



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 8, 2026

Blazingly fast way to build, track and deploy your models!
Ferramentas de codificação assistidas por IA, como o OpenCode, mudam fundamentalmente a forma como os desenvolvedores interagem com o código. Em vez de operar em trechos isolados, esses sistemas raciocinam através de arquivos, dependências e contexto histórico. O resultado é um aumento significativo na produtividade, mas também um novo desafio de custo e escalabilidade que muitas equipes subestimam: o uso de tokens.
Ao contrário das ferramentas de desenvolvedor tradicionais com custos de licenciamento previsíveis, o uso do OpenCode é regido por um modelo de precificação baseado em tokens. Cada interação — geração de código, refatoração, depuração ou revisão — consome tokens. À medida que as equipes escalam o uso entre desenvolvedores, repositórios e agentes automatizados, o consumo de tokens torna-se o principal fator de custo.
O que torna isso particularmente complicado é que o uso de tokens é frequentemente não intuitivo. Pequenas mudanças no tamanho do contexto, na estrutura do prompt ou no comportamento do agente podem resultar em grandes variações no consumo de tokens. Sem um modelo mental claro de como os tokens são usados, as equipes têm dificuldade em prever custos, otimizar fluxos de trabalho ou impor limites.
Este blog detalha como o uso de tokens funciona no OpenCode em um nível técnico, por que as cargas de trabalho relacionadas a código são especialmente intensivas em tokens e o que as equipes de plataforma devem entender antes de escalar o uso em produção.
Em sua essência, o uso de tokens do OpenCode segue a mesma mecânica da maioria dos sistemas baseados em LLM: os tokens são consumidos tanto para entradas quanto para saídas. No entanto, a natureza das cargas de trabalho de codificação introduz uma complexidade adicional.

O uso de tokens do OpenCode pode ser amplamente dividido em duas categorias:
No OpenCode, os tokens de prompt geralmente incluem:
Os tokens de conclusão incluem:
Do ponto de vista do custo, os tokens de prompt são frequentemente o fator dominante no uso do OpenCode, especialmente à medida que os repositórios e os tamanhos de contexto aumentam.
As tarefas relacionadas a código se comportam de forma muito diferente das consultas em linguagem natural. Vários fatores contribuem para um maior consumo de tokens:
Ao contrário dos casos de uso baseados em chat, o OpenCode frequentemente envia:
Mesmo uma base de código “pequena” pode rapidamente se traduzir em dezenas ou centenas de milhares de tokens quando vários arquivos são incluídos.
O código-fonte é denso. Sintaxe, indentação, símbolos e formatação, tudo isso conta como tokens. Alguns milhares de linhas de código podem consumir muito mais tokens do que uma quantidade equivalente de texto simples.
Os fluxos de trabalho do OpenCode frequentemente envolvem:
Cada etapa pode reenviar o contexto ou saídas intermediárias, multiplicando o uso de tokens em uma única tarefa.
Quando o OpenCode é usado via agentes ou automação (por exemplo, refatoração em vários arquivos ou execução em pipelines de CI), o uso de tokens se acumula rapidamente:
Isso torna o uso impulsionado por agentes poderoso, mas também caro se não for limitado.
Um dos maiores desafios com o uso de tokens do OpenCode é que os desenvolvedores raramente veem o contexto completo sendo enviado ao modelo. Editores e ferramentas abstraem:
Como resultado, duas tarefas aparentemente semelhantes podem ter consumos de token drasticamente diferentes. Sem rastreamento explícito no nível da requisição, as equipes frequentemente descobrem problemas de custo somente após picos de uso.
É por isso que entender a mecânica dos tokens não é suficiente por si só. As equipes precisam visibilidade sobre o consumo real de tokens por tarefa, por desenvolvedor e por fluxo de trabalho para tomar decisões de otimização informadas.
A maioria dos picos no uso de tokens do OpenCode não é causada por um único erro óbvio. Eles surgem de como o OpenCode é usado em fluxos de trabalho de engenharia do mundo real — especialmente quando ferramentas e agentes são integrados profundamente em pipelines de desenvolvimento e automação.
Abaixo estão os cenários mais comuns que aumentam desproporcionalmente o consumo de tokens.
