Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Gemini 3 vs Kimi-K2 Thinking vs Grok-4.1 vs GPT-5.1: Quem Realmente Vence o Humanity’s Last Exam?
Published: May 21, 2026
Built for Speed: ~10ms Latency, Even Under Load
Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed
Quando o Google diz “Planeje qualquer coisa” com o Gemini 3, a Moonshot afirma que o Kimi-K2 Thinking é o novo SOTA em raciocínio, a xAI chama o Grok-4 de “o modelo mais inteligente do mundo”, e a OpenAI continua a impulsionar o GPT-5.1, é difícil saber o que é real e o que é apenas uma impressão.
Em vez de mais uma parede de gráficos de benchmark, aqui está uma pergunta mais específica:
O que acontece se você submeter o Gemini 3, Kimi-K2 Thinking, Grok-4.1 e GPT-5.1 ao mesmo conjunto de problemas no estilo do Último Exame da Humanidade — e realmente observar como eles pensam?
Neste artigo:
Por que Humanity’s Last Exam (HLE) se tornou o “chefe final” dos benchmarks acadêmicos.
Um breve panorama de Gemini 3, Kimi-K2 Thinking, Grok-4.1 e GPT-5.1 como modelos de “pensamento”.
Cinco estudos de caso concretos no estilo HLE abrangendo matemática, física multimodal, ciência de contexto longo, teoria dos jogos e planejamento.
Como executar os mesmos experimentos você mesmo via o TrueFoundry AI Gateway.
1. O Último Exame da Humanidade em 2 minutos
Benchmarks como o MMLU já estão praticamente "esgotados" na vanguarda. Muitos dos principais modelos estão acima de 90% neles, então outro modelo com +1 ou −1% não diz muito sobre como é realmente trabalhar com ele.
O Último Exame da Humanidade (HLE) é diferente:
É um exame elaborado por especialistas que abrange matemática, ciências naturais, engenharia, economia, humanidades, direito e muito mais.
Ele mistura múltipla escolha e correspondência exata perguntas, muitas das quais exigem várias etapas de raciocínio não óbvias.
Uma parte das perguntas é multimodal, forçando os modelos a raciocinar em conjunto sobre texto e imagens.
Crucialmente, mesmo os melhores modelos hoje ainda estão longe do nível de um especialista humano na HLE, e a sua confiança é frequentemente mal calibrada.
Os autores pedem explicitamente às pessoas para não republicarem as perguntas originais, porque querem que a HLE continue a ser um benchmark útil a longo prazo. Assim, nesta publicação:
Nós não mostramos a formulação original de nenhuma pergunta.
Em vez disso, descrevemos cinco tarefas representativas “no estilo HLE” e como os modelos se comportam nelas.
Pode reproduzir estes padrões por si mesmo usando o conjunto de dados público da HLE ou problemas semelhantes do seu próprio domínio.
2. Quatro modelos de “pensamento” em 2025
Não estamos a comparar “chatbots” aqui, estamos a analisar modelos apresentados explicitamente como raciocinadores: cadeia de pensamento profunda, ferramentas, contexto longo, planeamento.
Gemini 3 (Pro + Deep Think)
A Google apresenta o Gemini 3 como o seu modelo mais capaz até à data:
Mais forte raciocínio e compreensão multimodal do que a geração Gemini 2.5.
Pontuações competitivas em HLE sem ferramentas, além de excelente desempenho em GPQA, MMMU-Pro, Video-MMMU e outros benchmarks de raciocínio.
Um grande foco em agentes de longo prazo e com chamada de ferramentas: a história do "planejar qualquer coisa", incluindo os melhores resultados em benchmarks de planejamento como o Vending-Bench.
O Gemini 3 também expõe um Deep Think modo que gasta mais computação e tokens em problemas difíceis para extrair um pouco mais de precisão.
