




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Jupyter notebooks são uma ferramenta poderosa e popular que oferece um ambiente de computação interativo, combinando código, visualização de dados e texto explicativo, facilitando o trabalho com dados e o compartilhamento de insights. Cientistas de dados usam Jupyter notebooks para diversas tarefas ao longo do ciclo de vida da análise de dados e aprendizado de máquina, como análise exploratória de dados (EDA), pré-processamento de dados, visualização, desenvolvimento de modelos, avaliação e validação, etc. Para muitos desses casos de uso, apenas instalar o Jupyter Notebook no seu laptop é suficiente para começar. No entanto, para muitas empresas e organizações, esta não é uma opção e precisamos de Jupyter notebooks hospedados.
Aqui estão as opções que uma empresa pode ter hoje para fornecer acesso ao Jupyter Notebook aos seus engenheiros:
DS/MLEs podem configurar o ambiente e executar um jupyter-server em uma VM que pode ser usada para executar as cargas de trabalho. Aqui está um guia simples sobre como você pode executar o jupyterlab em uma instância ec2.
👍 Prós:
- Oferece controle total da máquina para um DS
- Todo o ambiente é persistente. A VM pode ser parada e reiniciada no mesmo estado.
👎 Contras:
- Alto custo de computação em nuvem - Não haverá recurso de parada automática. O DS pode iniciar uma VM e deixá-la sem utilização por grande parte do tempo, aumentando assim os custos.
- Difícil de gerenciar e rastrear um grande número de VMs centralizadamente.
- O DS precisa configurar muitas coisas para preparar o ambiente de trabalho para iniciar a experimentação.
- Dificuldade na reprodutibilidade - O DS pode ter instalado vários pacotes que não são mais rastreados e leva muito tempo para colocar em produção o código que roda nessa VM.
Outra opção pode ser usar uma solução gerenciada como AWS Sagemaker, Vertex AI Notebooks ou Azure ML Notebooks. Embora cada um desses métodos tenha vantagens, aqui estão alguns prós e contras deles em geral.
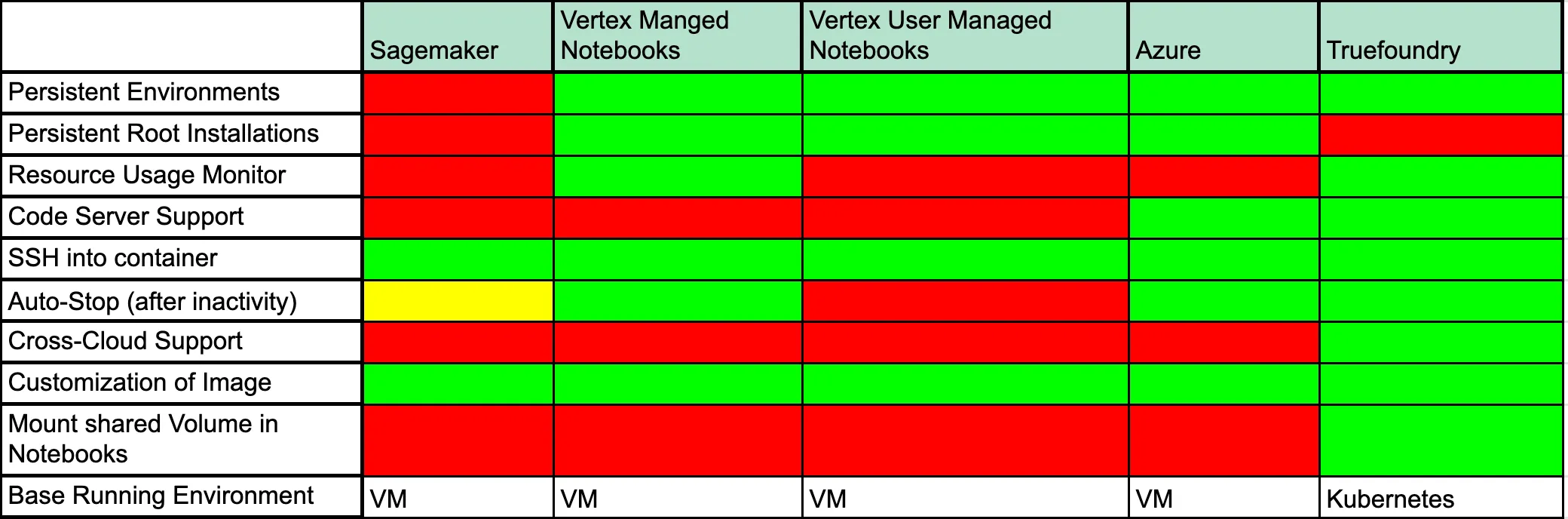
Vamos discutir o que cada um desses campos significa:
Outra opção pode ser hospedar notebooks sobre Kubernetes, mas isso vem com seu próprio conjunto de desafios, pois os cientistas de dados não podem interagir diretamente com o Kubernetes e precisam de um software intermediário que forneça uma interface simples para iniciar notebooks Jupyter. Vejamos quais são as opções disponíveis para isso:
Operador de Notebook do Kubeflow:
Kubeflow ajuda a tornar as implantações de fluxos de trabalho de aprendizado de máquina (ML) no Kubernetes simples, portáteis e escaláveis. Ele possui um recurso de notebook que ajuda a gerenciar e executar notebooks facilmente.
Embora o Kubeflow seja um grande projeto de código aberto que oferece muitas funcionalidades para casos de uso de Machine Learning, é muito difícil instalar e gerenciar o Kubeflow por conta própria.
