





.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Estamos de volta com mais um episódio do True ML Talks. Neste, mergulhamos novamente nas aplicações de MLOps e LLMs no GitLab e conversamos com Monmayuri Ray.
Monmayuri lidera a área de pesquisa em IA no GitLab com grande foco em LLMs ao longo do último ano. Antes disso, ela foi gerente de engenharia na Divisão de ModelOps do GitLab. Ela também trabalhou em outras empresas como Microsoft, eBay.
📌
Nossas conversas com Monmayuri abordarão os seguintes aspectos:
- Casos de uso de ML e LLM no GitLab
- Evolução da infraestrutura de ML do GitLab para suportar grandes modelos de linguagem (LLMs)
- A Jornada do GitLab com LLMs: Do Código Aberto ao Ajuste Fino
- Treinamento de Grandes Modelos de Linguagem no GitLab
- Triton vs. PyTorch, GPUs em Conjunto e Agrupamento Dinâmico para Inferência de LLM
- Desafios e Pesquisas na Avaliação de LLMs no GitLab
- Arquitetura de LLM do GitLab e o Futuro dos LLMs
A aprendizagem de máquina (ML) está transformando o ciclo de vida do desenvolvimento de software, e o GitLab está na vanguarda dessa inovação. O GitLab está usando ML para capacitar os desenvolvedores ao longo de sua jornada, desde a criação de issues até a fusão de requests e a implantação de aplicativos.
Um dos casos de uso mais empolgantes para ML no GitLab são os grandes modelos de linguagem (LLMs). O GitLab está usando LLMs e GenAI para desenvolver novos recursos para seus produtos, como preenchimento de código e resumo de problemas.
O GitLab tem estado na vanguarda do uso de grandes modelos de linguagem (LLMs) para capacitar desenvolvedores. Como resultado, o GitLab teve que evoluir sua infraestrutura de ML para suportar esses modelos complexos.
Para enfrentar os desafios mencionados acima, o GitLab implementou diversas mudanças na sua infraestrutura de ML. Essas mudanças podem ser categorizadas nas seguintes áreas:
O GitLab tem estado na vanguarda do uso de grandes modelos de linguagem (LLMs) para capacitar desenvolvedores. Nos primeiros dias, o GitLab começou usando LLMs de código aberto, como o gerador de código da Salesforce. No entanto, à medida que o cenário mudou e os LLMs se tornaram mais poderosos, o GitLab mudou para o ajuste fino de seus próprios LLMs para casos de uso específicos, como a geração de código.
O ajuste fino de LLMs exige um investimento significativo em infraestrutura, já que esses modelos são muito grandes e complexos. O GitLab teve que desenvolver novos pipelines de treinamento e implantação para LLMs, bem como novas formas de gerenciar sua infraestrutura de ML em um ambiente distribuído.
Um dos principais desafios que o GitLab enfrentou no ajuste fino de LLMs é encontrar o equilíbrio certo entre custo e latência. LLMs podem ser muito caros para treinar e implantar, e também podem ser lentos para gerar resultados. O GitLab teve que experimentar diferentes tamanhos de cluster, configurações de GPU e técnicas de processamento em lote para encontrar o equilíbrio certo para suas necessidades.
Outro desafio que o GitLab enfrentou é garantir que seus LLMs sejam precisos e confiáveis. LLMs podem ser treinados em grandes conjuntos de dados de texto e código, mas esses conjuntos de dados também podem conter erros e vieses. O GitLab teve que desenvolver novas técnicas para avaliar e desenviesar seus LLMs.
Apesar dos desafios, o GitLab fez progressos significativos no uso de LLMs para capacitar desenvolvedores. O GitLab agora é capaz de treinar e implantar LLMs em escala, e está usando esses modelos para desenvolver novos recursos e produtos que tornarão o processo de desenvolvimento de software mais eficiente e agradável.
Treinar grandes modelos de linguagem (LLMs) é uma tarefa desafiadora que exige um investimento significativo em infraestrutura e recursos. O GitLab tem estado na vanguarda do uso de LLMs para capacitar desenvolvedores, e a empresa aprendeu muito ao longo do caminho.
