




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
Não seria errado dizer que toda empresa precisa lidar com mais tráfego, processar mais dados e atender mais clientes à medida que cresce. Frequentemente, elas precisam escalar sua infraestrutura para acompanhar as crescentes demandas. Isso também é verdade se o seu negócio tiver sazonalidade. Imagine um site de e-commerce que recebe muito tráfego durante feriados, como na Black Friday ou Cyber Monday. O tráfego do site pode aumentar drasticamente durante esses períodos de pico. O site pode apresentar problemas de carregamento lento de páginas e irritar os usuários se não conseguir lidar com o aumento da demanda. Como resultado, a empresa pode sofrer perdas de vendas e uma deterioração de sua reputação.
Uma maneira de resolver esse problema é aumentar manualmente o número de servidores na infraestrutura para lidar com o tráfego crescente. No entanto, escalar manualmente para cima e para baixo pode ser demorado, propenso a erros e difícil de gerenciar. É aqui que entra o dimensionamento automático de clusters (cluster autoscaling). O dimensionamento automático de clusters ajusta automaticamente o número de servidores na infraestrutura com base em certas condições, como uso de CPU, uso de memória ou solicitações de entrada. Isso significa que a infraestrutura pode escalar para cima ou para baixo com base na demanda atual, sem intervenção manual.
Esta postagem de blog explorará o que é o dimensionamento automático de clusters, por que ele é necessário e como ele pode ser implementado em diferentes provedores de nuvem.
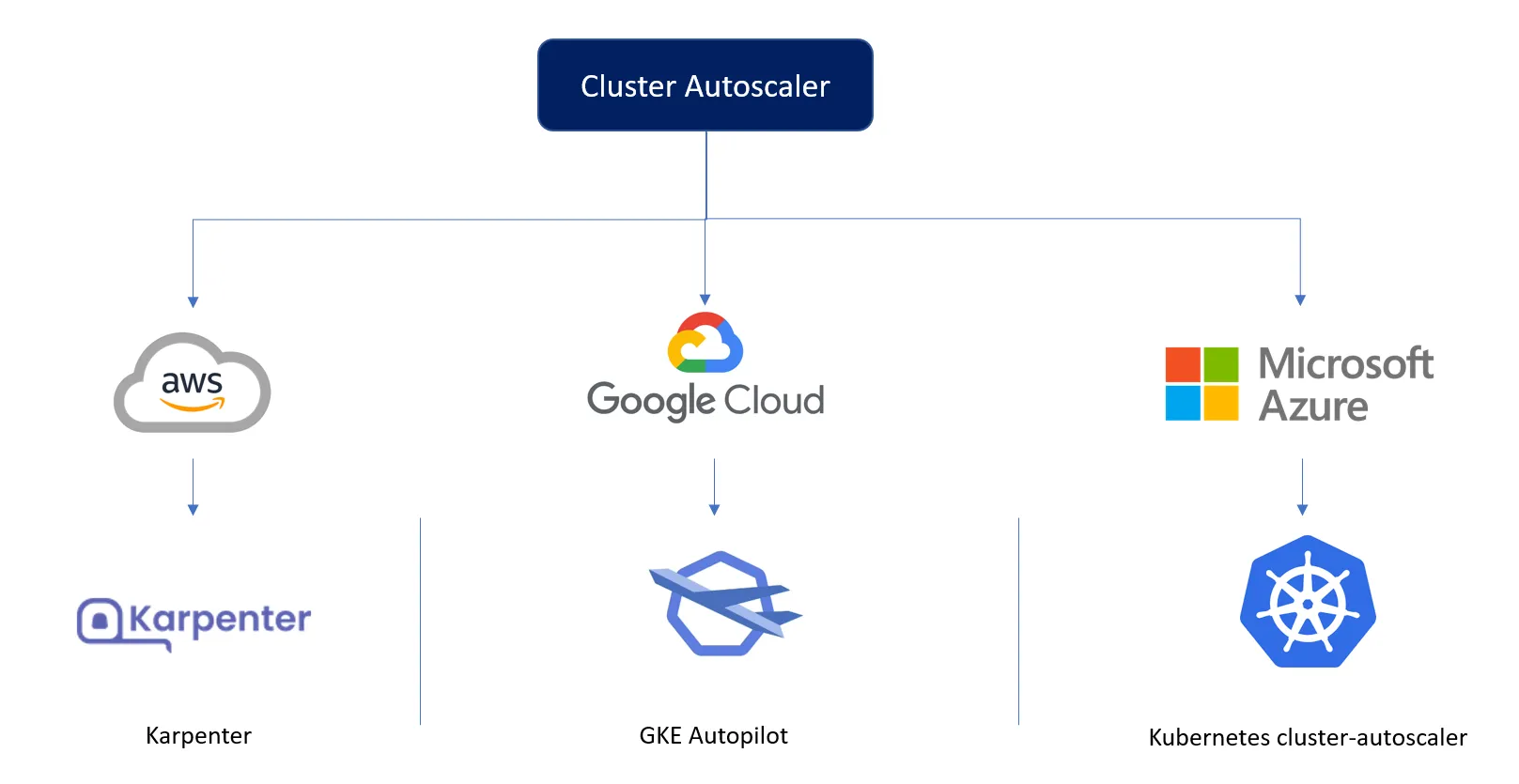
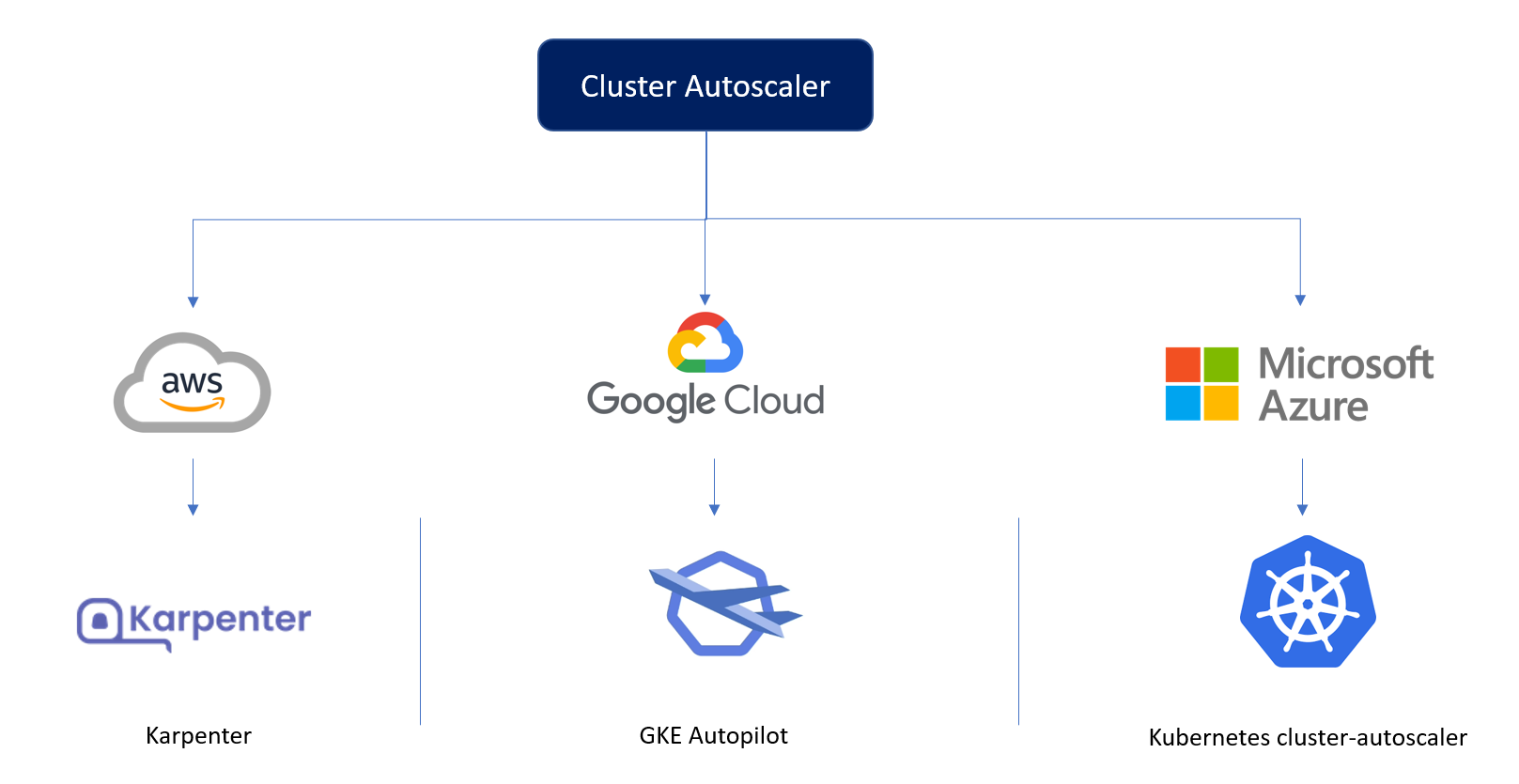
