




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
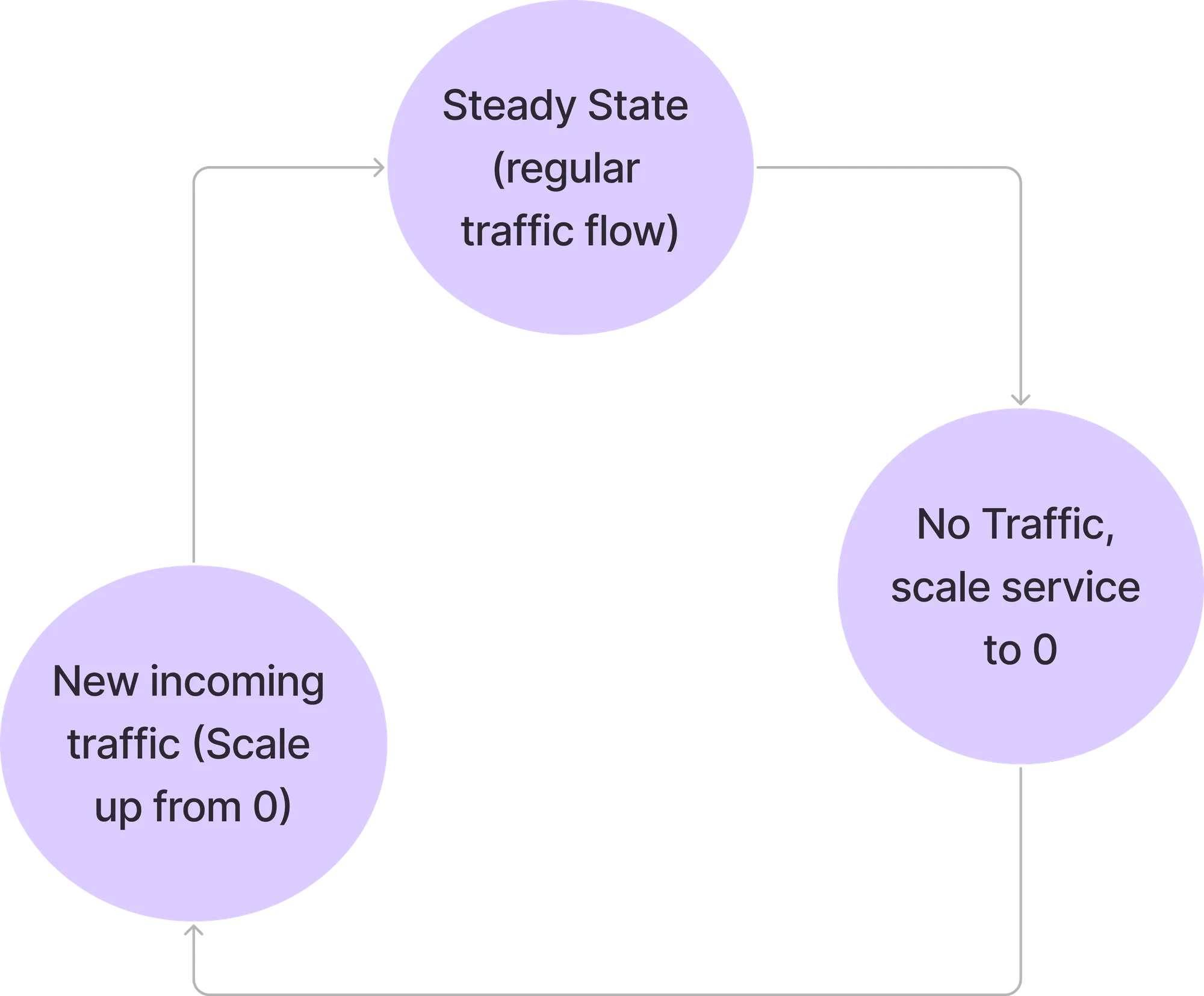
Elasti é uma solução inovadora de código aberto projetada para otimizar o uso de recursos do Kubernetes, permitindo que os serviços sejam reduzidos a zero durante períodos de inatividade e escalados novamente sob demanda. Construído com uma arquitetura de dois componentes — um controlador Kubernetes e um resolvedor de requisições — o Elasti gerencia a disponibilidade do serviço de forma contínua, minimizando custos. Esta publicação visa ser um guia técnico de sua arquitetura, instalação e fluxos operacionais, garantindo que você possa integrar e estender o Elasti de forma eficaz em seus ambientes Kubernetes.
