





July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Neste artigo, fazemos o benchmark do desempenho do LLama2-7B sob a perspectiva de latência, custo e requisições por segundo. Isso nos ajudará a avaliar se ele pode ser uma boa escolha com base nos requisitos de negócio. Observe que não abordamos o desempenho qualitativo neste artigo — existem diferentes métodos para comparar LLMs que podem ser encontrados aqui.
Neste blog, fizemos o benchmark do Llama-2-7B modelo da NousResearch. Esta é uma versão pré-treinada do Llama-2 com 7 bilhões de parâmetros.
A Meta desenvolveu e lançou publicamente a família Llama 2 de grandes modelos de linguagem (LLMs), uma coleção de modelos de texto generativos pré-treinados e ajustados, com escala variando de 7 bilhões a 70 bilhões de parâmetros.
Os principais fatores que usamos como base para o benchmarking são:
Tipo de GPU:
Comprimento do Prompt:
Para o benchmarking, utilizamos o Locust, uma ferramenta de teste de carga de código aberto. O Locust funciona criando usuários/trabalhadores para enviar requisições em paralelo. No início de cada teste, podemos definir o Número de Usuários e Taxa de Criação. Aqui o Número de Usuários significam o número máximo de usuários que podem ser gerados/executados simultaneamente, enquanto a Taxa de Geração significa quantos usuários serão gerados por segundo.
Em cada teste de benchmarking para uma configuração de implantação, começamos com 1 usuário e continuamos aumentando o Número de Usuários gradualmente até vermos um aumento constante no RPS. Durante o teste, também plotamos os tempos de resposta (em ms) e total de requisições por segundo.
Em cada uma das 2 configurações de implantação, utilizamos o servidor de modelo huggingface text-generation-inference com version=0.9.4. A seguir estão os parâmetros passados para a imagem text-generation-inference para diferentes configurações de modelo:
Latência, RPS e Custo
Calculamos a melhor latência com base no envio de apenas uma requisição por vez. Para aumentar o throughput, enviamos requisições em paralelo ao LLM. O throughput máximo ocorre quando o modelo é capaz de processar as requisições de entrada sem deterioração significativa na latência.
Tokens Por Segundo
LLMs processam tokens de entrada e geração de forma diferente - por isso, calculamos a taxa de processamento de tokens de entrada e de saída de forma diferente.

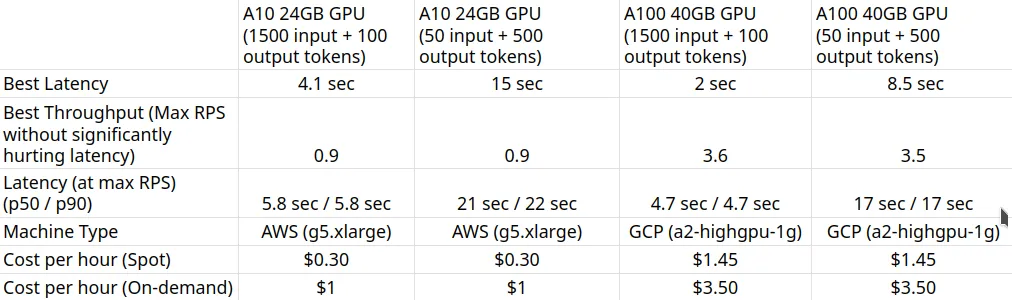
GPU A10 de 24GB (1500 tokens de entrada + 100 tokens de saída)
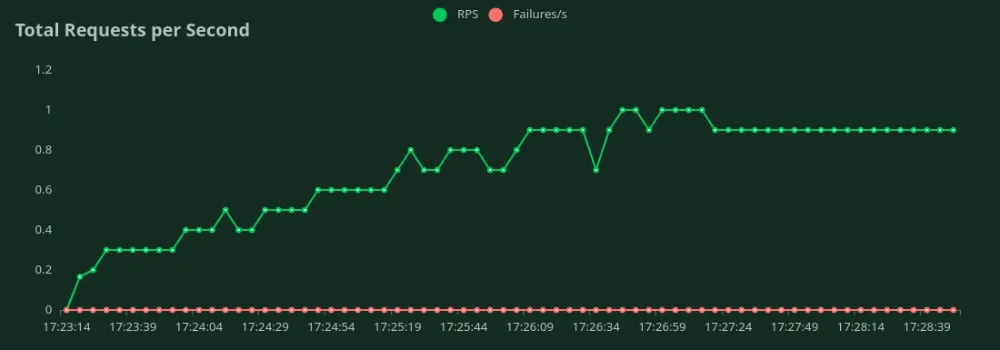
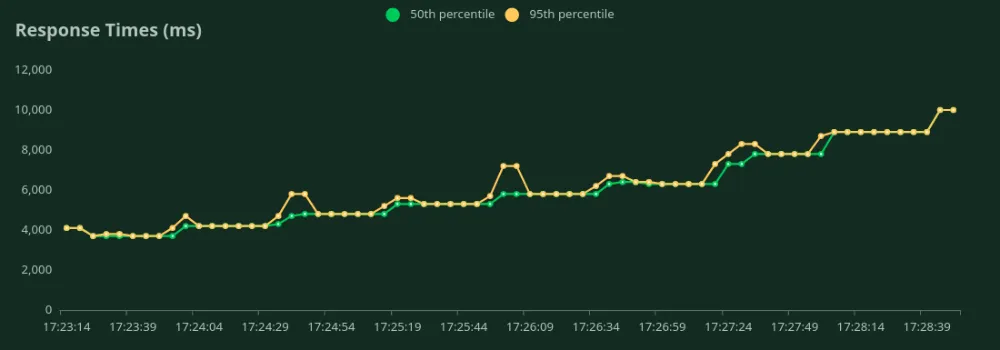
Podemos observar nos gráficos acima que a Melhor Tempo de Resposta (com 1 usuário) é de 4,1 segundos. Podemos aumentar o número de usuários para direcionar mais tráfego ao modelo - podemos ver o throughput aumentando até 0.9 RPS sem uma queda significativa na latência. Acima de 0.9 RPS, a latência aumenta drasticamente, o que significa que as requisições estão sendo enfileiradas.