Aqui estão alguns insights e lições aprendidas da experiência do GitLab no treinamento de LLMs:
Além das informações acima, o GitLab também aprendeu várias lições valiosas sobre a importância de ter um bom entendimento do modelo base e dos dados de treino. Por exemplo, o GitLab descobriu que é importante conhecer a construção do modelo base e como curar os dados de treino para otimizar para o caso de uso desejado.
O GitLab usa o Triton para inferência de LLM porque é mais adequado para escalar para o alto volume de pedidos que o GitLab recebe. O Triton também é mais fácil de encapsular e escalar do que outros servidores de modelo, como os servidores PyTorch.
O GitLab ainda não experimentou os servidores de modelo TGI ou VLLM da Hugging Face, pois estes ainda estavam nas fases iniciais de desenvolvimento quando o GitLab implementou pela primeira vez o seu pipeline de inferência de LLM.
No que diz respeito ao agrupamento dinâmico, a estratégia do GitLab é otimizar para o caso de uso específico, carga, nível de consulta, volume e número de GPUs disponíveis. Por exemplo, se o GitLab tiver 500 GPUs para um modelo de 7B, pode usar uma estratégia de agrupamento diferente da que usaria se tivesse apenas algumas GPUs para um modelo menor.
O GitLab também usa um conjunto de GPUs para lidar com os pedidos. Isso significa que o GitLab usa uma mistura de diferentes tipos de GPUs, incluindo GPUs de alto desempenho e GPUs de menor desempenho. O GitLab faz o balanceamento de carga dos pedidos através do conjunto de GPUs para otimizar o desempenho e o custo.
Aqui estão algumas dicas para projetar uma arquitetura para agrupar GPUs e otimizar o balanceamento de carga:
Aqui estão alguns exemplos específicos de como o GitLab otimizou a sua arquitetura para GPUs em conjunto e agrupamento dinâmico:
Ao seguir estas dicas, você pode projetar uma arquitetura que possa lidar eficientemente com grandes volumes de solicitações de inferência de LLM.
Nós também tentamos o streaming, e acho que estamos analisando a possibilidade de streaming para nossos terceiros também - Monmayuri
Avaliar o desempenho de grandes modelos de linguagem (LLMs) é uma tarefa desafiadora. O GitLab tem trabalhado neste problema e enfrentado vários desafios, incluindo:
O GitLab está abordando esses desafios ao:
O objetivo do GitLab é desenvolver uma abordagem escalável e orientada por dados para avaliar LLMs. Essa abordagem ajudará o GitLab a garantir que seus LLMs estejam com bom desempenho em produção e atendendo às necessidades de seus usuários.
O GitLab também está realizando pesquisas sobre novas formas de avaliar LLMs. Algumas das direções de pesquisa que o GitLab está explorando incluem:
A pesquisa do GitLab sobre a avaliação de LLMs está em andamento. O GitLab está comprometido em desenvolver formas novas e inovadoras de avaliar LLMs para garantir que seus LLMs atendam às necessidades de seus usuários.
A arquitetura de LLM do GitLab é uma abordagem abrangente para treinar, avaliar e implantar LLMs. A arquitetura é projetada para ser flexível e escalável, para que o GitLab possa facilmente adotar novas tecnologias e atender às necessidades de seus usuários.