Um dos maiores contribuintes para o alto uso de tokens é a inclusão de contexto excessivamente ampla. Muitos fluxos de trabalho do OpenCode incluem diretórios inteiros ou grandes subconjuntos de um repositório por segurança, mesmo quando apenas uma pequena parte do código é relevante.
Exemplos incluem:
Como os tokens de prompt escalam linearmente com o tamanho do contexto, apenas este padrão pode multiplicar os custos rapidamente.
O OpenCode frequentemente opera de forma iterativa: gerar código, revisar, ajustar, regenerar. Em muitas configurações, cada iteração reenvia o contexto completo, incluindo arquivos e saídas anteriores.
Isso leva a:
Sem cache ou reutilização inteligente de contexto, a iteração torna-se um dos padrões mais caros.
Quando o OpenCode é usado através de agentes ou fluxos de trabalho automatizados, o uso de tokens pode escalar rapidamente se a execução não for explicitamente delimitada.
As causas comuns incluem:
Como esses processos frequentemente são executados em segundo plano, as equipes podem não perceber o uso descontrolado até que os custos disparem.
Tarefas de refatoração e revisão tendem a ser mais intensivas em tokens do que a geração de código porque exigem:
Quando essas tarefas são aplicadas em grandes bases de código ou em múltiplos pull requests, o uso de tokens aumenta significativamente.
O uso do OpenCode incorporado em pipelines de CI ou fluxos de trabalho de automação introduz um perfil de risco diferente. Esses sistemas:
Mesmo um uso modesto de tokens por execução pode se tornar caro quando multiplicado por muitas compilações ou implantações.
Finalmente, um dos fatores mais negligenciados do alto uso de tokens é a ausência de visibilidade. Quando as equipes não conseguem ver:
A otimização se torna um palpite. As equipes frequentemente respondem restringindo o uso globalmente, em vez de abordar os fluxos de trabalho específicos que geram custos.
Depois que as equipes entendem de onde vem o uso de tokens, o próximo passo é a otimização. É importante ressaltar que a otimização não se trata de limitar o uso arbitrariamente, mas sim de usar tokens intencionalmente para que os ganhos de produtividade não se transformem em custos descontrolados.
Abaixo estão práticas recomendadas que reduzem consistentemente o uso de tokens OpenCode sem degradar a qualidade da saída.
A alavanca de otimização mais eficaz é controlar qual contexto é enviado ao modelo. Mais contexto nem sempre é melhor, especialmente quando é irrelevante.
Técnicas práticas incluem:
Uma boa regra geral: se um arquivo não é necessário para analisar a mudança, não deve fazer parte do prompt.
Em vez de enviar grandes quantidades de código antecipadamente, as equipes devem caminhar para recuperação sob demanda.
Exemplos:
Essa abordagem reduz o tamanho do prompt ao mesmo tempo que frequentemente melhora a qualidade do raciocínio, já que o modelo recebe informações mais direcionadas.
Prompts genéricos tendem a encorajar um raciocínio mais amplo e saídas maiores, o que aumenta tanto os tokens de prompt quanto os de conclusão.
Melhores padrões:
Prompts com escopo de tarefa não apenas reduzem o uso de tokens, mas também melhoram o determinismo.
Fluxos de trabalho baseados em agentes amplificam o uso de tokens se não forem controlados. Cada agente deve operar dentro de limites claramente definidos.
Principais salvaguardas incluem:
Sem esses limites, os agentes podem reprocessar inadvertidamente grandes contextos várias vezes, aumentando o uso.
Muitos fluxos de trabalho do OpenCode repetem tarefas semelhantes em várias iterações ou entre usuários. O armazenamento em cache pode reduzir significativamente o consumo redundante de tokens.
Cenários aplicáveis:
Mesmo o armazenamento em cache parcial no nível do fluxo de trabalho pode gerar economias significativas.
Embora os tokens de prompt frequentemente dominem, os tokens de conclusão também importam, especialmente em fluxos de trabalho de refatoração ou com muitas explicações.
As técnicas incluem:
Restrições de saída claras reduzem a verbosidade desnecessária.
Finalmente, a otimização não deve ser reativa. As equipes devem monitorar o uso de tokens desde o primeiro dia.
