

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Low-Code-Builder wie Flowise sind stark angestiegen, weil sie schnell sind. Mithilfe der Drag-and-Drop-Oberfläche können Datenwissenschaftler und Produktmanager Eingabeaufforderungen, Tools, Vektorsuche und mehrstufige Agenten miteinander verknüpfen — ganz ohne Python. Machbarkeitsnachweise werden innerhalb von Stunden, nicht in Wochen geliefert. Aber wenn diese Prototypen anfangen, echten Mehrwert zu generieren, kommt die versteckte Steuer zum Vorschein: Jeder Knoten ruft einen anderen Modellendpunkt auf, jeder mit seinem eigenen API-Schlüssel, seinen eigenen Nutzungsprotokollen und seiner eigenen Zeile auf der Unternehmenskarte. Multiplizieren Sie das mit Teams und Experimenten und niemand kann die Grundlagen beantworten: Wer hat was angerufen? Wie viel hat es gekostet? War es sicher?
Genau das löst das TrueFoundry AI Gateway. Es verarbeitet täglich über eine Million LLM‑Anrufe für Unternehmen und wendet dabei Authentifizierung auf Projektebene, Kostenkontrollen pro Anfrage, Latenz-SLOs und vollständige Audit-Trails an — egal, ob Sie GPT‑5, Claude 4, Mistral oder ein internes, fein abgestimmtes Modell verwenden. Die Teams baten uns, die gleichen Leitplanken auch für die Mitarbeiter von Flowise zu verwenden. Also hier ist der ausführliche Blog zu: Warum Low‑Code‑Agenten hinter das Gateway gehören
Das ist dieselbe Regelung, die wir bereits für unternehmenskritischen Traffic (> 1 Million Anrufe/Tag) anwenden. Wenn Sie Flowise hinzufügen, wird es einfach auf Ihre Low-Code-Experimente ausgedehnt. Einen kurzen Blick auf das AI Gateway von Truefoundry finden Sie unter: Verknüpfung
Voraussetzungen
Einrichtung in zwei kurzen Schritten
Eine detailliertere Anleitung mit Screenshots finden Sie in unserem Dokumente
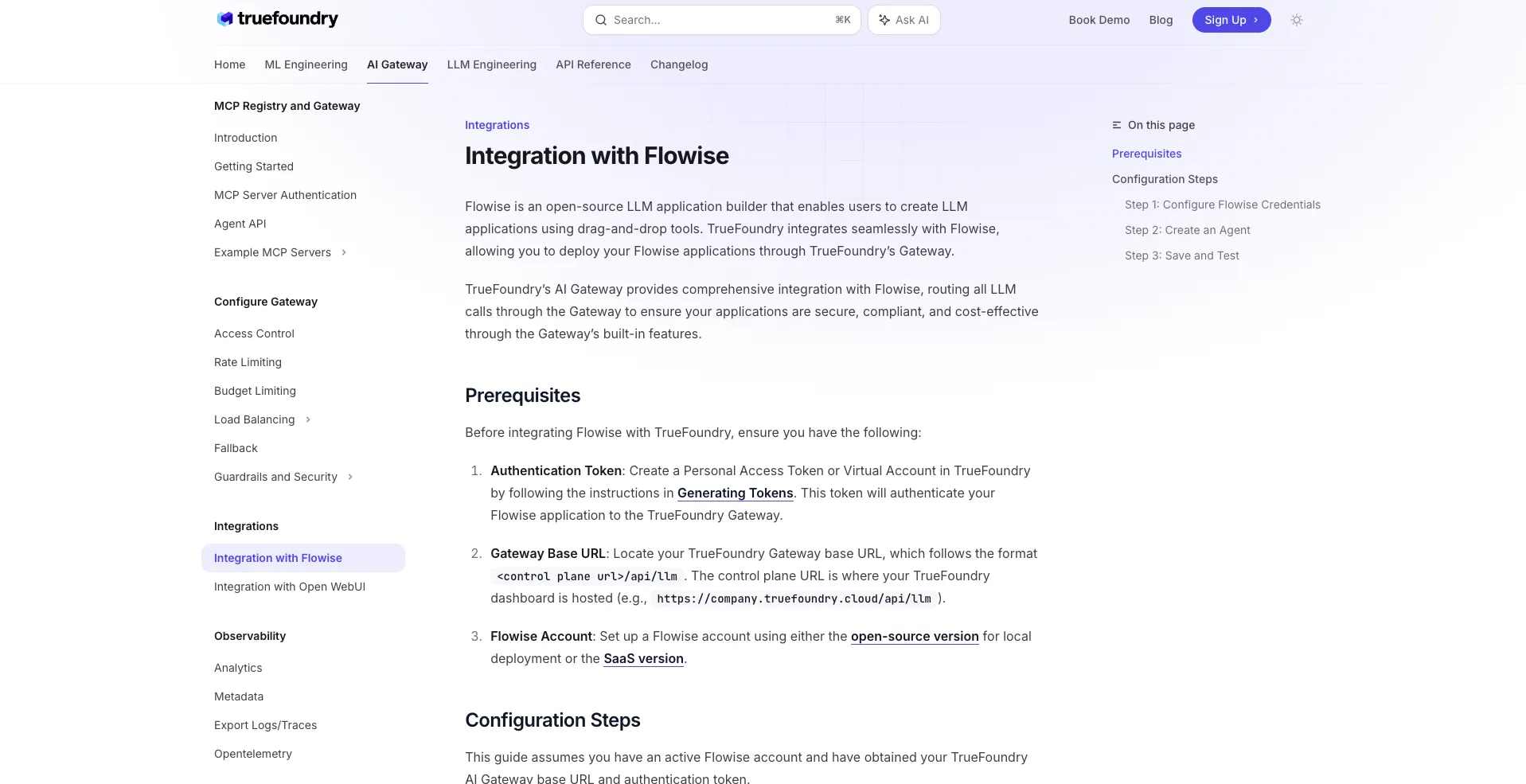
Sobald diese beiden Felder gefüllt sind, erbt Flowise alles, was das Gateway bereits für Produktions-Workloads tut:
Willst du loslegen? Eröffnen Sie hier ein Konto: Wahre Gießerei keine Kreditkarte erforderlich:), folge den Einrichtungsschritten in unserem Schnellstartanleitung, und in etwa 15 Minuten haben Sie einen produktionsbereiten KI-Stack, der läuft. Keine komplexen Migrationen, kein Umschreiben von Code — nur bessere Leistung, Sicherheit und Kontrolle für Ihre KI-Anwendungen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




