




August 27, 2025
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
O cenário da infraestrutura de ML está repleto de algumas das soluções mais impressionantes disponíveis para simplificar o pipeline de ML. A TrueFoundry pode ser uma solução se você se identificar com alguns dos problemas mencionados abaixo:
A principal razão que encontramos para atrasos nos cronogramas é a dependência entre equipes e a falta de competências em diferentes perfis. A TrueFoundry facilita para os Cientistas de Dados treinarem e implantarem no Kubernetes usando Python. Também permite que as equipes de infraestrutura configurem restrições de segurança e orçamentos de custo. Na maioria das empresas com as quais conversamos, o fluxo de implementação é algo como o seguinte:
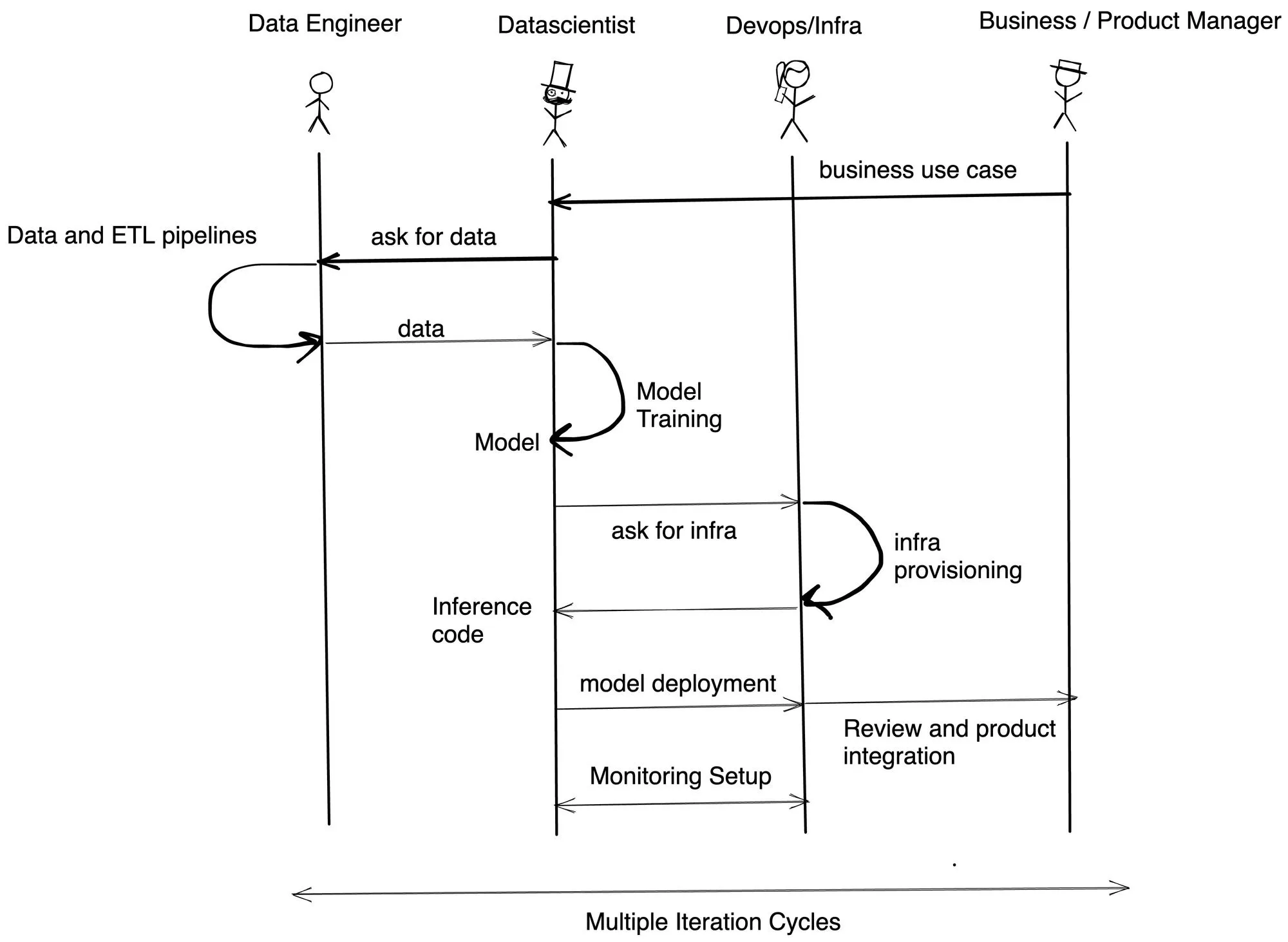
A TrueFoundry ajuda a reduzir o tempo de desenvolvimento em pelo menos 3 a 4 vezes, capacitando os Cientistas de Dados a implantar e avaliar o modelo por conta própria, sem depender da equipe de infraestrutura/DevOps.
