



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Versão resumida: Kimi-K2 Thinking (Moonshot AI) é um modelo de “pensamento” de peso aberto e com capacidade de usar ferramentas que impulsiona o raciocínio em várias etapas, a orquestração de ferramentas de longo alcance e grandes janelas de contexto. No Humanity’s Last Exam (HLE) e em vários benchmarks de agentes, ele apresenta números líderes no setor (especialmente quando o acesso a ferramentas está ativado), argumentando fortemente que a próxima grande fronteira em LLMs é pensamento + ferramentas + contexto longo, e não apenas a contagem bruta de parâmetros.
Use Truefoundry AI Gateway para experimentá-lo agora mesmo.
Benchmarks como MMLU, testes de codificação e benchmarks de chat nos disseram muito, mas eles não medem completamente o raciocínio em várias etapas, a orquestração de ferramentas ou o planejamento de longo prazo. Uma nova classe de modelos de “pensamento” treina explicitamente para essas habilidades: o modelo deve intercalar o raciocínio interno passo a passo com chamadas de ferramentas externas (pesquisa, interpretadores de código, navegação na web) e manter a coerência por muitas etapas sequenciais.
Kimi-K2 Thinking é um exemplo emblemático dessa tendência. Ele é projetado como um sistema agêntico: ele raciocina, decide chamar ferramentas, ingere as saídas das ferramentas e continua raciocinando — tudo isso enquanto mantém o contexto ao longo de centenas de etapas. O resultado: ganhos substanciais em benchmarks de “pensamento” difíceis, como HLE e BrowseComp.
Principais destaques técnicos da ficha oficial do modelo:
Estes elementos — escala MoE, contexto enorme, orquestração explícita de ferramentas e inferência eficiente de baixa precisão — são os blocos de construção que permitem ao Kimi-K2 agir mais como um agente do que como um transformador conversacional.
Último Exame da Humanidade (HLE) pretende ser um benchmark muito desafiador no estilo de exame que enfatiza o raciocínio genuíno, não a recuperação ou atalhos. Contém problemas complexos de domínio, muitas vezes de várias etapas, em matemática, ciência, engenharia e outras disciplinas. Como os problemas do HLE geralmente exigem raciocínio em várias etapas e, em alguns casos, consulta ou computação externa, é um excelente teste de estresse para agentes com capacidade de ferramenta e contexto longo. O desenvolvimento do Kimi-K2 enfatizou o HLE e outros benchmarks de agentes — a ficha do modelo destaca o HLE como um de seus principais alvos de avaliação.
De acordo com os resultados de avaliação publicados pela Moonshot AI:
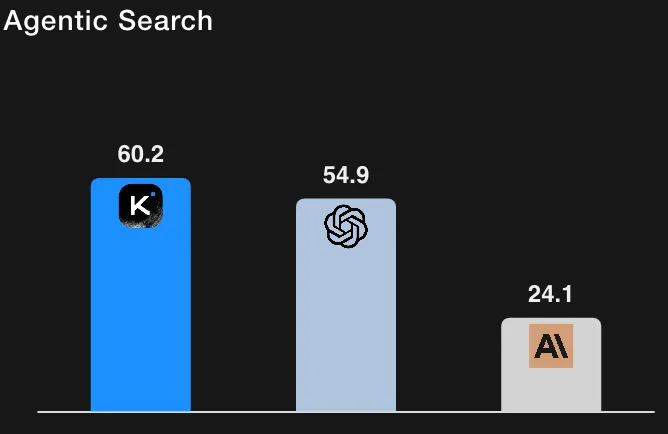
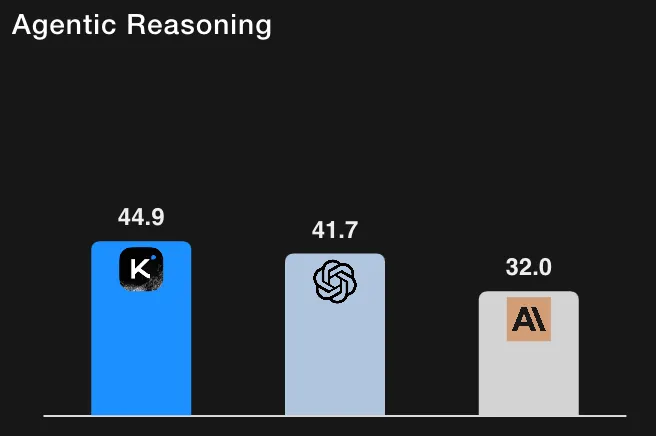
Para contextualizar, o GPT-5 (Alto) obteve ~41,7% no HLE com ferramentas (suas reexecuções internas) e o Claude Sonnet 4.5 obteve ~32,0% (modo de pensamento). Os resultados do Kimi-K2, portanto, o colocam à frente das linhas de base relatadas nas execuções do HLE com ferramentas. (Todos os números são retirados da tabela de avaliação e notas de rodapé da Moonshot AI.)
