




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 18, 2026
Blazingly fast way to build, track and deploy your models!
O Gerenciamento de Configuração é um aspecto importante da engenharia de software. Este artigo destacará o porquê e o quê do problema e discutirá as diferentes soluções existentes.

A abordagem para gerenciar mudanças de configuração à medida que o aplicativo escala — tanto em termos de tráfego quanto do tamanho da equipe de desenvolvedores. Para ilustrar essa jornada, vamos começar com um aplicativo simples.
Este é um aplicativo de servidor simples que se conecta ao MongoDB e retorna a lista de usuários. O código é apenas pseudocódigo e não se destina a aderir a nenhuma linguagem.

Configuração hardcoded no aplicativo: um GRANDE NÃO!

Codificar o URI do MongoDB diretamente no aplicativo tornará muito difícil executar o aplicativo em qualquer outro ambiente — como nos laptops de colegas de equipe, ou em produção. Devemos seguir a metodologia de aplicativo de 12 fatores aqui para separar a configuração do código.
“ SEPARAR A CONFIGURAÇÃO DO CÓDIGO “
Agora a questão é o que compõe a configuração de um aplicativo? Citando de https://12factor.net/config
A configuração de um aplicativo é tudo o que provavelmente varia entre implantações (ambientes de staging, produção, desenvolvimento, etc). Isso inclui:
1. Manipuladores de recursos para o banco de dados, Memcached e outros serviços de retaguarda
2. Credenciais para serviços externos, como Amazon S3 ou Twitter
3. Valores por implantação, como o nome de host canônico para a implantação
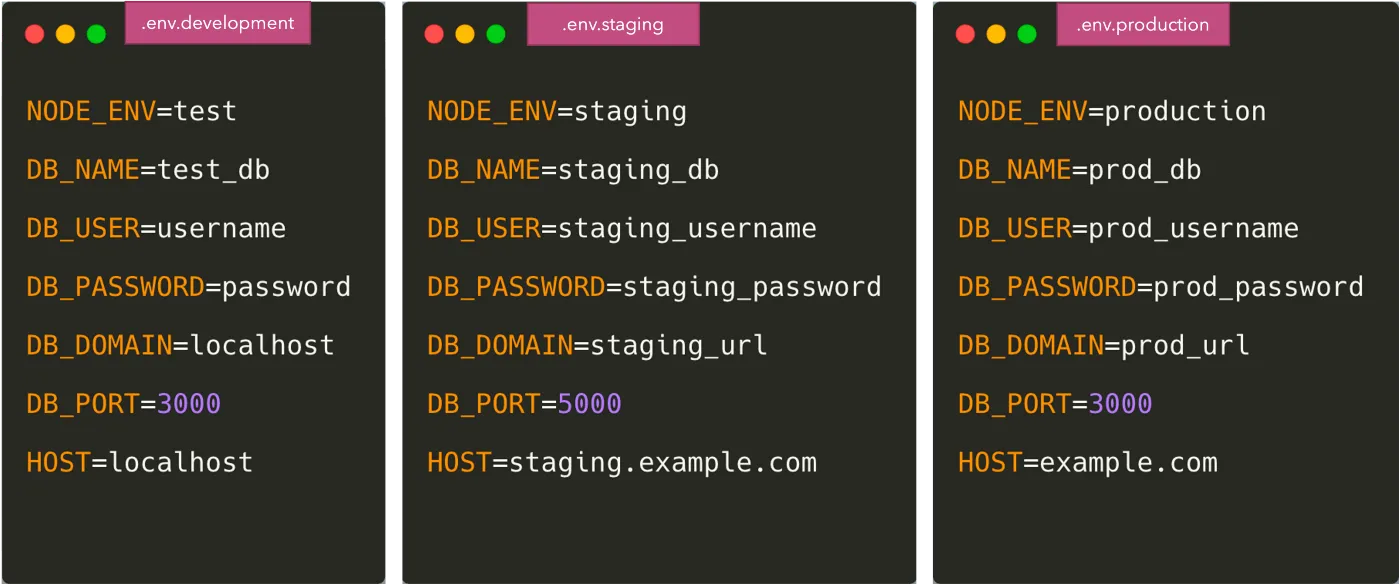
A maneira mais fácil e comum de separar a configuração do código é colocar as variáveis em um arquivo .env.
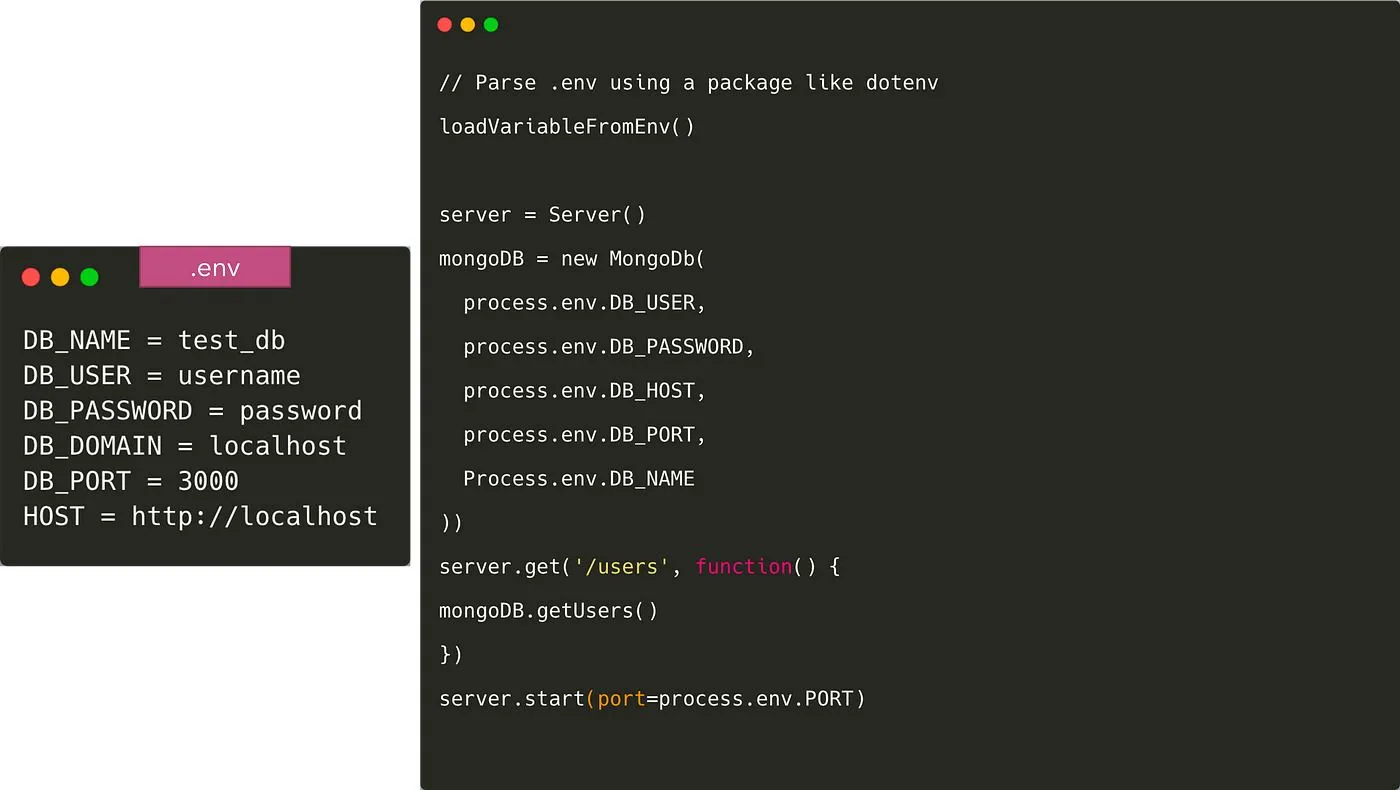
Uma vez feito isso, precisamos carregar as variáveis no código a partir do arquivo .env. Existem vários pacotes para fazer isso, como dotenv e dotenv-expand. Nesse caso, o arquivo .env não é enviado para o Git e cada desenvolvedor sobrescreve a variável de acordo com seu próprio ambiente. Para dar a todos os desenvolvedores uma ideia de quais variáveis de ambiente precisam ser adicionadas, geralmente fazemos commit de um arquivo como .env.example para o Git.