Para que nosso cluster funcione corretamente em todos os principais provedores de nuvem, precisamos adaptar a forma como escalamos os nós do cluster.
💡
Na AWS, usamos o Karpenter, que, com configuração mínima, pode escolher o nó mais barato e eficiente para as solicitações de pods recebidas.
💡
No GCP, contamos com o GKE Autopilot, que nos fornece um cluster gerenciado capaz de escalar para cima e para baixo dependendo das solicitações.
💡
Não há soluções ad-hoc no Azure, e usamos o cluster-autoscaler do Kubernetes, que é menos otimizado que o Karpenter e requer mais configuração que o Autopilot.
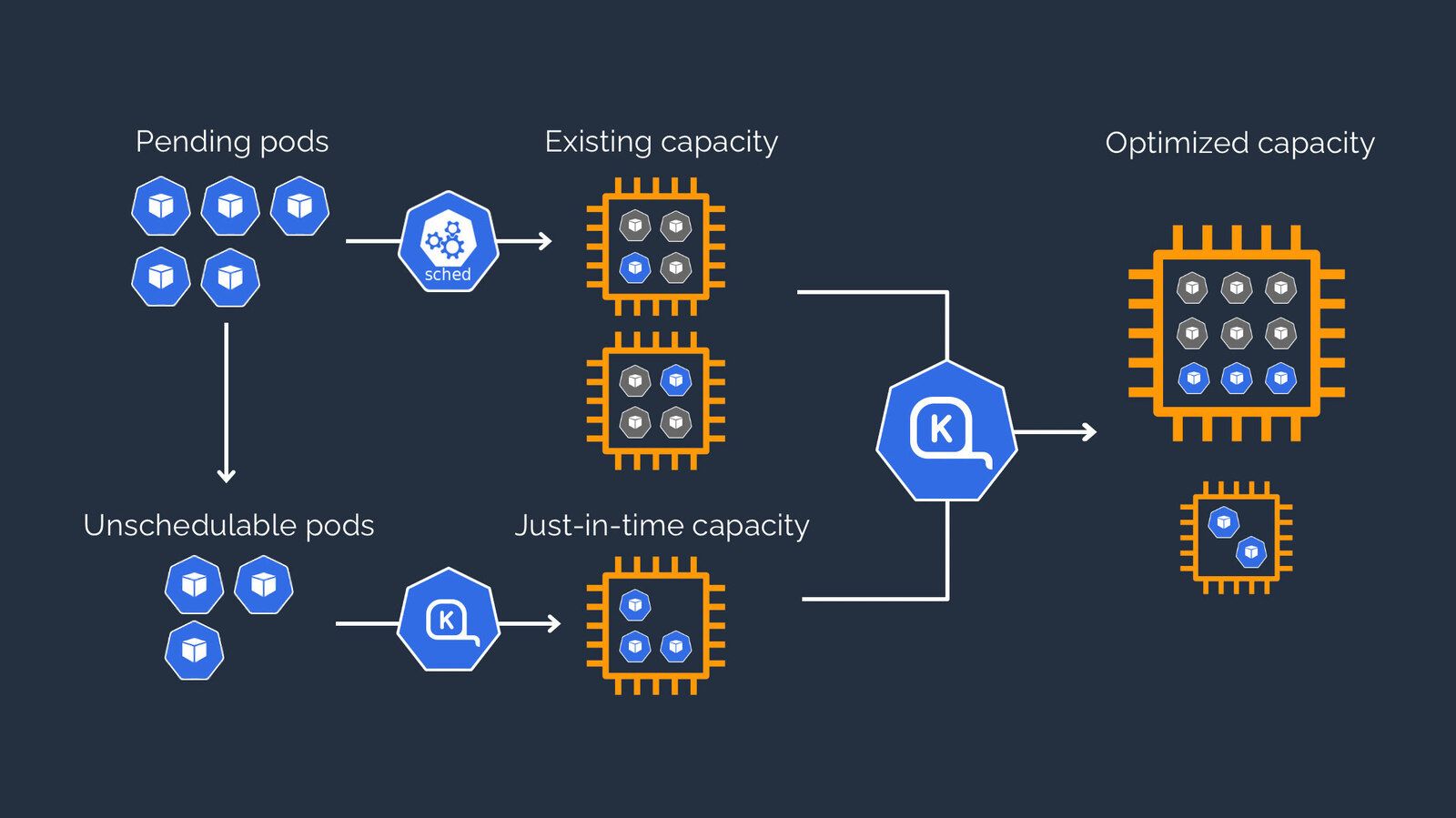
O Karpenter observa as solicitações agregadas de recursos de pods não agendados e toma decisões para iniciar e encerrar nós para minimizar latências de agendamento e custos de infraestrutura.
Mas, infelizmente, o Karpenter funciona apenas na AWS.
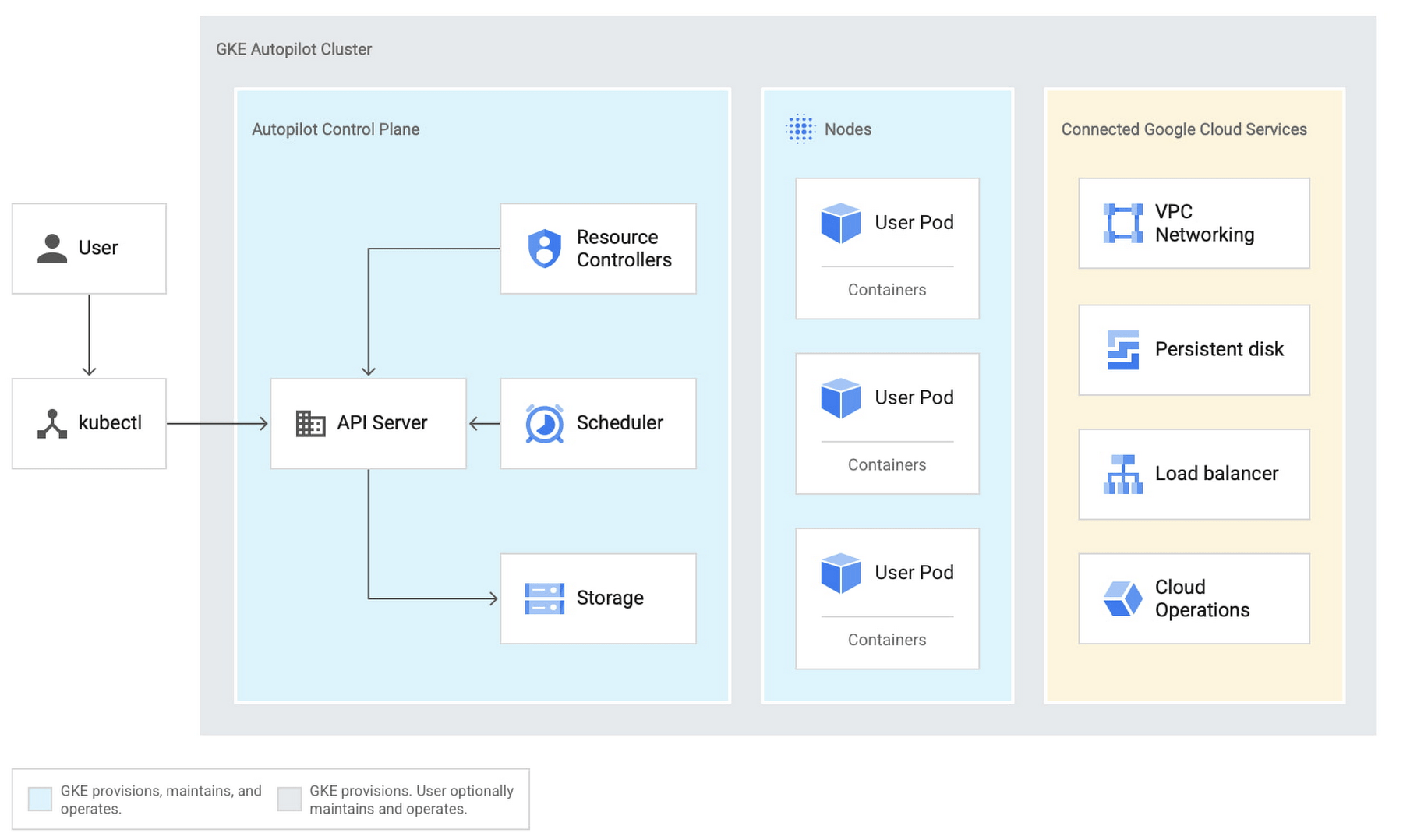
