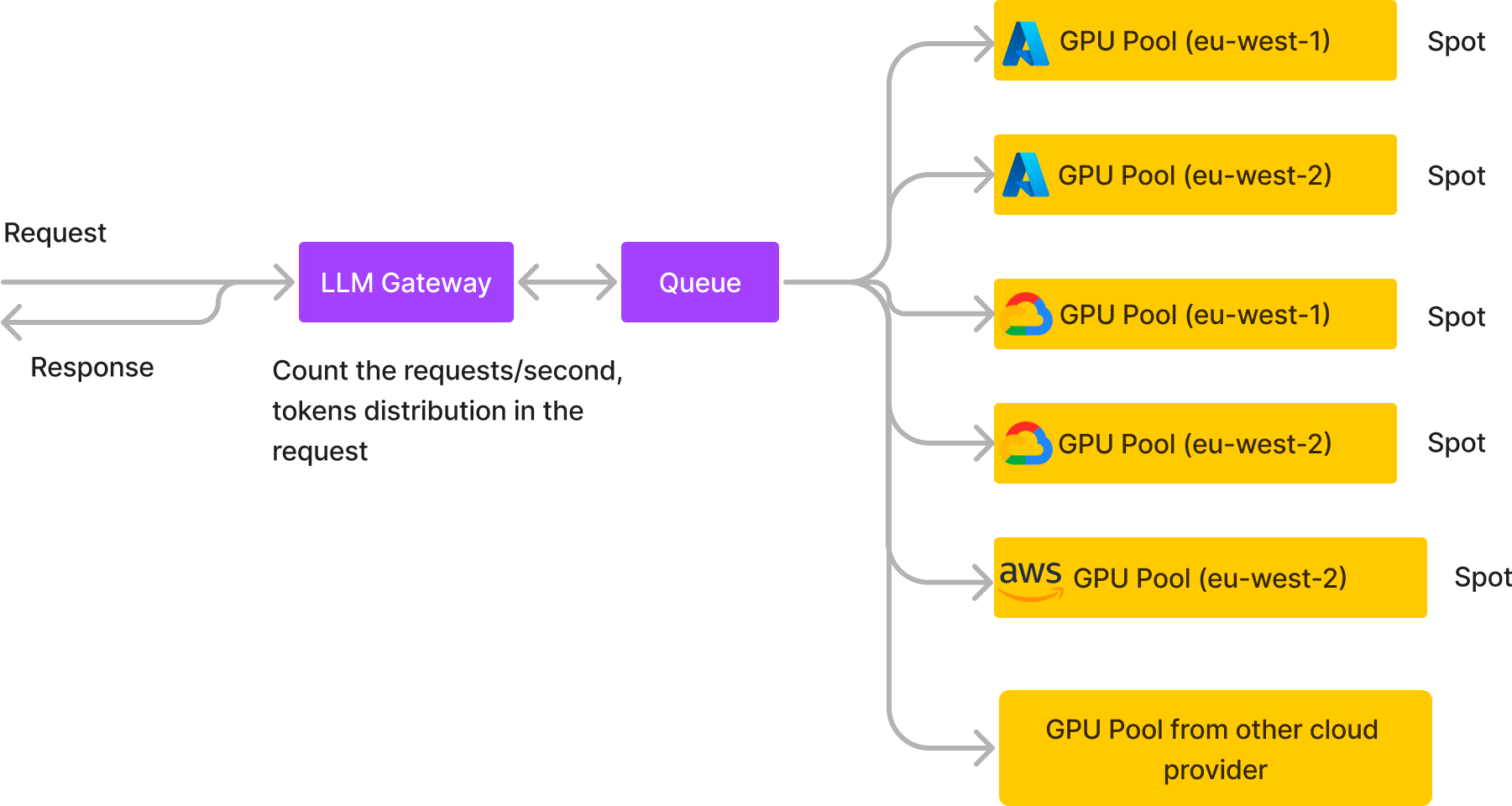
Skalierung von LLMs über mehrere Clouds und Regionen hinweg
💡
Ein Chatbot-Anbieter für Konversations-KI auf mittlerer Ebene mit hohem Benutzerverkehr (über 20 RPS und mehr als 2 Millionen Anfragen pro Tag) läuft mithilfe unseres asynchronen Dienstes vollständig auf verteilten Spot-GPU-Instances über fünf Cluster in verschiedenen Clouds und Regionen. Dadurch werden ihre Infrastrukturkosten um 60% reduziert und gleichzeitig die Zuverlässigkeit und der Durchsatz verbessert.