No mínimo, isso significa monitorar:
Sem esses dados, as equipes não conseguem distinguir entre uso produtivo e desperdício.
A maioria das equipes não tem problemas com o uso de tokens do OpenCode no primeiro dia. Os problemas surgem gradualmente à medida que o uso se espalha por desenvolvedores, repositórios e fluxos de trabalho automatizados. O que começa como uma ferramenta de produtividade individual rapidamente se torna uma infraestrutura compartilhada, e o uso de tokens escala de maneiras difíceis de prever ou gerenciar.
Em escala, o OpenCode não é mais usado por um único desenvolvedor em um editor. Ele é usado por:
Cada um desses consumidores gera uso de tokens de forma independente. Sem uma visão centralizada, torna-se difícil responder a perguntas básicas como quem está usando tokens, para qual finalidade, e a que custo.
Os esforços iniciais de otimização são frequentemente implementados no nível da aplicação ou da ferramenta, como limites personalizados de prompt, poda de contexto ou lógica de repetição. Embora estes ajudem localmente, eles não escalam para:
Como resultado, as políticas tornam-se fragmentadas e inconsistentes. Uma equipe otimiza agressivamente enquanto outra, sem saber, aumenta os custos.
A automação muda a matemática. Um fluxo de trabalho que consome um número modesto de tokens por execução pode tornar-se caro quando:
Como esses trabalhos são executados sem visibilidade humana direta, as ineficiências se acumulam rapidamente. Picos de uso de tokens frequentemente se originam da automação, e não do uso interativo.
Sem atribuição granular, as equipes veem apenas números de uso agregados. Isso torna a otimização reativa e ineficaz.
Os modos de falha comuns incluem:
O controle eficaz requer saber quais fluxos de trabalho geram valor e quais geram desperdício algo que as métricas agregadas não conseguem revelar.
Em muitas organizações, a adoção de ferramentas de IA supera a governança. O uso do OpenCode se espalha mais rápido do que:
Quando o uso de tokens se torna uma preocupação, a ferramenta já está profundamente incorporada aos fluxos de trabalho, tornando os controles retroativos difíceis e disruptivos.
A questão central não é o uso indevido - é uso descentralizado sem controle centralizado. À medida que o OpenCode se torna uma infraestrutura compartilhada, o uso de tokens deve ser gerenciado da mesma forma que as equipes gerenciam recursos de computação, armazenamento ou CI.
Isso exige:
Sem essa mudança, o uso de tokens permanece imprevisível e os esforços de otimização continuam reativos.
Uma vez que o uso do OpenCode atinge a escala de produção, o rastreamento ad-hoc e as otimizações manuais deixam de funcionar. Nesta fase, o uso de tokens deve ser tratado como qualquer outro recurso de infraestrutura compartilhada - medido continuamente, governado centralmente e vinculado à responsabilidade.
Muitas equipes começam rastreando o uso de tokens dentro de ferramentas ou fluxos de trabalho individuais. Embora isso forneça uma visão local, rapidamente falha quando:
Cada integração relata o uso de forma diferente, e nenhuma oferece uma visão holística. Como resultado, as equipes de plataforma não têm uma única fonte de verdade para o consumo de tokens.
Em escala, o monitoramento precisa ocorrer no nível de solicitação, não apenas no nível da ferramenta. Configurações eficazes capturam:
Isso permite que as equipes respondam a perguntas como:
Sem essa granularidade, os esforços de otimização permanecem grosseiros e muitas vezes mal direcionados.
A governança começa com a atribuição. O uso de tokens deve ser mapeado para proprietários que possam agir sobre ele.
Os modelos de atribuição comuns incluem:
Uma vez que a propriedade esteja clara, as conversas sobre custos mudam de orçamentos abstratos para decisões concretas sobre quais fluxos de trabalho entregam valor suficiente.
O monitoramento por si só não impede estouros de custos. Sistemas de produção exigem mecanismos de aplicação que operam em tempo real.
As salvaguardas típicas incluem:
Esses controles devem ser aplicados centralmente para que todos os fluxos de trabalho alimentados por OpenCode os herdem automaticamente.