Também precisaremos fornecer os valores dessas variáveis nos ambientes de staging e produção. Quase todos os sistemas de implantação oferecem uma maneira de armazenar e fornecer variáveis de ambiente, como ConfigMap e Secrets no Kubernetes, ou S3 para o Elastic Container Service.
Precisaremos copiar essas variáveis para esses ambientes e mantê-las sincronizadas sempre que os desenvolvedores adicionarem/removerem variáveis de ambiente. Uma abordagem possível é ter um arquivo .env separado para os ambientes de staging, produção, etc.

Pode-se sugerir armazenar esses arquivos no Git, mas há um grande problema de segurança nesse caso — especialmente para algumas das credenciais sensíveis nos arquivos .env.
As pessoas usam abordagens diferentes aqui — no entanto, alguns dos métodos bem conhecidos são:

Ao usar qualquer um desses sistemas externos, dividimos agora a configuração entre os arquivos .env e os secretmanagers. Alguns dos parâmetros não sensíveis virão dos arquivos .env e outros virão do armazenamento remoto de credenciais. Podemos argumentar que podemos armazenar todos os parâmetros no armazenamento remoto — mas isso pode ser um exagero às vezes. Então, o que temos agora é:
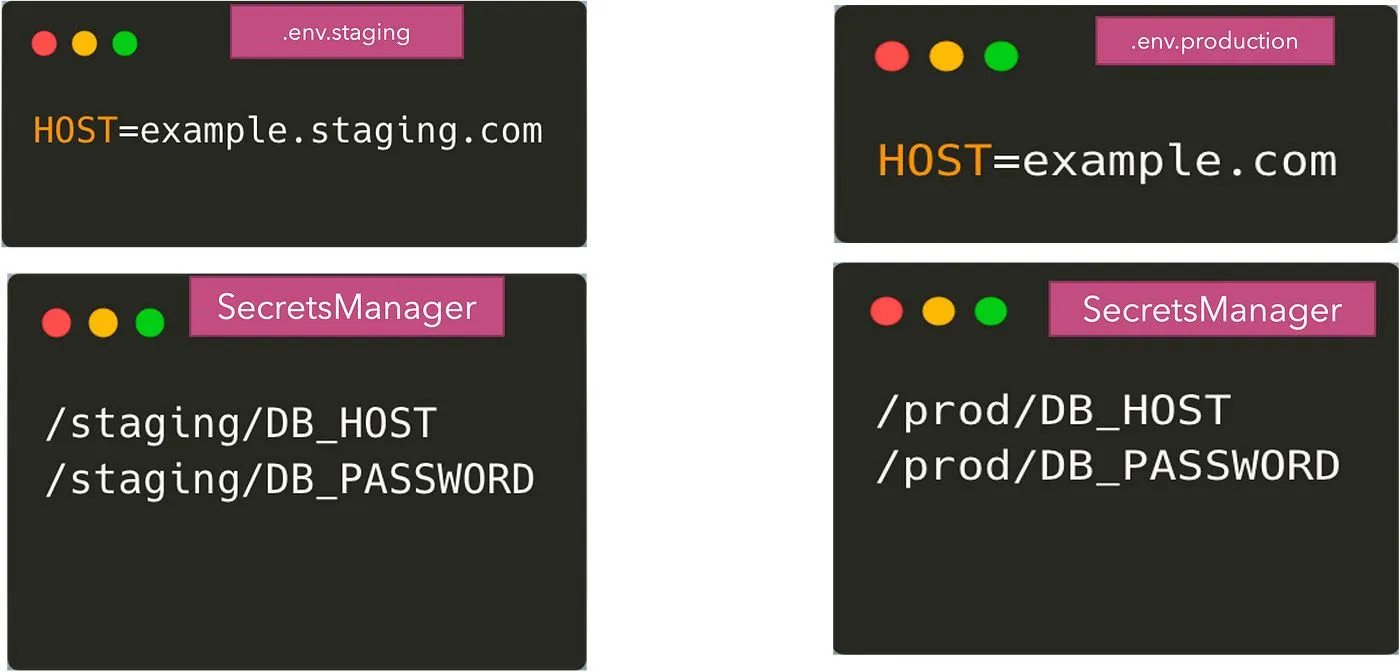
Nossa aplicação agora precisa ter código para ler de ambas as fontes de configuração. A leitura dos arquivos .env pode ser feita usando o pacote dotenv, no entanto, obter as variáveis de ambiente dos secretmanagers exige que usemos suas APIs correspondentes para obter os valores.

Isso resolve a questão de manter nossa configuração segura e também seguir a metodologia de 12 fatores.
No entanto, escrever código de aplicação para obter segredos acaba sendo uma prática repetitiva, onde cada aplicação agora precisa adicionar código específico do secretmanager para obter os valores da API. Isso também significa que, se alguma vez mudarmos nosso provedor de secretsmanager, o código em todas as aplicações precisará ser alterado. Para resolver este problema, podem existir algumas abordagens:
O gerenciamento de configuração é complexo e deve ser feito corretamente desde o início para garantir que a velocidade do desenvolvedor permaneça alta sem sacrificar os aspectos de segurança. O Kubernetes, que é o mais amplamente utilizado hoje para implantar aplicações, vem com seu próprio gerenciamento de configuração e segredos, no qual me aprofundarei em outro artigo. Além disso, se você estiver usando alguma outra forma de gerenciamento de configuração, por favor, mencione nos comentários — adoraria saber mais e aprender com você!
TrueFoundry é um gateway de IA de nível empresarial que engloba um LLM, MCP e gateways de agente, permitindo que as empresas conectem, observem e governem com segurança o acesso a modelos, ferramentas, guardrails e agentes a partir de um único painel de controle. O AI Gateway permite cargas de trabalho agentivas que são:
a) Seguras — resolvendo questões de gerenciamento de chaves, autenticação e autorização
b) Eficientes — otimizando custos, latência e failovers multirregionais
c) Preparadas para o futuro — permitindo conexões unificadas e composíveis entre LLMs, MCPs e guardrails de qualquer provedor
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




