Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
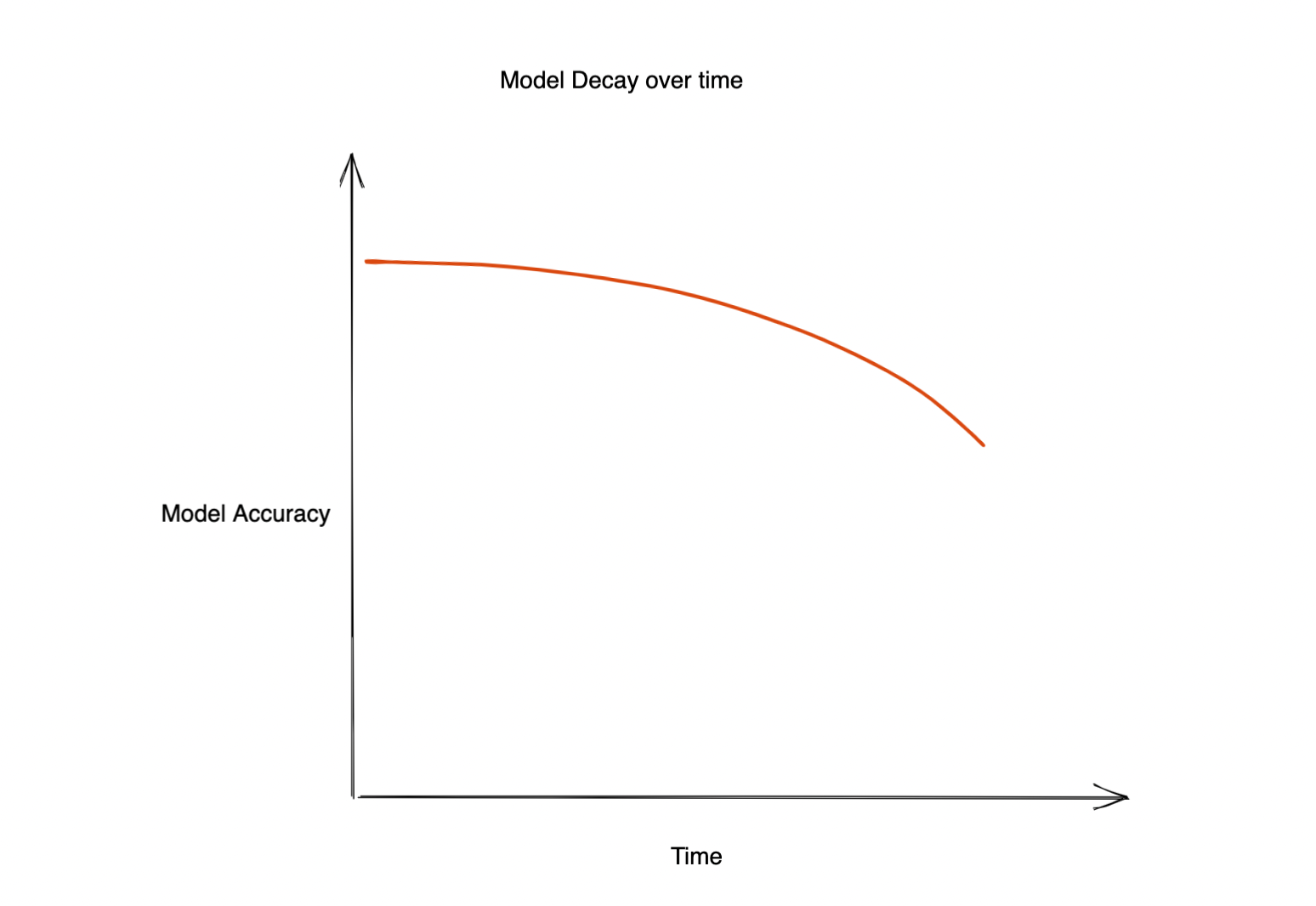
Machine Learning tem um impacto significativo em quase todos os aspectos dos negócios. Mas, frequentemente, a precisão do modelo implantado começa a decair, causando uma má experiência ao cliente e impactando negativamente o negócio. A questão é: por que a precisão deste modelo diminui? Isso pode ocorrer por vários motivos. Por exemplo:
Um modelo de detecção de spam não consegue detectar e-mails de spam corretamente após algum tempo, já que os ‘spammers’ atualizam as palavras e seus padrões de e-mail, que são ‘desconhecidos’ para o modelo.