Kimi-K2 Thinking
Da Moonshot, o Kimi-K2 Thinking é um modelo de "pensamento" de peso aberto:
Arquitetura de mistura de especialistas com um enorme orçamento total de parâmetros, mas um subconjunto ativo menor por token.
Contexto longo (centenas de milhares de tokens) e cadeia de pensamento muito elaborada por concepção.
Análises públicas frequentemente mostram o Kimi-K2 Thinking e sua variante "Heavy" no topo ou perto dele em HLE e outros benchmarks de raciocínio.
Se você já viu um modelo despejar páginas de monólogo interno para um problema de matemática: essa é a estética no estilo Kimi.
Grok-4 / Grok-4.1
da xAI Grok-4 é apresentada como:
Um modelo altamente capaz de raciocínio com uso nativo de ferramentas e pesquisa na internet.
Forte em HLE, GPQA e tarefas de longo prazo onde os agentes devem manter um comportamento coerente ao longo de muitas etapas.
O Grok-4.1 adiciona mais foco na inteligência "emocional" e criativa, mas ainda mantém a força central de raciocínio.
Pense no Grok-4.x como o modelo que realmente quer ser um agente: planejar, pesquisar, agir, refletir, repetir.
GPT-5.1 (família GPT-5)
da OpenAI GPT-5 é a referência que a maioria das pessoas busca:
Muito forte em amplos conjuntos de benchmarks: codificação, raciocínio, multimodal, contexto longo.
Quando executado em um modo de alto "esforço de raciocínio" / "pensamento", ele aloca mais tokens e resolve problemas difíceis, tendendo a diminuir a diferença em benchmarks avançados como HLE e GPQA.
Vamos nos referir a GPT-5.1 Pensamento como uma variante do GPT-5 operando nesse perfil de alto esforço.
3. Como os comparamos (sem vazar HLE)
O objetivo aqui não era criar outro ranking, mas sim ver como esses modelos se comportam em tarefas do tipo HLE.
Em um nível geral:
Selecionamos um conjunto de perguntas HLE representativas (matemática, física multimodal, longos trechos científicos, teoria dos jogos, planejamento).
Para cada pergunta, usamos um prompt “modo de exame”:
“Raciocine passo a passo.”
“Explique seu raciocínio.”
“Termine com Resposta final: … e Confiança: ….”
Executamos exatamente a mesma pergunta e estrutura em:
Kimi-K2 Pensando
Grok-4.1
GPT-5.1 Pensando
Gemini 3 Pro (e onde disponível, Gemini 3 Deep Think)
Tudo isso foi conectado através do TrueFoundry AI Gateway:
Um único endpoint onde integramos OpenAI, Google, xAI, Moonshot e mais de 1000 outros modelos.
Um único local para registrar respostas, tokens, latência e custo por chamada.
Um único conjunto de autenticação, cotas e salvaguardas entre fornecedores.
Mais sobre isso depois — por enquanto, vamos analisar os cinco estudos de caso.
