




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
No mundo do Machine Learning (ML), a construção eficiente de imagens Docker não é apenas um luxo — é uma necessidade. A maioria das empresas possui um pipeline DevOps existente para construir e enviar imagens Docker, seja em laptops locais ou via pipelines de CI/CD. No entanto, à medida que os projetos de ML crescem em complexidade, com dependências maiores e iterações mais frequentes, o processo tradicional de construção de imagens Docker pode se tornar um gargalo significativo.
.webp)
Este artigo destaca como reduzimos o tempo de compilação no Truefoundry em 5 a 15 vezes em comparação com pipelines de CI padrão.
Projetos de ML geralmente envolvem inúmeras dependências pesadas - frameworks de deep learning (PyTorch, TensorFlow), bibliotecas de computação científica (NumPy, SciPy), drivers de GPU e toolkits CUDA. Essas dependências podem fazer com que as imagens Docker tenham vários gigabytes de tamanho, resultando em longos tempos de compilação.
O desenvolvimento de ML envolve mudanças frequentes no código que precisam ser implantadas para serem testadas. Cientistas de dados frequentemente não possuem o hardware necessário para executar seu código em seus laptops locais — o que significa que o código precisa ser executado no cluster remoto, o que frequentemente envolverá a construção de imagens.
Na Truefoundry, nosso objetivo é permitir que os desenvolvedores avancem em um ritmo de iteração rápido e para isso queríamos tornar nossas compilações Docker realmente rápidas. Para entender o que fizemos para otimizar os tempos de compilação, vamos primeiro entender como costumávamos construir imagens anteriormente na Truefoundry.
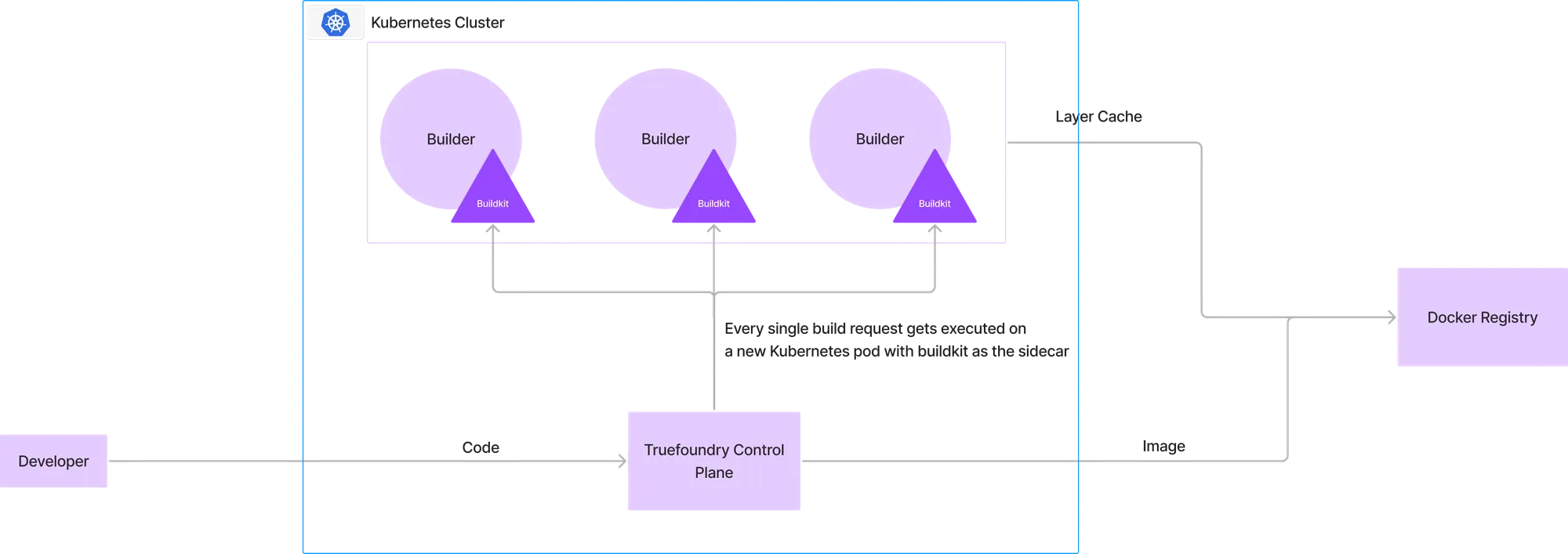
Toda vez que um desenvolvedor quisesse construir uma imagem, o código era carregado para o plano de controle, onde um novo pod começaria a construir a imagem com o buildkit rodando no sidecar. O registro Docker de destino serviria como camada de cache e a imagem final seria enviada para o registro Docker.