A10 24GB GPU (50 tokens de entrada + 500 tokens de saída)
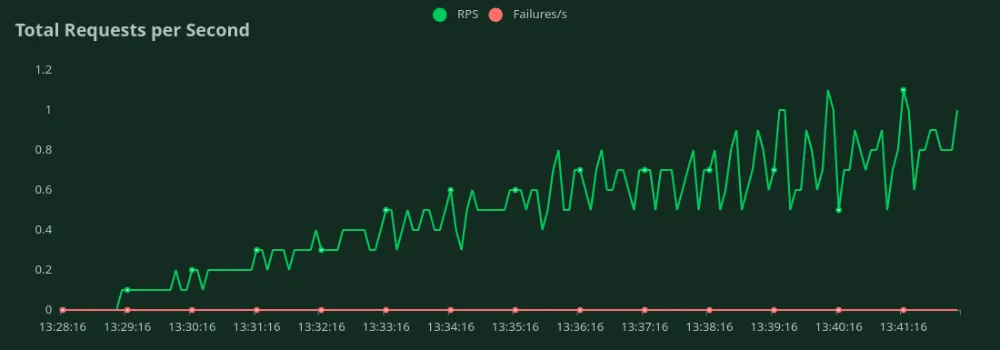
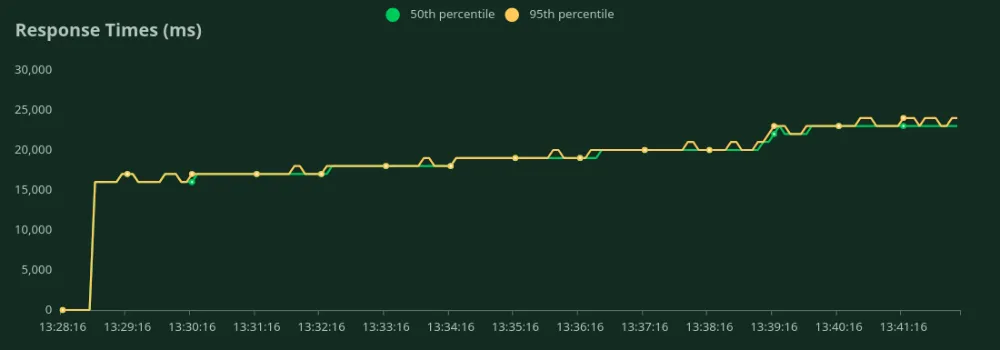
Podemos observar nos gráficos acima que o Melhor Tempo de Resposta (com 1 usuário) é 15 segundos. Podemos aumentar o número de usuários para direcionar mais tráfego ao modelo - podemos ver o throughput aumentando até 0.9 RPS sem uma queda significativa na latência. Além de 0.9 RPS, a latência aumenta drasticamente, o que significa que as requisições estão sendo enfileiradas.