👍 Prós:
- Fácil de iniciar e gerenciar notebooks para CD
- Diretório inicial persistente com suporte de disco
- Opção para imagens pré-definidas para sklearn, pytorch e tensorflow, que vêm com todas as dependências instaladas.
- Código-base de código aberto
- Obter um recurso de encerramento automático que interrompe notebooks após algum tempo de inatividade.
👎 Contras:
- Difícil de configurar o Kubeflow no Kubernetes. Leva muito tempo para instalar e manter o Kubeflow
- Para fornecer notebooks em várias regiões, diferentes clusters Kubernetes precisam ser criados e o Kubeflow precisa ser instalado em cada cluster - o que leva a altos custos de infraestrutura e manutenção.
- Os pacotes Python não são persistentes por padrão, o que significa que você precisa instalar os pacotes cada vez que reinicia
- Nenhuma maneira direta de obter acesso root ao contêiner [ pode ser útil para vários casos de uso ]
- Parar notebooks não pode ser configurado a nível de notebook e é uma configuração global.
Hospedar JupyterHub no Kubernetes:
JupyterHub é uma ótima configuração para casos de uso multiusuário, o que ajuda no uso ideal dos recursos. A implantação do JupyterHub no Kubernetes pode ser feita com um projeto de código aberto chamado Zero a JupyterHub com Kubernetes:
👍 Prós:
- Vários usuários podem trabalhar juntos facilmente com suporte a autenticação
- Configuração fácil de parada automática para notebooks
- Fácil gerenciamento de ambientes
👎 Contras:
- Difícil de configurar e gerenciar. É preciso configurar Rede, Volumes Persistentes, Escalabilidade e Balanceamento de Carga para que o JupyterHub funcione corretamente.
- Difícil executar cargas de trabalho de GPU em diferentes tipos de GPUs no Jupyterhub. Por exemplo, leia isto.
- Ambientes não são persistentes
Embora existam muitas soluções disponíveis atualmente, cada uma delas apresenta seu próprio conjunto de limitações. Na Truefoundry, tentamos preencher essa lacuna e construir uma solução de notebook que satisfaça todas as necessidades de um Cientista de Dados (DS) e também mantenha os custos sob controle. Na próxima seção, descreveremos nossa abordagem para construir a solução de notebook e os desafios que enfrentamos ao fazê-lo.
Truefoundry é uma plataforma de desenvolvedores para equipes de ML que ajuda na implantação de Modelos, Serviços, Jobs e, agora, Notebooks no Kubernetes. Você pode ler mais sobre o que fazemos aqui. Nossa motivação para construir uma solução de notebook foi simplesmente permitir a experimentação e o desenvolvimento em nossa plataforma. Após estudar todas as soluções disponíveis, decidimos resolver os pontos problemáticos e as funcionalidades ausentes em outras plataformas para que os cientistas de dados pudessem ter a melhor experiência sem incorrer em muitos custos. Algumas coisas que queríamos possibilitar são:
O Kubeflow suporta a execução de notebooks no Kubernetes. Ele oferece uma série de recursos para notebooks prontos para uso. No entanto, queríamos resolver os problemas que destacamos acima nos Notebooks do Kubeflow e proporcionar uma experiência fluida para cientistas de dados e desenvolvedores.
Então, tivemos que fazer alterações no controlador de notebooks, integrá-lo com o backend da Truefoundry e disponibilizamos os notebooks em nossa UI.
Instalamos o controlador de notebooks, mas deparamo-nos com alguns problemas, por causa dos quais tivemos que fazer alterações no kubeflow-notebook-controller:
Resolvemos os dois problemas acima e lançamos o tfy-notebook-controller
e o publicamos como um helm-chart no repositório de Charts Públicos da Truefoundry. Você pode encontrar o chart aqui.
Criamos uma interface de usuário fácil de entender para cientistas de dados iniciarem notebooks. O usuário pode personalizar o Tempo Limite de Inatividade (tempo de inatividade após o qual o notebook será parado), o Tamanho do Volume Persistente (Tamanho do Disco que armazena o Conjunto de Dados e os arquivos de código), os Recursos (requisitos de CPU, Memória e GPU) e iniciar o notebook!
Com todas essas mudanças, lançamos o v0 dos nossos notebooks.