Um modelo de recomendação para compras pode ser significativamente afetado por grandes eventos mundiais, como o surto de covid-19, o que altera as preferências dos clientes.
Um modelo de previsão de churn irá decair com o tempo, à medida que os comportamentos dos clientes e os padrões de gastos mudam lentamente ao longo do tempo.
Decaimento do modelo ao longo do tempo
Então, como garantimos que o desempenho do nosso modelo não diminua com o tempo? Como descobrir quando retreinar nosso modelo para evitar uma queda na precisão?
A resposta é ‘drift’. É preciso detectar o ‘drift’ de forma oportuna e ‘precisa’ e tomar as medidas apropriadas de acordo.
O que é drift de modelo?
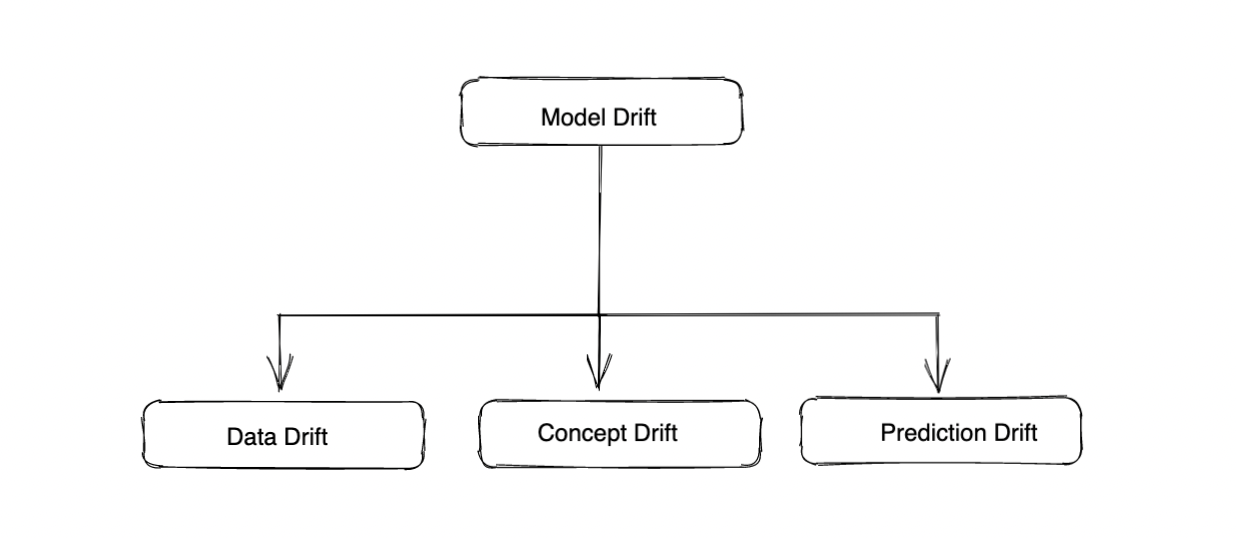
Drift de Modelo refere-se à mudança na distribuição dos dados ao longo de um período de tempo. No contexto de Machine Learning, geralmente nos referimos aos drifts nas características do modelo, previsões ou valores reais a partir de uma linha de base dada.