Verbesserte Sichtbarkeit
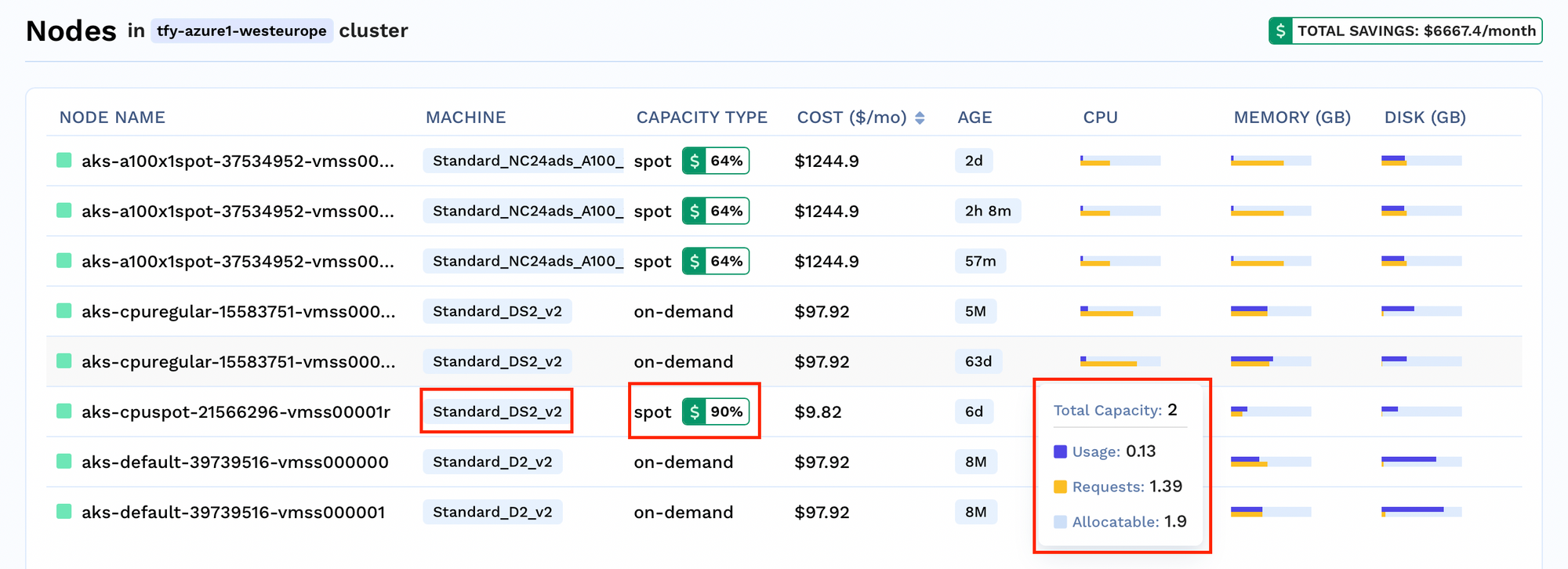
Für jeden Cluster können Sie die Anzahl der Knoten anzeigen, die im Cluster ausgeführt werden. Sie können auch Einblicke in knotenspezifische Details erhalten, wie
Analyse der Einsparungen: Sehen Sie sich den Prozentsatz der eingesparten Kosten für jeden Knoten an
Einblicke in die Ressourcenzuweisung: Sehen Sie sich die aktuelle Nutzung, die Ressourcenanforderung und das Limit an, um fundierte Entscheidungen zu treffen.
Einblicke in den Kapazitätstyp: Sehen Sie, welche Arten von Knoten in Ihrem Cluster ausgeführt werden, ob es sich um Spot- oder On-Demand-Knoten handelt.
Kosteneinsparungen auf Workspace-Ebene
Grenzwerte für Ressourcen
Mit TrueFoundry können Sie mehrere Workspaces innerhalb eines Clusters erstellen. Diese Segmentierung hilft Ihnen bei der Organisation Ihrer Bereitstellungen für verschiedene Teams oder Umgebungen.
