




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Construir um modelo para resolver um caso de uso de negócios parece uma ótima ideia para todos nós. Parece intuitivo que, se pudermos aumentar o engajamento através da personalização em um determinado site usando ML em 5%, isso impulsionará as receitas em alguma porcentagem.
No entanto, o que muitas vezes é negligenciado são dois fatores que podem comprometer este projeto:
Bem, não deveria ser simples testar essas duas coisas? Bem, vamos aprofundar o que é preciso para ir da ideia de construir um modelo até finalmente colocá-lo em produção e avaliar o impacto nos negócios. Vamos considerar o caso em que um aplicativo de entrega de comida deseja mostrar o tempo de entrega esperado assim que um cliente faz um pedido no aplicativo. Como não sabemos o tempo de entrega de antemão, precisaremos construir um modelo de ML que possa fazer a previsão com base em certos fatores como a cidade, restaurante, hora do dia, distância do cliente ao restaurante, etc.
Mostrar o tempo de entrega estimado ao usuário para um aplicativo de entrega de comida
O fluxo de trabalho para colocar este modelo em funcionamento envolverá as seguintes equipes:
O Gerente de Produto desenvolverá o projeto para estimar o tempo de entrega. A expectativa é que, se o tempo de entrega for razoavelmente preciso, proporcionará uma melhor experiência aos usuários. Haverá menos consultas dos clientes relacionadas aos tempos de entrega e a pontuação geral de satisfação do cliente deverá aumentar. A equipe de negócios então pedirá à equipe de ciência de dados para desenvolver este modelo.
Cientistas de dados começam a coletar os dados históricos de todos os pedidos realizados e seus tempos de entrega.
O cientista de dados irá então analisar os dados para verificar se tudo parece correto - sem valores nulos ou inválidos e se todos os dados necessários estão presentes. Muitas vezes, o CD (Cientista de Dados) identificará alguns erros no conjunto de dados - ou talvez haja alguns dias de dados ruins devido a alguns erros transitórios. Precisaremos eliminar os dados inválidos, pois só assim poderemos construir um bom modelo. Isso pode levar a algumas iterações com as equipes de Produto e Engenharia de Dados.
Uma vez que os dados estejam bons, em alguns casos, os cientistas de dados desejarão ter um pipeline para calcular e armazenar as features, para que não haja desvio entre treinamento e serviço e seja mais fácil obter os valores das features durante a inferência.
No entanto, este é um passo opcional e é ignorado quando o volume de dados ou o número de modelos construídos no mesmo conjunto de dados é pequeno. Caso uma equipe decida fazer engenharia de features, precisaremos de um sistema de orquestração de pipelines como Airflow, Prefect e um banco de dados / cache para armazenar as features para recuperação (por exemplo, Feast). Construir um feature store é, por si só, um grande empreendimento e exige um esforço significativo.
Uma vez que os dados estejam prontos, o cientista de dados irá agora experimentar com diferentes algoritmos, features e modelos para descobrir qual tem o melhor desempenho. Eles desejarão registrar todas as métricas, parâmetros e modelos para que possam consultá-los mais tarde ou compartilhar com outros membros da equipe. É aqui que entram um sistema de rastreamento de experimentos e um armazenamento de metadados de modelo.
