



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
É com entusiasmo que anunciamos a integração da Resemble AI com o TrueFoundry AI Gateway, que traz clonagem de voz, conversão de texto em fala síncrona e TTS por streaming para o mesmo caminho de gateway que as equipes já usam para LLMs, embeddings e tráfego de agentes.
Equipes que roteiam tráfego de IA através do AI Gateway da TrueFoundry agora podem conectar a Resemble AI como um provedor de texto para fala de primeira classe através do pass-through nativo do SDK do gateway. As solicitações para o endpoint /synthesize e o endpoint /stream da Resemble fluem pelo caminho do gateway com autenticação centralizada, controle de acesso por equipe, rastreamento unificado de custos e rastreamento completo de solicitações. Nenhuma alteração no código do cliente é necessária, além de apontar a URL base da Resemble para o gateway e autenticar com um token TrueFoundry.
Esta publicação aborda a arquitetura da integração. Ela explica como o TrueFoundry AI Gateway expõe provedores de TTS, como a superfície da API nativa da Resemble é preservada através da camada de pass-through e como o failover entre múltiplos provedores de TTS funciona através de Modelos Virtuais.
TrueFoundry fornece a camada de controle para sistemas de IA em produção. Através do AI Gateway, as equipes centralizam o roteamento de modelos, gerenciamento de chaves, controle de acesso, observabilidade e rastreamento de custos em LLMs, embeddings e provedores de imagem e áudio. Cada solicitação flui através de uma única camada de proxy onde a identidade é verificada, limites de taxa são impostos e rastreamentos são capturados.
O tráfego de TTS em produção tende a se assemelhar ao tráfego de LLM de três maneiras. Múltiplos provedores geralmente estão em jogo porque nenhum fornecedor de TTS único se destaca em todas as dimensões. A latência importa porque os agentes de voz transmitem áudio de volta aos usuários em tempo real. O custo aumenta rapidamente no nível por caractere ou por segundo e se beneficia dos mesmos controles de estorno e orçamento que as equipes já aplicam às conclusões de chat. Os argumentos para colocar um gateway na frente dos provedores de LLM se aplicam diretamente.
Resemble AI é uma plataforma de geração de voz e inteligência de áudio. Seu motor de síntese principal é o modelo Chatterbox, com uma variante Chatterbox Turbo para menor latência e suporte a tags paralinguísticas. A plataforma suporta clonagem de voz, SSML, síntese HD e saída por streaming. A Resemble também expõe produtos adjacentes, incluindo Resemble Detect para detecção de deepfake de áudio, e Audio Edit, Voice Design e Watermark, que podem ser integrados ao fluxo de trabalho de TTS.
Juntas, as duas plataformas oferecem às equipes um único lugar para governar e rastrear a geração de voz ao lado do restante de sua pilha de IA. A TrueFoundry lida com a implantação, roteamento e controle operacional. A Resemble lida com a síntese real. A integração usa o pass-through nativo do SDK da TrueFoundry, que preserva a superfície completa da API da Resemble sem forçá-la a um formato compatível com OpenAI.

O endpoint síncrono de texto para fala da Resemble aceita um pequeno conjunto de campos e retorna áudio juntamente com metadados de tempo. O endpoint de síntese aceita um voice_uuid que seleciona qual voz treinada ou pré-construída usar e um campo de dados contendo texto ou SSML de até 3000 caracteres. Campos opcionais controlam a seleção do modelo através de model (por exemplo, chatterbox-turbo), a precisão do áudio através de precision (um de MULAW ou PCM_16 ou PCM_24 ou PCM_32), o formato de saída através de output_format (wav ou mp3), a taxa de amostragem, o modo HD através de use_hd e o tratamento de pronúncia personalizada através de apply_custom_pronunciations.
O payload da resposta retorna sucesso e um campo audio_content codificado em base64 contendo os bytes de áudio sintetizados. Metadados de tempo chegam em audio_timestamps com caracteres de grafema e tempos de grafema, e caracteres de fonema e tempos de fonema para casos de uso de alinhamento a jusante, como sincronização labial e legendagem. A resposta também informa duration (a duração do áudio em segundos), synth_duration (o tempo de síntese bruto), output_format, sample_rate e quaisquer problemas que o sintetizador tenha sinalizado durante a geração.
Um segundo endpoint em /stream suporta síntese por streaming via HTTP para casos de uso de agentes de voz onde o tempo para o primeiro chunk de áudio é importante. O formato da solicitação é o mesmo. A resposta é um fluxo de quadros de áudio em vez de um único payload base64. A autenticação para ambos os endpoints é um token de portador emitido a partir do console da conta Resemble.
