






July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
O objetivo deste artigo é educar o leitor sobre como funciona a precificação dos Grandes Modelos de Linguagem (LLM). Isso é motivado por nossas conversas com várias empresas que utilizam LLMs comercialmente. Percebemos nessas conversas que a economia dos LLMs é frequentemente mal compreendida, deixando um vasto campo para otimização.
Você percebe que fazer a mesma tarefa pode custar US$ 3.500 com um modelo ou US$ 1.260.000 com outro? Isso vem com o custo de uma diferença de desempenho, mas deixa muito espaço para pensar sobre qual é o equilíbrio entre custo e desempenho. A tarefa é tal que posso usar algo mais barato?
Temos encontrado empresas, repetidamente, superestimando ou subestimando seus gastos com Grandes Modelos de Linguagem. Então, aqui, tentaríamos entender o custo de operar alguns dos modelos de linguagem grandes populares e como funciona sua precificação.
ℹ️
O objetivo deste blog não é educar o leitor sobre LLMs ou seus desempenhos. Este é um blog com foco em matemática, dedicado a entender a precificação de LLMs. Para simplificar, não compararemos o desempenho entre esses modelos.
A amostra para análise de precificaçãoPara entender como funciona a precificação dos LLMs, compararemos o custo incorrido para a mesma tarefa, ou seja, resumir a Wikipédia à metade de seu tamanho.
Usaremos algumas aproximações para simplificar os cálculos e torná-los facilmente compreensíveis.
❓
Tokens são subpartes de palavras que não dependem precisamente do início ou fim das palavras. É a unidade em que as APIs da OpenAI dividem a entrada em tokens antes de serem processadas. Os tokens podem incluir espaços finais e até subpalavras.
Para esta tarefa, assumimos que cada artigo é simplesmente compactado para metade do seu tamanho, para simplificar. Assim, os resultados que esperamos serão os seguintes:

Comparando o custo de usar diferentes modelos para esta tarefa
A OpenAI e outras APIs de terceiros geralmente cobram com base em dois fatores; se você deseja fazer inferências usando as APIs delas
Este custo depende do número de tokens (explicado acima) passados como contexto/prompt/instrução para a API.
É o custo baseado no número de tokens que a API retorna como resposta.
Para uma tarefa como a sumarização, uma vez que é necessário passar o documento ou excerto completo a ser resumido para o modelo, o número de tokens que fazem parte do prompt pode tornar-se significativo, daí o custo de entrada.
Com modelos auto-hospedados, o usuário precisa gerenciar/provisionar a máquina necessária para executar o modelo. Embora possa incluir o custo de gerenciamento desses recursos, o preço é relativamente fácil de entender, pois se baseia apenas no custo de execução da máquina (geralmente o que é cobrado pelos provedores de nuvem, a menos que você tenha seu próprio cluster local).
Custo de provisionamento da máquina necessária para executar/hospedar o modelo. Como a maioria desses modelos maiores é maior do que o que pode ser executado em um laptop ou em um único dispositivo local, usar um provedor de nuvem para essas máquinas é o mais comum.
Os provedores de nuvem oferecem essas instâncias, embora os usuários possam enfrentar problemas de disponibilidade de GPU, já que esses modelos exigem GPU.
Custos de instâncias Google Cloud
Custos de instâncias Microsoft Azure
Os provedores de nuvem oferecem sua capacidade ociosa por um custo que é 40-90% mais barato do que as instâncias sob demanda
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $30 (/Milhão de tokens) = $180.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $60 (/Milhão de tokens) = $180.000
Custo Total
Custo de Entrada + Custo de Saída
Custo de Entrada (/Milhões de Tokens)Custo de Saída (/Milhões de Tokens)$60$120
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $60 (/Milhões de tokens) = $360.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $120 (/Milhões de tokens) = $360.000
Custo Total
Custo de Entrada + Custo de Saída
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $11 (/Milhão de tokens) = $66.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $60 (/Milhão de tokens) = $96.000
Custo Total
Custo de Entrada + Custo de Saída
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $20 (/Milhão de tokens) = $120.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $20 (/Milhões de tokens) = $60.000
Custo Total
Custo de Entrada + Custo de Saída
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $2 (/Milhões de tokens) = $12.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $60 (/Milhões de tokens) = $6.000
Custo Total
Custo de Entrada + Custo de Saída
Custo de operação da Máquina (/Hora para Spot A100-80Gb)$10
Custo = Nº de Tokens (Por 1000 Artigos) X Nº de Artigos (Em Milhares) X Custo Unitário (Por 1 Milhão de Tokens)
Custo de Entrada
1K (tokens/artigo) X 6.000K (artigos) X $30 (/Milhão de tokens) = $180.000
Custo de Saída
0,5 K (tokens/artigo) X 6.000K (artigos) X $60 (/Milhão de tokens) = $180.000
Custo Total
Custo de Entrada + Custo de Saída
A maioria dos casos de uso que as empresas têm exige que elas ajustem modelos específicos aos seus próprios dados e para tarefas particulares. Várias empresas relataram que modelos de código aberto ajustados são equivalentes ou, por vezes, até melhores do que APIs de terceiros, como a OpenAI, para a tarefa específica.