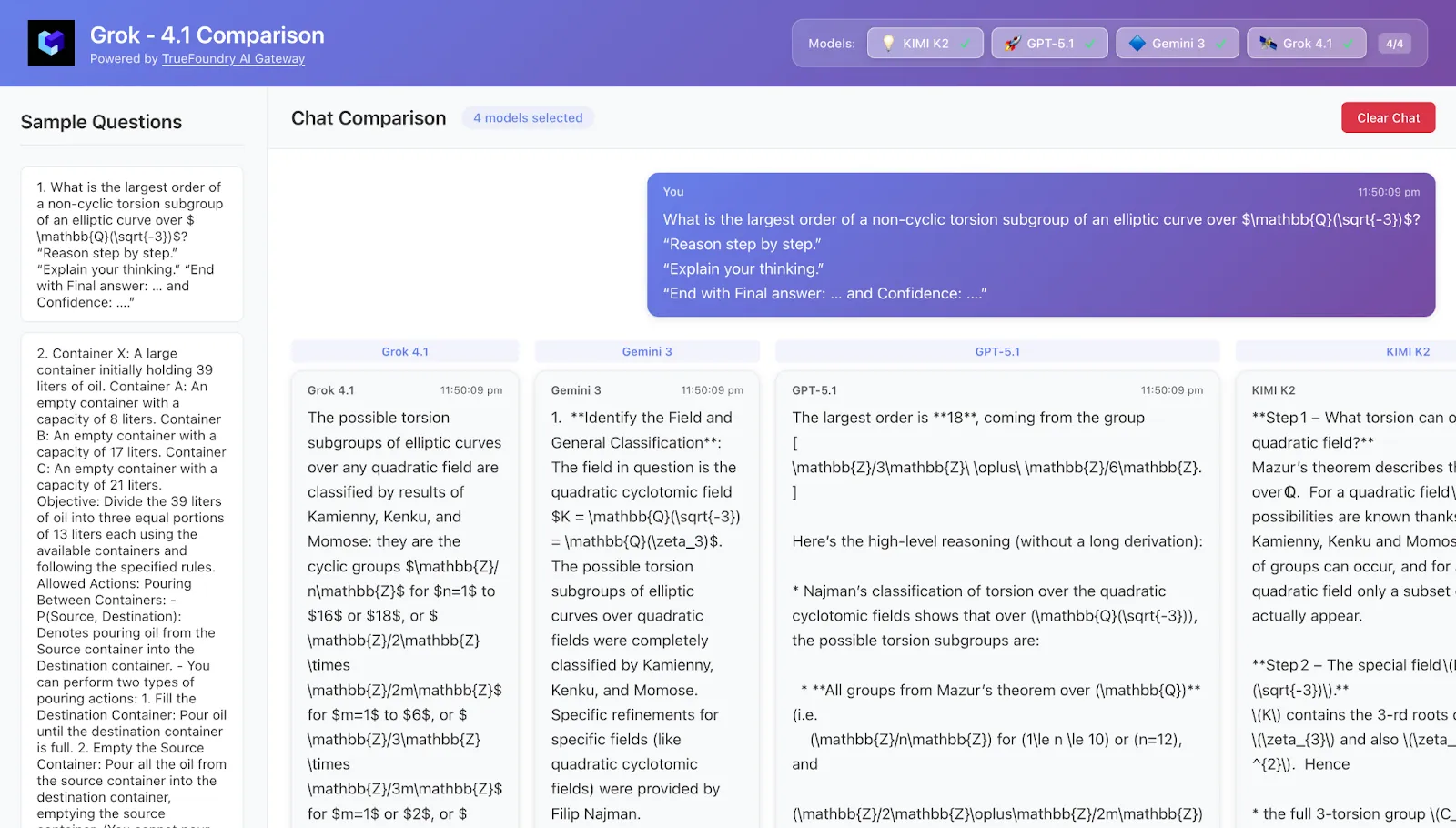
4. Estudo de Caso 1 – Matemática avançada: precisão vs. raciocínio intensivo em tokens
Tarefa Um problema de matemática de nível de pós-graduação (pense em teoria dos números / combinatória):
Resposta única e curta (um número inteiro ou uma expressão simples).
Requer cerca de 4 a 6 etapas de raciocínio não óbvias.
Muito difícil adivinhar corretamente sem realmente resolver o problema.
O que analisamos
O modelo estabelece a estrutura corretamente (por exemplo, teorema / classificação corretos)?
Ele leva o raciocínio até o fim sem perder um sinal de menos?
Quantos tokens ele gasta para chegar lá?
Quão calibrada é a sua confiança?
Padrões típicos observados
Pensamento Kimi-K2
Cadeia de pensamento extremamente longa: recorda teoremas relevantes, explora múltiplas abordagens candidatas, frequentemente ramifica e retrocede.