O TrueFoundry AI Gateway é executado no framework Hono e um único pod de gateway lida com mais de 250 solicitações por segundo em 1 vCPU e 1 GB de RAM com aproximadamente 3 ms de latência adicionada. Os pods do gateway são stateless e limitados pela CPU, e escalam horizontalmente para dezenas de milhares de RPS através de pods adicionais. O plano de controle e o plano do gateway são separados. A configuração do provedor, incluindo credenciais, regras de roteamento e limites de taxa, reside no plano de controle e sincroniza com os pods do gateway através do NATS. O caminho real da solicitação permanece na memória, sem chamadas externas além da própria chamada do provedor.
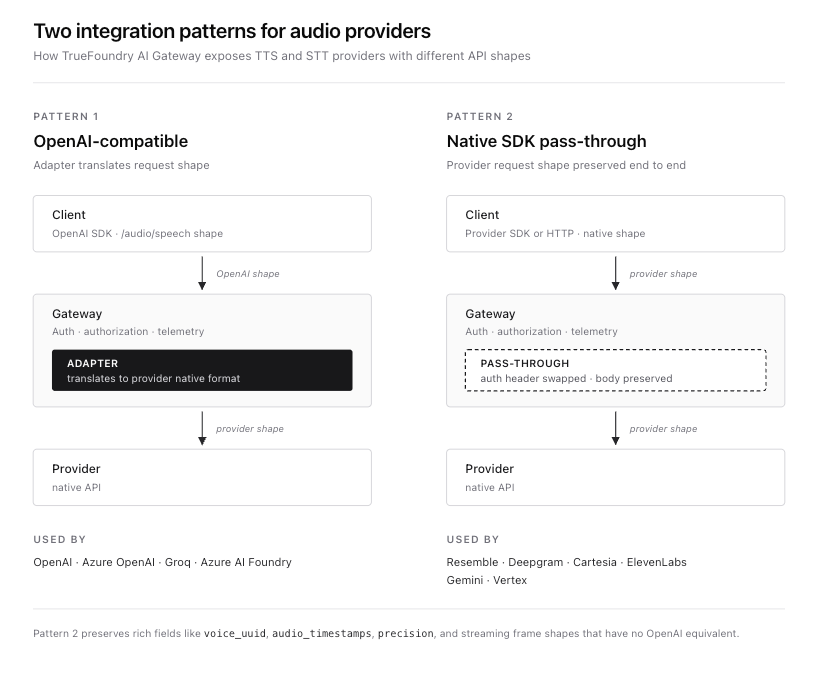
Para TTS, o gateway expõe dois padrões de integração.
O primeiro é o API compatível com OpenAI padrão na URL base do gateway. Provedores que utilizam o formato OpenAI /audio/speech (OpenAI, Azure OpenAI, Azure AI Foundry e Groq) se conectam aqui. Os clientes usam o SDK padrão da OpenAI e o gateway traduz a solicitação para o formato nativo do provedor através de uma camada adaptadora.
O segundo é o pass-through do SDK nativo padrão em {GATEWAY_BASE_URL}/tts/{providerAccountName}. Provedores com APIs nativas ricas que não se encaixam perfeitamente no formato OpenAI (Deepgram, Cartesia, ElevenLabs, Gemini e Vertex) se conectam aqui. O formato completo da requisição e resposta do provedor é preservado. O gateway lida com autenticação, controle de acesso, rastreamento e roteamento, mas não reescreve o payload. Este é o padrão que o Resemble usa porque o corpo da requisição do Resemble, com voice_uuid, audio_timestamps, níveis de precisão e o seletor de modelo chatterbox-turbo, não tem um equivalente no contrato TTS da OpenAI.
Quando uma requisição atinge um pod do gateway, o caminho é o seguinte. O token TrueFoundry no cabeçalho Authorization é validado contra chaves públicas IdP em cache. A identidade da equipe é resolvida contra um mapa em memória e a autorização para a conta do provedor Resemble é verificada. O corpo da requisição é encaminhado para o endpoint de síntese ou stream do Resemble com o token bearer do Resemble anexado no lado do servidor. A resposta é transmitida de volta ao cliente. A interação completa é capturada em um trace span com o nome do modelo, a conta do provedor, a contagem de caracteres de entrada, a duração da resposta, a duração da síntese e a latência. Não há viagens de ida e volta extras além da chamada real do provedor.
O Resemble é registrado no painel de controle do TrueFoundry como uma conta de provedor, com o token bearer do Resemble armazenado como um segredo. Uma vez adicionada a conta, o gateway expõe duas rotas TTS para ela. A rota do SDK nativo em {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize atua como proxy para o endpoint síncrono. A rota de streaming em {GATEWAY_BASE_URL}/tts/{providerAccountName}/stream atua como proxy para o endpoint de streaming. Ambas as rotas preservam exatamente o formato de requisição e resposta do Resemble.
