







July 20, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Implementar Modelos de Linguagem Grandes (LLMs) de código aberto em escala, garantindo confiabilidade, baixa latência e custo-benefício, pode ser um desafio. Com base em nossa vasta experiência na construção de infraestrutura de LLM e sua implantação bem-sucedida para nossos clientes, compilei uma lista dos principais desafios comumente enfrentados por indivíduos neste processo.
Existem várias opções de servidores de modelo para hospedar LLMs e diversos parâmetros de configuração para ajustar e obter o melhor desempenho para o seu caso de uso. TGI, VLLM, OpenLLM são alguns dos frameworks mais comuns para hospedar esses LLMs. Você pode encontrar uma análise detalhada neste blog. Para escolher o framework certo para sua hospedagem, é importante comparar o desempenho desses frameworks para o seu caso de uso e escolher aquele que melhor se adapta. Além disso, esses frameworks possuem seus próprios parâmetros ajustáveis que podem ajudar a obter os melhores resultados de benchmark.
GPUs são caras e difíceis de encontrar. Existem vários provedores de nuvem de GPU, desde grandes nuvens como AWS, GCP e Azure até provedores de nuvem de pequena escala como Runpod, Fluidstack, Paperspace e Coreweave. Há uma grande variação nos preços e ofertas de cada um desses provedores. A confiabilidade também continua sendo uma preocupação com alguns dos provedores de nuvem de GPU mais recentes.
Na prática, isso é mais difícil do que parece. Pela nossa experiência de executar LLMs em produção, você deve estar preparado para bugs estranhos e pontuais em servidores de modelo que podem deixar seu processo travado e todas as requisições expirarem. É muito importante ter gerentes de processo adequados e sondas de prontidão/atividade configuradas para que os servidores de modelo possam se recuperar de falhas ou o tráfego possa ser transferido sem problemas de uma instância não saudável para uma saudável.
Ao fazer benchmarking, é muito importante descobrir o equilíbrio entre latência e throughput. À medida que aumentamos o número de requisições simultâneas ao modelo, a latência aumentará ligeiramente até certo ponto, após o qual a latência se deteriora drasticamente. Encontrar o equilíbrio correto entre latência, throughput e custo pode ser demorado e propenso a erros. Temos alguns blogs que descrevem esses benchmarks para Llama7B e Llama13B.
Modelos LLM são enormes em tamanho - variando de dezenas a 100GB. Pode levar muito tempo para baixar o modelo assim que o servidor do modelo estiver pronto, e depois para carregá-lo do disco para a memória. É essencial que você armazene o modelo em cache no disco para que não acabemos baixando o modelo novamente caso o processo seja reiniciado. Além disso, para economizar custos de rede, é melhor baixar o modelo uma vez e compartilhar o disco entre várias réplicas, em vez de cada réplica baixar repetidamente o modelo pela internet.