O fio condutor comum em configurações de governança eficazes é a centralização. As políticas de uso de tokens, limites e visibilidade devem residir em um ponto de controle compartilhado, em vez de serem reimplementadas em várias ferramentas.
É aqui que plataformas orientadas para infraestrutura, como TrueFoundry se encaixam naturalmente. Ao centralizar o tráfego de IA, a observabilidade e a aplicação de políticas, as equipes de plataforma podem gerenciar o uso de tokens OpenCode de forma consistente entre desenvolvedores, agentes e sistemas automatizados – sem desacelerar as equipes individuais.
Do ponto de vista da plataforma, o principal desafio com o uso de tokens OpenCode não é entender como os tokens são consumidos, mas onde o controle e a visibilidade devem residir.
A TrueFoundry aborda este problema tratando o uso de IA e LLM, incluindo ferramentas para desenvolvedores como o OpenCode, como uma infraestrutura compartilhada que deve ser observável, governável e consciente dos custos por padrão. No centro desta abordagem está o AI Gateway, que atua como o plano de controle para todo o tráfego de LLM em toda a organização.
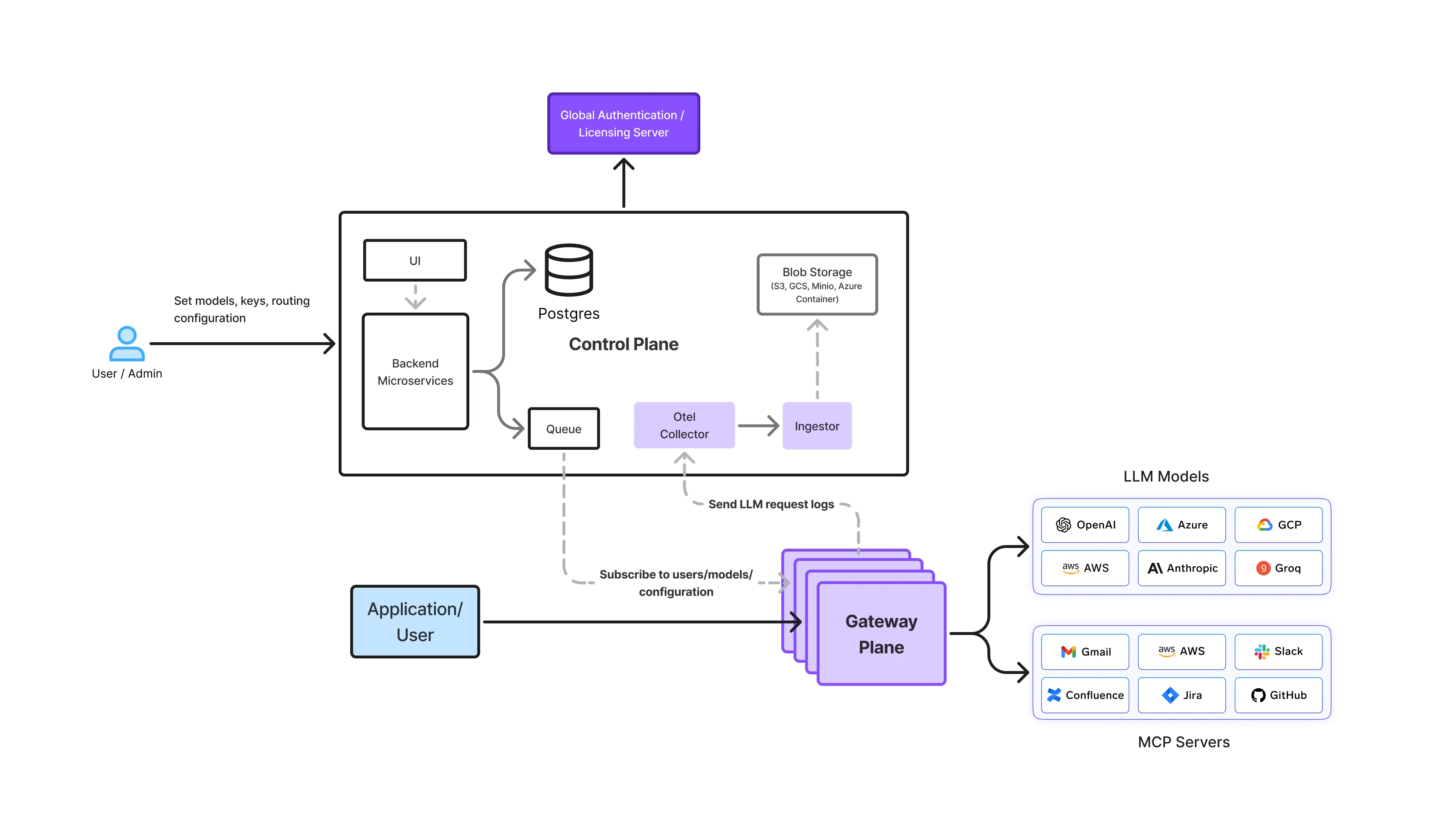
Em uma configuração TrueFoundry, o OpenCode não interage diretamente com os provedores de LLM subjacentes. Em vez disso, todas as solicitações fluem através do AI Gateway, que fornece uma interface única e consistente para inferência.