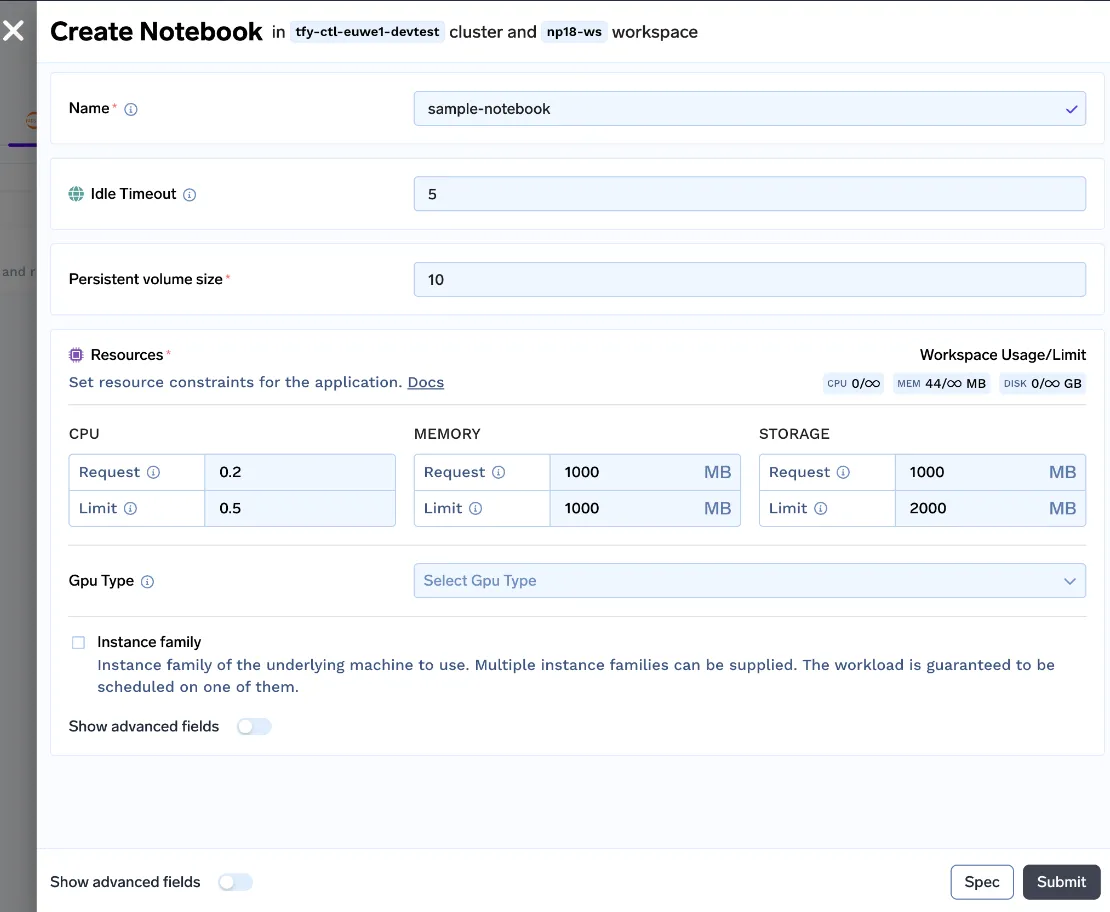
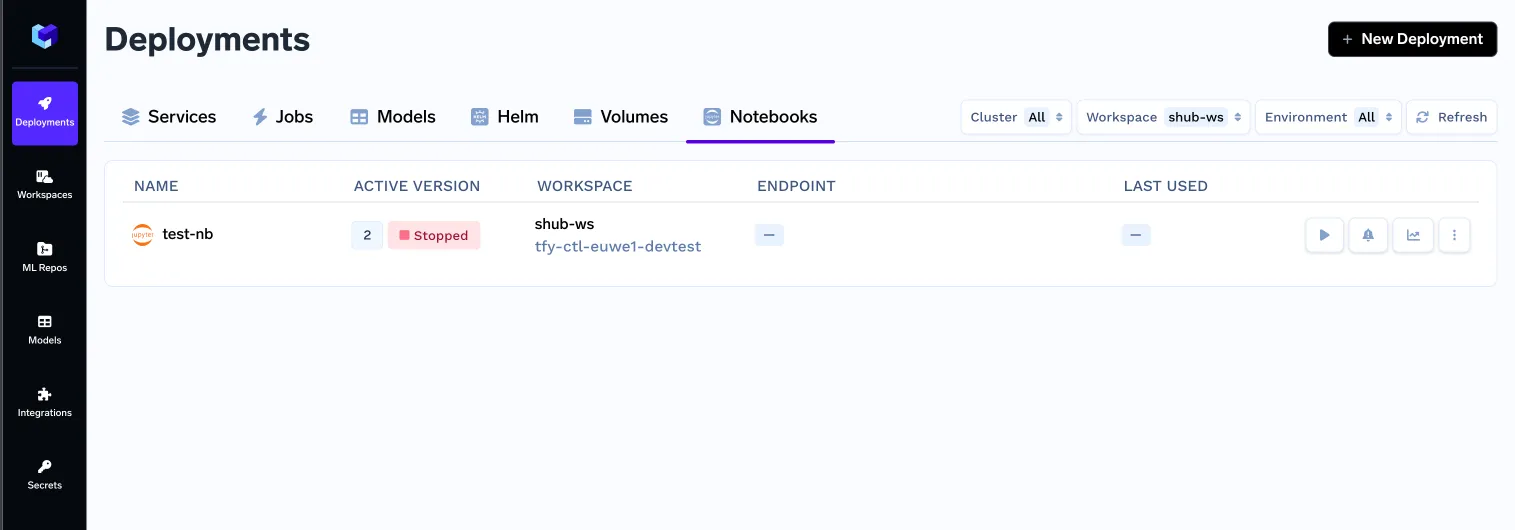
Mas ainda estamos longe de uma boa experiência de usuário, vejamos os prós e contras desta abordagem:
👍 Vantagens:
- Diretório home persistente [todos os arquivos e pacotes serão persistidos]
- Tempo limite de inatividade (Cull Timeout) por notebook pode ser configurado
- Iniciar notebook com poucos cliques
- Iniciar notebook facilmente com GPUs
👎 Limitações:
- O ambiente Python não é persistente (todos os pacotes instalados desaparecem com o reinício do pod)
- Não há como instalar pacotes que exigem acesso root
- Não há uma maneira adequada de gerenciar múltiplos ambientes para experimentação
- Não é possível configurar um endpoint para o notebook [adicionado na próxima versão]
Agora, estas limitações são cruciais para resolver, pois bloqueiam muitos fluxos de trabalho de Cientistas de Dados, que podem ser tão simples quanto instalar 'apt-packages' como ffmpeg.