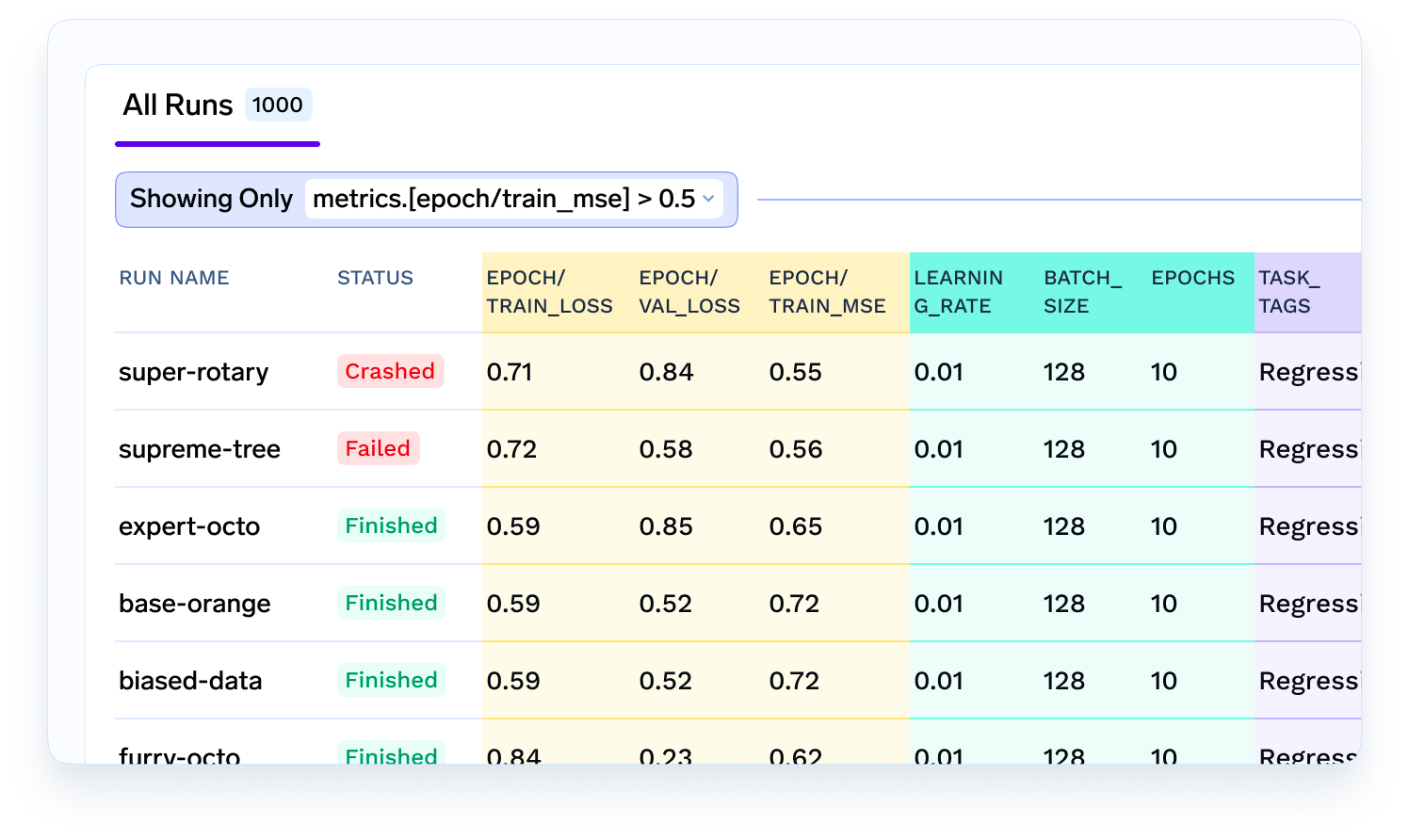
Uma vez que o modelo é construído, o modelo precisa ser hospedado como um microsserviço ou como um trabalho de inferência em lote. No nosso caso de previsão de tempo de entrega, isso precisa ser um serviço online em tempo real - então provavelmente faz sentido implantá-lo como um serviço de autoescalonamento. Neste caso, um engenheiro de ML entra em ação que pega o modelo, o encapsula em um serviço Flask ou FastAPI e constrói a imagem docker. Então, o Engenheiro de ML, com a ajuda da equipe de Devops, o implantará como um microsserviço na infraestrutura.
Uma vez que a API do modelo esteja hospedada, a equipe de produto ou backend precisará chamar a API em seu código para utilizar o tempo de entrega previsto e exibi-lo no aplicativo. Isso exigirá colaboração entre as equipes de Cientistas de Dados, Produto e Engenharia de ML. Durante este período, o Gerente de Produto pode querer testar as previsões e seria ótimo se eles pudessem testar rapidamente o modelo com algumas entradas de exemplo. Isso pode exigir a construção de uma demonstração rápida do modelo.
Uma vez que o modelo é implantado e está sendo usado no produto, precisaremos de métricas sobre o modelo implantado.