Uma chamada de cliente mínima se parece com o trecho abaixo. Observe que a única mudança em relação a uma chamada direta ao Resemble é a URL base e o cabeçalho de autenticação.
curl -X POST {GATEWAY_BASE_URL}/tts/resemble-prod/synthesize \
-H "Authorization: Bearer ${TFY_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "voice_uuid": "55592656",
"data": "Hello from the gateway.",
"model": "chatterbox-turbo",
"output_format": "mp3",
"use_hd": false }'O código de aplicação existente que visa diretamente o Resemble migra trocando a URL base e o token bearer. UUIDs de voz, payloads SSML, configurações de precisão e modo HD são todos transferidos sem modificação. As bibliotecas cliente oficiais do Resemble podem ser configuradas da mesma forma, sobrescrevendo sua URL base.
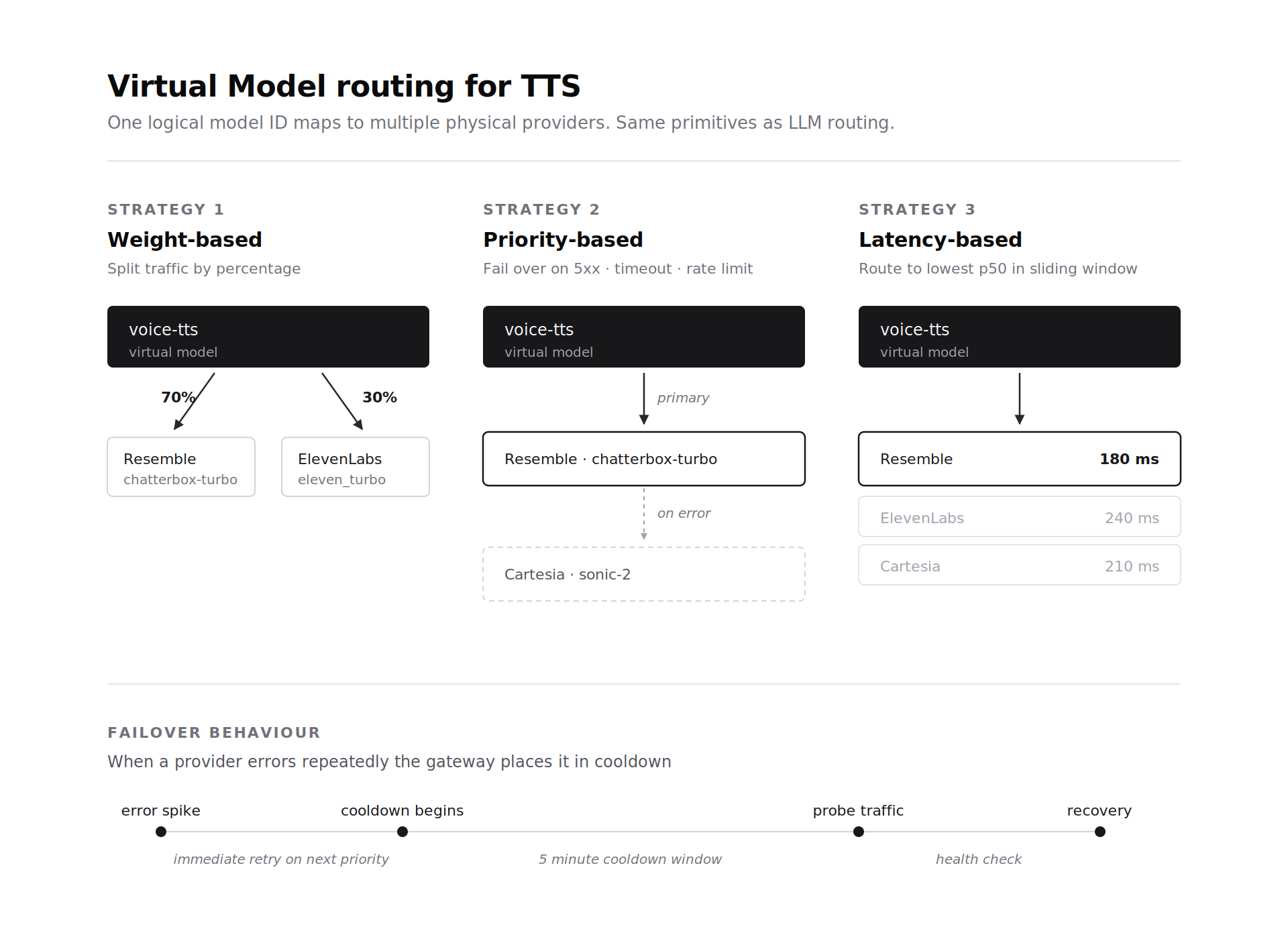
Pilhas de agentes de voz frequentemente executam mais de um provedor TTS em produção por razões de custo e latência. A abstração de Modelo Virtual do gateway se estende aos provedores TTS da mesma forma que se estende aos provedores LLM. Um identificador de modelo virtual mapeia para uma ou mais implantações TTS físicas com regras de roteamento. Baseado em peso o roteamento distribui o tráfego por porcentagem entre os provedores. Baseado em prioridade o roteamento tenta o primeiro provedor e faz failover em caso de 5xx, timeout ou limite de taxa. Baseado em latência o roteamento envia o tráfego para o provedor que tiver a menor latência p50 na janela deslizante.