💡Este recurso está incluído no pacote de autoescalonamento da Truefoundry. Para detalhes adicionais, consulte a documentação.
Embora o Kubernetes ofereça recursos robustos de dimensionamento através do HPA e soluções como KEDA, o dimensionamento para zero réplicas continua sendo um desafio. As abordagens existentes geralmente se enquadram em duas categorias:
O Elasti foi criado para abordar essas limitações com três objetivos de design principais:
Elasti é composto por dois componentes principais que trabalham em conjunto para gerenciar a escalabilidade do serviço:
Controlador (Operador):
Resolvedor:
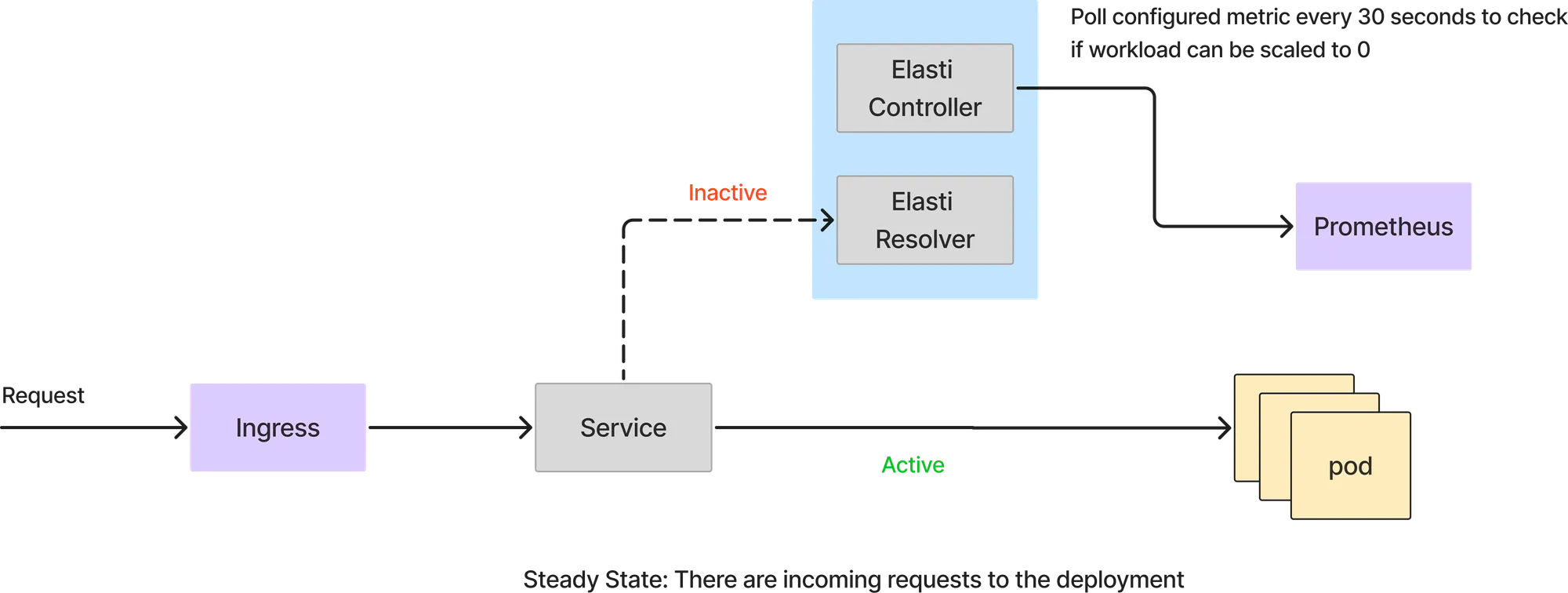
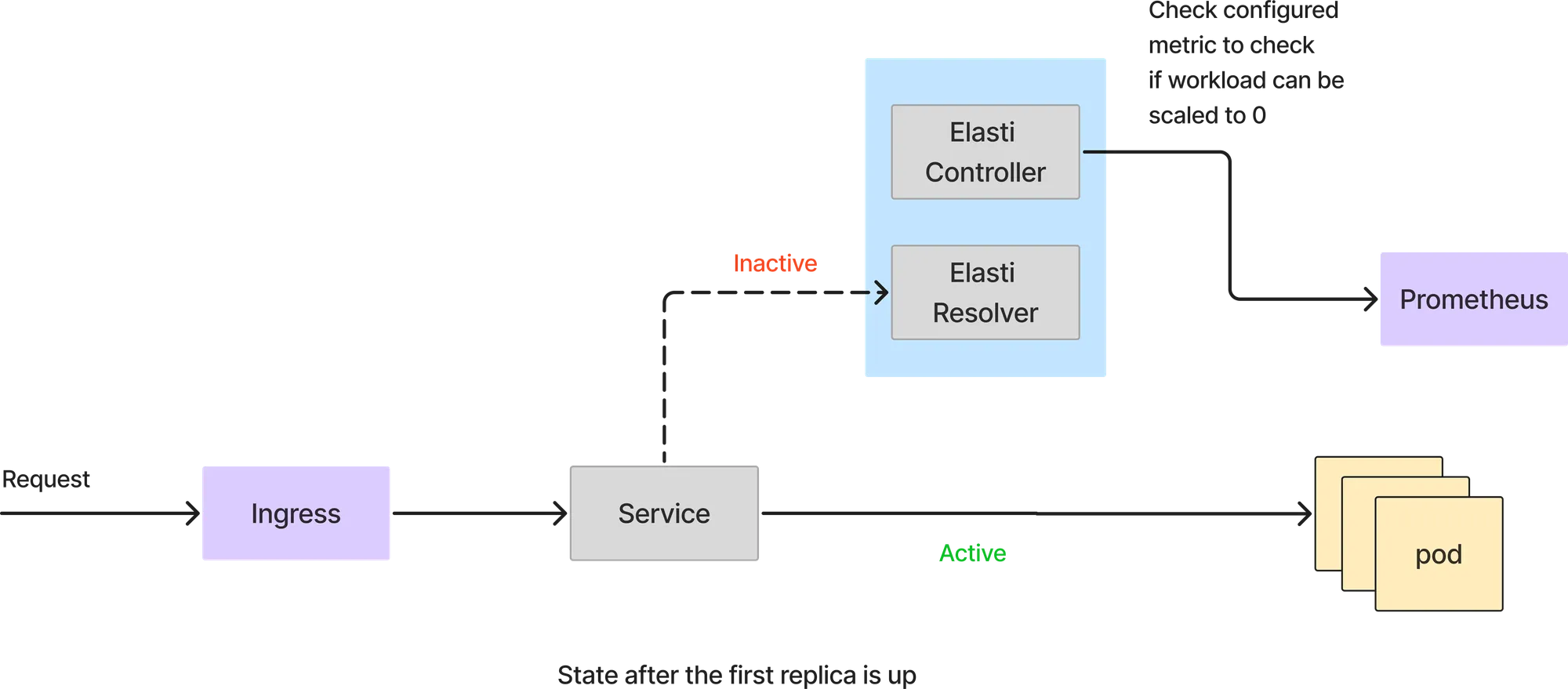
Neste modo, todas as requisições são tratadas diretamente pelos pods do serviço. O resolvedor Elasti não entra no caminho da requisição. O controlador Elasti continua consultando o Prometheus com a query configurada e verifica o resultado com o valor limite para ver se o serviço pode ser reduzido.