Com a TrueFoundry, o fluxo é semelhante ao seguinte:
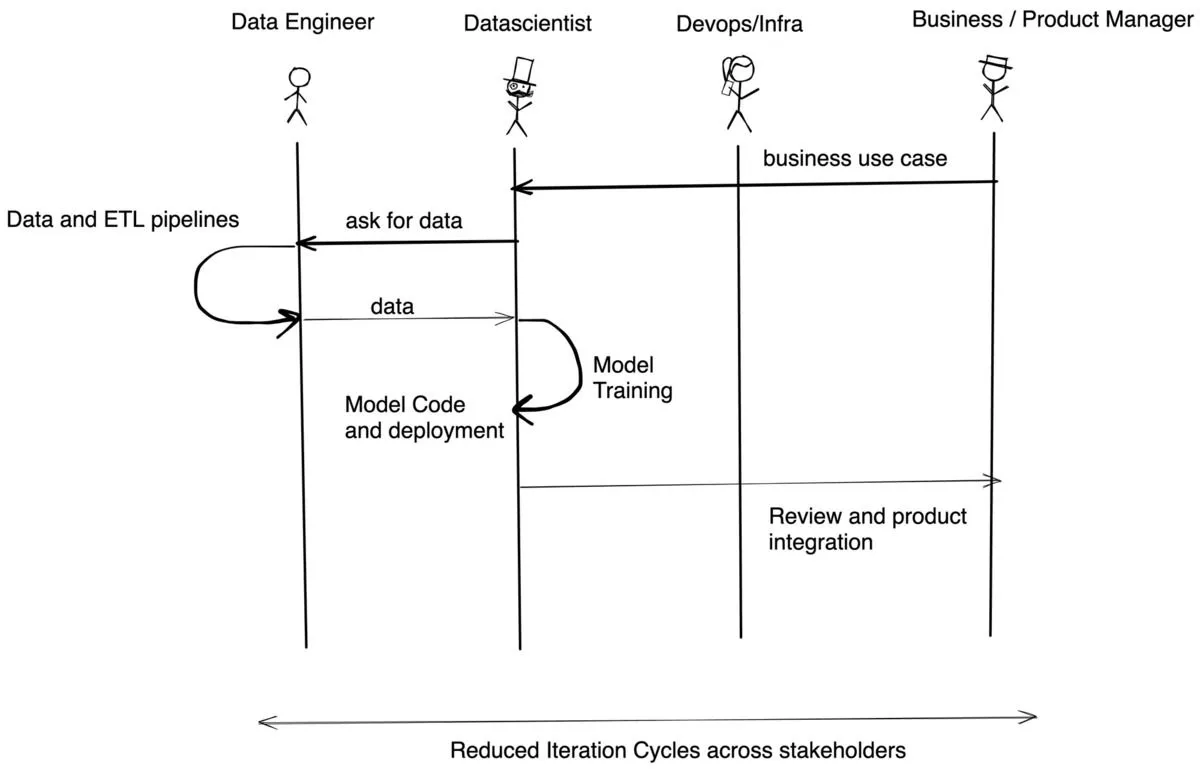
A TrueFoundry é nativa do Kubernetes e funciona em EKS, AKS, GKE (clusters padrão e autopilot) ou clusters on-premise. O ML exige algumas coisas personalizadas em comparação com a infraestrutura de software padrão – como provisionamento dinâmico de nós, suporte a GPU, volumes para acesso mais rápido, orçamentação de custos e autonomia do desenvolvedor. Nós cuidamos de todos os pormenores em todos os clusters para que você possa se concentrar em construir as melhores aplicações sobre uma infraestrutura de ponta.