O failover para TTS funciona com os mesmos primitivos do failover de LLM. Erros não retentáveis acionam uma nova tentativa imediata no próximo provedor de prioridade. Picos de erro colocam um provedor em um período de resfriamento de 5 minutos e o tráfego de sondagem verifica a recuperação. Uma equipe executando o Resemble Chatterbox Turbo como o caminho primário de baixa latência pode fazer failover para Cartesia ou ElevenLabs sem alterar o código do cliente. O Modelo Virtual lida com a seleção.
O rastreamento de custos captura o uso de TTS com a mesma granularidade do uso de LLM. O gateway registra a contagem de caracteres de entrada, a duração da síntese, o modelo, a equipe e o usuário para cada requisição. O serviço agregador calcula os gastos por equipe e por usuário e alimenta os mesmos painéis e primitivos de aplicação de orçamento que já cobrem as conclusões de chat e embeddings. Os limites de taxa são aplicados através do algoritmo Sliding Window Token Bucket com janelas por minuto definidas por usuário, equipe ou modelo. Para TTS, a unidade são caracteres ou requisições, em vez de tokens, mas o algoritmo permanece inalterado.
Cada requisição TTS emite um trace span. Os atributos do span incluem a conta do provedor, o identificador do modelo (por exemplo, resemble-prod/chatterbox-turbo), a contagem de caracteres de entrada, a duração da resposta em segundos, o tempo de síntese bruto, o formato de saída, a taxa de amostragem e a latência do lado do gateway. Os rastreamentos são emitidos assincronamente via NATS e exportados via OTEL para qualquer backend de observabilidade que a equipe tenha configurado (Arize, Langfuse, LangSmith ou qualquer um dos alvos suportados). A opção "Exclude Request Data" (Excluir Dados da Requisição) se aplica da mesma forma que para as conclusões de chat para manter o texto de entrada fora dos rastreamentos exportados quando a privacidade dos dados o exige.
Isso significa que as chamadas TTS aparecem na mesma linha do tempo de rastreamento que a chamada LLM a montante que produziu o texto e a ação do agente a jusante que consumiu o áudio. Para a depuração de agentes de voz, essa consolidação é importante. Uma interação falha pode ser rastreada desde a conclusão do LLM que selecionou a resposta, passando pela síntese TTS que a renderizou, até a ação que o agente realizou em seguida.
De ponta a ponta, o fluxo da solicitação é assim. Um cliente envia uma solicitação TTS para o gateway em {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize ou sua contraparte de streaming com um token de portador TrueFoundry. O gateway autentica o chamador usando chaves IdP em cache, resolve a conta do provedor e verifica a autorização da equipe e do usuário em memória. Se um Modelo Virtual estiver em uso, a lógica de roteamento seleciona um provedor físico com base no peso, prioridade ou latência. O corpo da solicitação é encaminhado para o Resemble com o token de portador do Resemble do lado do servidor anexado. A resposta é transmitida de volta ao cliente, preservando a forma completa do payload do Resemble, incluindo conteúdo de áudio, carimbos de data/hora e metadados de duração. Cada etapa é capturada em um span de rastreamento emitido assincronamente para NATS e exportado via OTEL.
Nada mais precisa ser alterado no aplicativo. Não é necessária uma reescrita de SDK, nem tratamento de autenticação por provedor no cliente, nem um pipeline de observabilidade separado para tráfego de voz. O gateway já está no caminho da solicitação para o restante da pilha de IA e o Resemble se conecta a esse caminho por meio de pass-through nativo. O código de cliente Resemble existente continua funcionando com uma troca de URL base.
Saiba mais sobre o TrueFoundry AI Gateway e a Resemble AI platform. Adicione o Resemble como uma conta de provedor no painel de controle do gateway e chame o endpoint de sintetização ou stream na rota /tts/{providerAccountName} a partir do código de aplicativo existente.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