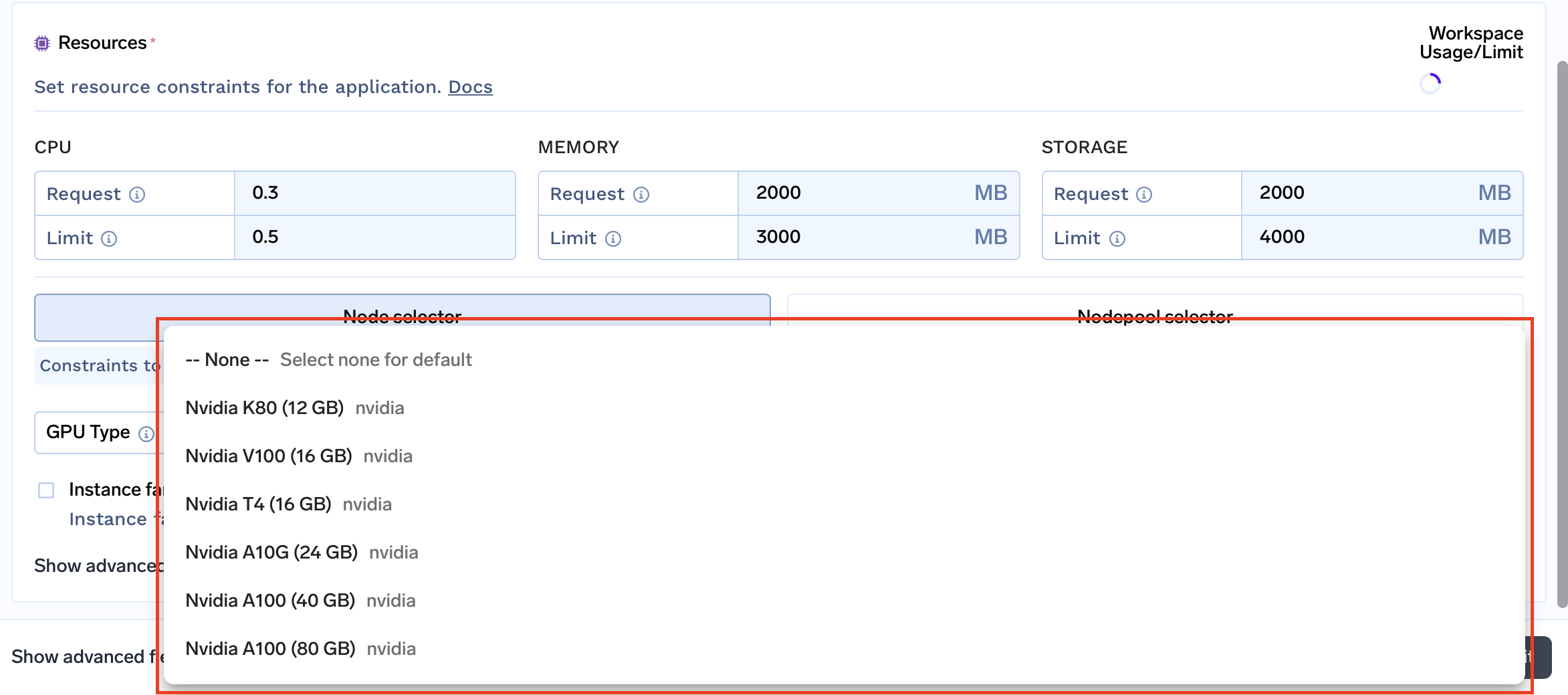
Beschränkungen der Ressourcen: Passen Sie die Ressourcenbeschränkungen für jeden Workspace an, einschließlich CPU, Arbeitsspeicher, Speicher und sogar Instance-Familien. Auf diese Weise können Sie die Ressourcen so zuweisen, dass sie den spezifischen Anforderungen Ihres Projekts oder Ihrer Umgebung entsprechen.
Unterstützte Instance-Familien: Passen Sie Ihren Workspace an bestimmte Leistungsanforderungen und Ihr Budget an, indem Sie die Instance-Familien auswählen, die er unterstützen soll.