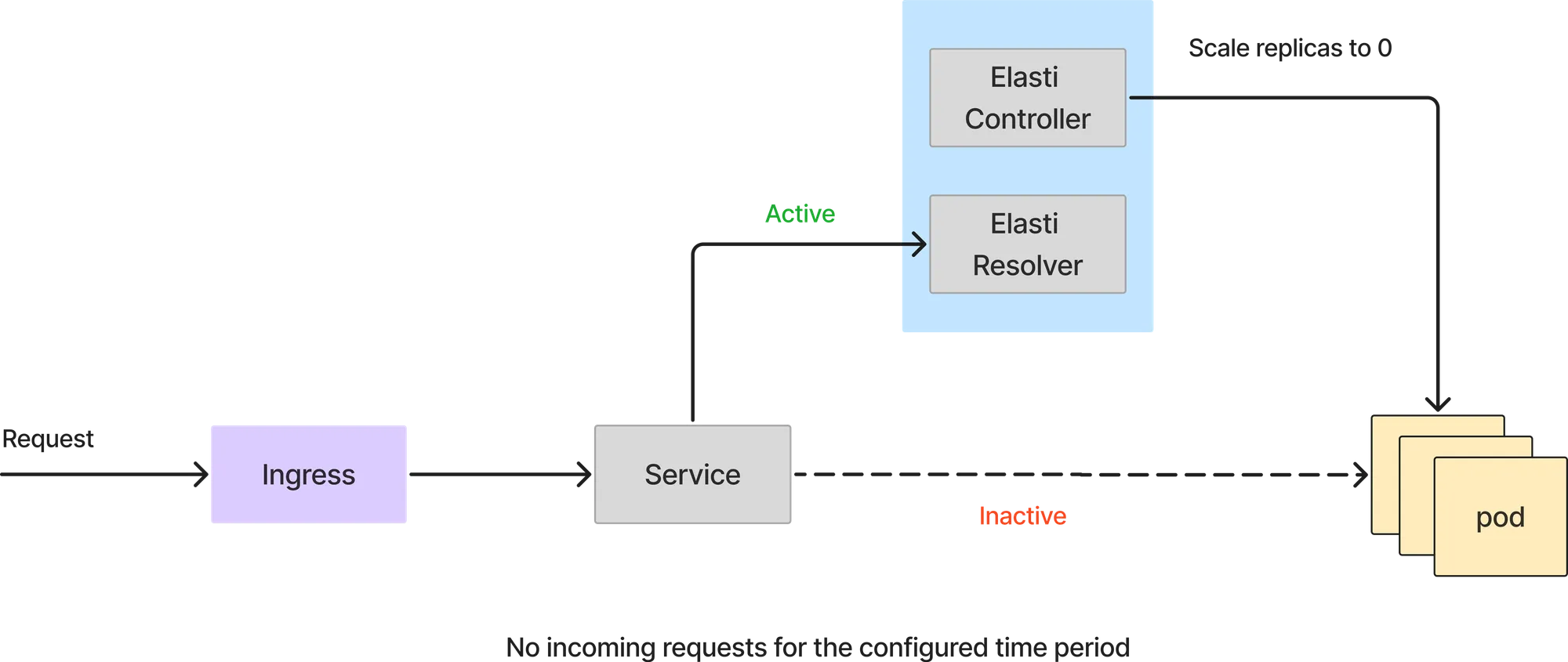
Se a consulta do Prometheus retornar um valor menor que o limite, o Elasti reduzirá o serviço para 0. Antes de escalar para 0, ele redireciona as requisições para serem encaminhadas ao resolvedor Elasti e, em seguida, modifica o Rollout/deployment para ter 0 réplicas. Ele também pausa o Keda (se o Keda estiver sendo usado) para evitar que ele escale o serviço, já que o Keda está configurado com minReplicas como 1.
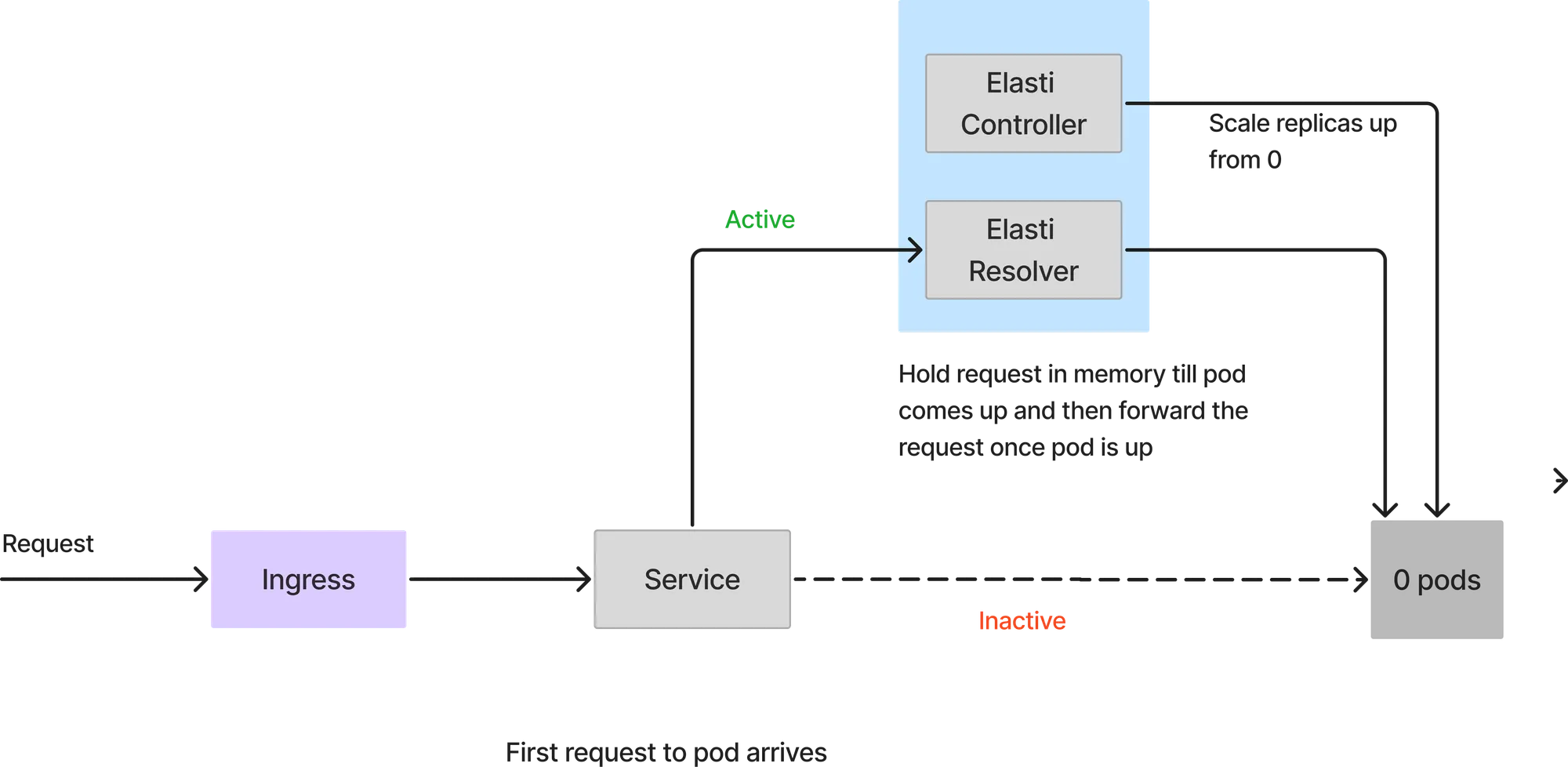
Como o serviço é escalado para 0, todas as requisições atingirão o resolvedor Elasti. Quando a primeira requisição chega, o Elasti escalará o serviço para o minTargetReplicas configurado. Em seguida, ele retoma o Keda para continuar o autoescalonamento caso haja um pico repentino de requisições. Ele também altera o serviço para apontar para os pods de serviço reais assim que o pod estiver ativo. As requisições que chegaram ao ElastiResolver são repetidas por até 6 minutos e a resposta é enviada de volta ao cliente. Se o pod demorar mais de 6 minutos para iniciar, a requisição é descartada.
minikube start
ou
kind create cluster --name elasti-demo
ou
Crie um cluster local com Docker Desktop
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set alertmanager.enabled=false \
--set grafana.enabled=false \
--set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
Instalar e configurar o prometheus no monitoring namespace
Prometheus será usado para ler métricas do nginx ingress, que serão então usadas pelo elasti para consultar métricas, com base nas quais ele decidirá quando escalar um serviço para e de zero.
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true \
--create-namespace
Implanta um controlador nginx no ingress-nginx namespace
O controlador será usado para rotear o tráfego para o nosso serviço httpbin de demonstração.
4. Configurando o Elasti:
helm repo add elasti https://charts.truefoundry.com/elasti
helm repo update
helm install elasti oci://tfy.jfrog.io/tfy-helm/elasti \
--namespace elasti --create-namespace
Instalando o Elasti com helm no namespace elasti
Uma vez que o Elasti esteja instalado, você deverá ver seus dois componentes principais em execução:
Para configurações mais avançadas, consulte values.yaml para ver todas as opções de configuração no arquivo de valores do helm.
kubectl create namespace elasti-demo
kubectl apply -n elasti-demo -f \
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
Implantando um serviço httpbin no elasti-demo namespace
Este serviço httpbin será usado para demonstrar como configurar um serviço para lidar com o tráfego via Elasti.