Até este ponto, estávamos usando as imagens pré-construídas para Jupyterlab fornecidas pelo Kubeflow. Mas como precisamos resolver a questão dos ambientes não persistentes, permitir acesso root e instalar apt-packages, precisamos ter nosso próprio conjunto de imagens docker.
Então, vejamos como resolvemos esses problemas!
- Modificamos o script de inicialização da imagem docker e clonamos o ambiente conda base para o diretório home e o nomeamos jupyter-base
- Adicionamos um arquivo .condarc e definimos $HOME diretório como o caminho padrão do ambiente
- Modificamos o arquivo .bashrc para ativar o jupyter-base ambiente por padrão
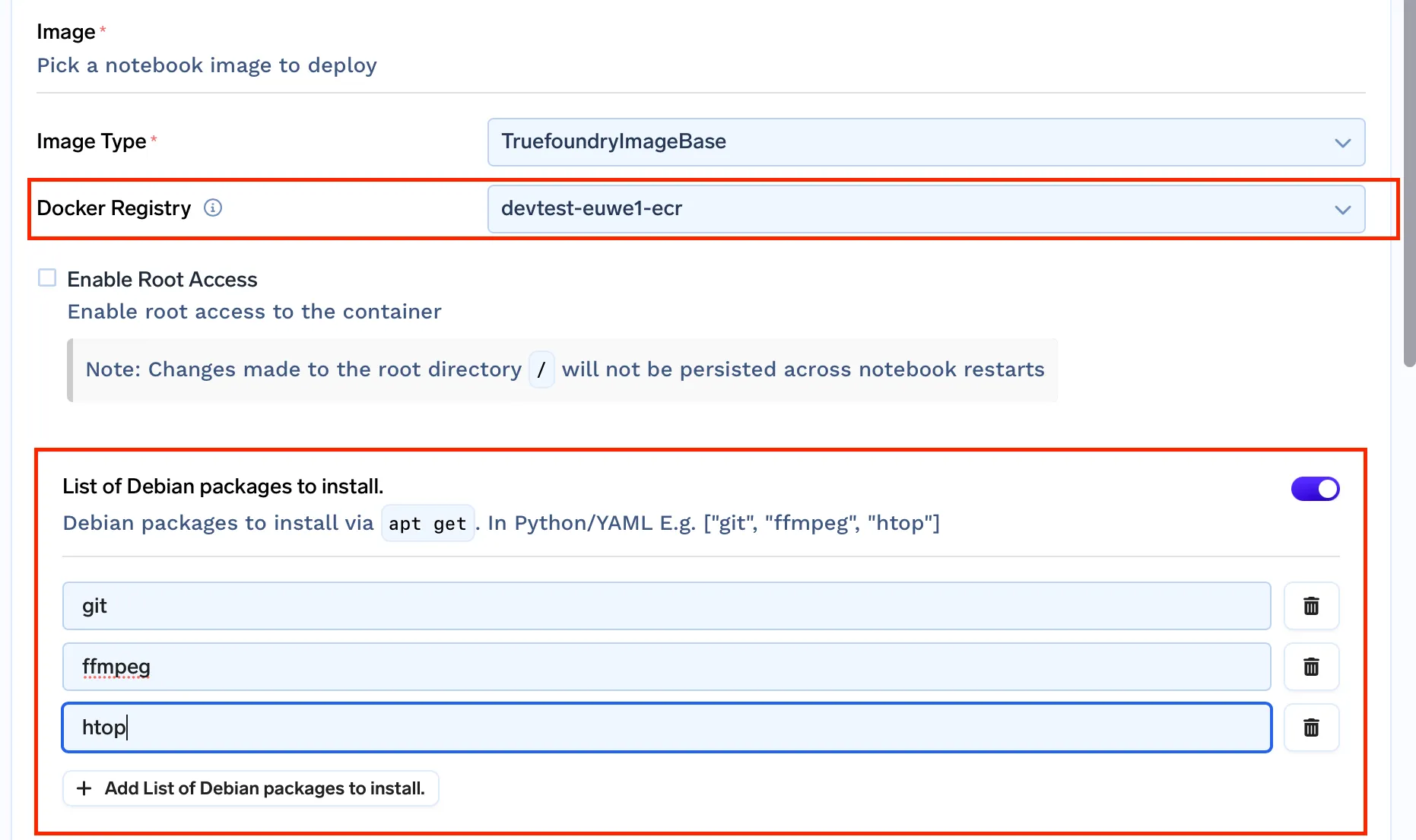
truefoundrycloud/jupyter:latest e truefoundrycloud/jupyter:latest-sudo. Onde as imagens com sudo fornecem acesso sudo sem senha ao usuário.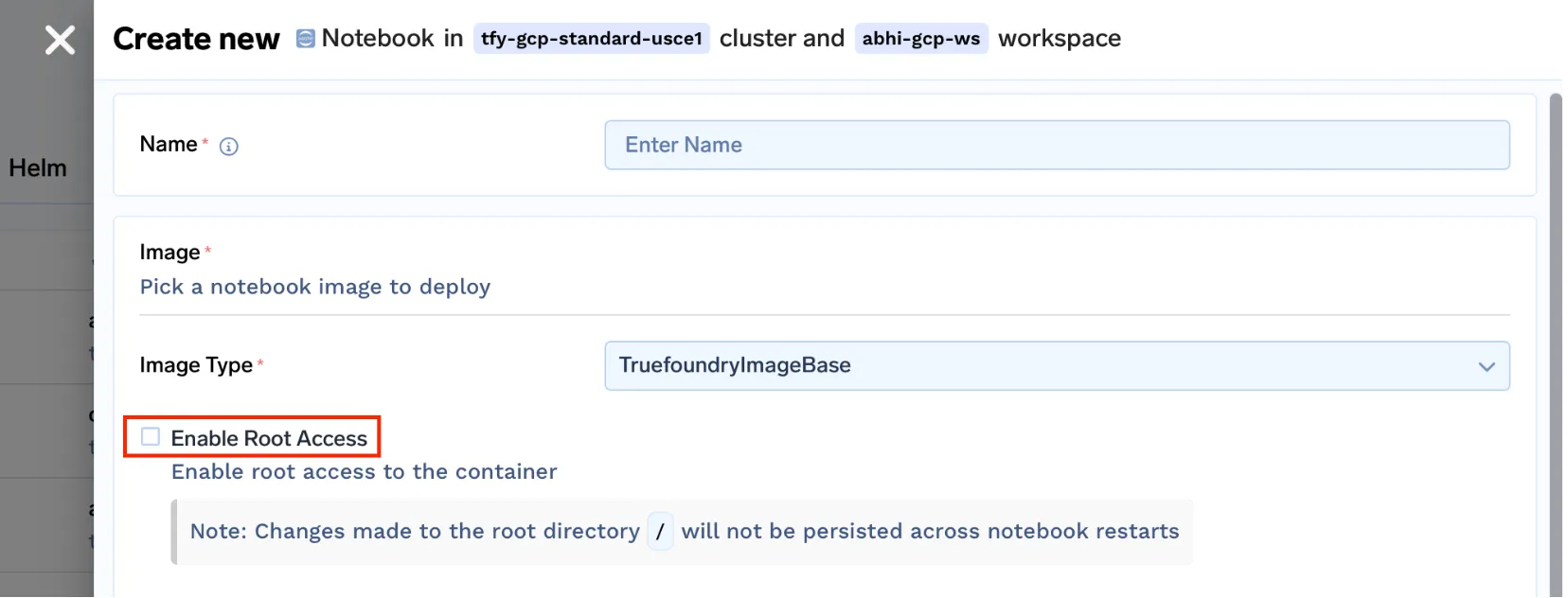