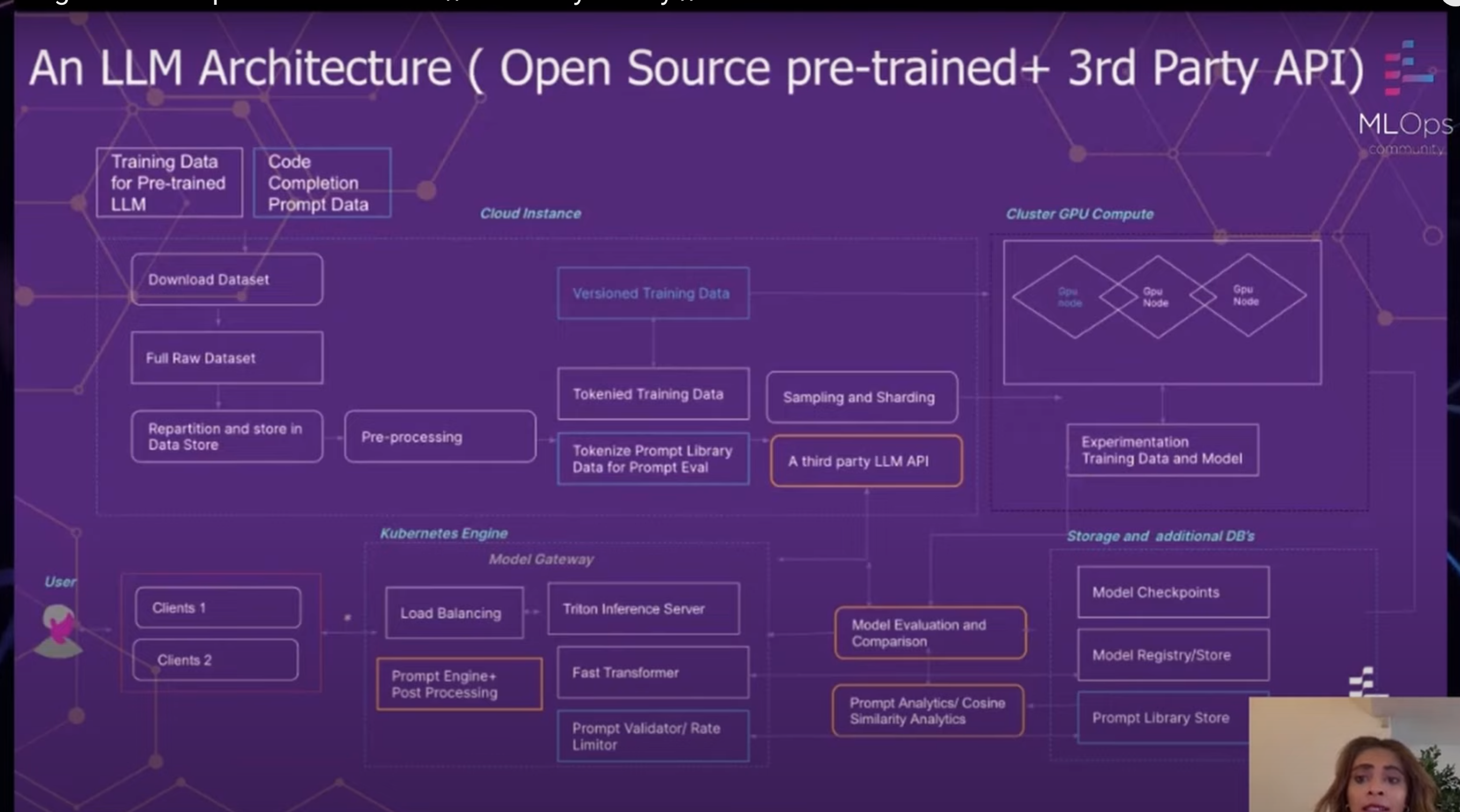
A arquitetura consiste em vários componentes-chave:
A arquitetura de LLM do GitLab é uma ferramenta poderosa que permite ao GitLab treinar, avaliar e implantar LLMs em escala. A arquitetura é projetada para ser flexível e escalável, para que o GitLab possa adotar facilmente novas tecnologias e atender às necessidades de seus usuários.
Os LLMs ainda são uma tecnologia relativamente nova, mas têm o potencial de revolucionar muitas indústrias. O GitLab acredita que os LLMs terão um impacto significativo na indústria de desenvolvimento de software.
O GitLab já está usando LLMs para aprimorar seus produtos e serviços. Por exemplo, o GitLab está usando LLMs para gerar sugestões de código, explicar vulnerabilidades e melhorar a experiência do usuário de seus produtos.
O GitLab acredita que outras organizações também deveriam investir em LLMs. Os LLMs têm o potencial de melhorar a produtividade, a eficiência e a qualidade em muitas indústrias.
O GitLab recomenda que as organizações invistam nas seguintes áreas para se manterem à frente no espaço dos LLMs:
Ao investir nessas áreas, as organizações podem manter-se à frente no espaço dos LLMs e colher os benefícios dessa tecnologia poderosa.
Continue assistindo à série TrueML do YouTube e lendo a série de blogs TrueML.
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, ao mesmo tempo que lhes permite total flexibilidade no teste e implantação de modelos, garantindo total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos – permitindo-lhes economizar custos e lançar modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.







.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