Muito forte em precisão, especialmente no modo “Pesado”, mas frequentemente gasta significativamente mais tokens do que outros.
A confiança auto-declarada é frequentemente de 90–100%, mesmo em problemas bastante delicados.
Grok-4.1
Audacioso e exploratório: esboça rapidamente uma resposta intuitiva e depois tenta justificá-la.
Quando acerta, parece brilhante; quando erra, pode ser muito confiante.
GPT-5.1 Thinking
Boa estrutura: enumera claramente os casos, os rotula e faz referências claras.
Frequentemente um pouco mais modesto nas suas estimativas de confiança, especialmente quando o problema exige múltiplos factos aprofundados.
Gemini 3 (Pro / Deep Think)
Raciocínio em várias etapas, mas notavelmente mais conciso do que as paredes de texto do Kimi-K2.
O modo Deep Think reduz grande parte da lacuna HLE com Kimi/Grok, mantendo-se, no entanto, um pouco mais comedido nas suas explicações.
Conclusão Se você busca cada ponto extra em matemática estilo HLE, Kimi-K2 Thinking e Grok-4.x parecem ser os líderes, com Gemini 3 Deep Think logo atrás. Se você valoriza custo e velocidade tanto quanto a precisão bruta, Gemini 3 e GPT-5.1 Thinking são atraentes porque alcançam resultados semelhantes enquanto consomem menos tokens.
5. Estudo de Caso 2 – Física multimodal: “observar o diagrama”
Tarefa Uma questão de física/engenharia com muitos diagramas:
Um diagrama de circuito, diagrama de corpo livre ou configuração óptica está incorporado como uma imagem.
A questão pede uma resposta numérica (por exemplo, corrente, ângulo, tempo).
Não é possível responder corretamente sem analisar a figura adequadamente.
O que observamos
O modelo descreve o diagrama de uma forma que corresponda à imagem?
Ele faz suposições que não estão presentes na imagem?
Quão bem ele combina imagem e texto em uma derivação coerente?
Padrões típicos observados
Gemini 3
Muito preciso em relação à própria imagem: “a seta aponta para a esquerda”, “há três resistores em série”, “a massa está presa por duas molas”.
Menos alucinações sobre o conteúdo do diagrama.
No geral, parece o mais fundamentado em seu raciocínio multimodal.
Pensamento do GPT-5.1
Forte compreensão multimodal, mas muitas vezes menos explícita: usa o diagrama corretamente, mas nem sempre o descreve em detalhes.
Quando falha, geralmente é por uma leitura incorreta do texto, e não da imagem.
Pensamento do Kimi-K2
Uma vez que os dados fornecidos estão corretos, a física é sólida.
Mas sob pressão, pode contar incorretamente elementos no diagrama (por exemplo, número de componentes) e depois propagar esse erro através de uma derivação muito longa.
Grok-4.1
Semelhante ao GPT-5.1 em estilo: intuitivo, muitas vezes correto, mas ocasionalmente excessivamente confiante em uma linha ou rótulo mal interpretado.
Conclusão Se grande parte da sua carga de trabalho no estilo HLE envolve diagramas, esquemas ou quebra-cabeças visuais, a pilha multimodal do Gemini 3 se destaca. GPT-5.1, Kimi-K2 e Grok-4.1 são todos capazes, mas mais propensos a "ver" detalhes que não estão exatamente lá.
6. Estudo de Caso 3 – Ciência de contexto longo: lendo, não apenas resolvendo
Tarefa Uma passagem científica longa e densa (biologia / medicina / química):
Vários parágrafos descrevendo um experimento, métodos, resultados e ressalvas.
Depois, uma pergunta que exige a integração de informações de toda a passagem, não apenas do último parágrafo.
O que analisamos
O modelo resume a passagem com precisão?
Ele acompanha variáveis, condições e exceções entre os parágrafos?
Ele identifica corretamente quais detalhes realmente importam para responder à pergunta?