Nota: Como estamos executando notebooks no kubernetes com o diretório inicial montado, apenas o diretório inicial será persistente. As instalações de pacotes raiz não serão persistentes após reinícios de pod. Para um melhor entendimento, leia isto.
Ao resolver esses problemas, solucionamos a maioria das questões enfrentadas por um usuário e proporcionamos uma experiência decente com notebooks. Mas, com o tempo, percebemos que os usuários enfrentavam alguns desafios que descreveremos na próxima seção.
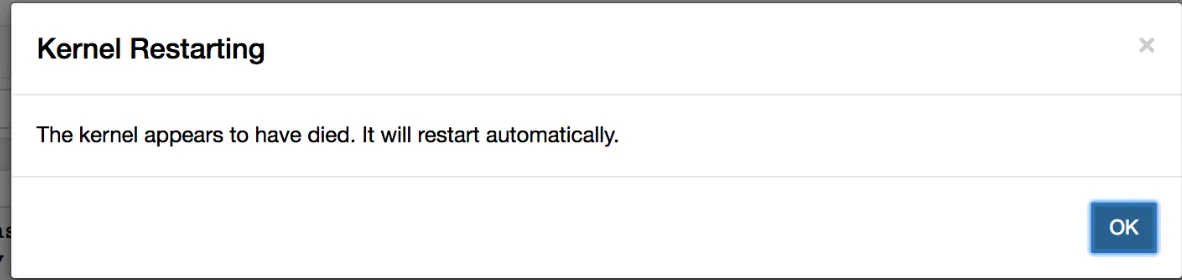
jupyterlab o pacote. Como o ambiente é persistente, o notebook não consegue iniciar (assim que o notebook atual é parado)kernelspec e garantir que kernelspec esteja configurado corretamente, o que pode causar problemas.
