







October 26, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Hoje, TrueFoundry está lançando uma Série de Aprofundamento em Machine Learning, onde conversamos com líderes de ML e Ciência de Dados de empresas que utilizam ML para aprofundar nos casos de uso e fluxos de trabalho de ML dentro de suas organizações. Como parte desta série, abordaremos e aprofundaremos na pilha de ML de empresas como Gong, StichFix, SalesForce, Gusto, Simpl, e muitas outras.
📌
Nesta série, mergulhamos no mundo do Machine Learning para desvendar o espectro de aplicações de ML e configurações de infraestrutura em diversas indústrias.
Nossas conversas girarão em torno de quatro temas principais:
1. Casos de uso de Machine Learning para o negócio
2. Como eles construíram sua pilha de Machine Learning, incluindo o Pipeline de Treinamento e Experimentação, Implantação e Servimento, Monitoramento, e como os otimizaram para Custo/Latência ao longo do caminho
3. Desafios enfrentados na construção da pilha de ML, com desafios específicos relacionados à indústria
4. Uma visão geral das inovações de ponta aplicadas durante o processo de construção e escalonamento da infraestrutura de ML.
Para iniciar a primeira discussão da série, conversamos com Noam Lotner da Gong. A Gong é uma plataforma de Inteligência de Receita. Ela permite que as equipes de Receita alcancem seu potencial máximo, revelando a realidade do cliente a partir das conversas da equipe de receita. A Gong analisa as interações com o cliente por telefone, e-mail, web, etc., para fornecer os melhores insights para as equipes de receita, para que elas possam usá-los para fechar mais negócios.
Noam Lotner é Líder da Equipe de Operações de Pesquisa na Gong. Ele está construindo a plataforma operacional para o grupo de pesquisa de IA/ML – automatizando processos de lançamento de modelos, gerenciamento de experimentos e testes de desempenho, construindo ferramentas de rotulagem e criação de conjuntos de dados, e permitindo acesso seguro a fontes de dados de produção.
A Gong analisa as interações com o cliente por telefone, e-mail, web, etc. O Machine Learning se torna ainda mais essencial para analisar as interações de vendas e fornecer insights às Equipes de Receita. Algoritmos de ML podem automatizar tarefas que antes eram feitas manualmente, como análise de videochamadas, transcrição e análise de chamadas telefônicas de vendas. Isso economiza tempo e melhora a eficiência do processo de vendas.
Embora esta seja uma pergunta que fizemos à Gong, vemos que invariavelmente todas as empresas SaaS:
📌
Número de modelos: Número de Clientes X Tipos de Modelos
📌
"Usamos o mesmo modelo base para todos. Também permitimos que os clientes realizem o treinamento de modelos específicos para o seu próprio conteúdo."
Para otimizar custos, a Gong utiliza o serviço de múltiplos modelos na camada de inferência, já que executar modelos separados em máquinas separadas resultaria em um sistema de alto custo.
Aqui está um blog detalhado da Gong que aborda o uso de ML em vendas B2B
Na Gong, o sistema de ML é estruturado de acordo com a organização de ML.