Esta configuração é idêntica à maioria dos construtores de CI e segue os mesmos prós e contras das configurações de CI atuais
Isso tinha as seguintes vantagens:
No entanto, esta abordagem apresentava algumas desvantagens:
1. O pod do buildkit requer um grande número de recursos, o que leva a um tempo de inicialização elevado para o executor de compilação.
2. Demora muito tempo para baixar o cache do registro do Docker, resultando em tempos de compilação lentos.
3. Não há reutilização do cache entre compilações de diferentes cargas de trabalho.
Queríamos proporcionar a mesma (e talvez melhor) experiência de construção de imagens remotamente em comparação com as compilações locais
Decidimos primeiro hospedar o pod do buildkit como um serviço no Kubernetes que pode ser compartilhado entre vários construtores e pode fornecer cache em disco local para que as compilações Docker possam ser realmente rápidas.
No entanto, esta abordagem apresenta algumas restrições:
1. O Buildkit tem uma restrição fundamental de que o sistema de arquivos de cache só pode ser usado por uma instância do Buildkit. O que isto significa é que, se executarmos várias instâncias do buildkit para processar múltiplas compilações em paralelo, cada uma delas terá o seu próprio cache e este não poderá ser partilhado.
2. Se executarmos múltiplas instâncias do buildkit, cada uma com o seu próprio cache, a mesma carga de trabalho deve ser roteada para a mesma máquina para que o cache possa ser usado de forma eficaz. Isso requer uma lógica de roteamento personalizada.
3. O autoescalonamento dos pods do buildkit com base no número de compilações em execução não é trivial. Não podemos usar o uso da CPU dos pods do buildkit como métrica de autoescalonamento, pois é possível que o Kubernetes encerre uma pequena compilação em execução, assumindo que nada está a ser executado nessa máquina.
Ter um número dinâmico de pods do buildkit com as cargas de trabalho sendo roteadas para a mesma instância de cache é um problema não trivial. Anexar e remover volumes entre pods é bastante lento no Kubernetes, o que leva a tempos muito altos para o início das compilações.
Para superar as restrições acima, desenvolvemos uma abordagem híbrida, de modo que a maioria das compilações seja concluída muito rapidamente, enquanto em alguns casos raros de alta concorrência de compilações paralelas, recorremos ao nosso fluxo anterior de execução do buildkit em um sidecar.
Na arquitetura descrita na imagem abaixo, configuramos uma certa concorrência de build abaixo da qual todas as builds serão direcionadas para o serviço buildkit. Para ilustrar, vamos considerar que alocamos uma máquina com 4 CPUs e 16GB de RAM para o serviço buildkit. A partir de dados históricos de builds, podemos determinar que esta máquina pode suportar 2 builds concorrentes. Assim, se já houver uma build em execução e uma nova chegar, ela será roteada para o serviço buildkit. No entanto, se mais uma build chegar, a rotearemos para o modelo anterior que usa o cache de camadas armazenado no registro Docker e executa o buildkit como um sidecar.