O autoescalonamento é complicado no caso de hospedagem de LLM devido ao alto tempo de inicialização de outra réplica. Se a carga for muito irregular, geralmente precisamos provisionar a infraestrutura de acordo com o pico de réplicas - no entanto, se o pico for esperado em determinados horários do dia, o autoescalonamento baseado em tempo funciona bem.
Começamos com a abordagem anterior, mas logo migramos para a arquitetura apresentada abaixo, que nos permite hospedar LLMs com custos muito baixos e alta confiabilidade.
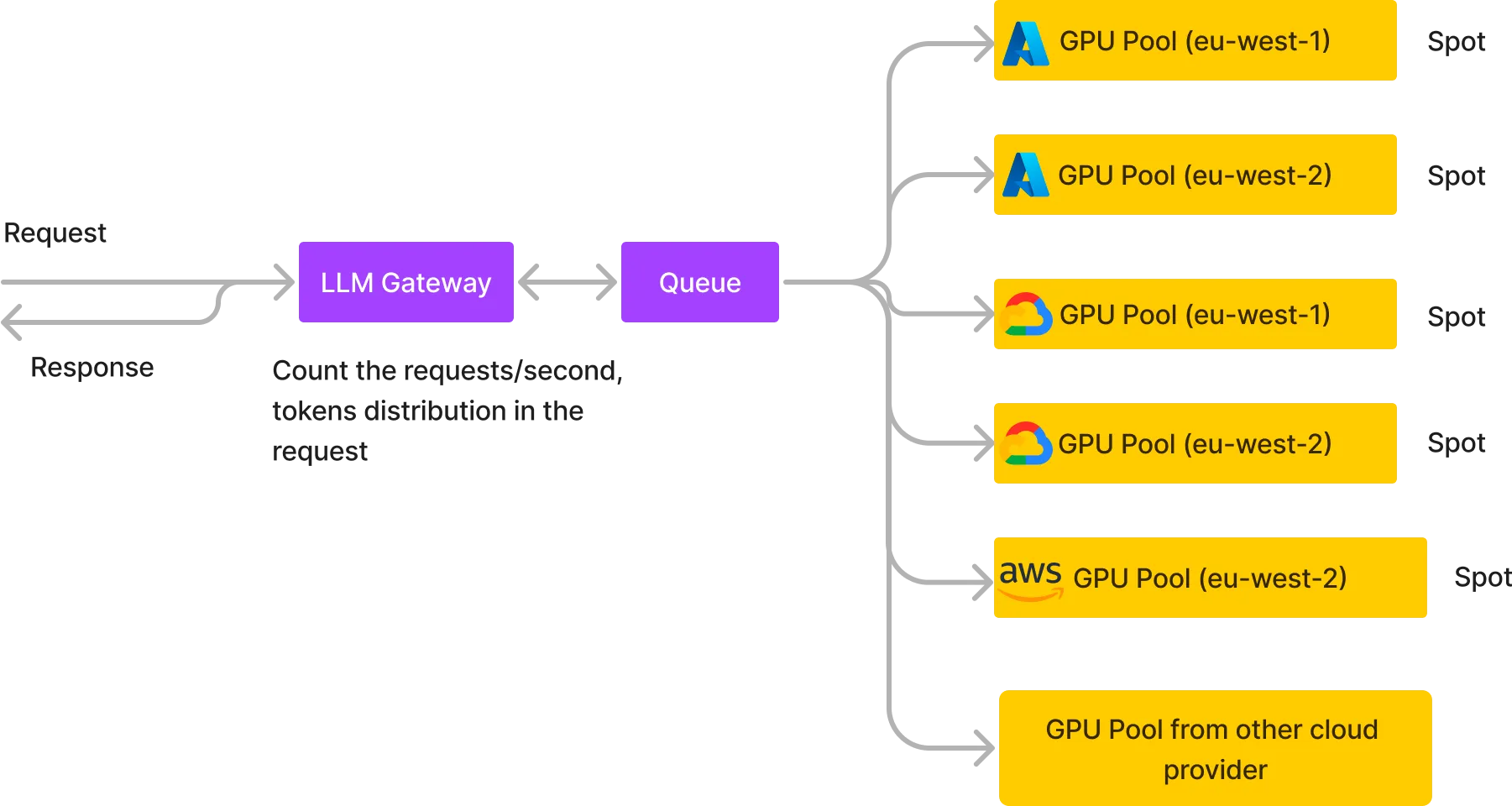
Basicamente, criamos múltiplos pools de GPU em diferentes provedores de nuvem e em diferentes regiões, e geralmente usamos instâncias spot se for um dos AWS, GCP ou Azure, ou nós sob demanda de provedores de nuvem menores. Também colocamos uma fila no meio que recebe todas as requisições, e os diferentes pools de GPU consomem da fila e retornam a resposta para a fila, de onde a resposta HTTP é retornada ao usuário. Algumas vantagens desta arquitetura:
Vamos considerar um cenário de hospedagem de um LLM com 10 requisições por segundo no pico e 7 requisições por segundo em média. Digamos que descobrimos, usando benchmarking, que uma máquina GPU A100 de 80GB pode fazer 0,5 RPS. Vamos também considerar que o tráfego é maior por 12 horas por dia (cerca de 9-10 RPS) e baixo pelas restantes 12 horas do dia (7-8 RPS).
Com base nos dados acima, podemos encontrar o número de máquinas GPU necessárias no período de pico de 12 horas e no período de não pico de 12 horas:
Período de pico de 12 horas: 20 GPUs
Período de não pico de 12 horas: 15 GPU
Vamos comparar o custo de execução do LLM usando Sagemaker, hospedando de forma direta em máquinas sob demanda na AWS, GCP e Azure e usando nossa própria arquitetura com autoescalonamento.
Custo de hospedagem no Sagemaker (região us-east-1):
Custo de máquina de 8 A100 80GB (ml.p4de.24xlarge) -> $47,11 por hora
Precisaremos de 2 máquinas durante horários de menor movimento e 3 máquinas durante horários de pico.
Custo mensal total: $85 mil
Custo de hospedagem diretamente em nós da AWS:
Custo de máquina de 8 A100 80GB (p4de.24xlarge) -> $40,966 por hora
Precisaremos de 2 máquinas durante horários de menor movimento e 3 máquinas durante horários de pico:
Custo mensal total: $73 mil
Custo de hospedagem na Truefoundry
Usando as instâncias spot e outros provedores de GPU, conseguimos reduzir o preço médio da GPU para $2,5 por hora. Assumindo 15 GPUs durante horários de menor movimento e 20 GPUs durante horários de pico, o custo total será:
$2,5 * (15*12 + 20*12) * 30 (dias por mês) = $31 mil
Como podemos ver, conseguimos hospedar o mesmo LLM por quase 30% do preço do Sagemaker com alta confiabilidade. No entanto, demandará esforços para construir e manter esta arquitetura. TrueFoundry pode ajudar a hospedá-lo para você ou hospedá-lo em sua própria conta na nuvem sem complicações, ao mesmo tempo em que economiza custos.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