Vários métodos são usados para o monitoramento de drift, incluindo a estatística de Kolmogorov-Smirnov, a distância de Wasserstein e a divergência de Kullback-Leibler. Essas métricas são frequentemente usadas em cenários de aprendizado online, onde o sistema alvo evolui continuamente e o modelo deve se adaptar em tempo real para manter sua precisão. Por exemplo, um modelo de recomendação para filmes pode sofrer drift ao longo do tempo à medida que o comportamento do cliente muda, e um modelo de previsão de churn pode sofrer drift com mudanças nas condições econômicas.
Diferentes tipos de drift de modelo:
Drift de Dados: Isso se refere à mudança nas distribuições de diferentes características ou mudanças nas relações entre diferentes características ao longo do tempo. Isso pode ser devido a mudanças nos próprios inputs. Por exemplo, para um modelo que avalia a capacidade de crédito treinado com dados de um ano, a renda média sofreria drift devido a mudanças econômicas/recessão.
Drift de Conceito: Drift de conceito refere-se ao drift nos valores de verdade fundamental (ground truth) do modelo. Isso indica uma mudança na distribuição dos valores reais para os quais o modelo está sendo usado. O drift de conceito não depende do modelo, mas apenas dos valores de verdade fundamental. O drift nos valores reais indica que pode haver uma mudança na relação entre as características e os valores reais (quando comparado com o conjunto de dados de treinamento ou períodos anteriores), o que aponta para a necessidade de retreinar o modelo.