Padrões típicos observados
Gemini 3
Bom em comprimir passagens longas em Pontos chave com foco cirúrgico.
Tende a reafirmar os principais fatos e depois raciocinar “a partir das anotações” para chegar à resposta.
Raramente se contradiz ao fazer referência a partes anteriores do texto.
Pensamento GPT-5.1
Excelente no rastreamento de variáveis e configurações experimentais; parece um monitor cuidadoso.
Frequentemente o fluxo de trabalho mais limpo de “ler → resumir → inferir”.
Pensamento Kimi-K2
Hiperdetalhado: repete grande parte do texto e às vezes rededuz a teoria de base.
Essa profundidade é útil, mas o comprimento excessivo significa que um desvio ocasional ou uma contradição interna podem surgir.
Grok-4.1
Muito bom em extrair implicações práticas (“isso sugere que o tratamento A é preferível quando…”).
Às vezes ignora casos extremos raros mencionados no texto.
Conclusão Para o estilo HLE “leia isto e realmente entenda” perguntas, Gemini 3 e GPT-5.1 Thinking são particularmente fortes: eles resumem de forma concisa, preservam detalhes importantes e mantêm a lógica clara. Kimi-K2 e Grok-4.1 também são capazes, mas suas narrativas mais longas podem introduzir mais oportunidades para desvios.
7. Estudo de Caso 4 – Teoria dos jogos e microeconomia: quem raciocina como um assistente de ensino?
Tarefa Uma questão de microeconomia / teoria dos jogos:
Múltiplos jogadores, um pequeno conjunto de ações e descrições de recompensas.
É pedido que você encontre equilíbrios, caracterize estratégias ou compare resultados de bem-estar.
O que analisamos
O modelo enumerar todos os casos relevantes?
Ele mantém a lógica consistente da análise de caso até a resposta final?
Ele está ciente de sutilezas como estratégias mistas, dominância ou simetria?
Padrões típicos observados
Kimi-K2 Thinking
Parece um assistente de ensino de pós-graduação: muita análise caso a caso, construção explícita de contraexemplos, consideração cuidadosa de casos extremos.
Muito forte quando se quer ver toda a árvore de raciocínio.
Grok-4.1
Intuitivamente excelente em raciocínio de incentivos (“se o jogador A se desviar, ele ganha X, então isso não pode ser um equilíbrio”).
Ocasionalmente, fixa-se num equilíbrio intuitivo precocemente e precisa de ser incentivado a reconsiderar.
Pensamento GPT-5.1
Sistemático: rotula casos (Caso 1, Caso 2, …), resume as descobertas e as conecta de forma fluida.
Bom equilíbrio entre profundidade e concisão.
Gemini 3
Semelhante ao GPT-5.1 na estrutura, com uma tendência um pouco maior a retroceder explicitamente (“vamos reconsiderar a suposição de que…”), especialmente num modo estilo Deep Think.
Conclusão Em questões HLE de teoria dos jogos, Pensamento Kimi-K2 e Grok-4.1 parecem mais próximos de um assistente de ensino humano: muitos casos explícitos e discussão intuitiva. Gemini 3 e GPT-5.1 chegar à resposta com menos rodeios, o que pode ser preferível quando se está a enviar saídas diretamente para código ou pipelines de decisão.