A100 40GB GPU (1500 tokens de entrada + 100 tokens de saída)
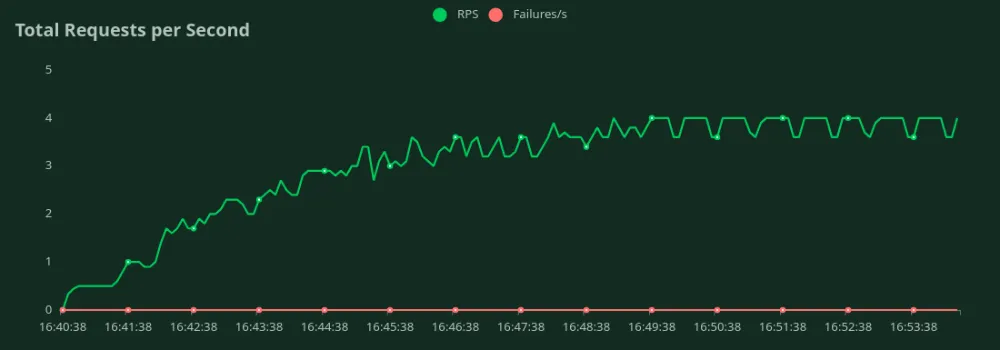
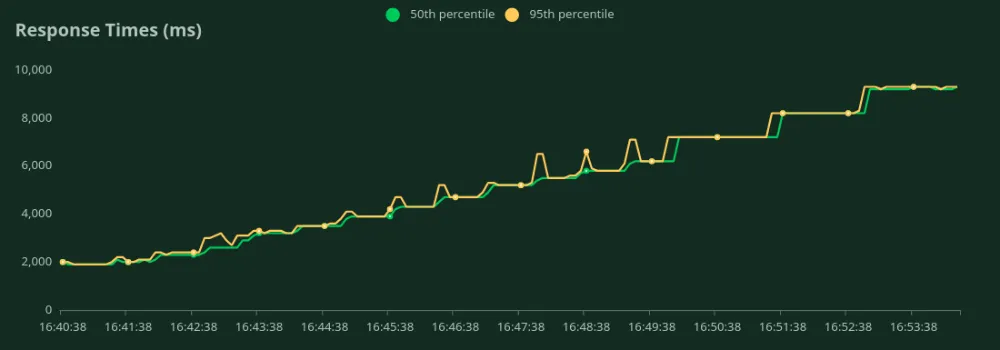
Podemos observar nos gráficos acima que o Melhor Tempo de Resposta (com 1 usuário) é 2 segundos. Podemos aumentar o número de usuários para direcionar mais tráfego ao modelo - podemos ver o throughput aumentando até 3.6 RPS sem uma queda significativa na latência. Acima de 3.6 RPS, a latência aumenta drasticamente, o que significa que os pedidos estão a ser enfileirados.
GPU A100 40GB (50 tokens de entrada + 500 tokens de saída)
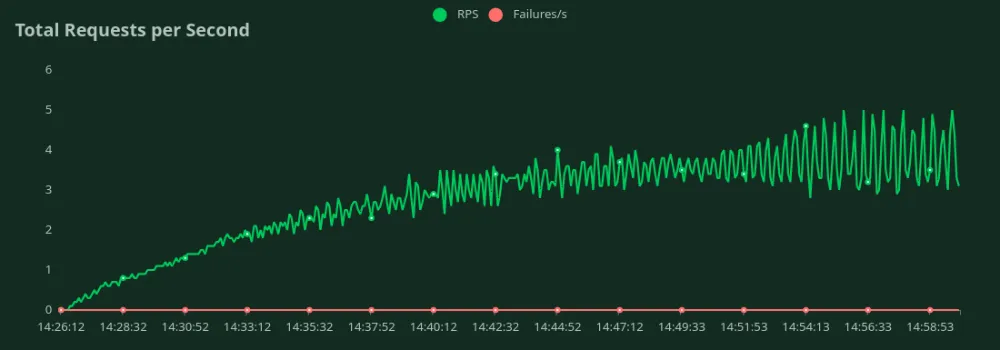
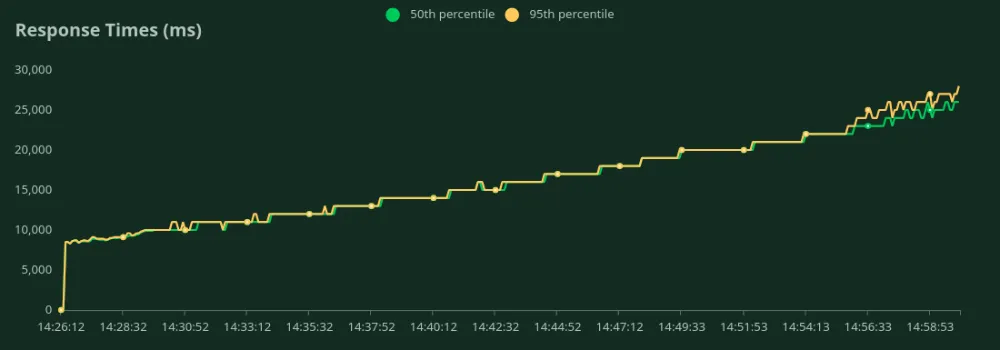
Podemos observar nos gráficos acima que o Melhor Tempo de Resposta (com 1 utilizador) é de 8,5 segundos. Podemos aumentar o número de utilizadores para direcionar mais tráfego para o modelo – podemos ver o débito a aumentar até 3.5 RPS sem uma queda significativa na latência. Acima de 3.5 RPS, a latência aumenta drasticamente, o que significa que os pedidos estão a ser enfileirados.
Esperamos que isto lhe seja útil para decidir se o LLama7B se adequa ao seu caso de uso e os custos que pode esperar ter ao alojar o Llama7B.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