Nós fornecemos APIs Python – assim você nunca precisará interagir com YAML. Também fornecemos suporte a YAML, caso você queira usá-lo em seus pipelines de CI/CD. Por exemplo, usando a TrueFoundry, você pode implantar uma API de inferência usando o código abaixo:
service = Service(
name="fastapi",
image=Build(
build_spec=PythonBuild(
command="uvicorn app:app --port 8000 --host 0.0.0.0",
requirements_path="requirements.txt",
)
),
ports=[
Port(
port=8000,
host="<Forneça um valor de host com base no seu domínio configurado>"
)
],
resources=Resources(
cpu_request=0.5,
cpu_limit=1,
memory_request=1000,
memory_limit=1500
),
env={
"UVICORN_WEB_CONCURRENCY": "1",
"ENVIRONMENT": "dev"
}
)
service.deploy(workspace_fqn="tfy-cluster/my-workspace")
O TrueFoundry é implantado inteiramente no seu próprio cluster Kubernetes. Os dados permanecem na sua própria VPC, as imagens Docker são salvas no seu próprio registro Docker e todos os modelos permanecem no seu próprio sistema de armazenamento de blobs. Você pode ler mais sobre a arquitetura do TrueFoundry aqui.
O Kubernetes geralmente suporta autoescalonamento usando HPA com base em CPU e memória. No entanto, para cargas de trabalho de ML, o autoescalonamento baseado na contagem de requisições é muito melhor em muitos casos. Outro desafio no autoescalonamento pode ser o alto tempo de inicialização dos modelos devido a grandes tamanhos de imagem e tempos de download de modelos. O Truefoundry resolve esses problemas fornecendo tempo de inicialização de contêineres em segundos, cache de modelos para carregamento mais rápido e tempos de inferência mais rápidos.
Podemos usar alguns modelos LLM de código aberto?
O TrueFoundry permite que você implante e ajuste (finetune) os LLMs de código aberto em sua própria infraestrutura. Já descobrimos as melhores configurações para os modelos de código aberto mais comuns para que você possa treiná-los e implantá-los com as configurações ideais e o menor custo.
Nós hospedamos um playground interno de LLMs onde você pode decidir quais LLMs deseja incluir na lista de permissões para os desenvolvedores da empresa, incluindo aqueles hospedados internamente, e diferentes desenvolvedores podem experimentar com os dados internos. Aqui está um vídeo rápido sobre o assunto:
Jupyter Notebooks são essenciais para o ciclo de desenvolvimento diário de um Cientista de Dados. Executar Jupyter Notebooks localmente na própria máquina nem sempre é uma opção pelos seguintes motivos:
Nós nos esforçamos muito para executar Jupyter Notebooks de forma contínua no Kubernetes. Jupyter Notebooks no TrueFoundry oferecem os seguintes benefícios em comparação com JupyterLab ou Kubeflow Notebooks:
O TrueFoundry oferece um registro de modelos que pode rastrear quais modelos estão em qual estágio, bem como o esquema e a API de todos os modelos no registro.
O TrueFoundry permite dividir ou espelhar o tráfego de um modelo para outro. Isso é especialmente útil quando você deseja testar uma nova versão de modelo em tráfego real por algum tempo antes de lançá-la em produção. O TrueFoundry também suporta estratégias de lançamento canary e blue-green na implantação de modelos.
Dedicamos muito esforço para garantir que cuidamos das diferenças minuciosas dos clusters Kubernetes em diferentes nuvens. Os desenvolvedores podem escrever e implantar o mesmo código em qualquer ambiente sem se preocupar com a infraestrutura subjacente. Nós nos encarregamos de verificar se os componentes subjacentes do Kubernetes estão instalados, verificar migrações incompatíveis e informar os desenvolvedores de acordo.
Exponibilizamos a visibilidade de custos dos serviços para os desenvolvedores e fornecemos insights para reduzir os custos. Todos os nossos clientes atuais observaram uma redução de custos de pelo menos 30% após a adoção do TrueFoundry.
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes, construída para simplificar a implantação de modelos de IA, acelerar os fluxos de trabalho dos desenvolvedores e manter o controle total da infraestrutura. Através da nossa plataforma, capacitamos as equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos – permitindo-lhes economizar custos e lançar modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.



.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




