



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Sistemas LLM comportam-se como serviços distribuídos. Eles chamam múltiplos provedores de modelo. Eles operam em aplicativos e agentes. Eles são lançados rapidamente e mudam frequentemente. Isso torna a depuração difícil quando um usuário relata uma resposta ruim ou lenta.
A peça que falta é um único limite de execução que cada requisição atravessa. Uma vez que você tem esse limite, você pode aplicar políticas. Você pode padronizar o roteamento. Você pode capturar rastreamentos limpos para cada chamada.
O TrueFoundry AI Gateway oferece esse limite. O New Relic oferece um lugar para explorar esses rastreamentos junto com o restante da telemetria do seu aplicativo. Com o OpenTelemetry como formato compartilhado, você pode exportar rastreamentos do gateway para o New Relic em poucos minutos.
TrueFoundry AI Gateway fica na frente do tráfego do seu modelo. Aplicativos e agentes enviam requisições para o gateway. O gateway as encaminha para o provedor e modelo corretos. Isso cria um ponto de entrada governado para roteamento e controles. Também cria um ponto consistente onde os rastreamentos podem ser gerados e exportados.
New Relic é uma plataforma de observabilidade que suporta monitoramento full stack e monitoramento de desempenho de aplicativos com análises em tempo real. Ele pode ingerir dados do OpenTelemetry. Isso o torna um lugar natural para analisar rastreamentos LLM do gateway com os mesmos fluxos de trabalho que você já usa para serviços e infraestrutura.
A integração é baseada no OpenTelemetry. O TrueFoundry AI Gateway exporta rastreamentos usando protocolos OpenTelemetry padrão. O New Relic aceita a ingestão OTLP. Isso mantém a integração limpa e evita acoplamento forte.
Você configura um exportador de rastreamentos OpenTelemetry na interface do TrueFoundry AI Gateway. Você o aponta para um endpoint de rastreamentos OTLP do New Relic. Você adiciona o cabeçalho de autenticação correto usando uma chave de licença de ingestão do New Relic gerada a partir da integração OpenTelemetry no New Relic.