Drift de Previsão: Drift de previsão refere-se ao drift na distribuição dos valores previstos em comparação com os valores previstos dos dados de treinamento ou dados de um período anterior. O drift de previsão geralmente indica um drift de dados subjacente, já que as previsões são uma função do modelo e das características, e o modelo permanece inalterado. O drift de previsão pode nos ajudar a detectar o drift de dados e a diminuição da precisão do modelo.
Drift de Modelo
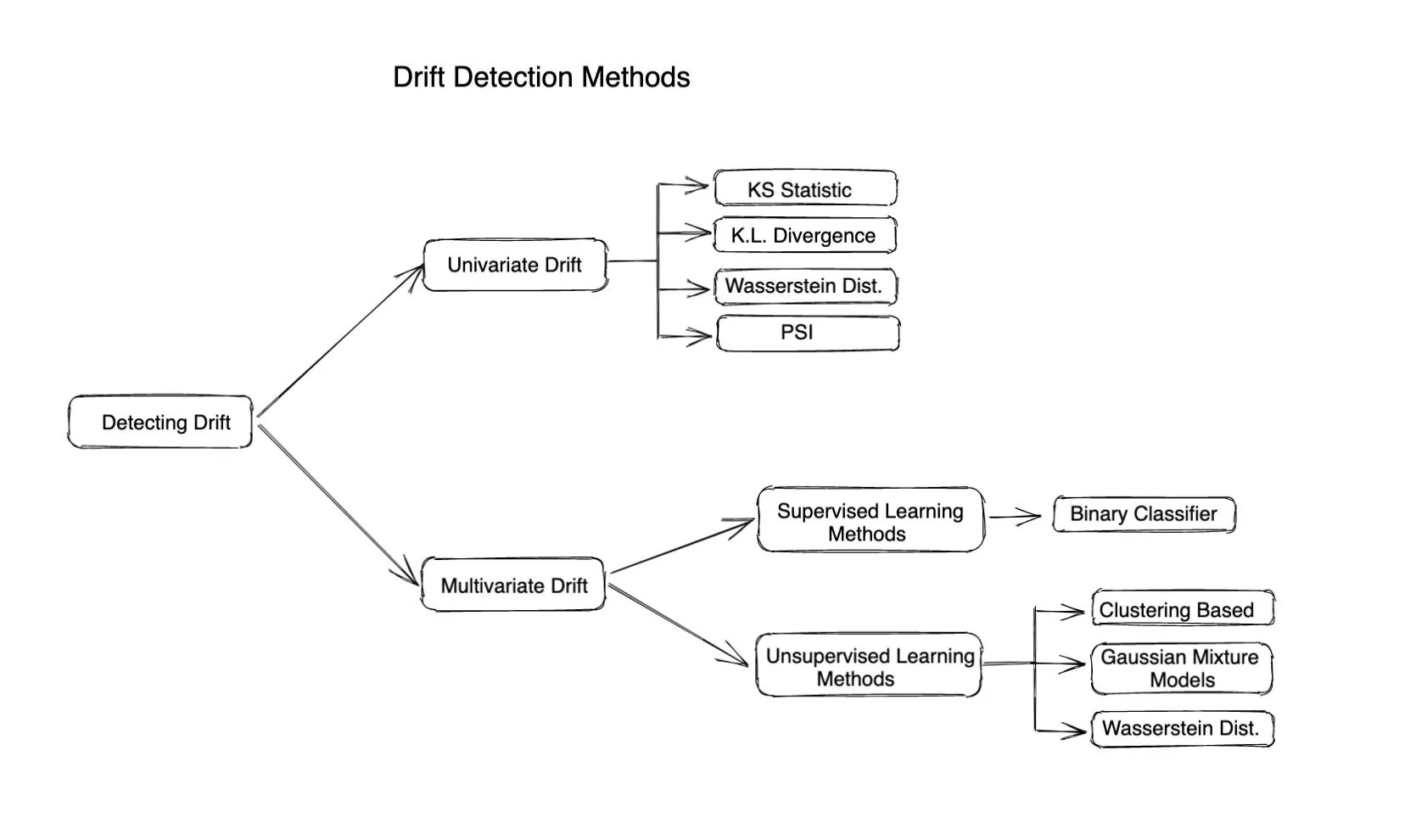
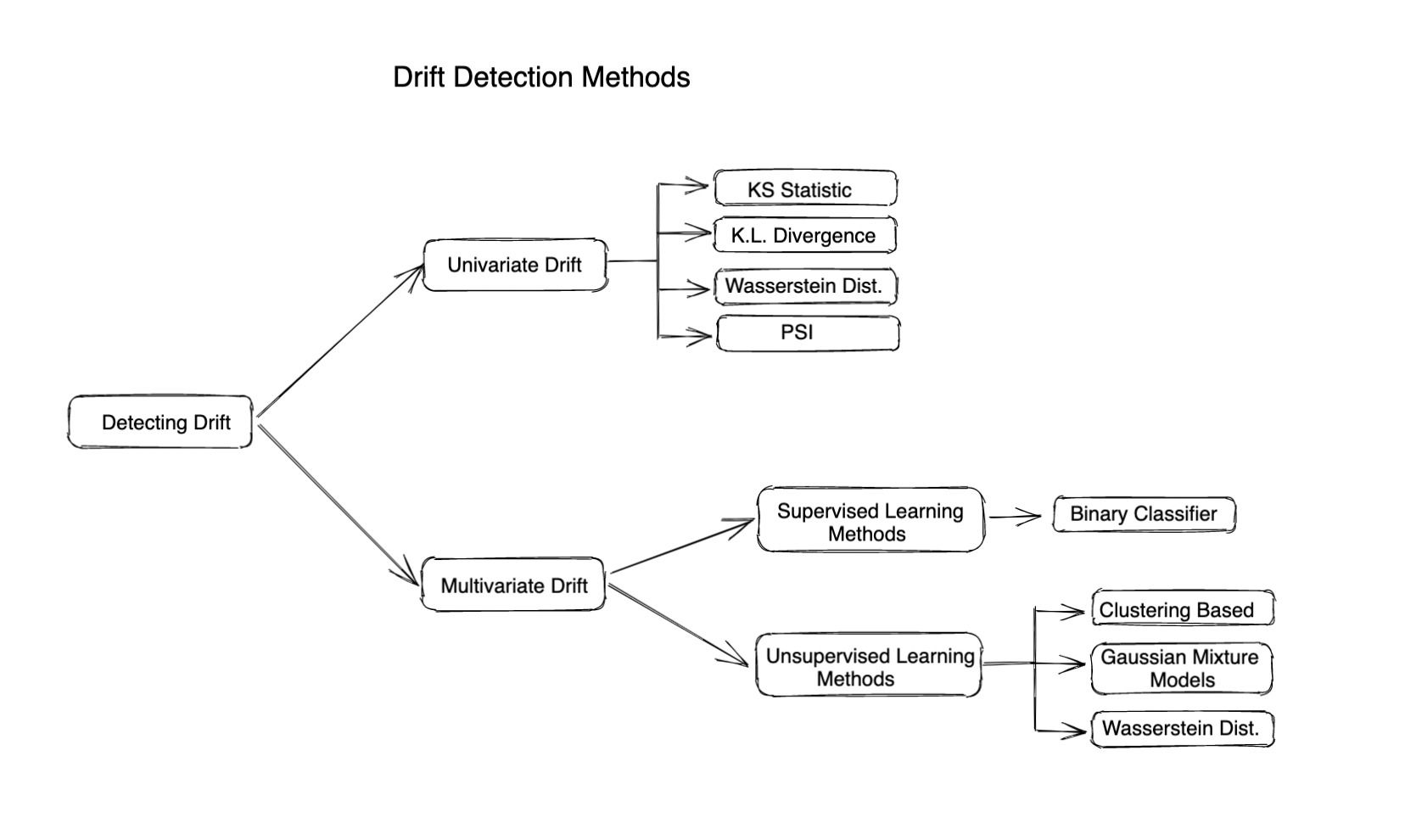
Diferentes Métodos de Monitoramento de Drift
Métodos Estatísticos
Métodos estatísticos são usados para medir a diferença entre a distribuição dada e a distribuição de referência. Métricas baseadas em distância ou divergência são frequentemente usadas para calcular o drift em uma característica ou valor real. Métodos estatísticos podem ser bons na detecção de outliers ou mudanças na distribuição de entrada e são muito simples de calcular e interpretar. Eles não consideram a mudança na correlação entre diferentes características, então eles descrevem a história completa do drift apenas quando as características de entrada são independentes.
Aqui estão algumas métricas famosas baseadas em distância para calcular o drift
Estatística de Kolmogorov-Smirnov: Ela mede a diferença máxima entre duas funções de distribuição cumulativa. É um teste não paramétrico que não assume uma distribuição específica para os dados. É amplamente utilizada na detecção de drift devido à sua capacidade de detectar mudanças na distribuição dos dados.