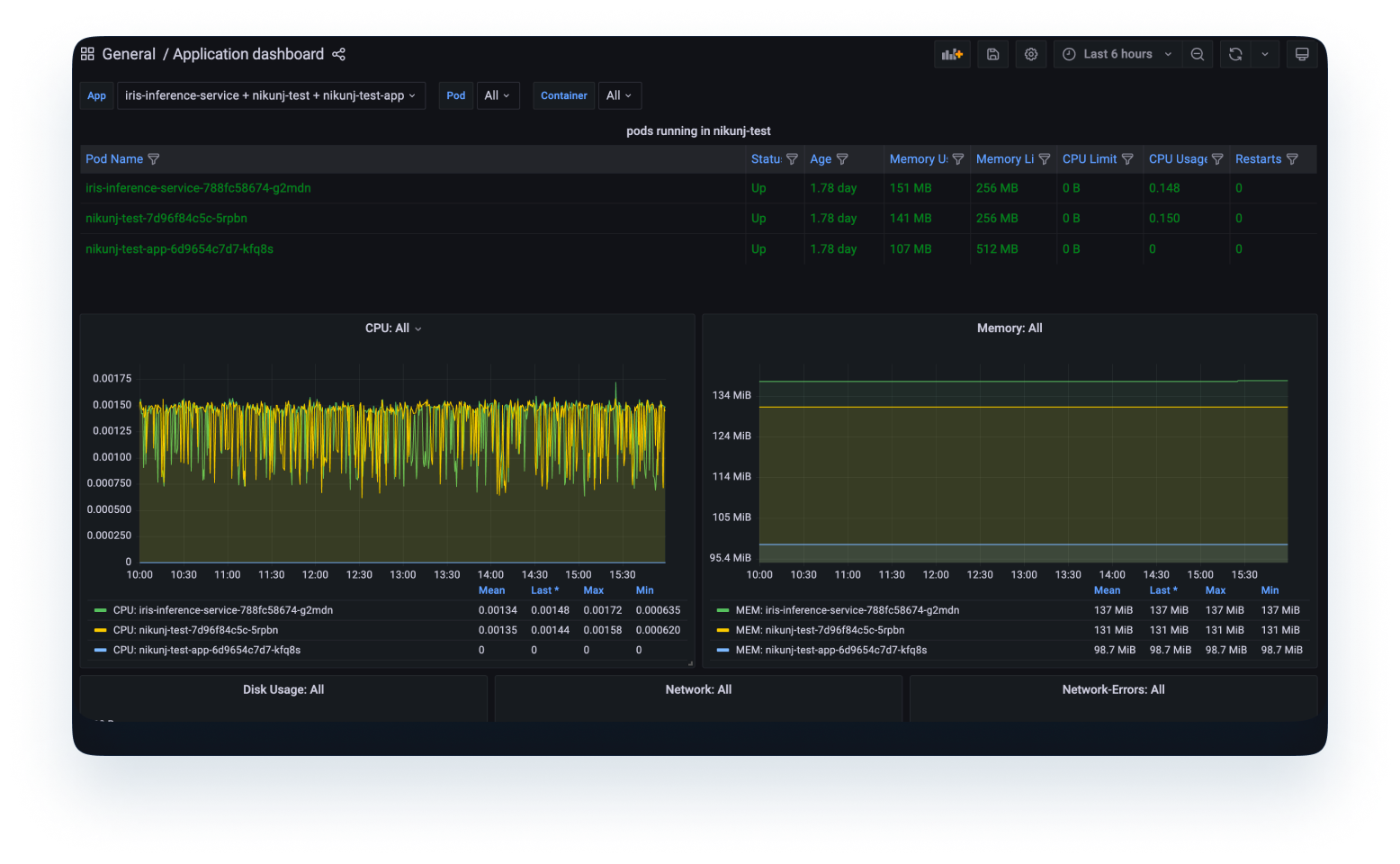
2. Monitoramento de Modelo: Isso inclui as métricas relacionadas à previsão do modelo nos dados de produção recebidos. Estes são dados nos quais o Cientista de Dados estará principalmente interessado e incluem métricas como precisão do modelo, desvio de características (feature drift), desvio de previsão (prediction drift), etc. Isso ajuda o cientista de dados a decidir se o modelo está se comportando de maneira semelhante à que se comportava durante o treinamento, se as distribuições de dados de entrada externos não mudaram e se não há bugs em nenhuma outra parte do sistema.

Para obter um monitoramento completo do modelo, serão necessários esforços significativos das equipes de Ciência de Dados, Engenharia e DevOps.
Uma vez que todo o monitoramento esteja organizado, o cientista de dados idealmente desejará automatizar o ciclo completo de retreinamento. Isso exigirá uma estrutura de orquestração de pipeline como Kubeflow ou Airflow.