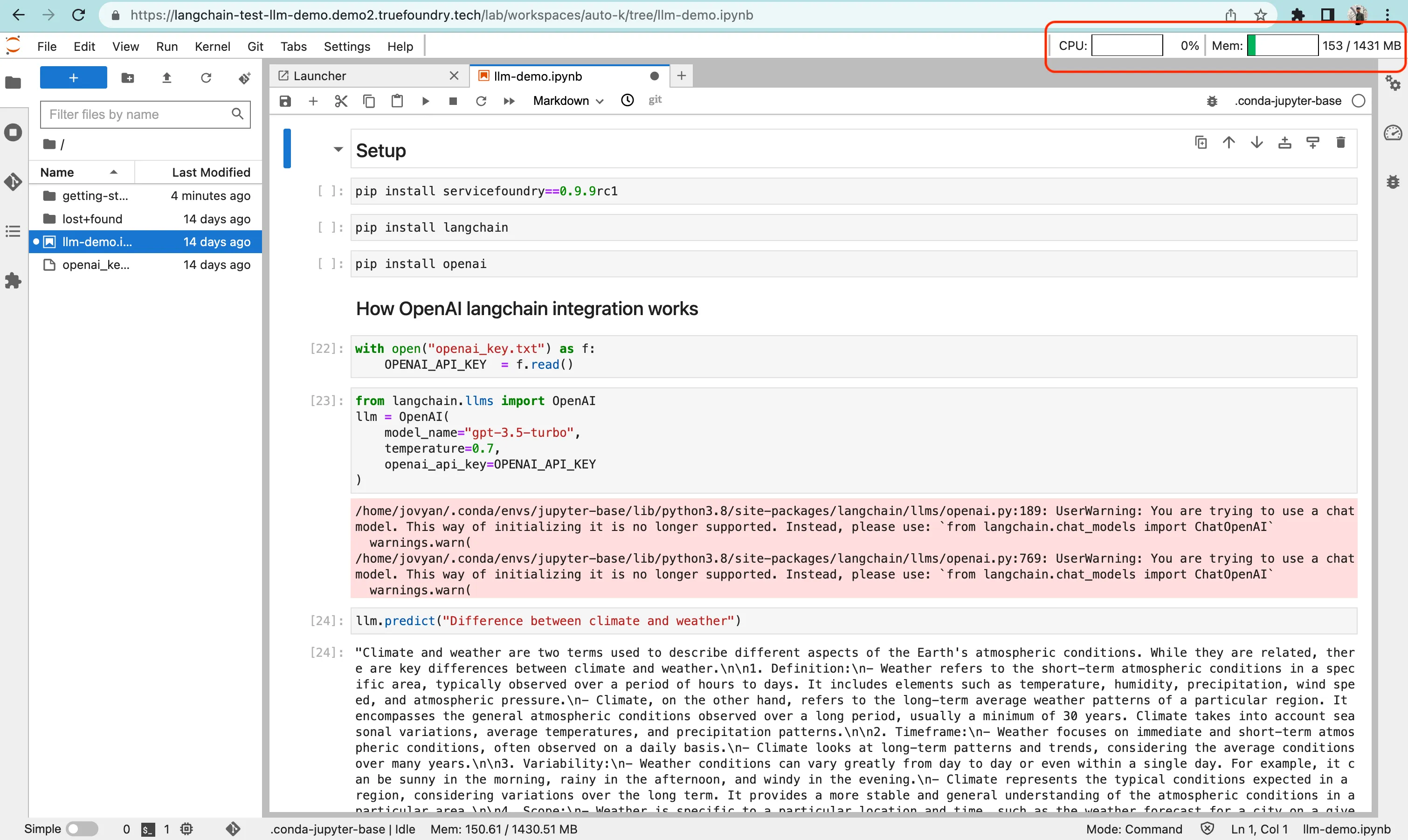
Adicionando métricas de uso de recursos ao notebook:
Adicionamos as métricas de uso de recursos ao notebook instalando a extensão jupyterlab-system-monitor==0.8.0 e configuramos suas definições no script de inicialização, passando argumentos ao iniciar o servidor Jupyterlab.
...
jupyter lab \
...
--ResourceUseDisplay.mem_limit=${mem_limit} \
--ResourceUseDisplay.cpu_limit=${cpu_limit} \
--ResourceUseDisplay.track_cpu_percent=True \
--ResourceUseDisplay.mem_warning_threshold=0.8
É assim que se parece na UI:
Separando o kernel que executa o servidor Jupyterlab do kernel de execução
Precisamos garantir que, quaisquer que sejam as alterações feitas pelo usuário no diretório inicial, o notebook sempre reinicie sem problemas. Para isso, usamos o ambiente anaconda 'base' de /opt/conda o diretório para iniciar o servidor Jupyterlab.
Além disso, criamos um ambiente separado no $HOME diretório, mas isso adiciona um kernel do base ambiente conda para listas de Kernels.
Para resolver isso, instalamos nb_conda_kernels para gerenciar kernels Jupyter. Configuramos o script de inicialização para garantir que apenas os ambientes Python persistentes apareçam na lista de kernels.
jupyter lab \
...
--CondaKernelSpecManager.conda_only=True \
--CondaKernelSpecManager.name_format={environment} \
--CondaKernelSpecManager.env_filter=/opt/conda/*"
Com isso, garantimos que o servidor de notebooks sempre iniciará com quaisquer alterações que um usuário faça dentro do notebook.
Também facilita o gerenciamento de múltiplos kernels. Basta criar um novo ambiente conda usando o comando conda create -n myenv e ele começará a aparecer na lista de kernels.
Embora os notebooks Jupyter resolvam vários problemas, há uma série de tarefas em que eles deixam de ser úteis:
Considerando essas limitações, decidimos resolver o problema. Adicionamos suporte ao code-server para oferecer uma experiência IDE completa aos usuários no navegador.
Ao adicionar suporte ao VS Code, permitimos que os usuários façam o seguinte:
localhost:8000 podem ser disponibilizados em ${NOTEBOOK_URL}/proxy/8000
Isso foi feito adicionando outra imagem Docker. Aqui está um diagrama que mostra as imagens Docker da Truefoundry.