Distância de Wasserstein: É também conhecida como Distância do Transportador de Terra (EMD). Ela mede a quantidade de "trabalho" necessária para transformar uma distribuição em outra. Ela tem a capacidade de capturar mudanças sutis na distribuição dos dados que podem não ser capturadas por outras métricas de distância.
A distância de Wasserstein ganhou popularidade recentemente devido à sua capacidade de lidar com dados de alta dimensão e ruidosos.
Divergência de Kullback-Leibler: É uma medida da diferença entre duas distribuições de probabilidade, também conhecida como entropia relativa ou divergência de informação. É uma métrica não simétrica, o que significa que a divergência KL da distribuição A para a distribuição B não é igual à divergência KL da distribuição B para a distribuição A.
É uma das métricas mais amplamente utilizadas para o rastreamento de drift, mas a cardinalidade da característica/previsão que está sendo rastreada não deve ser muito alta.
PSI (Índice de Estabilidade Populacional): O PSI mede o quanto uma população se deslocou ao longo do tempo ou entre duas amostras diferentes de uma população em um único número. Ele faz isso agrupando as duas distribuições em intervalos e comparando as porcentagens de itens em cada um dos intervalos, resultando em um único número que você pode usar para entender o quão diferentes as populações são. As interpretações comuns do resultado do PSI são:
PSI < 0.1: nenhuma mudança populacional significativa
PSI < 0.2: mudança populacional moderada
PSI >= 0.2: mudança populacional significativa
Assim, pode-se configurar monitores para o valor de drift das características que impactam a precisão do modelo e tomar ações relevantes com base nisso.