Wenn für ein Projekt beispielsweise kein Hochleistungsrechnen erforderlich ist, können Sie größere Instanzen in seinem Workspace deaktivieren. Auf diese Weise wird verhindert, dass Entwickler zu viele Ressourcen bereitstellen, wodurch Geld gespart werden kann.
Unterstützte Knotenpools: Nodepools sind Gruppen von Knoten, die die Rechenressourcen für Ihre Workloads bereitstellen. Sie können die Knotenpools auswählen, die am besten zu Ihren Workloads und Ihrem Budget passen.
Sie können beispielsweise einen Knotenpool mit A100-GPUs erstellen. Dann können Sie diesen speziellen Knotenpool nur für Projekt-Workspaces aktivieren, die Zugriff auf diese Art von GPU benötigen.
Verfolgen Sie die Kosten auf Workspace-Ebene
Wir geben dir außerdem Einblick, sodass du die Kosten auf Workspace-Ebene anhand der vergangenen Nutzung verfolgen kannst. Auf diese Weise können Sie feststellen, welche Projekte oder Umgebungen die meisten Ressourcen beanspruchen und wo Sie Einsparungen erzielen können.
Kosteneinsparungen auf Bereitstellungsebene
Wir bieten erweiterte Funktionen auf Anwendungsebene, mit denen Sie erhebliche Kosteneinsparungen erzielen können:
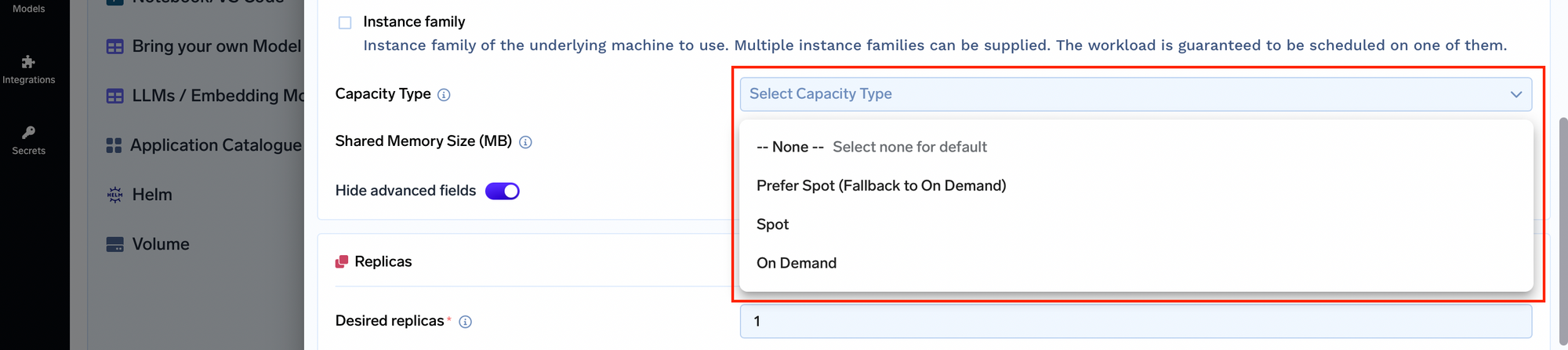
Spot-Instances mit Fallback auf On-Demand: In der Regel haben Anwendungen Schwierigkeiten, Kosten und Zuverlässigkeit in Einklang zu bringen. Mit TrueFoundry können Sie den Kapazitätstyp für Ihre Knoten auswählen, einschließlich Spot-Instances mit Fallback auf On-Demand-Ressourcen. Dadurch wird sichergestellt, dass Ihre Anwendungen auch dann verfügbar bleiben, wenn eine Spot-Instance entfernt wird, und bieten so das optimale Gleichgewicht zwischen Kosten und Verfügbarkeit.
Dienste pausieren: Pausieren Sie Dienste, wenn sie nicht verwendet werden, um Kosten zu sparen. Auf der Seite „Bereitstellungen“ können Sie Dienste ganz einfach anhalten oder wieder aufnehmen.
Optimierung der Ressourcen: Stellen Sie sicher, dass Ihre Ressourcen optimal zugewiesen sind und Ihre Dienste mit der richtigen Kapazität ausgeführt werden.