Autopilot é um serviço gerenciado que usa algoritmos de aprendizado de máquina para determinar o número ideal de nós para o cluster com base na carga de trabalho atual. Ele também oferece recursos como atualizações e patches automáticos, facilitando a manutenção do cluster atualizado e seguro.
Além do autoescalonamento, o Cluster Autopilot também oferece outros benefícios, como melhor utilização de recursos e economia de custos, evitando o superprovisionamento de recursos. Ele também proporciona uma abordagem mais automatizada para o gerenciamento de clusters, já que todas as operações de autoescalonamento são tratadas pelo serviço.
Não há uma oferta gerenciada na nuvem Azure como o GKE Autopilot ou uma abordagem personalizada para autoescalonamento como o Karpenter; portanto, dependemos do cluster-autoscaler.
O Kubernetes Cluster Autoscaler é uma ferramenta de código aberto que permite o escalonamento automático de clusters Kubernetes. Ele é executado como um pod dentro do cluster e monitora a utilização de recursos do cluster, ajustando o número de nós necessários para atender às necessidades dos aplicativos em execução. Isso ajuda a otimizar a utilização de recursos e a reduzir custos, evitando o superprovisionamento de recursos quando a demanda é baixa. O Cluster Autoscaler requer configuração manual de grupos e tipos de nós.
Este blog aborda detalhes sobre o Autoescalonamento do Kubernetes.
TrueFoundry é uma PaaS de Implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, permitindo-lhes total flexibilidade no teste e implantação de modelos, ao mesmo tempo em que garante total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos - permitindo-lhes economizar custos e lançar Modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