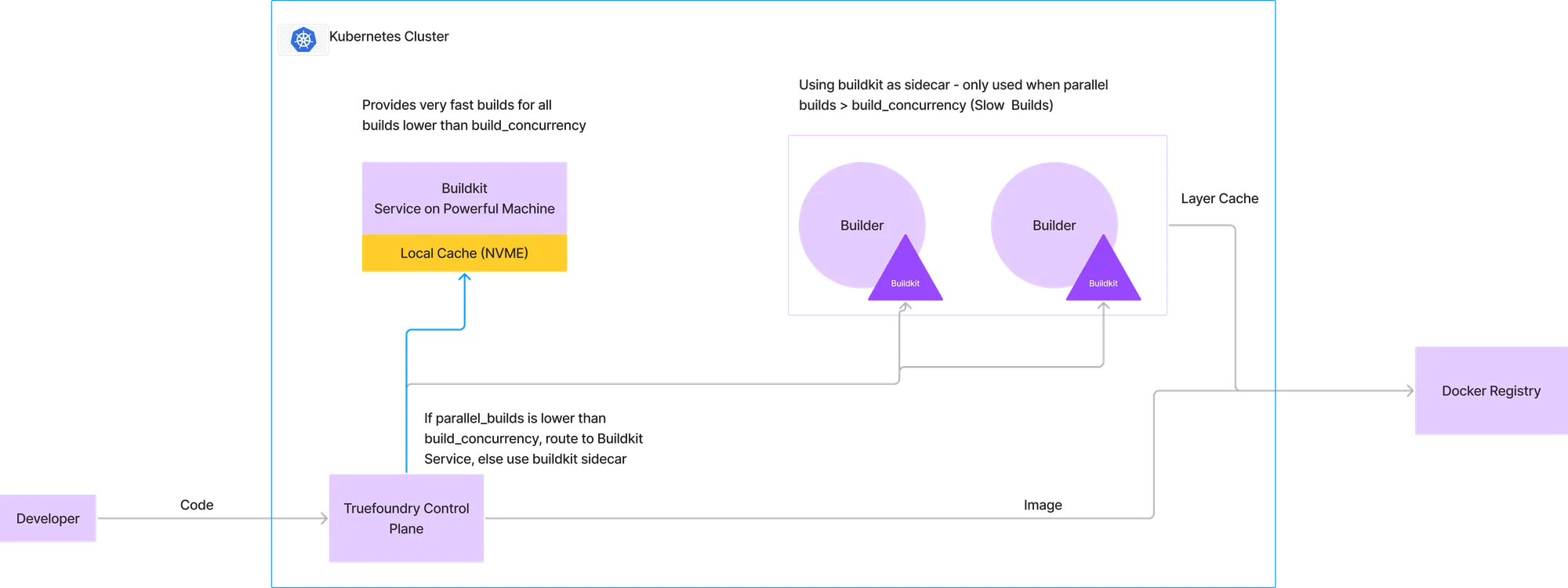
Isso nos permite fornecer builds ultrarrápidas para 99% das cargas de trabalho, enquanto em pouquíssimos casos, a build acaba levando o tempo que normalmente leva em pipelines de CI padrão.
Fizemos algumas outras melhorias no processo de build para torná-lo mais rápido. Algumas delas são:
Para fazer o comparativo de desempenho de nossos experimentos, usamos um Dockerfile de exemplo que representa o cenário mais comum para cargas de trabalho de ML.
FROM tfy.jfrog.io/tfy-mirror/python:3.10.2-slim
WORKDIR /app
RUN echo "Starting the build"
COPY ./requirements.txt /app/requirements.txt
RUN pip install -r requirements.txt
COPY . /app/
EXPOSE 8000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
O requirements.txt é o seguinte:
fastapi[standard]==0.109.1
huggingface-hub==0.24.6
vllm==0.5.4
transformers==4.43.3
Fizemos o benchmark da construção para 3 cenários:
Os tempos incluem o tempo para construir e enviar a imagem para o registro, e a unidade é em segundos.