Uma vez ativado, o gateway continua a gerar rastreamentos para suas próprias visualizações de monitoramento. A exportação é aditiva. Ele encaminha os mesmos rastreamentos para o New Relic para que você possa analisá-los lá também.
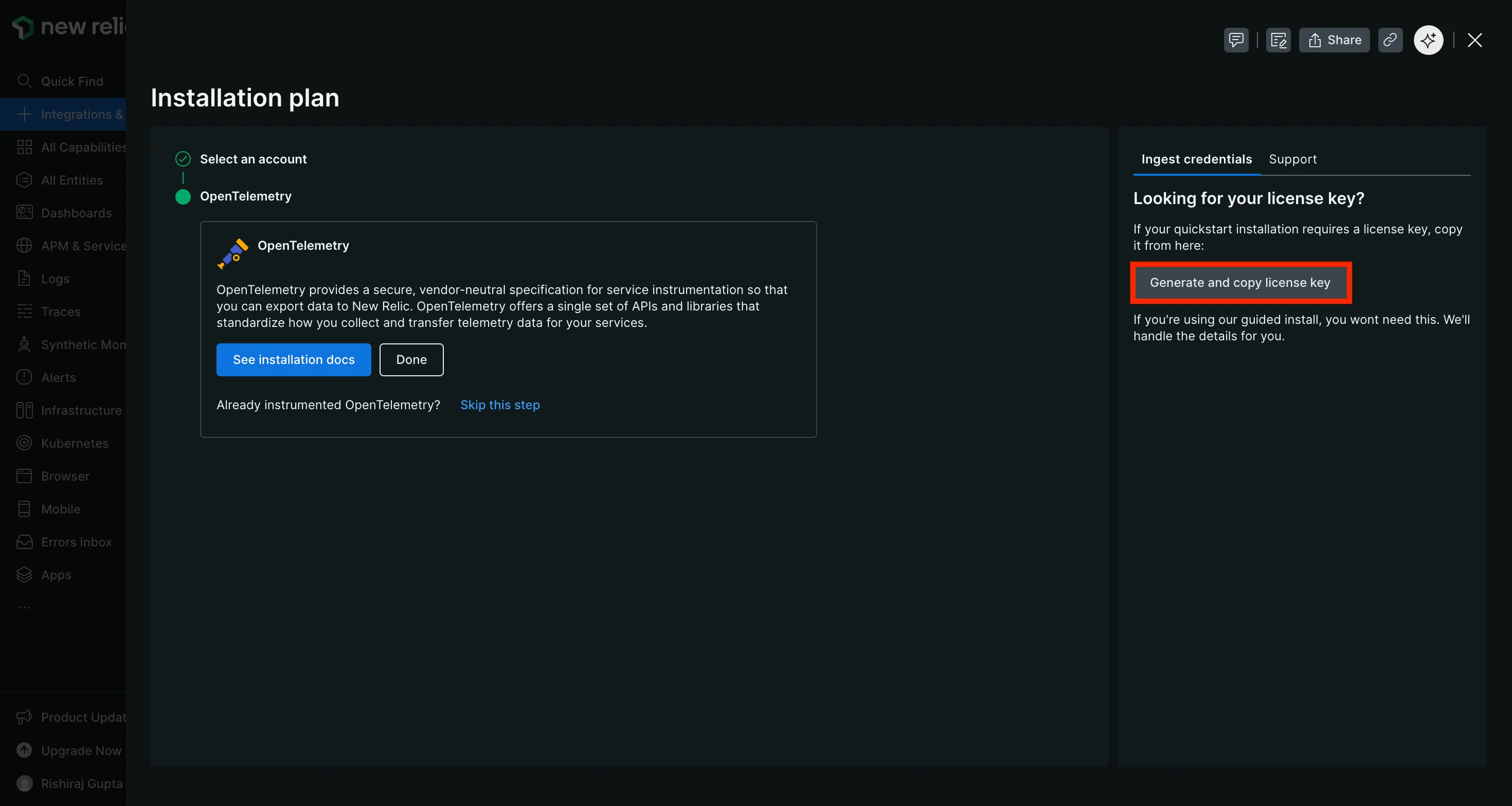
Abra seu painel do New Relic. Vá para Integrações e Agentes. Procure por OpenTelemetry e abra essa integração. No plano de instalação, encontre a área de credenciais de ingestão e gere a chave de licença.
Use a chave de licença de ingestão da página de integração do OpenTelemetry. Uma chave de API regular do New Relic não funcionará para a ingestão OTLP.
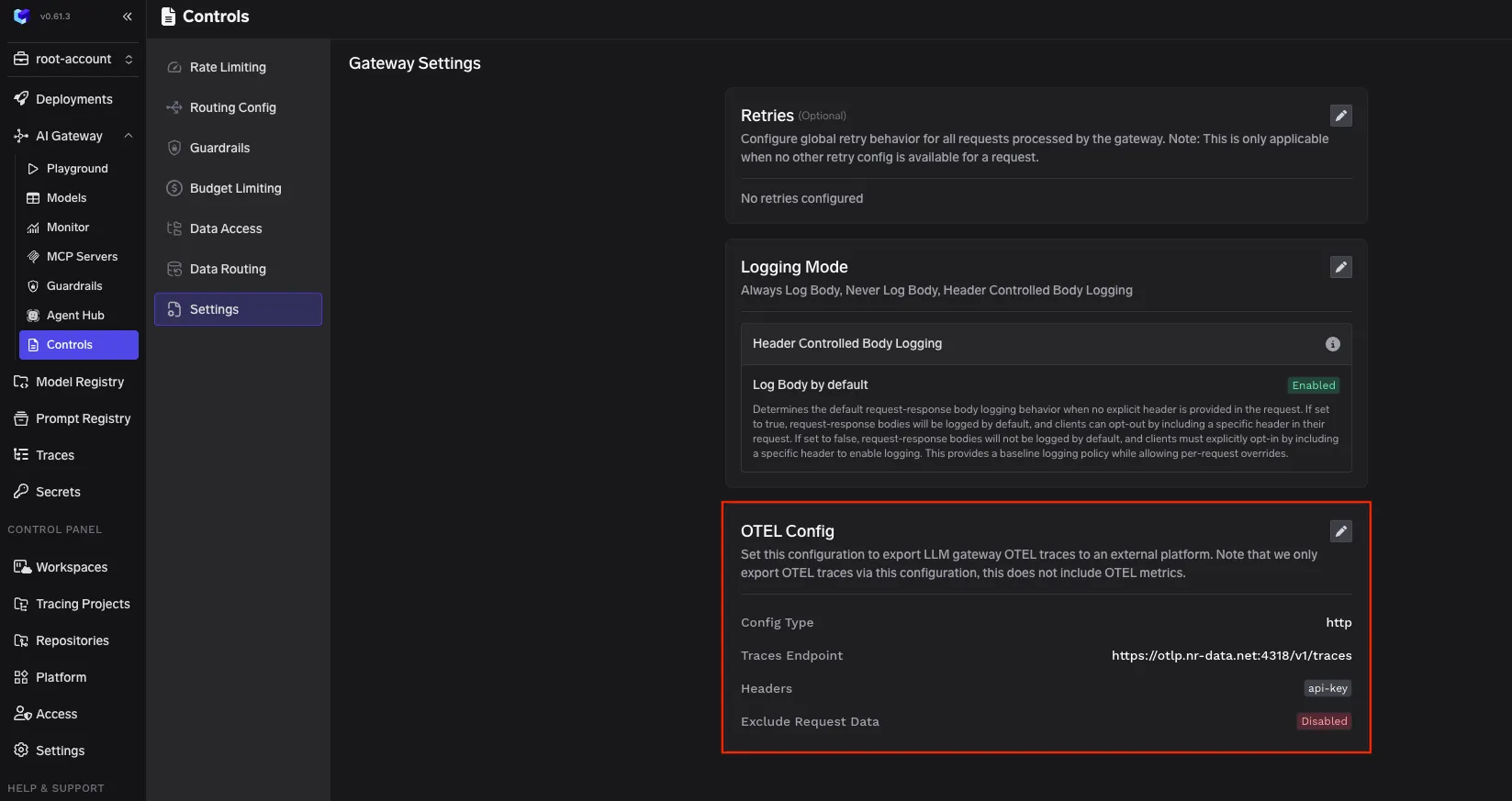
No painel do TrueFoundry, vá para AI Gateway, depois Controles e, em seguida, Configurações. Role até a seção OTEL Config e edite a configuração do exportador.
Ative o exportador de rastreamentos e preencha os campos principais.
Tipo de configuração
http
Endpoint de rastreamentos para a região dos EUA
https://otlp.nr-data.net:4318/v1/traces
Codificação
Json
O New Relic usa endpoints regionais. Se sua conta estiver na região da UE, use este endpoint em vez disso.