Arquitetonicamente, isso permite:
Ao remover o acesso direto ao modelo de ferramentas individuais, as equipes de plataforma obtêm visibilidade total sobre como o OpenCode está sendo realmente usado entre desenvolvedores, agentes e automação.
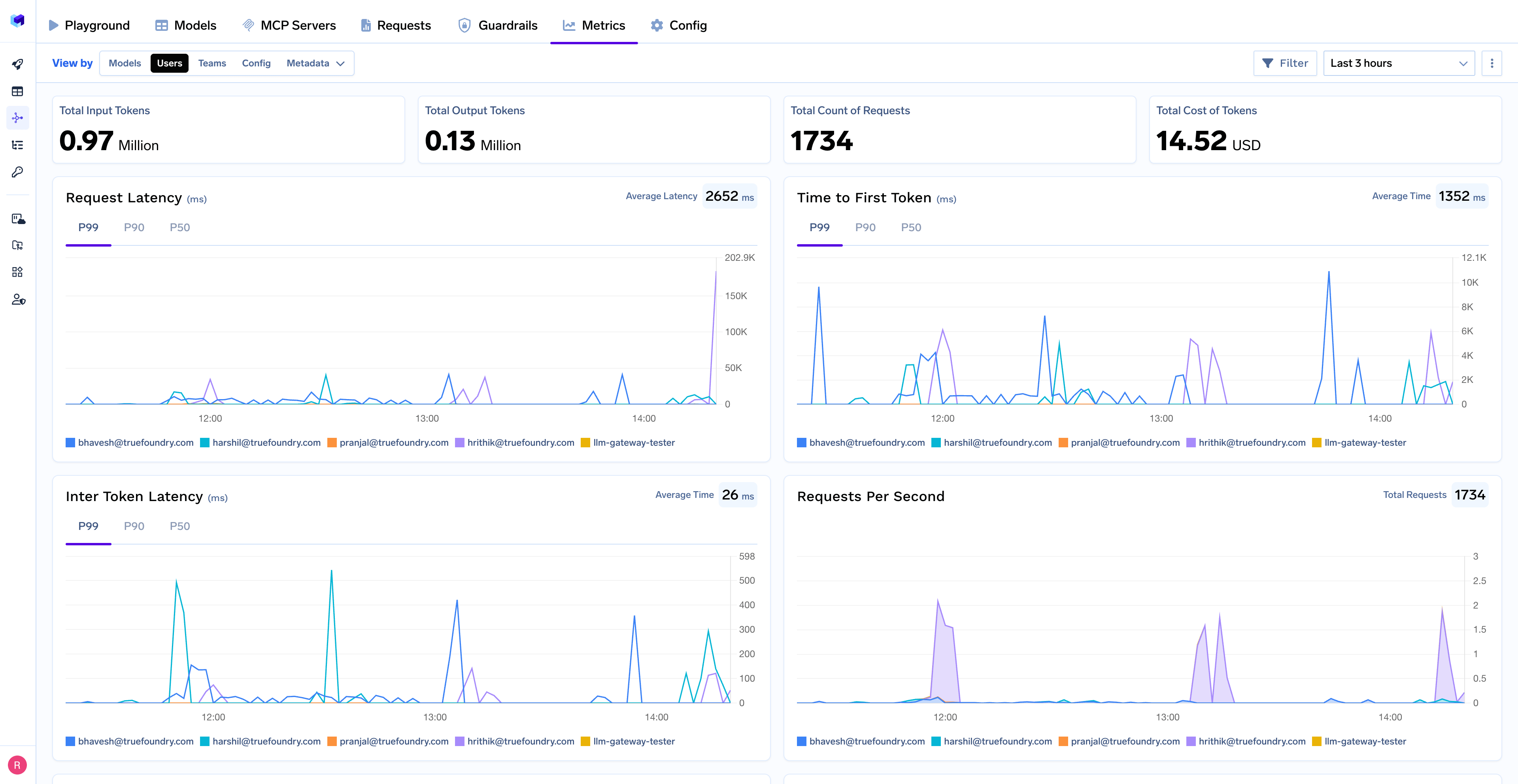
O Gateway de IA da TrueFoundry captura o uso de tokens ao nível do pedido, incluindo:
É fundamental que esta telemetria não esteja bloqueada num sistema controlado por fornecedor. Os registos e métricas são armazenados na própria cloud e armazenamento do cliente, permitindo às equipas:
Isto evita o problema da "caixa preta" comum com ferramentas de IA e torna possível a otimização a longo prazo.
Uma vez que todo o tráfego do OpenCode passa pelo gateway, os controlos de custos podem ser aplicados de forma consistente e em tempo real.
As equipas de plataforma podem:
Essas políticas são aplicadas uma vez no gateway e aplicam-se automaticamente a cada fluxo de trabalho alimentado por OpenCode, sem exigir alterações em editores, plugins ou ferramentas internas.
A arquitetura da TrueFoundry é projetada para ambientes onde o uso do OpenCode se estende além do IDE. Pipelines de CI, tarefas em segundo plano e agentes frequentemente geram o maior e menos visível consumo de tokens.
Ao rotear essas cargas de trabalho pelo mesmo AI Gateway, as equipes podem:
Isso torna possível escalar o uso do OpenCode em toda a organização sem perder a previsibilidade ou o controle.
O uso de tokens OpenCode é a verdadeira restrição de escala para a codificação assistida por IA. À medida que o uso se espalha por desenvolvedores, repositórios, automação e agentes, o consumo de tokens torna-se difícil de prever e controlar sem visibilidade e governança centralizadas.