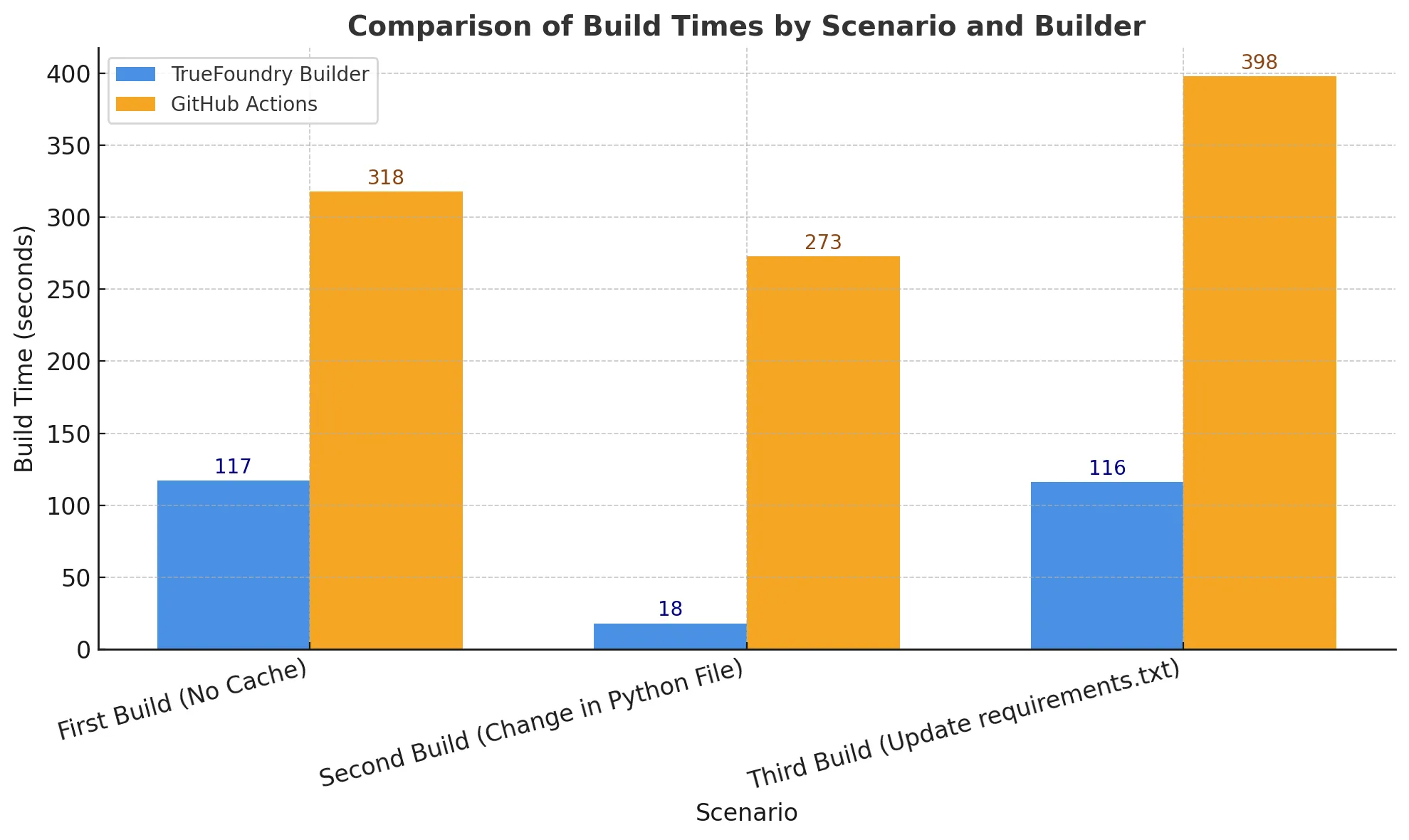
O segundo cenário, com apenas a alteração de código, é o mais comum encontrado pelos desenvolvedores e, como podemos ver, representa uma melhoria de quase 15 vezes nos tempos de construção.
Também fizemos o benchmark de um cenário com um dockerfile contendo triton como imagem base, que é uma imagem base muito maior.
FROM nvcr.io/nvidia/tritonserver:24.09-py3
WORKDIR /app
RUN echo "Starting the build"
COPY ./requirements2.txt /app/requirements.txt
RUN pip install -r requirements.txt
RUN echo "Finished the build"
Os resultados são os seguintes:
.webp)
Neste caso, observamos uma melhoria 3X no tempo de compilação para a primeira compilação e uma melhoria 9X para as compilações subsequentes.
As mudanças mencionadas acima melhoraram massivamente a experiência do desenvolvedor, permitindo-lhes iterar muito rapidamente em suas ideias, enquanto ainda mantêm paridade com a forma como as coisas serão eventualmente implantadas em produção.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