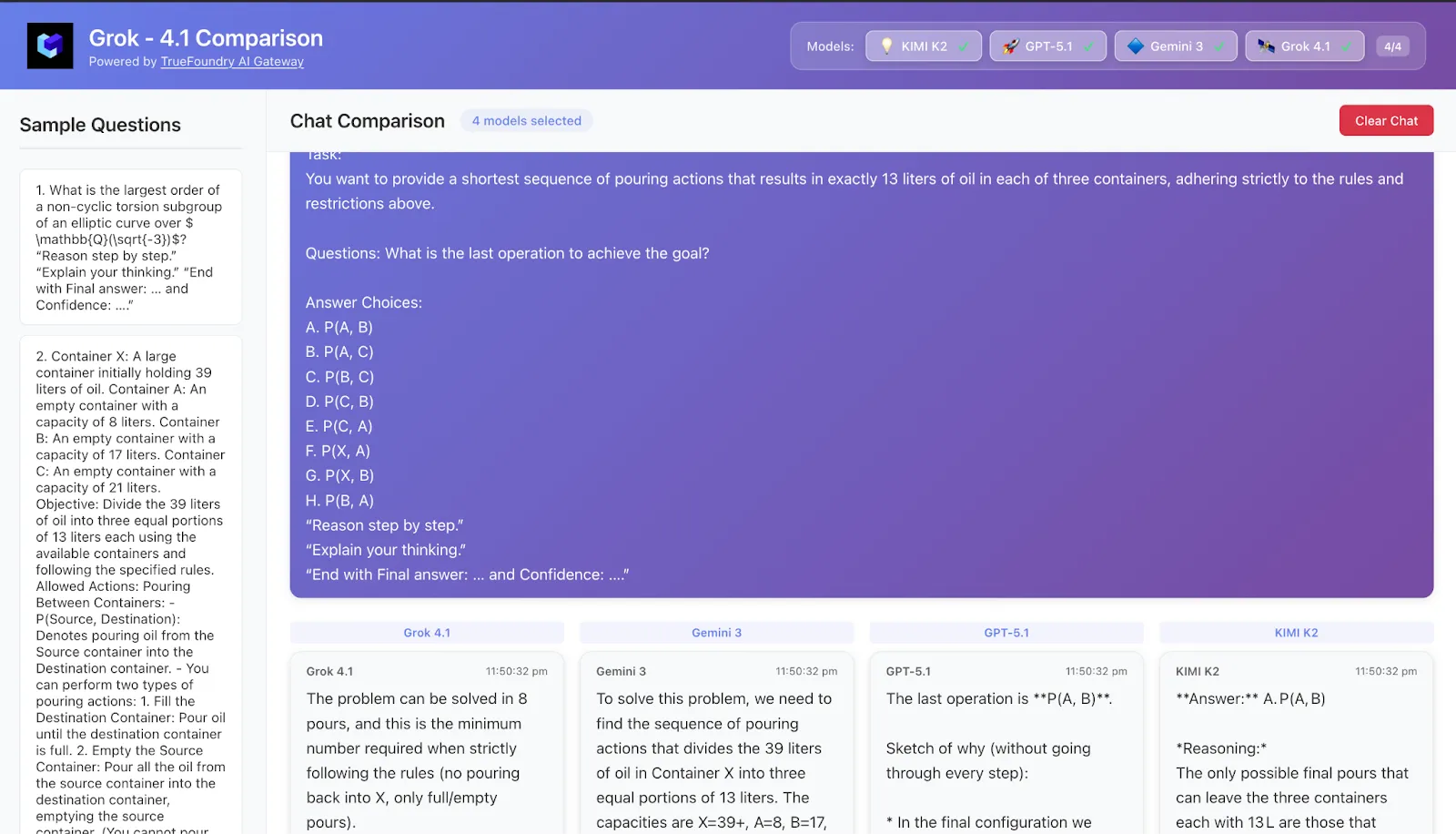
8. Estudo de Caso 5 – Problemas de planejamento: mini-agentes dentro de um prompt
Tarefa Um quebra-cabeça no estilo de planejamento / pesquisa operacional:
Vários recipientes, capacidades e regras de despejo, ou uma configuração de agendamento / gestão de estoque.
Você deve escolher uma política ou sequência de ações que atinja um objetivo em passos mínimos sob restrições.
O que observamos
O modelo configura o espaço de estados claramente?
Ele simula sequências corretamente sem esquecer ações anteriores?