Neste blog (e também na série de chats), vamos aprofundar nos desafios da infraestrutura do lado da Pesquisa para a Gong
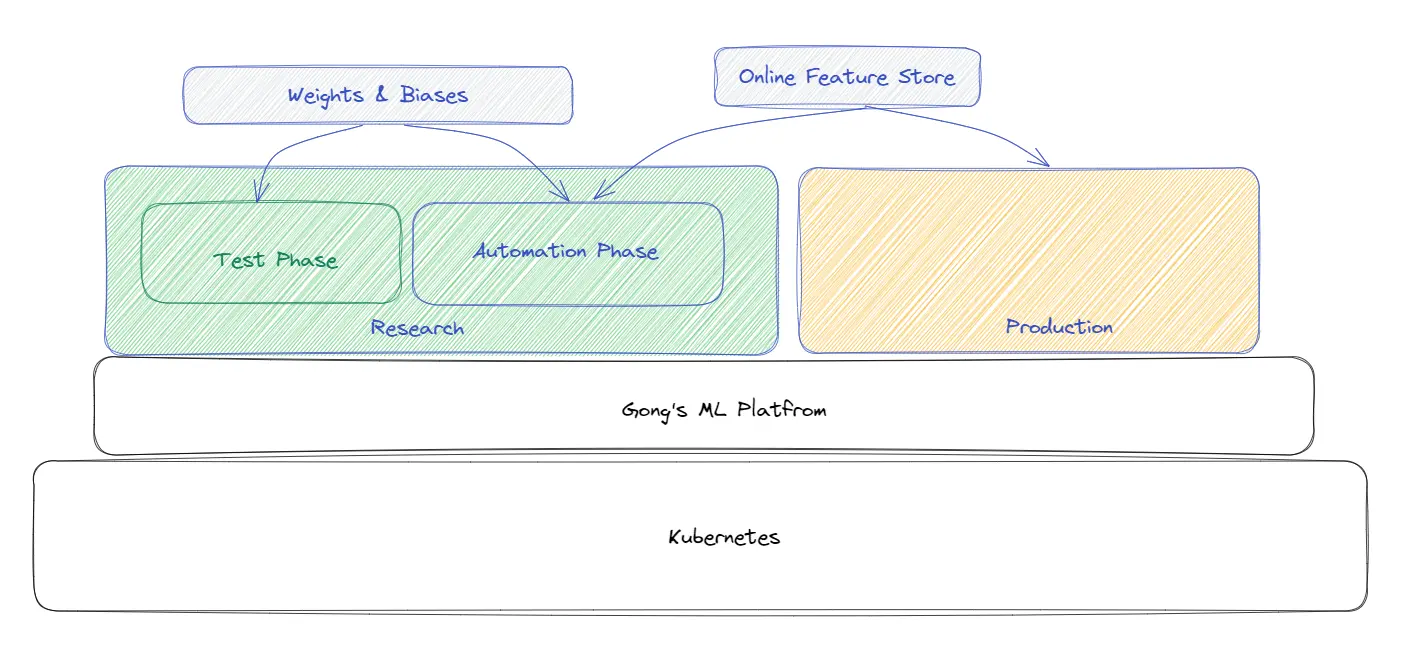
Para permitir que os pesquisadores iniciem máquinas facilmente, toda a pilha é configurada sobre o Kubernetes para a Infraestrutura de Pesquisa. A maioria dos modelos na equipe de pesquisa não utiliza recursos online.
Nuvem: A maior parte da infraestrutura está na AWS e também trabalha com outros fornecedores de nuvem em uma capacidade um pouco menor.
Gerenciamento de infraestrutura: os pipelines estão, na verdade, executando os modelos especificamente para cada cliente. Há uma máquina que é ativada e lida com todas as chamadas dessa empresa.
Tudo o que é feito na equipa de Pesquisa está agora a ser migrado para Kubernetes. Parte do trabalho do Noam é ajudar a sua equipa a obter acesso automático a recursos da cloud Kubernetes. É atualmente um esforço contínuo.
📌
"Eu recomendaria a qualquer pessoa que esteja a entrar nisto que, bem no início da sua jornada, precisa de pensar em escala e precisa de pensar em como o seu grupo vai funcionar"
"Penso que a maioria dos sistemas MLOps exige Kubernetes para gerir os recursos. Não vejo nenhuma plataforma no futuro que possa fazer algo relacionado com MLOps sem usar Kubernetes"
Alguns pontos importantes a considerar:
📌
"A minha perspetiva é que na Gong foi necessário construir esta plataforma"
Nada pode ser mais importante para uma empresa SaaS do que a segurança. O pipeline de ML deve priorizar a segurança devido à privacidade dos dados ao lidar com dados sensíveis de clientes, bem como para controlar o acesso não autorizado.
Esperamos que a 1ª série de artigos do blog TrueML Talks tenha conseguido fornecer-lhe informações valiosas sobre como pode pensar em construir a sua Infraestrutura de Pesquisa de Machine Learning para impulsionar as suas Equipas de ML. #MLOps #MachineLearning #DataScience #DevOps #ModelOps #AIInfrastructure
Aceda ao nosso segundo episódio dos TrueML talks, onde conversamos com o Líder de Plataforma da Stitch. Continue assistindo aos TrueML série do YouTube e encontre todos os episódios da série de blog TrueML aqui -
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, ao mesmo tempo que lhes permite total flexibilidade no teste e implantação de modelos, garantindo total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as Equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos - permitindo-lhes economizar custos e lançar Modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.



.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