Nuance importante: a ficha do modelo documenta cuidadosamente como o acesso a ferramentas, as configurações do avaliador, os orçamentos de tokens e os limites de contexto foram tratados; os autores também observam que alguns números de referência foram retirados de publicações oficiais, enquanto outros foram retestados internamente. Em resumo: estes são sinais fortes, mas os leitores devem notar que são relatados pela Moonshot AI e condicionados ao protocolo de avaliação detalhado descrito com os resultados.
Amostramos 50 linhas de dados do HLE e aqui estão os resultados
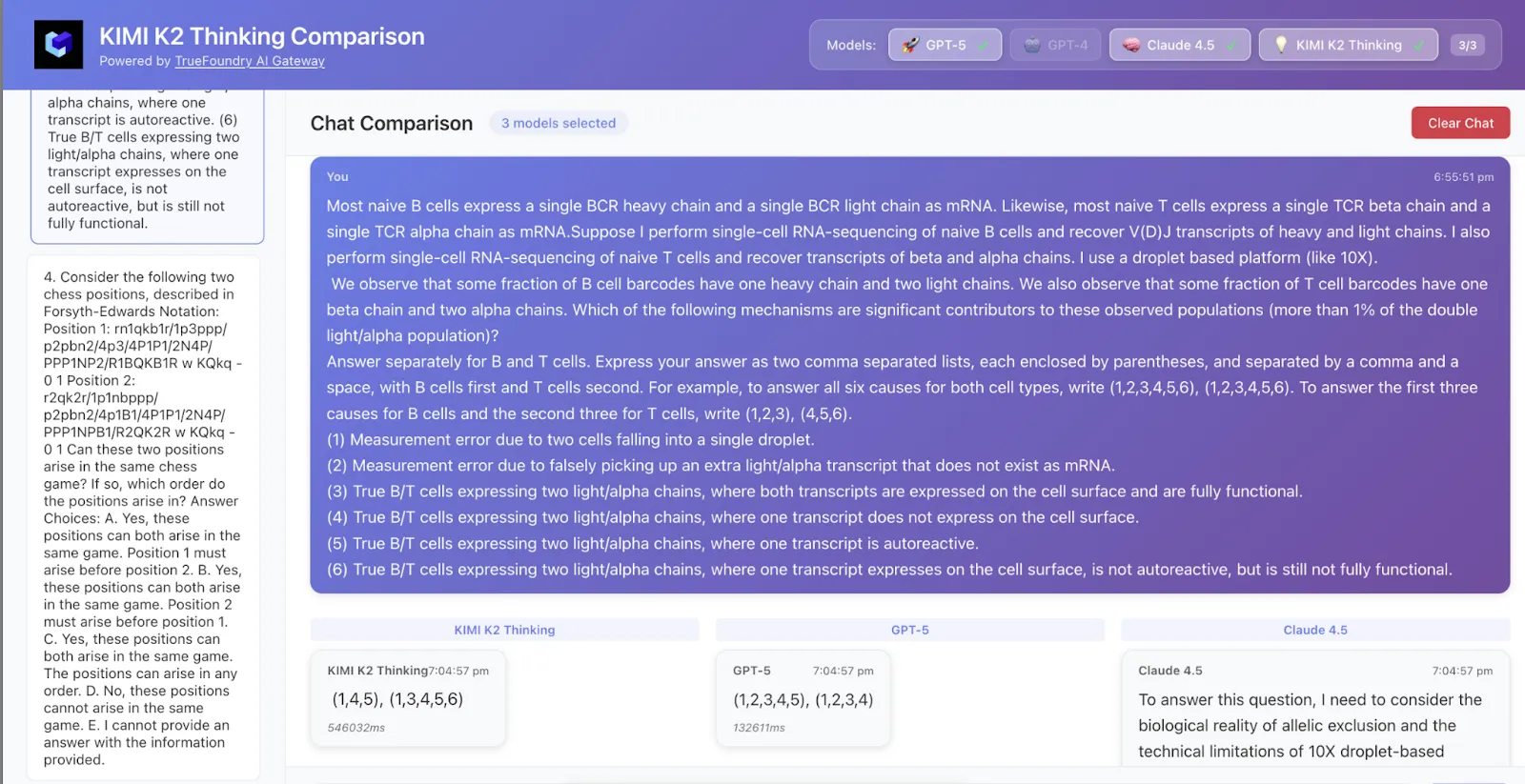
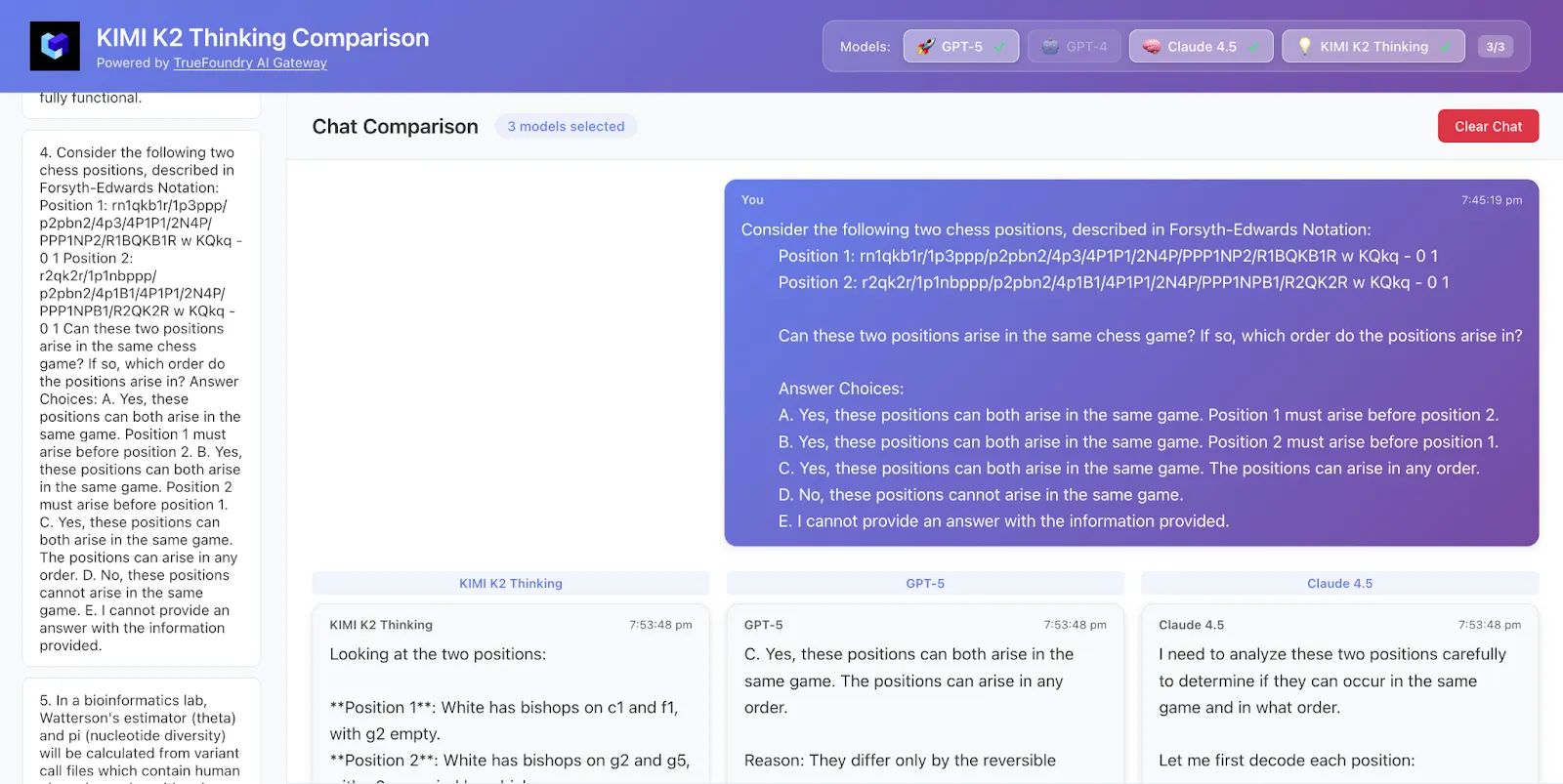
O Kimi K2 acertou tanto a resposta quanto a lógica, enquanto o GPT-5 acertou apenas a resposta e o Claude não estava correto.
A duplicação aproximada do desempenho do HLE do Kimi-K2 de sem ferramentas → com ferramentas (≈24→45%) demonstra um ponto crucial:
Simplificando: os ganhos do HLE sugerem que o problema central é como um modelo raciocina e usa ferramentas, não apenas o tamanho bruto do modelo.
Além dos benchmarks, o mais empolgante é o quão acessível esse tipo de capacidade está se tornando. Você não precisa esperar meses para experimentar — você pode experimentar por si mesmo. TrueFoundry AI Gateway facilita o acesso direto ao Kimi-K2 Thinking e a outros modelos de ponta, permite avaliá-los com seus próprios dados ou integrá-los em fluxos de trabalho.
Se precisar de ajuda mais personalizada, agende uma demonstração — a equipe pode apresentar a você o desempenho, as opções de implantação, o custo e como avaliar esses modelos em suas tarefas. Mantemos-nos atualizados com o mercado e garantimos que novos modelos estejam disponíveis para seu uso o mais rápido possível.
Em resumo: O Kimi-K2 Thinking não é apenas mais um LLM — é um vislumbre claro do futuro dos agentes com capacidade de raciocínio: abertos, eficientes, com consciência de ferramentas e otimizados para a resolução de problemas em várias etapas. Experimente-o, compare-o em seus próprios problemas e veja a diferença que a orquestração de ferramentas agênticas faz em tarefas reais.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