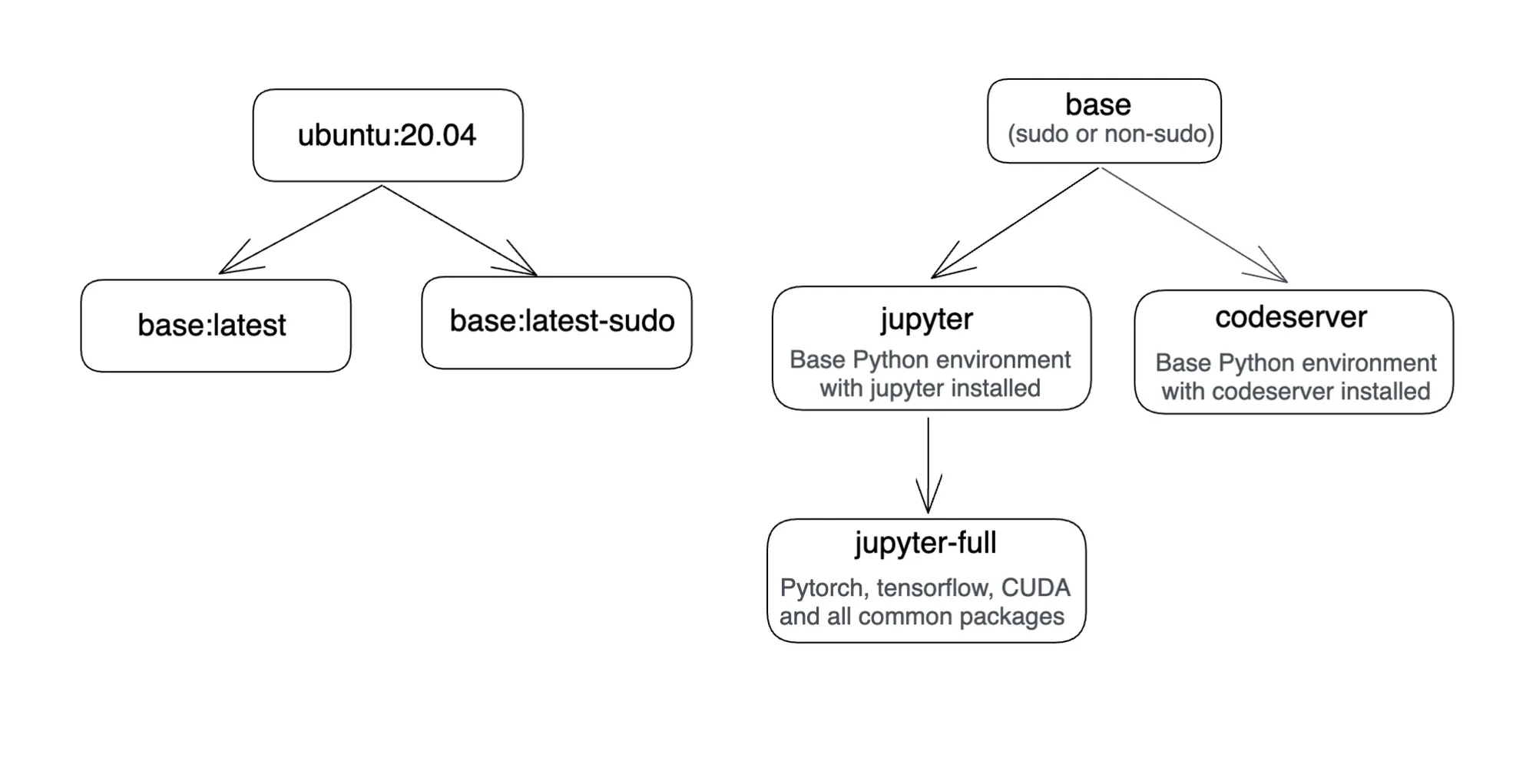
Acesso SSH ao seu Notebook/VSCode:
Embora na maioria dos casos o VS Code Hospedado possa resolver o problema. Mas pode haver casos (especialmente para Jupyter Notebooks) em que o usuário fica preso e precisa de acesso direto ao contêiner que executa seu Jupyter Notebook / Servidor VS Code.
Então, simplificamos isso instalando um servidor SSH em cada um dos notebooks e para se conectar ao seu contêiner, você precisa executar um comando simples e inserir sua senha:
ssh -p 2222 jovyan@test-notebook.ctl.truefoundry.tech

O poder desta ferramenta pode ser aprimorado com sua Extensão do VS Code chamada Remote Explorer onde você pode abrir diretamente todos os arquivos dentro do seu VS Code!
Clique aqui para saber mais sobre isso
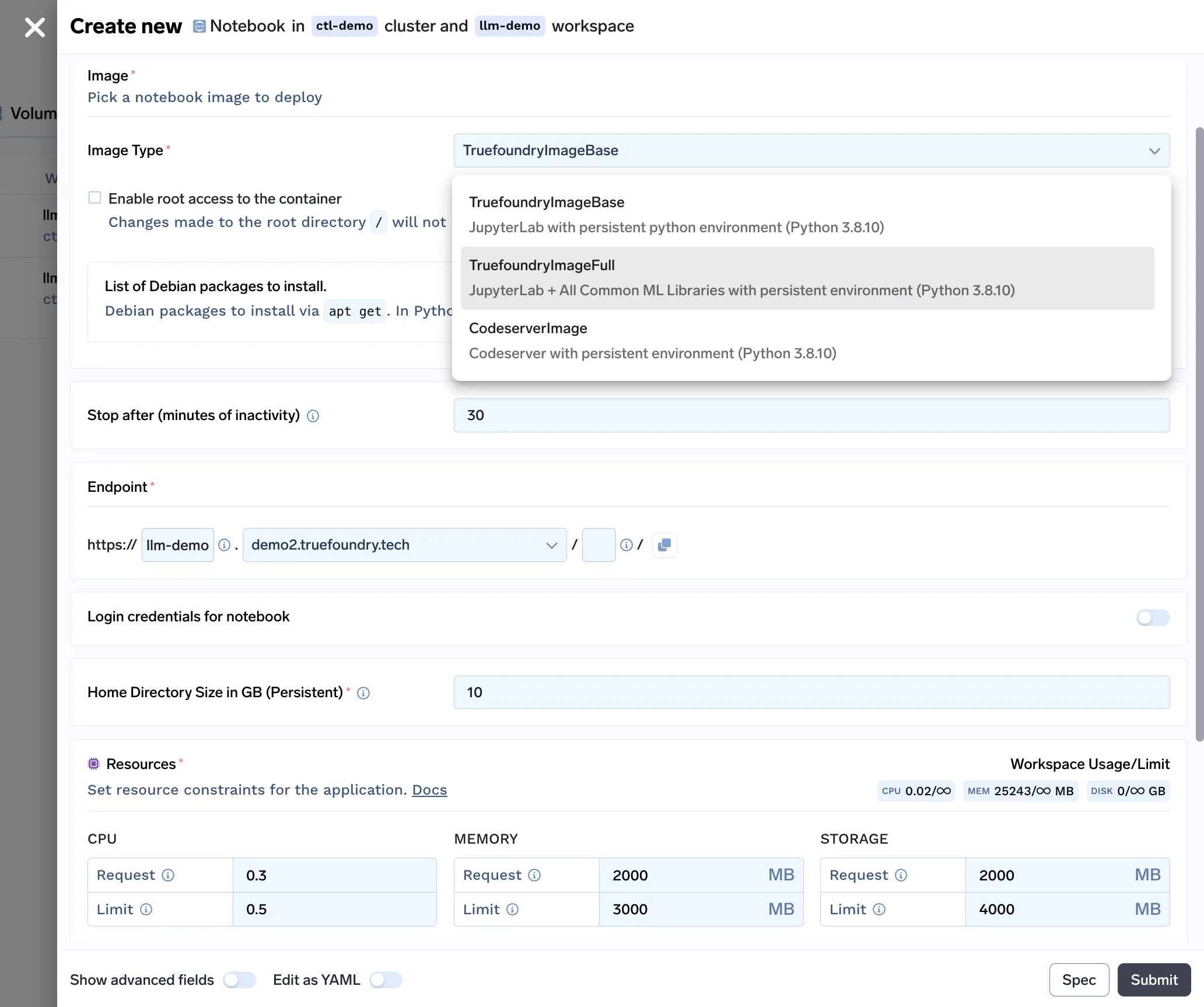