Gerenciar isso no nível da ferramenta ou aplicação não escala. O uso de tokens precisa de observabilidade no nível da requisição, atribuição clara e aplicação em tempo real, tratando a codificação assistida por IA como infraestrutura compartilhada, não como um recurso isolado.
Plataformas como TrueFoundry refletem essa abordagem ao centralizar o tráfego do OpenCode através de um AI Gateway, permitindo que as equipes monitorem, governem e otimizem o uso de tokens de forma consistente. Para líderes de plataforma e engenharia, a conclusão é simples: se o OpenCode é fundamental para a construção de software, o uso de tokens deve ser gerenciado com o mesmo rigor que qualquer outro recurso crítico de infraestrutura.
Verificar com precisão o uso de tokens do OpenCode requer rastreamento explícito e instrumentação no nível da requisição. Como as ferramentas frequentemente abstraem o contexto completo enviado ao modelo, obter visibilidade do consumo real de tokens por tarefa, desenvolvedor e fluxo de trabalho é crucial para prever custos e otimizar seu uso de forma eficaz.
O uso de tokens Opencode é o modelo de precificação baseado em tokens para ferramentas de codificação assistidas por IA, como o OpenCode. Cada interação, desde prompts de entrada e contexto de código até código gerado e explicações, consome tokens. Gerenciar esse uso de tokens Opencode é crucial, pois se torna o principal fator de custo para equipes de desenvolvimento nos EUA.
Para reduzir o uso de tokens Opencode, limite a injeção de contexto apenas a arquivos essenciais, evitando a inclusão ampla de repositórios. Evite a reidratação repetida de contexto reutilizando saídas de forma inteligente entre as iterações. Divida tarefas complexas em etapas menores e use prompts precisos. Monitorar o consumo de tokens para cada tarefa fornece insights cruciais para otimizar custos e eficiência.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