Custo Total
Custo de Entrada + Custo de Saída

Custo Total
Custo de Entrada + Custo de Saída

Custo Total
Custo de Entrada + Custo de Saída
Pontos a observar na precificação:
Utilizamos o seguinte benchmark para analisar o efeito da otimização dos modelos no desempenho dos mesmos. É interessante notar que:
Tarefa TipoMelhor Modelo OOTB 6B/7B Few-shotMoveLM 7B Zero-shotGPT-3.5 Turbo Zero-shotGPT-3.5 Turbo Few-shotGPT-4 Zero-shotGPT-4 Few-shotRelevância - conjunto de dados interno0.330.930.840.840.920.95Extração - saída estruturada para consultas0.380.980.220.720.380.73Raciocínio - acionamento personalizado0.620.930.870.880.90.88Classificação - domínio da consulta do usuário0.210.790.60.730.70.76Extração - saída estruturada de tipagem de entidades0.830.870.90.890.890.89
Acreditamos em um estado de aplicações onde as tarefas mais fáceis são tratadas por LLMs de código aberto leves, enquanto as tarefas mais complexas ou aquelas que exigem capacidades distintas (por exemplo, pesquisa na web, chamadas de API, etc.), que são oferecidas apenas por LLMs comerciais de código fechado, podem ser delegadas a eles.
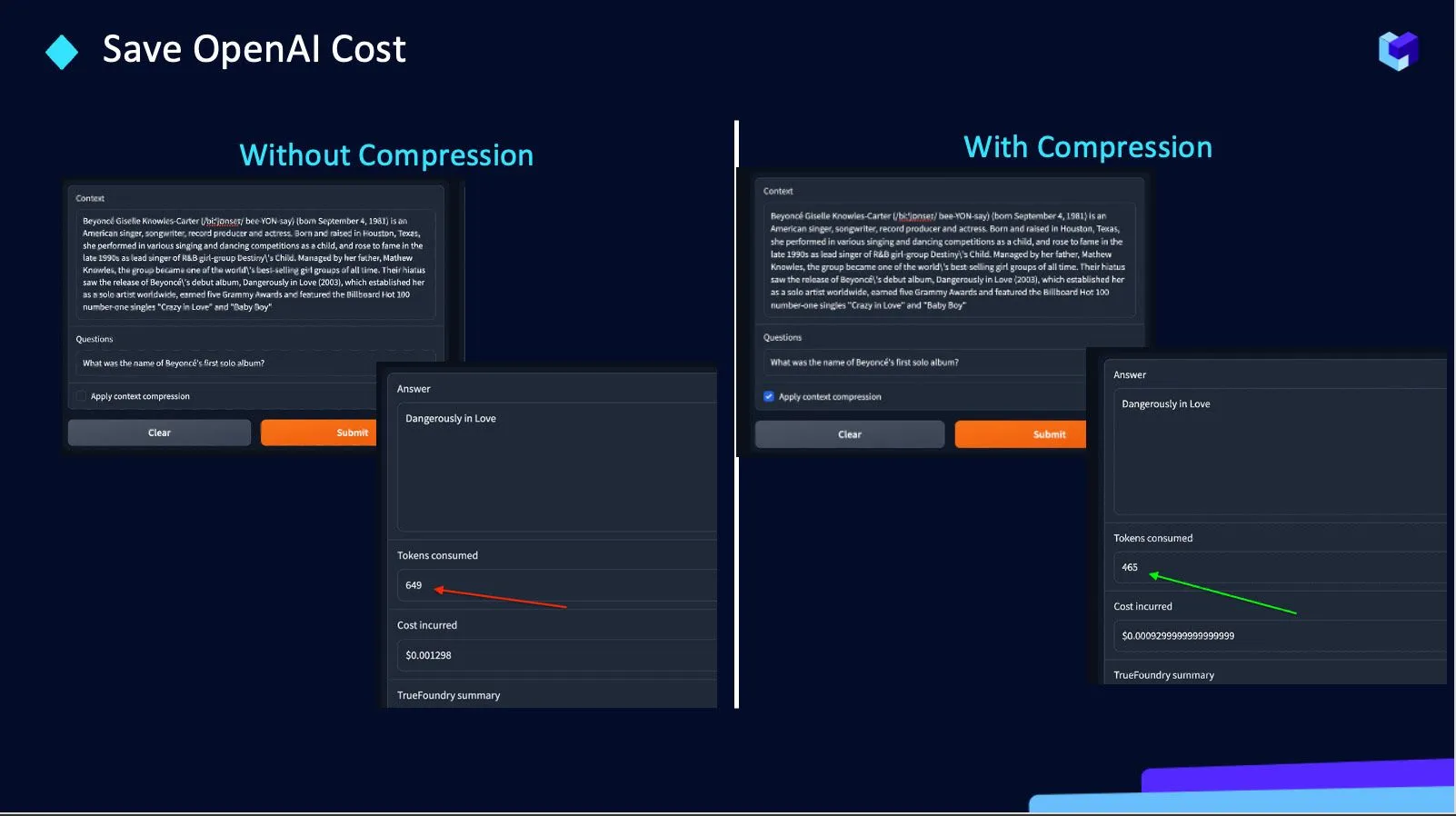
Ajudamos a reduzir o número de tokens enviados para as APIs da OpenAI. Decidimos trabalhar nisso porque:
Portanto, TrueFoundry está desenvolvendo uma API de compressão para economizar custos da OpenAI em cerca de 30%.
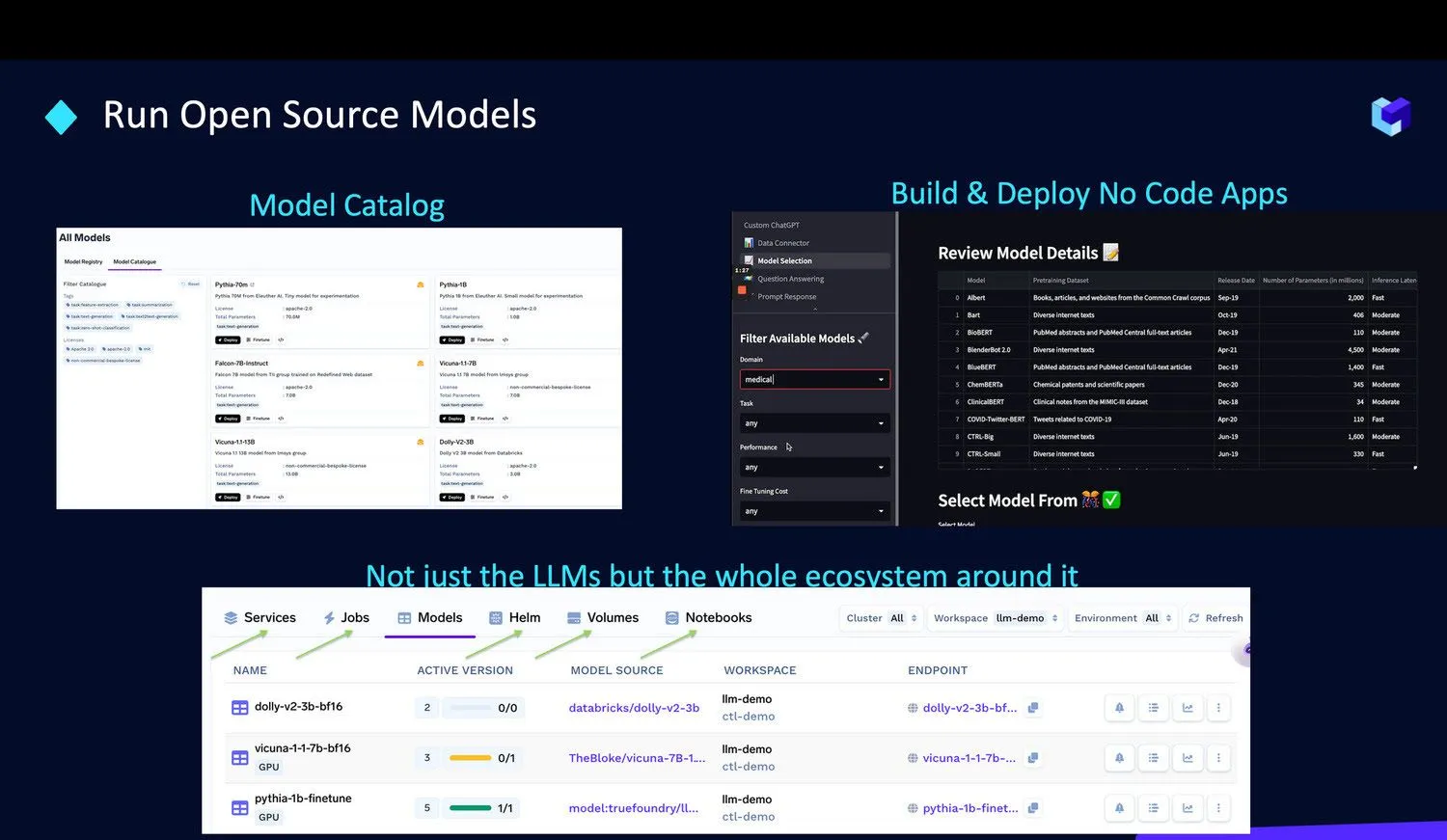
Simplificamos a execução desses modelos em sua própria infraestrutura através de nossas seguintes ofertas:
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