Com todos os recursos incluídos em nossa solução de notebook, veja como é o nosso formulário de implantação de notebook:
Por fim, vamos comparar os preços de cada uma das soluções gerenciadas com a Truefoundry.
Como a Truefoundry funciona implantando na nuvem do cliente ao conectar seu Cluster Kubernetes, aqui está o preço da Truefoundry rodando em diferentes provedores de nuvem.
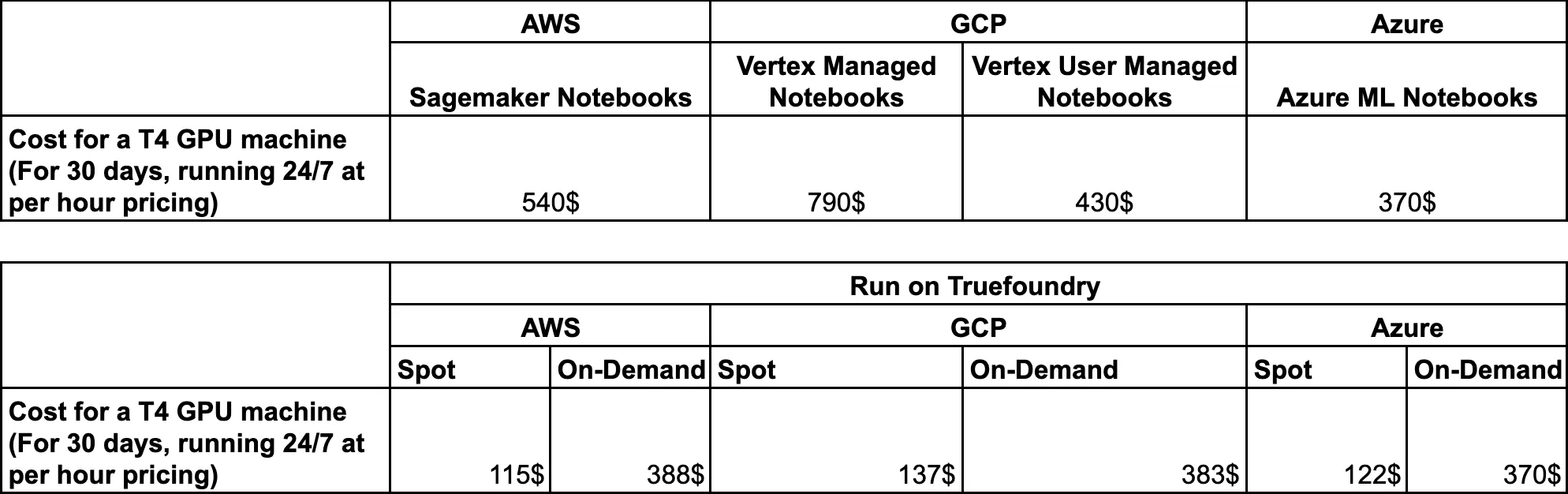
No caso da Truefoundry, você pode economizar muitos custos, pois:
Este foi um breve resumo sobre nosso esforço na construção da solução de notebooks. Você pode se juntar ao nosso Friends of Truefoundry canal do Slack se quiser discutir em profundidade nossa abordagem ou se tiver alguma sugestão.
Se você quiser experimentar nossa plataforma, pode se registrar aqui!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