Ele se mantém fiel às restrições que ele próprio declarou?
Padrões típicos observados
Grok-4.1
Muito parecido com um agente: escreve explicitamente os estados ("após o passo 3: inventário é X, Y, Z"), verifica cada um em relação ao objetivo e corrige o curso quando necessário.
É o que mais se assemelha a usar um agente de planejamento real dentro de um único prompt.
Gemini 3
Estilo de planejamento semelhante: reformula o objetivo e as restrições, propõe uma política e, em seguida, simula várias etapas.
Particularmente bom em não perder o controle do estado ao longo de sequências mais longas, o que se alinha bem com sua proposta de longo prazo / Vending-Bench.
Pensamento GPT-5.1
Bom planejamento conceitual, mas mais propenso a pequenos erros aritméticos ou de contabilidade em muitas etapas.
Quando solicitado a garantir a “sequência mais curta”, às vezes precisa de uma segunda tentativa.
Pensamento Kimi-K2
Fornece muita simulação detalhada, mas a combinação de CoT longo + estado complexo às vezes leva a pequenas inconsistências (por exemplo, uma quantidade mudando silenciosamente entre as etapas).
Conclusão Em tarefas HLE com foco em planejamento, Grok-4.1 e Gemini 3 parecem os mini-agentes mais confiáveis. Kimi-K2 e GPT-5.1 são muito capazes, mas seus longos rastros de raciocínio às vezes podem trabalhar contra eles quando o rastreamento de estado é crítico.
9. Então… quem “vence” o Último Exame da Humanidade?
Se você olhar apenas para Percentagens HLE, Kimi-K2 Thinking (especialmente variantes Pesadas) e algumas configurações do Grok-4 atualmente estão no topo ou perto dele, com Gemini 3 Deep Think logo atrás e GPT-5 Pro um pouco abaixo.
Mas o HLE é complicado no bom sentido:
A precisão ainda está muito abaixo da de especialistas humanos.
A confiança é muitas vezes mal calibrada: os modelos podem ser muito confiantes e muito errados.
Diferentes domínios (matemática vs. ciência vs. planejamento vs. humanidades) apresentam vencedores diferentes.
Dos cinco estudos de caso:
Kimi-K2 Thinking
Melhor quando você quer profundidade máxima e se sentem à vontade em pagar em tokens e latência para extrair cada último pedaço de desempenho.
Grok-4.1
Destaca-se em planejamento e raciocínio semelhante ao de um agente; se suas tarefas se assemelham a simulações ou decisões de negócios em várias etapas, o Grok parece muito natural.
GPT-5.1 Thinking
Uma opção padrão forte e segura: ótima leitura de contexto longo, estrutura geralmente limpa e muito fácil de integrar em sistemas existentes.
Gemini 3 (Pro + Deep Think)
Particularmente atraente em raciocínio multimodal, compreensão de leitura estruturada, e planejamento — e o argumento de “Planeje qualquer coisa” não é apenas marketing; isso se manifesta na forma como ele lida com problemas longos e com estado.
Não há um único vencedor para o Último Exame da Humanidade. O modelo “melhor” é aquele que o que falha menos mal nas suas tarefas reais, sob suas restrições reais.
10. Como executamos isso através do TrueFoundry AI Gateway
Nos bastidores, não construímos quatro integrações separadas. Tudo passou pelo TrueFoundry AI Gateway (truefoundry.com/ai-gateway):
Um único endpoint para OpenAI (GPT-5.1), Google (Gemini 3), xAI (Grok-4.x), Moonshot (Kimi-K2) e centenas de outros modelos.
Observabilidade centralizada: logs para prompts, respostas, tokens, latência e erros entre fornecedores.
Governança e segurança integradas: RBAC, logs de auditoria e opções de implantação que mantêm os dados na sua nuvem ou on-premise.
No lado da experimentação, isso significou:
Conectamos nossa estrutura de avaliação uma única vez ao Gateway.