Drift em Nível de Modelo (Detecção de drift multivariado)
A detecção de drift multivariado ajuda a detectar mudanças ou drifts em múltiplas variáveis ou características em conjunto. Ao contrário da detecção de drift univariado, que se concentra apenas na detecção de mudanças em uma única variável, a detecção de drift multivariado considera a relação entre múltiplas características e não assume que todas as características são independentes umas das outras.
Dessa forma, os métodos de deteção de desvio multivariado podem detetar alterações na distribuição dos dados, alterações na relação entre variáveis e alterações na relação funcional entre variáveis. Estes métodos são particularmente úteis em sistemas complexos onde as alterações numa variável podem ter um impacto significativo no comportamento de outras variáveis. Portanto, o desvio multivariado ajuda os utilizadores a ter uma melhor compreensão das alterações nos dados de inferência. Também é mais fácil de monitorizar, pois apenas uma métrica precisa ser acompanhada em comparação com o acompanhamento de cada característica separadamente. Mas, ao mesmo tempo, é computacionalmente pesado para calcular e pode ser excessivo para sistemas mais simples.
Os algoritmos de deteção de desvio multivariado geralmente dependem de um modelo de machine learning para calcular o desvio. Assim, estes algoritmos podem ser classificados da seguinte forma:
Utilizando Métodos Supervisionados: Estes geralmente dependem de treinar um modelo classificador binário para adivinhar se um ponto de dados é do dataframe de referência. Um valor mais alto da precisão do modelo indica um desvio maior.
Para descobrir quais características sofreram desvio, a importância das características deste modelo de classificação binária é utilizada.
Métodos de Aprendizagem Não Supervisionada: Aqui estão alguns métodos: Agrupamento: Utilize K-means, DBSCAN ou qualquer outro algoritmo de agrupamento para encontrar agrupamentos no conjunto de dados de referência e no conjunto de dados atual e depois encontrar diferenças entre os agrupamentos para avaliar se os dados sofreram desvio ou não.
Modelos de Mistura Gaussiana (GMM): O GMM representa os nossos dados como uma mistura de distribuições Gaussianas. O GMM pode ser usado para detetar desvio multivariado comparando os parâmetros das distribuições Gaussianas do conjunto de dados atual com o conjunto de dados de referência.
Análise de Componentes Principais (PCA): Utilize PCA para reduzir as dimensões do conjunto de dados e depois utilize algoritmos regulares de deteção de desvio univariado considerando as características como únicas.
Em resumo, a deteção de desvio multivariado é útil em sistemas complexos e é mais fácil de monitorizar, pois há apenas um KPI para acompanhar.
Deteção de Desvio do Modelo
Conclusão:
O desempenho de um modelo implementado em produção acabará por diminuir. O tempo necessário para esta degradação dependerá do caso de uso. Em alguns casos, os modelos podem não sofrer desvio durante um ano, enquanto outros modelos podem exigir retreinamento a cada hora! Assim, compreender a causa desta degradação e detetá-la torna-se extremamente importante. É aqui que a ‘deteção precoce de desvio’ pode ajudar.
Em conclusão, os modelos em produção devem ter mecanismos adequados de rastreamento ou monitorização de desvio e pipelines de retreinamento configurados para criar o melhor valor a partir de um modelo de machine learning!
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, permitindo-lhes total flexibilidade no teste e implantação de modelos, ao mesmo tempo em que garante total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as Equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos - permitindo-lhes economizar custos e lançar Modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.






























.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