https://otlp.eu01.nr-data.net:4318/v1/traces
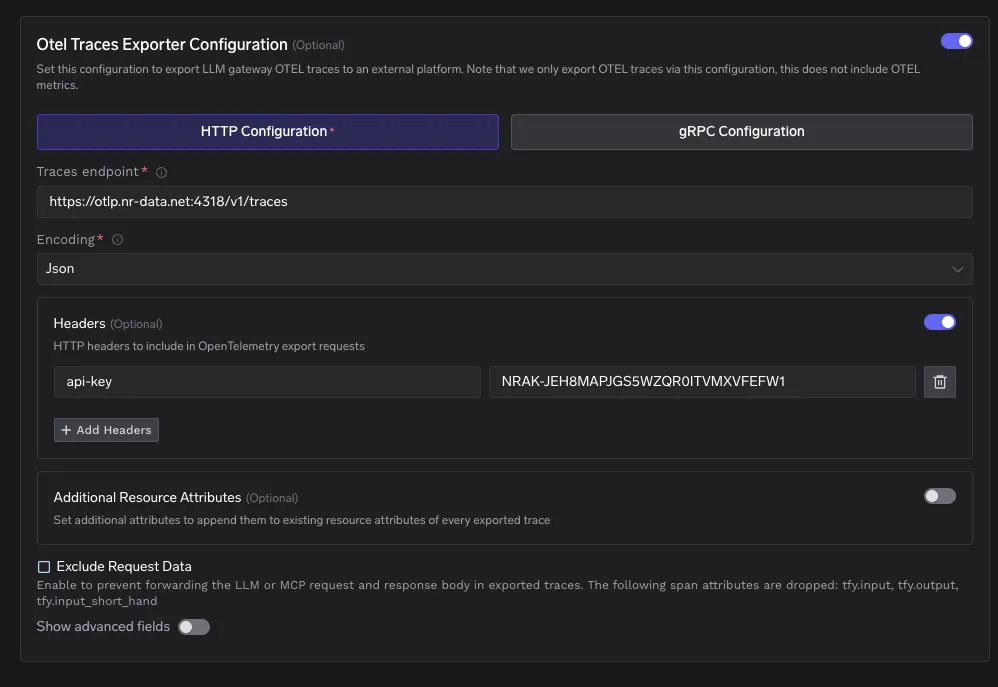
Adicione um cabeçalho com esta chave e sua chave de licença de ingestão como valor.
api-key: <sua chave de licença de ingestão do New Relic>
Salve a configuração. Em seguida, envie algumas requisições LLM através do AI Gateway. Depois disso, o gateway exportará os rastreamentos para o New Relic automaticamente.
No New Relic, vá para Rastreamentos e procure por rastreamentos do serviço de gateway. Em seguida, abra um rastreamento e inspecione os spans para o caminho de chamada do modelo e o tempo.
Você pode visualizar os rastreamentos LLM junto com o restante da sua telemetria. Isso ajuda quando um problema de LLM é, na verdade, um pico de latência upstream. Também ajuda quando uma lentidão do provedor de modelo é apenas uma parte de um incidente mais amplo.
Você pode criar painéis que rastreiam a latência e o volume do tráfego LLM. Você pode criar alertas para picos de latência ou taxas de erro. Você pode correlacionar o comportamento do rastreamento com logs e sinais de infraestrutura durante um incidente.
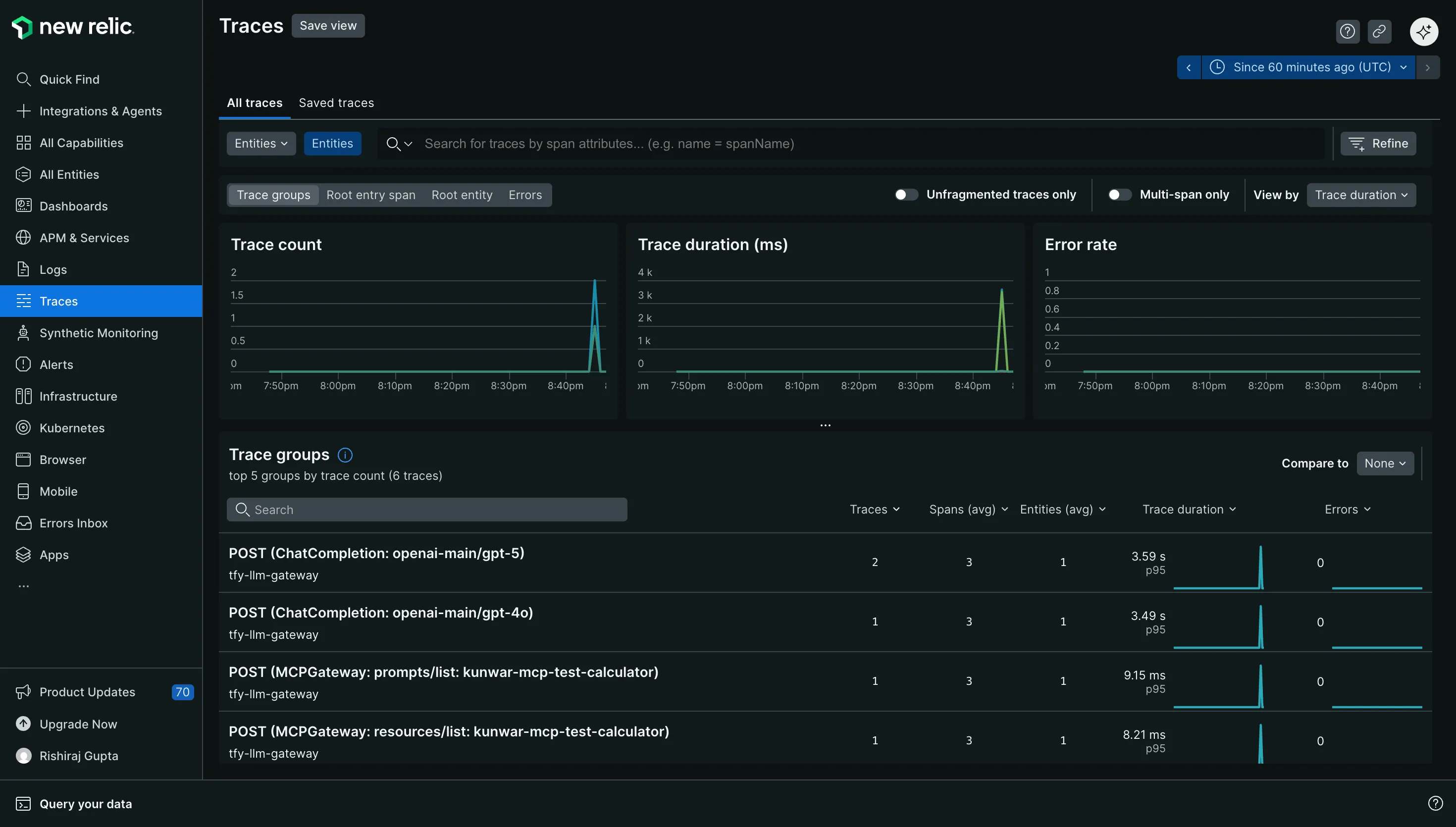
Selecione o endpoint que corresponde à sua região do New Relic. Esta é a causa mais comum de rastreamentos ausentes. Se desejar uma filtragem mais detalhada no New Relic, adicione atributos de recurso adicionais na configuração do exportador. Use esses atributos para agrupamento por ambiente e por equipe.
O New Relic suporta tanto HTTP quanto gRPC para ingestão OTLP. Se precisar de maior taxa de transferência, pode considerar o gRPC. Se desejar uma inspeção mais fácil durante a configuração, HTTP com codificação JSON é um ponto de partida simples.
Um sistema LLM confiável precisa de um local confiável para aplicar controles e um local confiável para entender o comportamento. O TrueFoundry AI Gateway oferece um único limite de execução para todo o tráfego do modelo. O New Relic oferece um fluxo de trabalho de observabilidade maduro para explorar rastreamentos e responder a incidentes. O OpenTelemetry conecta os dois com um caminho de exportação padrão.
Se você já usa o New Relic para seus serviços, esta integração permite que seu tráfego LLM se junte ao mesmo ciclo operacional com alteração mínima no seu código de aplicação.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