Registramos gpt-5.1-thinking, kimi-k2-thinking, grok-4.1, gemini-3-pro e gemini-3-deep-think apenas como IDs de modelo diferentes.
Alternar entre eles era uma alteração de configuração de uma linha, não uma nova integração de SDK.
11. Experimente o Gemini 3 (e o resto) no seu próprio “último exame”
Se você quiser reproduzir (ou desafiar) os padrões nesta publicação:
Escolha seu exame.
Use HLE ou um “último exame” interno construído a partir do seu próprio domínio: perguntas de pesquisa, tickets de suporte, revisões de código, análises pós-incidente.
Execute-o em vários modelos.
Aponte sua ferramenta de avaliação para o TrueFoundry AI Gateway e execute os mesmos prompts no Gemini 3, Kimi-K2 Thinking, Grok-4.1 e GPT-5.1 Thinking.
Compare em um só lugar.
Observe a correção, qualidade do raciocínio, uso de tokens, latência e custo lado a lado.
Decida qual modelo de “pensamento” realmente merece sua nota em suas tarefas.
Porque em 2025, o único benchmark que realmente importa não é HLE, MMLU ou GPQA — é o exame que se parece com o seu próprio trabalho. E você não precisa escolher um único modelo por fé quando pode conectar quatro deles por trás de um gateway e deixar os resultados falarem por si.
Perguntas Frequentes
Qual a diferença entre Kimi K2 e Gemini 3?
O Gemini 3 do Google foca na compreensão multimodal e em fortes capacidades de invocação de ferramentas com um modo Deep Think. O Kimi-K2 Thinking, um modelo de peso aberto, é conhecido por seu amplo contexto longo e raciocínio detalhado em cadeia de pensamento. Compreender kimi k2 vs gemini 3 revela abordagens distintas para a resolução avançada de problemas de IA.
Para que o kimi K2 thinking é mais adequado?
O Kimi-K2 Thinking é mais adequado para tarefas de raciocínio complexo e resolução profunda de problemas. Com seu contexto longo e cadeia de pensamento robusta por design, o **kimi k2** se destaca em desafios que exigem um monólogo interno extenso, como problemas de matemática avançada e benchmarks como o Humanity's Last Exam, frequentemente classificado entre os melhores modelos.
Gemini 3 vs GPT-5: qual é melhor?
Nosso blog explora Gemini 3 vs GPT-5.1, avaliando seu desempenho no Humanity's Last Exam. Descobrimos que 'melhor' depende da tarefa de raciocínio específica e do comportamento do modelo. A análise da TrueFoundry, conduzida através do nosso AI Gateway, destaca suas abordagens únicas para a resolução de problemas, ajudando você a determinar o ajuste ideal para suas soluções de IA.
Gemini 3 vs Grok-4: qual modelo tem melhor desempenho?
Ao comparar Gemini 3 vs Grok-4, ambos se destacam como poderosos agentes de raciocínio, demonstrando forte desempenho em tarefas complexas como o Humanity's Last Exam. O Gemini 3 apresenta compreensão multimodal avançada e um modo Deep Think, enquanto o Grok-4 foca no uso nativo de ferramentas e capacidades agentivas. O desempenho ideal frequentemente depende dos requisitos da tarefa específica.
Qual modelo de IA é melhor para tarefas de raciocínio?
Para tarefas de raciocínio complexo, modelos como Gemini 3, Kimi-K2 Thinking e GPT-5.1 demonstram fortes capacidades. Nosso blog avalia como cada um se comporta em diversos desafios, ajudando você a entender suas forças específicas. A escolha ideal ao comparar gemini 3 vs kimi k2 thinking vs gpt 5 depende, em última análise, das demandas exclusivas do seu projeto e do tipo de raciocínio necessário.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




.webp)


























.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