Crie um arquivo yaml com a seguinte configuração para um ElastiService.
apiVersion: elasti.truefoundry.com/v1alpha1
kind: ElastiService
metadata:
name: httpbin-elasti
namespace: elasti-demo
spec:
minTargetReplicas: 1
service: httpbin
cooldownPeriod: 5
scaleTargetRef:
apiVersion: apps/v1
kind: deployments
name: httpbin
triggers:
- type: prometheus
metadata:
query: sum(rate(nginx_ingress_controller_nginx_process_requests_total[1m])) or vector(0)
serverAddress: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
threshold: "0.5"
demo-elasti-service.yaml
Após a criação do arquivo, aplique o ElastiService
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
Alguns campos chave na especificação do CRD são:
minTargetReplicas: Número mínimo de réplicas a serem iniciadas quando a primeira requisição chega.cooldownPeriod: Tempo mínimo (em segundos) de espera após o aumento da escala antes de considerar a redução da escala.triggers: Lista de condições que determinam quando reduzir a escala (atualmente suporta apenas métricas do Prometheus)scaleTargetRef: Referência ao alvo de escalonamento, semelhante ao usado no HorizontalPodAutoscaler.Para mais detalhes e para configurar um ElastiService para o seu caso de uso, consulte este documento.
Com estas etapas, você agora tem:
Esta configuração ajuda você a testar cenários de roteamento do mundo real e monitorar o desempenho e as métricas do seu tráfego Ingress.
Para testar esta configuração, você pode enviar requisições para o balanceador de carga nginx e monitorar os pods do nosso serviço de demonstração.
kubectl port-forward svc/nginx-ingress-nginx-controller \
-n ingress-nginx 8080:80
Encaminhar porta para o controlador nginx
kubectl get pods -n elasti-demo -w
Monitorar o serviço httpbin
Agora você pode enviar uma requisição para http://localhost:8080/httpbin e você pode ver o serviço sendo escalado para 1 réplica pelo elasti.
curl -v http://localhost:8080/httpbin
Enviar uma requisição para o serviço httpbin
O serviço será então reduzido novamente após nenhuma atividade por cooldownPeriod segundos especificados no ElastiService (5 segundos neste caso).
Para desinstalar o Elasti, você precisará remover todos os ElastiServices instalados primeiro. Então, basta excluir o arquivo de instalação.
kubectl delete elastiservices --all
helm uninstall elasti -n elasti
kubectl delete namespace elasti
O Elasti é a melhor escolha quando você:
O Elasti foi desenvolvido a partir da necessidade de abordar um desafio específico no Kubernetes: implementar uma verdadeira escala para zero sem sacrificar a integridade das requisições ou impor sobrecarga excessiva. Esta solução suporta autoscaling nativo com HPA e KEDA, garantindo que as configurações de serviço existentes permaneçam inalteradas, ao mesmo tempo em que se alcança uma utilização eficiente dos recursos.
Ao tornar esta ferramenta de código aberto, pretendemos oferecer uma solução robusta para ambientes que exigem uma verdadeira escala para zero, zero perda de requisições e uma pegada operacional mínima.
Agradecemos contribuições e feedback da comunidade — explore a documentação de desenvolvimento para mais detalhes.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


Escalar para zero no Kubernetes significa reduzir o número de pods em execução para uma carga de trabalho até zero réplicas durante períodos de inatividade. Quando não há tráfego ou demanda, a implantação não consome recursos de computação e não gera custos de nuvem. Quando uma nova solicitação chega, o sistema escala automaticamente de volta a partir do zero e atende à carga de trabalho.
As principais ferramentas que permitem escalar a zero no Kubernetes incluem KEDA (Kubernetes Event-Driven Autoscaling), que escala com base em fontes de eventos externas como filas e tráfego HTTP, e Knative Serving, que oferece comportamento de escala a zero estilo serverless para cargas de trabalho conteinerizadas. A infraestrutura de implantação da TrueFoundry também se baseia nesses primitivos para oferecer escala a zero para o serviço de modelos de ML, reduzindo os custos de GPU e CPU durante períodos de inatividade.
O Kubernetes não suporta escala para zero nativamente através do seu Horizontal Pod Autoscaler (HPA) integrado, pois o HPA tem uma contagem mínima de réplicas de um. Alcançar a verdadeira escala para zero requer ferramentas adicionais como KEDA ou Knative, que estendem as capacidades de autoescalonamento do Kubernetes para incluir implantações de zero réplicas acionadas por eventos externos ou escalonamento baseado em requisições HTTP.






As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