Überwachung der Ressourcen: Verfolgen Sie die Ressourcenauslastung Ihres Dienstes in Echtzeit, einschließlich der CPU- und GPU-Zuweisung. Erhalten Sie Benachrichtigungen über zu hohe oder zu geringe Bereitstellung und erhalten Sie Ressourcenempfehlungen.
Dynamische Ressourcenanpassung: Passen Sie die Ressourcenebenen im Handumdrehen an, um sie auf eine niedrigere CPU-Ressource zu reduzieren, und stellen Sie Ihren Service entsprechend erneut bereit.
Zeitbasiertes Autoscaling: Planen Sie Ressourcenanpassungen auf der Grundlage der Zeit ein, um die Kosten in nicht produktiven Umgebungen in Zeiten geringer Auslastung zu senken.
💡
Viele unserer Kunden sparen über 60% der Cloud-Kosten ihrer Entwicklungsumgebung ein, indem sie Shutdowns außerhalb der Arbeitszeiten planen und so die Computernutzung um 128 Stunden pro Woche reduzieren.
Kosteneinsparungen auf der Ebene der Code-Editoren
Wir bieten bestimmte Funktionen für Code-Editoren an. Auf Notebook- und VSCode-Ebene können Sie erhebliche Kosteneinsparungen erzielen:
Geteilte Volumes: Verwenden Sie je nach Bedarf Volumes, um große Datenmengen zwischen Notebooks und VSCode-Instances gemeinsam zu nutzen und die Zusammenarbeit zu erleichtern. Gemeinsam genutzte Volumes reduzieren Redundanzen und erhöhen die Effizienz, insbesondere wenn mehrere Benutzer Zugriff auf umfangreiche Daten über Notebooks und VSCode-Instances hinweg benötigen.
Adaptive Ressourcennutzung: Wechseln Sie einfach zwischen CPU und GPU auf derselben Maschine, um die Ressourcenzuweisung zu optimieren. Sie müssen eine GPU-Ressource nicht ständig verwalten, sondern nur bei Bedarf.
💡
Ein Unternehmen für generative KI, das im Bereich der Videogenerierung tätig ist und Hunderte von Jupyter Notebooks auf Spot-Instances für Workloads außerhalb der Produktion ausführt, sparte rund 50-60% an Cloud-Kosten ein, indem es GPUs nur bei Bedarf einschaltete.
Manuelles Pausieren: Pausieren Sie Notebooks/VSCode-Instanzen einfach, wenn sie nicht verwendet werden. Der Code und die Daten bleiben erhalten, sodass bei Bedarf ein reibungsloser Neustart gewährleistet ist.
Automatisches Pausieren: Konfigurieren Sie Ihre Notebooks/VSCode-Instanzen so, dass sie nach einer bestimmten Zeit der Inaktivität automatisch angehalten werden, um wertvolle Ressourcen zu sparen.
💡
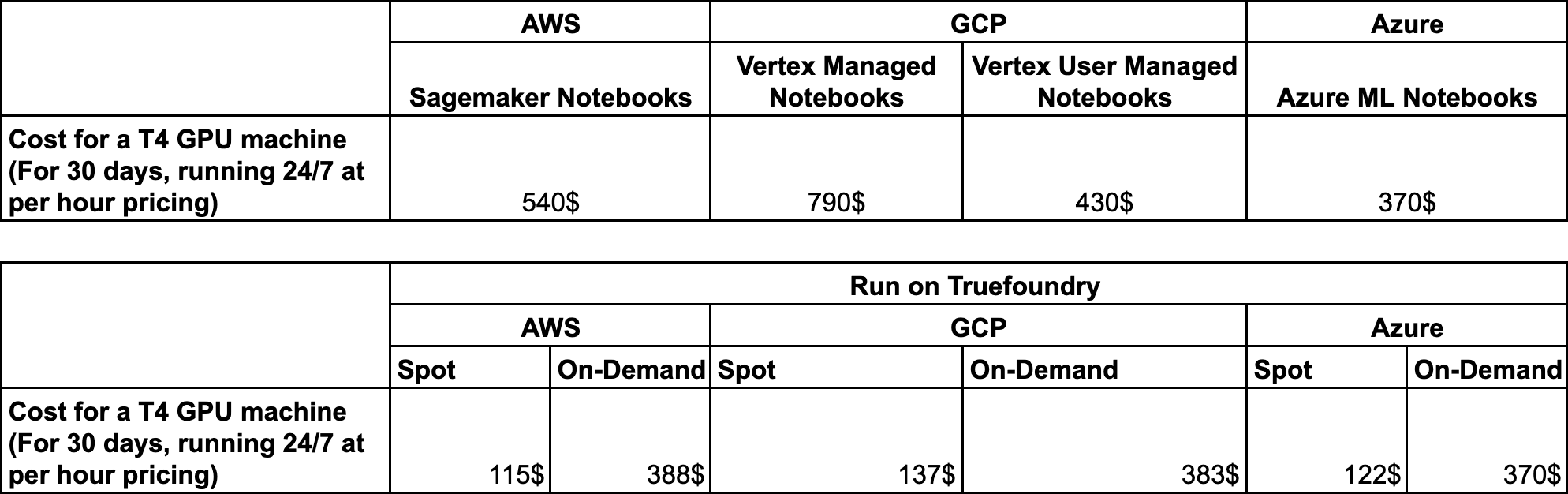
Kosten-Benchmarking Wir haben Benchmarks in AWS, GCP und Azure durchgeführt, um die Kosteneinsparungen zu vergleichen, die sich aus dem Betrieb von Notebooks und VSCode auf Abruf oder der Verwendung der entsprechenden Cloud ergeben.