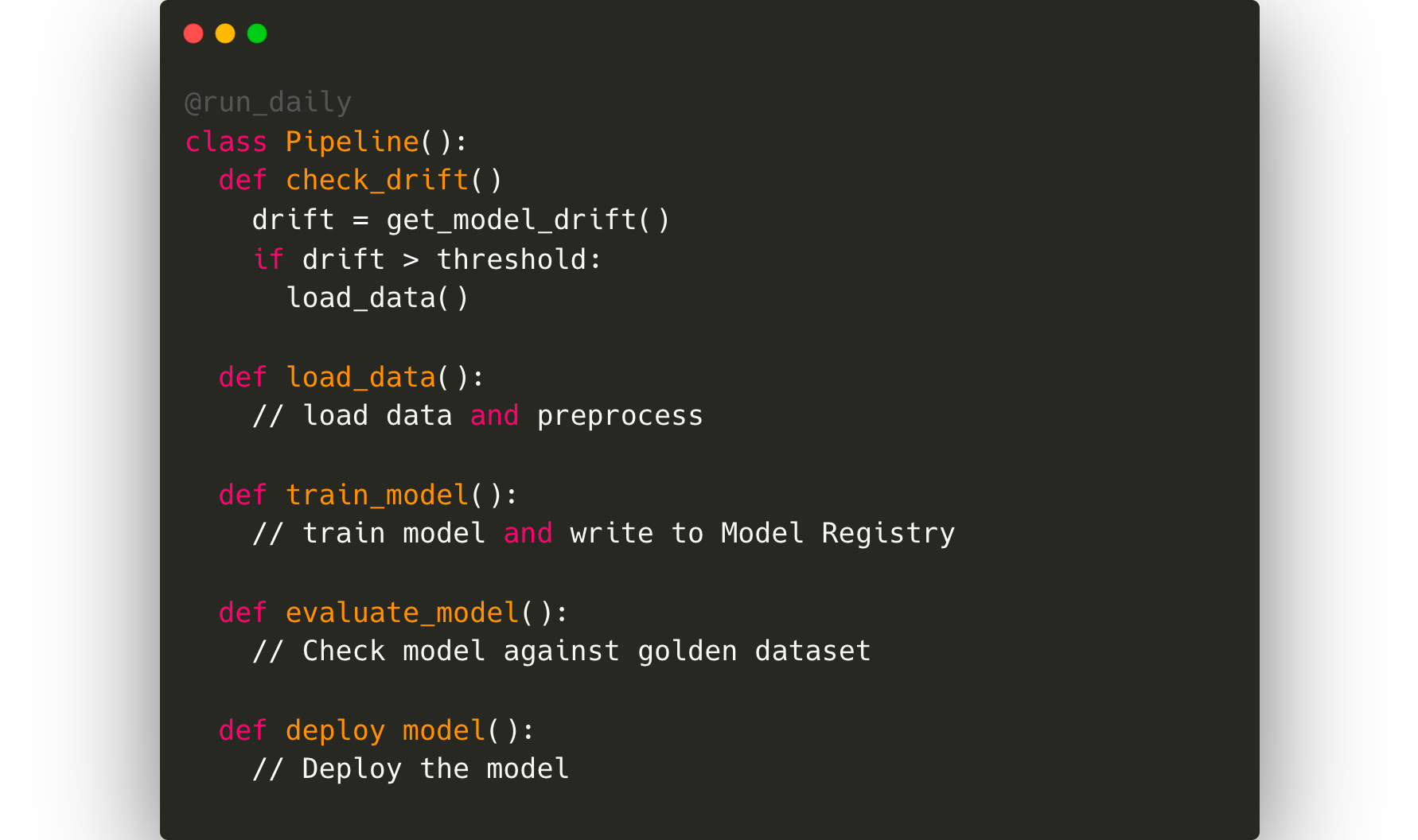
Precisamos então também estimar o impacto deste modelo nas métricas reais de satisfação do usuário. Algumas métricas proxy neste caso serão o número de consultas de clientes relacionadas a prazos de entrega, pontuação geral de satisfação dos clientes para um pedido. As métricas de negócio precisarão ser combinadas com as métricas do modelo, e a equipe de Engenharia de Dados provavelmente escreverá um pipeline ETL para obter esses dados e exibi-los em uma ferramenta de dashboarding interna para observação dos líderes de negócio.
Para resumir, isso envolve 5 stakeholders:

O processo geral leva facilmente mais de 2-3 meses em qualquer empresa e às vezes pode levar até 6 meses para os primeiros modelos. É devido aos múltiplos stakeholders envolvidos e às múltiplas habilidades necessárias que tornar o ML impactante leva tanto tempo e um investimento inicial tão grande.
Ainda não falamos sobre alguns dos aspectos de escalabilidade e confiabilidade envolvidos no processo. Esperamos abordar alguns dos aspectos abaixo em um artigo futuro.
A solução aqui é automatizar as partes que podem ser automatizadas e dar autonomia ao cientista de dados / engenheiro de ML para realizar a maioria das etapas sem ter que aprender todas as ferramentas envolvidas. Há muito trabalho acontecendo neste domínio e esperamos que, em alguns anos, criar um modelo de ML impactante se torne tão fácil quanto construir uma landing page hoje!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