Kosteneinsparungen bei der Bereitstellung und Feinabstimmung großer Sprachmodelle (LLMs):
Unser Modellkatalog bietet eine praktische Anlaufstelle für den Einsatz und die Feinabstimmung bekannter vortrainierter LLMs. Wir haben diese Schritte unternommen, um sicherzustellen, dass der Einsatz und die Feinabstimmung dieser LLMs so kosteneffizient wie möglich sind:
Optimierte Model Serving-Konfiguration: Basierend auf Benchmarking für verschiedene Modellserver und Ressourcenzuweisungen stellen wir Ihnen vorgefüllte Konfigurationen zur Verfügung, die die beste Latenz und den besten Durchsatz bieten. Dies vereinfacht den Prozess der Bereitstellung von LLMs und hilft Ihnen, Ihre Bereitstellungen ressourceneffizient und kostengünstig zu gestalten.
Effiziente Feinabstimmungskonfiguration: Wir bieten effiziente Methoden zur Feinabstimmung, wie LoRa und Q-LoRa, die dazu beitragen, den Ressourcenverbrauch zu reduzieren und es Ihnen zu ermöglichen, Ihre Ziele zu niedrigeren Kosten zu erreichen.
Skalierbare Bereitstellungen mit Async-Unterstützung: Stellen Sie LLMs in großem Umfang mit asynchroner Unterstützung bereit, um Ihre GPU-Kontingente in allen drei Clouds zu nutzen und zuverlässig die GPUs zu erhalten, die Sie für die Feinabstimmung und Bereitstellung benötigen. Diese zusätzliche Zuverlässigkeit ermöglicht es Ihnen, Spot-Instances zu verwenden und so Geld zu sparen.
Benchmarking Wir haben ein Kosten-Benchmarking durchgeführt, um die Kosten für die Bereitstellung von LLMs auf AWS EKS mit denen von SageMaker zu vergleichen. Weitere Informationen finden Sie im folgenden Blog.
Mehrere Fortune-100-Unternehmen und mittelständische Unternehmen haben durch die Nutzung unserer Plattform erheblich gespart. Einige haben sogar ihre internen SageMaker- oder Cloud-Plattformen durch unser System ersetzt und dabei 30-40% gespart.
In dieser Artikelserie haben wir auch die Leistung vieler gängiger Open-Source-LLMs aus der Perspektive von Latenz, Kosten und Anfragen pro Sekunde bewertet. Du kannst sie dir ansehen unter TrueFoundry-Blogs
Sie können sich auch dieses Video ansehen, um eine Live-Demo aller Funktionen zu erhalten, die wir in diesem Blog behandelt haben:
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last



















































.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




